【Designing ML Systems】第 3 章 :数据工程基础
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
数据源
数据格式
JSON
行主要格式与列主要格式
文本与二进制格式
数据模型
关系模型
NoSQL
文档模型
图模型
结构化数据与非结构化数据
数据存储引擎和处理
交易和分析处理
ETL:提取、转换和加载
数据流模式
数据通过数据库
数据通过服务传递
数据通过实时传输
批处理与流处理
概括
近年来 ML 的兴起与大数据的兴起紧密相关。大型数据系统,即使没有 ML,也很复杂。如果您没有与他们一起工作多年,很容易迷失在首字母缩略词中。这些系统产生了许多挑战和可能的解决方案。行业标准(如果有的话)会随着新工具的出现和行业需求的扩大而迅速发展,从而创造出一个动态且不断变化的环境。如果您查看不同科技公司的数据堆栈,似乎每个公司都在做自己的事情。
在本章中,我们将介绍数据工程的基础知识,希望这些基础知识能够为您提供一块稳定的土地,让您在探索自己的需求时可以立足。我们将从您可能在典型 ML 项目中使用的不同数据源开始。我们将继续讨论可以存储数据的格式。仅当您打算稍后检索该数据时,存储数据才有意义。要检索存储的数据,重要的是不仅要了解其格式,还要了解其结构。数据模型定义了以特定数据格式存储的数据的结构。
如果数据模型描述了现实世界中的数据,那么数据库会指定数据应该如何存储在机器上。我们将继续讨论用于两种主要处理类型的数据存储引擎(也称为数据库):事务处理和分析处理。
在生产环境中处理数据时,您通常会跨多个流程和服务处理数据。例如,您可能有一个从原始数据计算特征的特征工程服务,以及一个基于计算的特征生成预测的预测服务。这意味着您必须将计算特征从特征工程服务传递到预测服务。在本章的下一节中,我们将讨论跨进程传递数据的不同模式。
在讨论不同的数据传递模式时,我们将了解两种不同类型的数据:数据存储引擎中的历史数据和实时传输中的流数据。这两种不同类型的数据需要不同的处理范例,我们将在“批处理与流处理”一节中讨论。
了解如何收集、处理、存储、检索和处理越来越多的数据对于想要在生产中构建 ML 系统的人来说至关重要。如果您已经熟悉数据系统,您可能想直接转到第 4 章,了解有关如何采样和生成标签以创建训练数据的更多信息。如果您想从系统角度了解更多关于数据工程的信息,我推荐 Martin Kleppmann 的优秀著作Designing Data-Intensive Applications(O'Reilly,2017)。
数据源
机器学习系统可以处理数据来自许多不同的来源。它们具有不同的特性,可用于不同的用途,需要不同的加工方法。了解数据的来源可以帮助您更有效地使用数据。本节旨在为不熟悉生产中数据的人提供不同数据源的快速概览。如果您已经在生产环境中使用过 ML 一段时间,请随意跳过本节。
一个来源是用户输入数据,数据用户明确输入。用户输入可以是文本、图像、视频、上传文件等。如果用户甚至可能远程输入错误数据,他们就会这样做。结果,用户输入的数据很容易被格式化。文本可能太长或太短。在需要数值的地方,用户可能会不小心输入文本。如果您让用户上传文件,他们可能会以错误的格式上传文件。用户输入数据需要更多繁重的检查和处理。
最重要的是,用户也没有什么耐心。在大多数情况下,当我们输入数据时,我们希望立即得到结果。因此,用户输入数据往往需要快速处理。
另一个来源是系统生成的数据。这是不同的数据生成的系统的组件,包括各种类型的日志和系统输出,例如模型预测。
日志可以记录状态和意义系统的事件,例如内存使用、实例数量、调用的服务、使用的包等。它们可以记录不同作业的结果,包括用于数据处理和模型训练的大批量作业。这些类型的日志提供了对系统运行方式的可见性。这种可见性的主要目的是调试和潜在地改进应用程序。大多数情况下,您不必查看这些类型的日志,但是当某些东西着火时,它们是必不可少的。
