一个超级懒鬼的jupyter环境搭建教学
文章目录
- 导读
- 你永远可以信赖的微软
- 随行参谋JetBrains
- 永远的神:Docker
-
- 优点
- 先去把Docker准备好
- 版本介绍
- 安装开始
- 问题发生
- 网络配置
- 环境配置
- 通信测试
- token验证
- 缺点
- 总结
导读
jupyter作为一个直接在浏览器上编辑的数据分析软件,对于一条在文献中苦苦挣扎的科研狗来说是相当友好的。但是他也有一个致命的缺点:启动的时候需要打开终端,这个终端还不能关,一关掉浏览器也给你关掉了。
作为一个懒得不能再懒的咸鱼,我连多一个终端的想法都没有,只想一开机就开始写代码。
当然方法有很多,这里一一介绍使用Docker搭建jupyter做知识图谱的方法。我会着重介绍我最推荐的,其他的会一笔带过。听说Spyder也相当优秀,但很不幸的是,我没有用过,所以我不会过多的评论这款软件。
你永远可以信赖的微软
首先,那肯定是在设计UI上相当在行的微软公司啦。虽然dotNet就是很难看的一大坨,但是每一款软件(包括Windows在内)都有相当不错的界面。
于是呢,就相当推荐微软的VScode,在软件内打开的终端是可以隐藏起来的,这就使得编译器相当干净:左边一小点是文件夹,右边一大片是编辑器。
简直不要太优秀。
但是对于我这条懒狗,打开软件后还要打开终端,再开启jupyter notebook,那可是太难受了。等服务开启之后我估计已经没有力气思考了。
随行参谋JetBrains
不管你是Java工程师还是Python工程师,只要涉及稍微大一丢丢的项目,web项目也好,爬虫项目也罢,你应该绝对会使用JetBrains的IDEA和PyCharm。因为JetBrains的代码提示做的实在是太完美了,就像一个军师一样,想要做什么直接给你规划出所有的备选方案,让你的代码速度飞起来。
不过打开软件的速度远远跟不上VScode,有太多的东西需要加载了。就像是军队的后勤部队一样,杂七杂八的东西很多,但任何一点都能起到相当大的作用。这一点相信JetBrains已经做了很多割舍和权衡了。
撇开加载速度不谈,要说有什么不足的话,那就是收费了。虽然学生可以直接申请,但不是学生就会相当贵……
永远的神:Docker
光看标题就知道我有多喜欢他了。这也是本篇着重介绍的。
优点
不得不说,Docker是一个相当神奇的虚拟环境,尤其在Linux爱好者和使用者手中就像是宝贝一样。优点就是:可以后台运行,保证了桌面的整洁,比虚拟机都方便。这一点对于强迫症相当友好。
另外,作为一个科研狗,平时用的最多的就是各种数据的处理,jupyter对我来说更轻量级,还不需要额外安装各类软件,而且浏览器还能直接查询问题,非常方便。
当然,最最最重要的优点就是:开机自启动。我突然就觉得这就是我想要的。
先去把Docker准备好
安装Docker我就不再赘述了,可以参考我的Linux版教程和Windows版教程。
接下来的重点,就是怎么搭建环境了。
版本介绍
首先,我们找到这样一个GitHub库:点击这里传送
这里面可以选一款你喜欢的jupyter,不同的版本有不同的依赖。如果你想亲自挑选,可以看看官方给的说明文档。如果想快速浏览,就看我下面简短的翻译:
- 基础版(
base-notebook)- 仅提供最低限度的功能,基本上就是个空的
Python编译环境 - 另外自带俩包管理工具
anaconda和mamba,但是科学计算包是一点都没有
- 仅提供最低限度的功能,基本上就是个空的
- 轻量版(
minial-notebook)- 在基础版之上添加了一些功能
- 能够将
LaTex导出到PDF中(还挺重要的) - 内置
git、vi、nano、tzdata、unzip,组成了一个很基础的Ubuntu Server
- 数学分析特供版(
r-notebook)- 在轻量版之上添加了一些功能
- 添加了
R语言解释器 - 塞进去了从
conda-forge里面下载的devtools、shiny、rmarkdown、forecast、rsqlite、nycflights13、caret、tidymodels、rcurl、randomforest包
- 科学计算特化版(
scipy-notebook)- 在轻量版之上添加了一些功能
- 你叫的上名字的包全都在里面,其中包括了数据分析、数据可视化等等一切涉及科学计算的包
- 深度学习特供版(
tensorflow-notebook)- 在科学计算特化版之上添加了一些功能
- 内置了
tensorflow和keras
- 数据科学特供版(
datascience-notebook)- 是科学计算特化版和数学分析特供版的结合,同时还增加了点功能
- 添加了
Julia解释器,还有HDF5、Gadfly和RDatasets
- 大数据特供版(
pyspark-notebook)- 在科学计算特化版之上添加了
Apache Spark支持和Hadoop
- 在科学计算特化版之上添加了
- 大数据旗舰版(
all-spark-notebook)- 在大数据特供版之上添加了一些功能
- 包含了
Python、R、Scala等的支持 - 还自带了
Apache Toree、spylon-kernel、ggplot2、sparklyr、rcurl等
看了这么多,是不是有点眼花缭乱?
