机器学习:原型聚类-高斯混合聚类算法、EM算法原理推导证明
我的小程序:
 待办计划:给自己立个小目标吧!
待办计划:给自己立个小目标吧!
高斯混合聚类假设样本来自高斯混合分布。
先看高斯分布,若样本n维样本x服从高斯分布,则其概率密度函数为: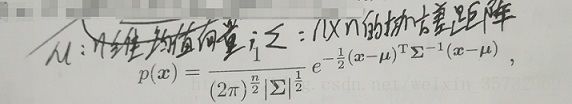
可以看出,高斯分布完全由均值向量μ和协方差矩阵Σ两个参数确定,把上式概率密度函数记为:p(x|μ,Σ).
实际中,样本集可能是来自多个不同的概率分布,或者来自相同的概率分布但分布的参数不同(这里的不同即表示了样本所属聚类的不同)。这里假设样本集来自参数不同的k个高斯分布(k个混合成分,每个混合成分即代表一个聚类),即高斯混合分布。定义高斯混合分布(也是概率密度函数):
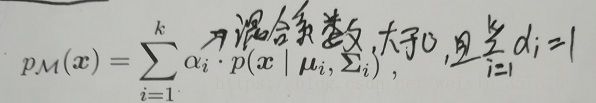
混合系数描述了样本x来自第i个混合成分的先验概率。用Zj∈{1,2,...,k}表示样本Xj来自的高斯混合成分,Zj的先验概率p(Zj=i)对应于混合系数。
我们的目的是将样本聚类,即想知道样本到底到底来自哪个高斯混合成分,即想知道Zj的后验概率:pm(Zj=i|Xj)。我们可以用贝叶斯定理:
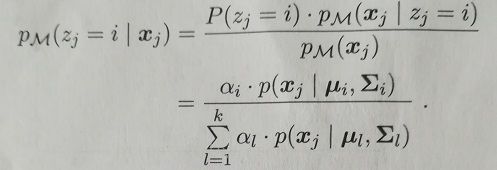
pm(Zj=i|Xj)给出了样本Xj来自第i个高斯混合成分的后验概率,记为:![]() (i=1,2,...k).所以,为了知道Xj来自哪个高斯混合成分,只要求:
(i=1,2,...k).所以,为了知道Xj来自哪个高斯混合成分,只要求:
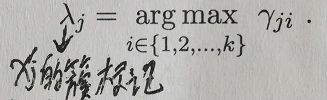
至此,万事俱备,只欠东风:怎么求高斯混合模型的参数?即求:![]() .想到可采用极大似然估计:
.想到可采用极大似然估计: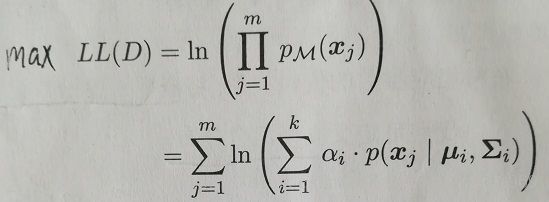
然而发现不能直接通过求导等于0来求解参数。这里通常采用EM算法。
EM算法的步骤稍后介绍,下面先介绍一些相关的东西,可能有助于加深对EM算法的理解和理清思路,可以先跳过直接看后面EM算法步骤。
所谓EM算法,是一种迭代式的方法,是常用的估计隐变量(未观测到的变量)的利器,其基本思想是:若参数已知,则可根据训练数据推断出最优隐变量的值(E步);反之,若隐变量已知,则可方便地对参数做极大似然估计(M步)。(这个等后面介绍了EM算法的具体步骤就可以理解了)
在似然函数LL(D)中,上面说的参数显然是![]() ,那么隐变量是什么?个人认为可以把样本Xj来自的高斯混合成分Zj看成隐变量(即样本Xj来自哪个高斯混合成分我们未知),或者说是把Zj的后验概率pm(Zj=i|Xj)(记为:
,那么隐变量是什么?个人认为可以把样本Xj来自的高斯混合成分Zj看成隐变量(即样本Xj来自哪个高斯混合成分我们未知),或者说是把Zj的后验概率pm(Zj=i|Xj)(记为:![]() )看成隐变量。