因为日志是系统生成的,所以它们不太可能像用户输入数据那样被格式化。总的来说,日志一到就不需要像处理用户输入数据那样处理。对于许多用例,定期处理日志是可以接受的,例如每小时甚至每天。但是,您可能仍希望快速处理日志,以便能够在发生有趣的事情时检测并得到通知。1
因为调试 ML 系统很困难,所以它是一个尽可能记录所有内容的常见做法。这意味着您的日志量可以非常非常快地增长。这导致了两个问题。首先是很难知道去哪里寻找,因为信号会在噪音中丢失。已经有许多处理和分析日志的服务,例如 Logstash、Datadog、Logz.io 等。其中许多使用 ML 模型来帮助您处理和理解海量日志。
第二个问题是如何存储快速增长的日志数量。幸运的是,在大多数情况下,您只需存储有用的日志,并且在它们不再与您调试当前系统相关时可以丢弃它们。如果您不必经常访问日志,它们也可以存储在低访问存储中,其成本远低于访问频率较高的存储。2
该系统还生成数据来记录用户的行为,例如单击、选择建议、滚动、缩放、忽略弹出窗口或在某些页面上花费不寻常的时间。即使这是系统生成的数据,它仍被视为用户数据的一部分,并且可能受隐私法规的约束。3
还有内部数据库,生成通过公司中的各种服务和企业应用程序。这些数据库管理他们的资产,例如库存、客户关系、用户等。此类数据可以直接由 ML 模型使用,也可以由 ML 系统的各种组件使用。例如,当用户在 Amazon 上输入搜索查询时,一个或多个 ML 模型会处理该查询以检测其意图——如果有人输入“frozen”,他们是在寻找冷冻食品还是迪士尼的Frozen特许经营权?——那么亚马逊需要检查在对这些产品进行排名并向用户展示之前,它的内部数据库会检查这些产品的可用性。
然后是奇妙的怪异第三方数据世界。第一方数据是贵公司已经收集的有关您的用户或客户的数据。第二方数据是另一家公司收集的关于他们自己客户的数据,他们提供给您,尽管您可能需要为此付费。第三方数据公司收集非直接客户的公众数据。
互联网和智能手机的兴起使收集所有类型的数据变得更加容易。它曾经使用智能手机尤其容易,因为每部手机过去都有一个唯一的广告商 ID(带有 Apple 的广告商标识符 (IDFA) 的 iPhone 和带有 Android 广告 ID (AAID) 的 Android 手机),它充当了聚合手机上所有活动的唯一 ID . 来自应用程序、网站、签到服务等的数据被收集并(希望)匿名化以生成每个人的活动历史记录。
可以购买各种数据,例如社交媒体活动、购买历史、网络浏览习惯、汽车租赁和不同人口群体的政治倾向,这些数据与男性、25-34 岁、从事科技工作、居住在海湾地区一样精细区域。从这些数据中,您可以推断出喜欢品牌 A 的人也喜欢品牌 B 的信息。这些数据对于推荐系统等系统生成与用户兴趣相关的结果特别有用。第三方数据通常在供应商清理和处理后出售。
然而,随着用户要求更多的数据隐私,公司一直在采取措施限制广告商 ID 的使用。2021 年初,Apple 选择了他们的 IDFA。这一变化大大减少了 iPhone 上可用的第三方数据量,迫使许多公司更多地关注第一方数据。4为了应对这种变化,广告商一直在投资解决方法。例如,国家支持的中国广告行业行业协会中国广告协会投资了一个名为 CAID 的设备指纹识别系统,该系统允许 TikTok 和腾讯等应用程序持续跟踪 iPhone 用户。5
数据格式
获得数据后,您可能希望存储它(或“持久化”它,用技术术语来说)。由于您的数据来自具有不同访问模式的多个来源,6存储您的数据并不总是简单明了的,在某些情况下,成本可能很高。重要的是要考虑将来如何使用数据,这样您使用的格式才会有意义。这里有一些您可能要考虑的问题:
-
如何存储多模式数据,例如,可能包含图像和文本的样本?
-
我在哪里存储我的数据,这样它既便宜又能快速访问?
-
如何存储复杂模型,以便它们可以在不同的硬件上正确加载和运行?