官方是这么总结的:
似乎直观一点了。
不过我个人比较喜欢datascience这个版本,也就是数据科学特供版,因为我刚好需要。
安装开始
我们先准备一个docker-compose.yml,里面包含这些东西:
严重警告:本配置文件还有为完善的地方,请不要复制,之后给出完整版
version: '3.3'
services:
# 专用于neo4j的jupyter
jupyter-neo4j:
# 镜像
image: 'jupyter/datascience-notebook'
# 自启动
restart: always
# 使用docker exec命令登入后显示的主机名称
hostname: 'jupyter'
# docker容器名称
container_name: 'neo4j-1002'
# 端口
ports:
- 1002:8888
# 文件保存位置
volumes:
- /home/sakebow/workplace/jupyter/neo4j:/home/jovyan/work
# neo4j服务器 - 配置同上
neo4j:
image: 'neo4j'
hostname: 'neo4j'
container_name: 'neo4j-server-1074-1087'
restart: always
# 环境变量
environment:
# 用户名和密码
NEO4J_AUTH: 'neo4j/ljx62149079'
ports:
- 1074:7474
- 1087:7687
volumes:
- /usr/local/docker/neo4j/data:/data
- /usr/local/docker/neo4j/logs:/logs
- /usr/local/docker/neo4j:/var/lib/neo4j
# 严重警告:本配置文件还有为完善的地方,请不要复制,之后给出完整版
很多教程里面顺便还会加上mysql和redis的配置,其实没有必要,neo4j和jupyter就够了。
问题发生
然后,使用docker-compose up -d命令后台运行这两个容器。无需等待,命令敲完之后立马就能开始使用。如果你发现有什么配置写错了,直接改yaml文件,再次docker-compose up -d,所有的容器将会重置。放心,只要设置了volumes字段,你所有的文件就会被保存到本机,不会像重装系统一样什么都没有了。这也是Docker真正吸引我的地方。
容器启动后,我开始配置环境,然后建立测试文件,运行,发现py2neo模块一直报错,说是连不上neo4j服务器。
网络配置
初步猜测,应该是Docker之间不能相互通信。于是尝试Docker的网络配置:
docker network create py2neo --driver bridge
也就相当于使用vmware的时候设置物理机与虚拟机之间的桥接一样,而且还给了这个桥接一个名字:py2neo。
接着我们来完善一下docker-compose.yml:
这次是完整正确的配置文件,放心使用。
version: '3.3'
services:
# jupyter
jupyter-neo4j:
image: 'jupyter/datascience-notebook'
restart: always
hostname: 'jupyter'
container_name: 'neo4j-1002'
ports:
- 1002:8888
volumes:
- /home/sakebow/workplace/jupyter/neo4j:/home/jovyan/work
# neo4j-server
neo4j:
image: 'neo4j'
hostname: 'neo4j'
container_name: 'neo4j-server-1074-1087'
restart: always
environment:
NEO4J_AUTH: 'neo4j/ljx62149079'
ports:
- 1074:7474
- 1087:7687
volumes:
- /usr/local/docker/neo4j/data:/data
- /usr/local/docker/neo4j/logs:/logs
- /usr/local/docker/neo4j/conf:/var/lib/neo4j/conf
- /usr/local/docker/neo4j/import:/var/lib/neo4j/import
# 添加网络连接配置
networks:
default:
# 使用现有的连接
external:
# 用上刚刚创建的桥接名称
name: py2neo
再次使用docker-compose up -d,等启动之后,立马就能使用。
环境配置
还记得上面讲的版本差异吗?你会发现,没有一个是适合知识图谱的。不过放心,这些容器都自带了anaconda环境,我们可以进去配置。
我们既然已经把容器命名了,那就直接用容器名称咯。
docker exec -it neo4j-1002 /bin/bash
然后就进来了,终端上会显示:
jovyan@neo4j $
你可能会有点不适应。实际上在base-notebook的Dockerfile你会发现他创建了jovyan用户。但是很可惜,没有指定密码,所以是随机生成的。这个密码我们也没有办法试出来,难度太大了,包含了符号、数字、大小写字母共四种字符。也就是说,无法获得管理员权限。
但是anaconda是不需要管理员权限的,那就直接上吧:
pip3 install neo4j-driver py2neo
你问我为什么有了anaconda都不新建环境?因为Docker能够提供比anaconda更高级别的隔离性,为什么不直接新建一个Docker呢?总归也是使用浏览器写代码。
通信测试
最后,我们来看看IP。
如果是Ubuntu,那么就得先安装net-tools,然后使用ifconfig查看:
sudo apt-get install net-tools -y; ifconfig
如果是Windows,那么就直接使用ipconfig查看。
我这里一共启动了四个容器,分别是是 172.17.0.1 172.17.0.1 172.17.0.1、 172.18.0.1 172.18.0.1 172.18.0.1、 172.19.0.1 172.19.0.1 172.19.0.1、 172.20.0.1 172.20.0.1 172.20.0.1。
如果你对SpringCloud+ Docker的微服务框架有所了解,那么你应该知道,使用HTTP在Docker间通信是不能使用localhost的。但由于桥接的特殊性,这四个IP能够自由通信,哪怕完全对应不上Docker和IP,随便从四个地址中选一个都可以进入jupyter,只要你的端口号是匹配的就能进去。比如,我在yml文件中对neo4j-1002配置的是1002端口,那么就应当是 172. x . 0.1 : 1002 172.x.0.1:1002 172.x.0.1:1002,其中 x x x是 17 17 17、 18 18 18、 19 19 19、 20 20 20中的任意一个。
token验证
如果你是JavaWeb工程师,那么你对token应该是相当熟悉了吧?没错,是一段能够自验证的、经过加密计算的字符串。
如果你是每次手动开启命令行启动jupyter服务,那么确实能看到一串很长的网址,大致是:
http://0.0.0.0:8888?token=...
后面是很长一串字符串,这个就是token。把等号后面的复制下来。
但是,这次我们是后台启动,没办法看到这个,怎么办?没关系,我们还能进容器找找:
docker exec -it neo4j-1002 /bin/bash
然后在容器内输入:
jupyter notebook list
就会出现所有连上来的网址:
![]()
同样的,把这个网址中等号后面的一长串全部复制。
最后,我们打开物理机的浏览器,输入:http://localhost:1002
就会出现:
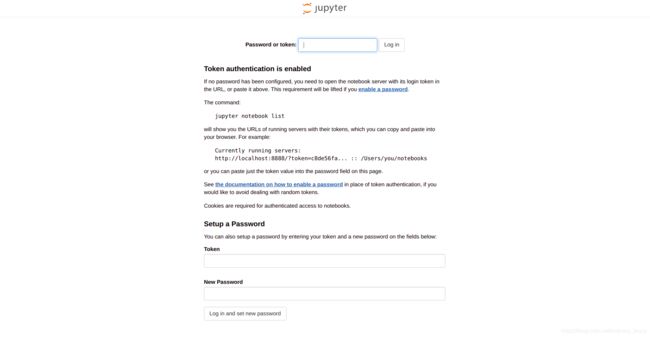
把剪贴板的内容粘贴在第一个文本框,就能够登录进去了。这一长串记不住没关系,最下面还有自定义密码的两个输入框。倒数第二个文本框还是粘贴token,倒数第一个就是自定义密码。
缺点
当然这么做肯定还有很多缺点。
Docker需要的内存相当大,如果电脑的内存小于 8 G 8G 8G,可能就相当难受,这也就是说在阿里云学生服务器上没有办法跑起来;- 不使用
anaconda新建环境的原因其实是:新建了之后jupyter没有办法切换过去,很鸡肋; - 无法使用管理员权限,如果像
vizdoom等需要额外的依赖包的话,只能下载官方提供的Dockerfile并一点点改。主要难点就是学习成本很高,进展很慢; jupyter本身就有很大局限,稍微大一点点的项目就没办法了。所以要做出一个什么产品的话还是得VScode或者PyCharm
总结
以上就是使用Docker搭建一个不需要自己启动的jupyter的全部内容。诚然,他有一些缺陷;不过对于我来说,已经相当符合我的诉求了。所以,我才会花一些心思整这个。
是不是有点能理解了呢?