)看成隐变量。
回头再看似然函数LL(D),上面说不能直接求解参数,可以认为就是因为存在隐变量Zj。这里做一个假设:若隐变量Zj已知,那么就会发现可以直接求解参数。如下:
在假设隐变量Zj已知的情况下,即我们知道样本Xj来自哪个高斯混合成分,似然函数LL(D)就会退化成下面的形式: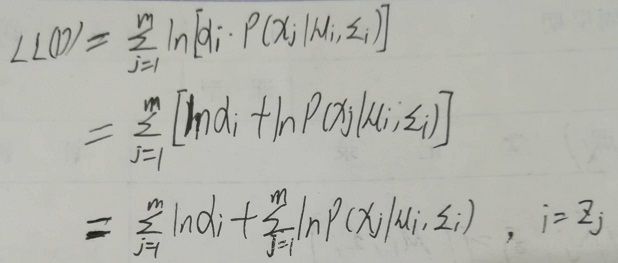
这样的形式就可以直接通过求导等于0的方法求解参数![]() ,下面以求解α为例:
,下面以求解α为例:
所以,如果已知Zj,那么求解参数![]() 就会变得很容易。但这里显然Zj是隐变量,所以要用到EM算法。下面就介绍EM算法的具体步骤。
就会变得很容易。但这里显然Zj是隐变量,所以要用到EM算法。下面就介绍EM算法的具体步骤。
首先随机初始化参数![]() ,继而可以求到:
,继而可以求到:
即得到![]() (还记得前面把pm(Zj=i|Xj)记为
(还记得前面把pm(Zj=i|Xj)记为![]() 么),
么),
接着最大化下面的似然函数:
我们令似然函数对各个参数求导为0。以对μ求导等于0为例,得到:
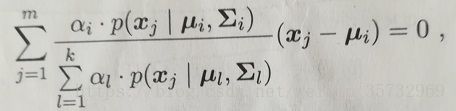
由![]() =pm(Zj=i|Xj),得:
=pm(Zj=i|Xj),得:
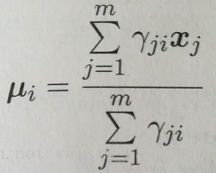
同理可得:
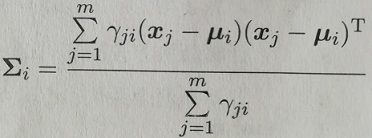
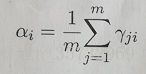
求![]() 时,要用到拉格朗日乘子法,写成拉格朗日形式:
时,要用到拉格朗日乘子法,写成拉格朗日形式:
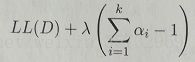
求导为0得:
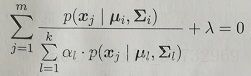
两边同乘![]() ,对所有混合成分求和:
,对所有混合成分求和:

得lambda=-m,继而求得![]() 。
。
求到所有参数![]() 后,再用新的参数求得pm(Zj=i|Xj),重复上面步骤,直到满足我们想要条件(如似然函数LL(D)不再增大,或达到最大循环轮数等)。
后,再用新的参数求得pm(Zj=i|Xj),重复上面步骤,直到满足我们想要条件(如似然函数LL(D)不再增大,或达到最大循环轮数等)。
由上面的推导,可以把高斯混合聚类的EM算法总结如下:在每步迭代中,先根据当前参数![]() 计算每个样本属于高斯成分的后验概率
计算每个样本属于高斯成分的后验概率![]() (E步);再用求到的
(E步);再用求到的![]() 跟新参数
跟新参数![]() (M步):
(M步):
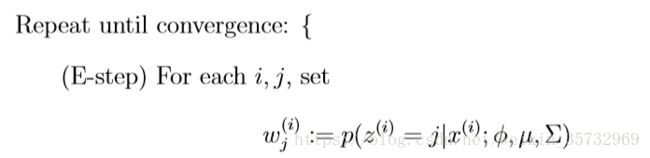