将数据结构或对象状态转换为可以存储或传输并在以后重构的格式的过程就是数据序列化。有很多很多的数据序列化格式。在考虑要使用的格式时,您可能需要考虑不同的特征,例如人类可读性、访问模式,以及它是基于文本还是基于二进制,这会影响其文件的大小。表 3-1仅包含您在工作中可能遇到的一些常见格式。如需更全面的列表,请查看精彩的 Wikipedia 页面“数据序列化格式比较”。
| 格式 | 二进制/文本 | 人类可读 | 示例用例 |
|---|---|---|---|
| JSON | 文本 | 是的 | Everywhere |
| CSV | 文本 | 是的 | Everywhere |
| Parquet | 二进制 | 不 | Hadoop、Amazon Redshift |
| Avro | 二进制初级 | 不 | Hadoop |
| Protobuf | 二进制初级 | 不 | 谷歌,TensorFlow (TFRecord) |
| Pickle | 二进制 | 不 | Python、PyTorch 序列化 |
我们将从 JSON 开始介绍其中的一些格式。我们还将讨论两种常见的格式并代表两种不同的范例:CSV 和 Parquet。
JSON
JSON,JavaScript 对象表示法,是到处。尽管它是从 JavaScript 派生的,但它与语言无关——大多数现代编程语言都可以生成和解析 JSON。它是人类可读的。它的键值对范式简单但功能强大,能够处理不同层次结构的数据。例如,您的数据可以以结构化格式存储,如下所示:
{
"firstName": "Boatie",
"lastName": "McBoatFace",
"isVibing": true,
"age": 12,
"address": {
"streetAddress": "12 Ocean Drive",
"city": "Port Royal",
"postalCode": "10021-3100"
}
}相同的数据也可以存储在非结构化文本块中,如下所示:
{
"text": "Boatie McBoatFace, aged 12, is vibing, at 12 Ocean Drive, Port Royal,
10021-3100"
}因为 JSON 无处不在,它带来的痛苦也无处不在。将 JSON 文件中的数据提交到模式后,回过头来更改模式是非常痛苦的。JSON 文件是文本文件,这意味着它们占用大量空间,我们将在“文本与二进制格式”一节中看到。
行主要格式与列主要格式
两种常见的格式代表两个不同的范例是 CSV 和 Parquet。CSV(逗号分隔值)是row-major,这意味着一行中的连续元素彼此相邻存储在内存中。Parquet 是列主要的,其中表示列中的连续元素彼此相邻存储。
因为现代计算机处理顺序数据比非顺序数据更有效,所以如果一个表是行优先的,访问它的行将比访问它的列更快。这意味着对于行主要格式,按行访问数据预计比按列访问数据要快。
假设我们有一个包含 1000 个示例的数据集,每个示例有 10 个特征。如果我们将每个示例视为一行,将每个特征视为一列,就像 ML 中经常出现的情况一样,那么像 CSV 这样的行主要格式更适合访问示例,例如,访问今天收集的所有示例。Parquet 等列主要格式更适合访问功能,例如访问所有示例的时间戳。请参见图3-1。

图 3-1。行主要格式与列主要格式
列主要格式允许灵活的基于列的读取,尤其是当您的数据很大时,具有数千个(如果不是数百万个)特征。考虑一下,如果您拥有包含 1,000 个特征的拼车交易数据,但您只需要 4 个特征:时间、位置、距离、价格。使用列优先格式,您可以直接读取与这四个特征对应的四列。但是,对于行主要格式,如果您不知道行的大小,则必须读取所有列,然后过滤到这四列。即使您知道行的大小,它仍然可能很慢,因为您必须在内存中跳转,无法利用缓存。
行主要格式允许更快的数据写入。考虑当您必须不断向数据中添加新的单个示例时的情况。对于每个单独的示例,将其写入数据已经采用行主要格式的文件会快得多。
总体而言,当您必须进行大量写入时,行优先格式会更好,而当您必须进行大量基于列的读取时,列优先格式会更好。
NUMPY 与 PANDAS
很多人不支付的一个微妙点请注意,导致误用 pandas 的原因是该库是围绕列格式构建的。
pandas 是围绕 DataFrame 构建的,这是一个受 R 的 Data Frame 启发的概念,它是专栏主要。DataFrame 是具有行和列的二维表。
在 NumPy 中,主要顺序可以是指定的。创建an 时
ndarray,如果您不指定顺序,则默认为行优先。从 NumPy 来到 pandas 的人们倾向于以他们的方式对待 DataFramendarray,例如,尝试按行访问数据,并发现 DataFrame 很慢。在图 3-2的左侧面板中,您可以看到按行访问 DataFrame 是这样的比按列访问相同的 DataFrame 慢得多。如果将相同的 DataFrame 转换为 NumPy
ndarray,访问一行会变得更快,如图右侧面板所示。7
图 3-2。(左)按列迭代 pandas DataFrame 需要 0.07 秒,但按行迭代相同 DataFrame 需要 2.41 秒。(右)当您将相同的 DataFrame 转换为 NumPy
ndarray时,访问它的行变得更快。

笔记
我使用 CSV 作为行主要格式的示例,因为它很流行,并且通常被我与之交谈过的技术人员所识别。然而,本书的一些早期评论者指出,他们认为 CSV 是一种可怕的数据格式。它对非文本字符的序列化很差。例如,当您将浮点值写入 CSV 文件时,可能会丢失一些精度——0.12345678901232323 可以任意四舍五入为“0.12345678901”——正如Stack Overflow 线程和Microsoft 社区线程中所抱怨的那样。Hacker News上的人们强烈反对使用 CSV。
文本与二进制格式
CSV 和 JSON 是文本文件,而Parquet 文件是二进制文件。文本文件是纯文本文件,这通常意味着它们是人类可读的。二进制文件是指所有非文本文件的总称。顾名思义,二进制文件通常是只包含 0 和 1 的文件,旨在供知道如何解释原始字节的程序读取或使用。程序必须确切地知道二进制文件中的数据是如何布局才能使用该文件的。如果您在文本编辑器(例如,VS Code、记事本)中打开文本文件,您将能够阅读其中的文本。如果您在文本编辑器中打开二进制文件,您将看到文件相应字节的数字块,可能是十六进制值。
二进制文件更紧凑。这是一个一个简单的例子来展示二进制文件与文本文件相比如何节省空间。考虑您要存储数字1000000。如果将其存储在文本文件中,则需要 7 个字符,如果每个字符为 1 个字节,则需要 7 个字节。如果将它存储为 int32 的二进制文件,它只需要 32 位或 4 字节。
作为说明,我使用interviews.csv,它是一个 17,654 行和 10 列的 CSV 文件(文本格式)。当我将其转换为二进制格式(Parquet)时,文件大小从 14 MB 变为 6 MB,如图 3-3所示。
AWS 建议使用 Parquet 格式因为“与文本格式相比,Parquet 格式的卸载速度最多可提高 2 倍,并且在 Amazon S3 中消耗的存储空间最多可减少 6 倍。” 8
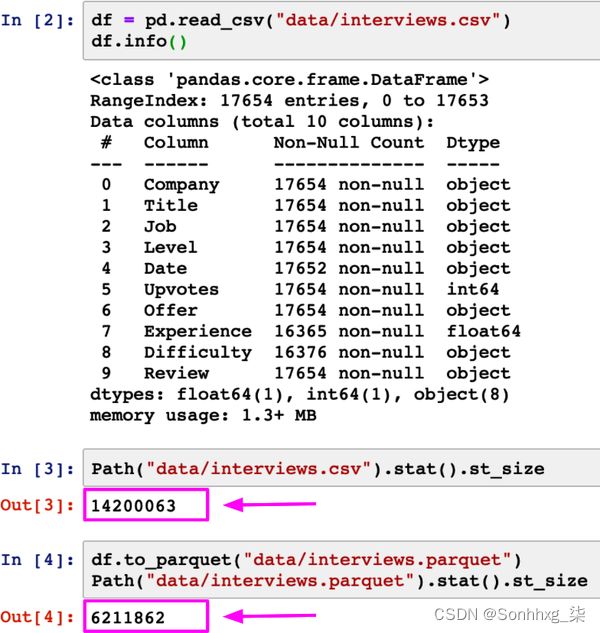
图 3-3。以 CSV 格式存储时,我的采访文件为 14 MB。但是当存储在 Parquet 中时,相同的文件是 6 MB。
数据模型
数据模型描述了数据的表示方式。考虑现实世界中的汽车。在数据库中,可以使用汽车的品牌、型号、年份、颜色和价格来描述汽车。这些属性构成了汽车的数据模型。或者,您也可以使用车主、车牌和注册地址历史来描述汽车。这是汽车的另一个数据模型。
您选择表示数据的方式不仅会影响系统的构建方式,还会影响系统可以解决的问题。例如,您在第一个数据模型中表示汽车的方式使人们更容易购买汽车,而第二个数据模型使警察更容易追踪犯罪分子。
在本节中,我们将研究两种看似相反但实际上正在融合的模型:关系模型和 NoSQL 模型。我们将通过示例来展示每个模型适合的问题类型。
关系模型
关系模型是最持久的计算机科学的思想。由 Edgar F. Codd 于 1970 年发明的9关系模型在今天仍然很强大,甚至越来越流行。这个想法很简单但很强大。在这个模型中,数据被组织成关系;每个关系都是一组元组。表是一个接受关系的可视化表示,表的每一行组成一个元组,10 ,如图 3-4所示。关系是无序的。您可以打乱关系中行的顺序或列的顺序,它仍然是相同的关系。遵循关系模型的数据通常以 CSV 或 Parquet 等文件格式存储。