到目前为止,应该已经可以唰唰唰地手撸混合聚类算法的代码了,EM算法原来就是这么简单。但有个问题其实还没有解释清楚,上面的伪代码头一行写了这么句话:repeat until convergence(循环以下步骤直到收敛),怎么解释通过EM算法的步骤就一定会收敛呢?或者说怎么解释EM算法每一轮迭代求到的参数![]() 会使似然函数LL(D)不断增大?很遗憾,好像没有这样的直觉一下子看出来说:哦,很明显,这就是在不断变大的。只能诉诸数学推导。
会使似然函数LL(D)不断增大?很遗憾,好像没有这样的直觉一下子看出来说:哦,很明显,这就是在不断变大的。只能诉诸数学推导。
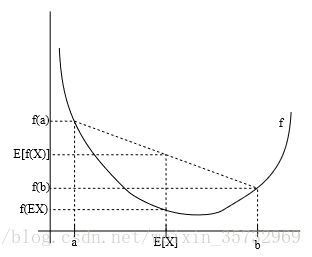
首先简单介绍下简森不等式(Jensen’s inequality):对于一个凸函数,有E[f(X)] ≥ f(EX)(凹函数相反)。且当且仅当X = E[X]时,不等式的等号成立。记住下面这个图就可以了(x以0.5的可能取a,0.5的可能取b):
利用简森不等式,并且假设存在一个关于Zj的概率分布Qj(Zj)(或写成Qj(Zj=i),i=1,2,...,k),可以得到似然函数LL(D)的下界:
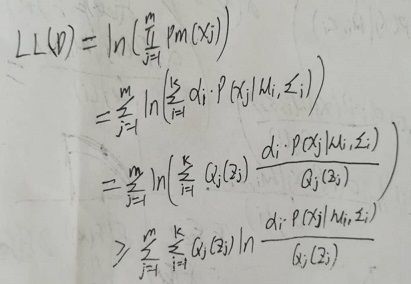
我们想知道上式不等式等号成立的条件。由简森不等式可知,等号成立的条件为X = E[X],当X是常数时,等号显然成立。继续上面的推导:

惊奇地发现,上面假设的分布Qj就是前面的![]() 。所以,当假设的概率分布Qj取
。所以,当假设的概率分布Qj取![]() 时,对LL(D)的极大似然估计,等价于求它的下界
时,对LL(D)的极大似然估计,等价于求它的下界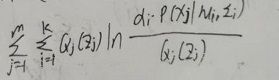 的极大似然估计。把第t+1轮迭代后求到的参数记为
的极大似然估计。把第t+1轮迭代后求到的参数记为![]() ,第t轮迭代后求到的参数记为
,第t轮迭代后求到的参数记为![]() ,从下界的形式可以容易的看出似然函数的值L(
,从下界的形式可以容易的看出似然函数的值L(![]() )>=L(
)>=L(![]() ),因为
),因为![]() 是从下面的式子求到的:
是从下面的式子求到的:
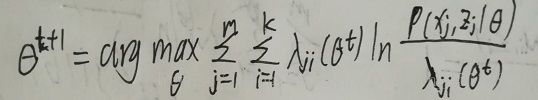
所以,通过EM算法,能保证每一轮迭代后,似然函数的值LL(D)不断增大直至收敛。
呼~终于,乱七的八糟的,有用的没用的,对的错的,该说的不该说的都扯完了~最后,加一张高斯混合聚类算法步骤的完整描述:

待办计划:给自己立个小目标吧!
参考资料:
周志华《机器学习》
Mixtures of Gaussians and the EM algorithm
The EM algorithm
参考博文:
机器学习第三课(EM算法和高斯混合模型)