图 3-4。在关系中,行和列的顺序都不重要
对于关系来说,这通常是可取的被规范化。数据规范化可以遵循规范形式,例如第一个范式(1NF)、第二范式(2NF)等,有兴趣的读者可以在维基百科上了解更多。在本书中,我们将通过一个示例来展示规范化的工作原理以及它如何减少数据冗余并提高数据完整性。
考虑表 3-2中所示的关系 Book 。此数据中有很多重复项。例如,第 1 行和第 2 行几乎相同,除了格式和价格。如果出版商信息发生变化——例如,它的名称从“Banana Press”更改为“Pineapple Press”——或者它的国家/地区发生变化,我们将不得不更新第 1、2 和 4 行。如果我们将出版商信息分成自己的表,如表3-3和表3-4所示,当发布者的信息发生变化时,我们只需要更新发布者关系即可。11这种做法使我们能够标准化不同列中相同值的拼写。它还使更改这些值变得更容易,因为这些值发生了变化,或者当您想要将它们翻译成不同的语言时。
表 3-2。初始账簿关系
| Title | Author | Format | Publisher | Country | Price |
|---|---|---|---|---|---|
| Harry Potter | J.K. Rowling | Paperback | Banana Press | UK | $20 |
| Harry Potter | J.K. Rowling | E-book | Banana Press | UK | $10 |
| Sherlock Holmes | Conan Doyle | Paperback | Guava Press | US | $30 |
| The Hobbit | J.R.R. Tolkien | Paperback | Banana Press | UK | $30 |
| Sherlock Holmes | Conan Doyle | Paperback | Guava Press | US | $15 |
表 3-3。更新书籍关系
| Title | Author | Format | Publisher ID | Price |
|---|---|---|---|---|
| Harry Potter | J.K. Rowling | Paperback | 1 | $20 |
| Harry Potter | J.K. Rowling | E-book | 1 | $10 |
| Sherlock Holmes | Conan Doyle | Paperback | 2 | $30 |
| The Hobbit | J.R.R. Tolkien | Paperback | 1 | $30 |
| Sherlock Holmes | Conan Doyle | Paperback | 2 | $15 |
表 3-4。发布者关系
| Publisher ID | Publisher | Country |
|---|---|---|
| 1 | Banana Press | UK |
| 2 | Guava Press | US |
规范化的一个主要缺点是您的数据现在分布在多个关系中。您可以将来自不同关系的数据重新连接在一起,但对于大型表来说,连接可能会很昂贵。
围绕关系数据模型构建的数据库是关系数据库。将数据放入数据库后,您将需要一种检索方法。可用于指定数据的语言您想要从数据库中获取的内容称为查询语言。当今关系数据库最流行的查询语言是 SQL。尽管受到关系模型的启发,但 SQL 背后的数据模型已经偏离了原来的关系模型。例如,SQL 表可以包含行重复,而真正的关系不能包含重复。然而,大多数人已经安全地忽略了这种细微的差异。
关于 SQL 需要注意的最重要的一点是,它是一种声明性语言,而 Python 是一种命令式语言。在命令式范例中,您指定操作所需的步骤,计算机执行这些步骤以返回输出。在声明式范式中,您指定所需的输出,计算机会计算出获得查询输出所需的步骤。
使用 SQL 数据库,您可以指定所需的数据模式——您要从中获取数据的表、结果必须满足的条件、基本的数据转换,例如连接、排序、分组、聚合等——但不是如何检索数据。由数据库系统决定如何将查询分成不同的部分,使用什么方法来执行查询的每个部分,以及执行查询的不同部分的顺序。
通过某些附加功能,SQL 可以是图灵完备的,这意味着,理论上,SQL 可用于解决任何计算问题(无需对所需的时间或内存做出任何保证)。然而,在实践中,编写查询来解决特定任务并不总是那么容易,而且执行查询并不总是可行或易于处理的。任何使用 SQL 数据库的人都可能对冗长的 SQL 查询有着噩梦般的回忆,这些查询无法理解,而且没有人敢触摸,因为担心事情可能会中断。12
弄清楚如何执行任意查询是困难的部分,这是查询优化器的工作。查询优化器检查执行查询的所有可能方式并找到最快的方式来执行此操作。13可以使用机器学习来改进基于传入查询学习的查询优化器。14查询优化是数据库系统中最具挑战性的问题之一,而规范化意味着数据分散在多个关系上,这使得将它们连接在一起变得更加困难。尽管开发查询优化器很困难,但好消息是您通常只需要一个查询优化器,并且您的所有应用程序都可以利用它。
从声明式数据系统到声明式机器学习系统
可能是受到声明式数据系统成功的启发,许多人一直期待声明式机器学习。15使用声明式机器学习系统,用户只需要声明特征的模式和任务,系统就会找出最佳模型来执行具有给定特征的任务。用户不必编写代码来构建、训练和调整模型。声明式机器学习的流行框架是由 Uber 开发的Ludwig和H2O AutoML。在 Ludwig 中,用户可以在特征的模式和输出之上指定模型结构,例如全连接层的数量和隐藏单元的数量。在 H2O AutoML 中,您无需指定模型结构或超参数。它对多种模型架构进行试验,并根据特征和任务挑选出最佳模型。
这是一个示例来显示H2O AutoML 如何工作。您向系统提供数据(输入和输出)并指定要试验的模型数量。它将试验该数量的模型并向您展示性能最佳的模型:
# Identify predictors and response
x = train.columns
y = "response"
x.remove(y)
# For binary classification, response should be a factor
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
# Run AutoML for 20 base models
aml = H2OAutoML(max_models=20, seed=1)
aml.train(x=x, y=y, training_frame=train)
# Show the best-performing models on the AutoML Leaderboard
lb = aml.leaderboard
# Get the best-performing model
aml.leader虽然声明式机器学习在许多情况下很有用,但它在生产中留下了机器学习面临的最大挑战。今天的声明式机器学习系统抽象出模型开发部分,正如我们将在接下来的六章中介绍的那样,随着模型越来越商品化,模型开发通常是更容易的部分。难点在于功能工程、数据处理、模型评估、数据偏移检测、持续学习等。
NoSQL
关系数据模型能够推广到很多用例,从电子商务到金融再到社交网络。但是,对于某些用例,此模型可能具有限制性。例如,它要求您的数据遵循严格的模式,而模式管理很痛苦。在 2014 年 Couchbase 的一项调查中,对模式管理的不满是采用其非关系数据库的第一大原因。16为专门的应用程序编写和执行 SQL 查询也很困难。
反对关系数据模型的最新运动是 NoSQL。NoSQL 最初是作为讨论非关系数据库的聚会的主题标签开始的,后来被追溯重新解释为不仅仅是 SQL,17因为许多 NoSQL 数据系统也支持关系模型。两种主要类型的非关系模型是文档模型和图模型。文档模型针对的用例是数据来自自包含文档并且一个文档与另一个文档之间的关系很少见的用例。图模型的方向相反,针对数据项之间的关系常见且重要的用例。我们将从文档模型开始检查这两个模型中的每一个。
文档模型
文档模型建立围绕“文档”的概念。文档通常是单个连续字符串,编码为 JSON、XML 或 BSON(Binary JSON)等二进制格式。假定文档数据库中的所有文档都以相同的格式编码。每个文档都有一个代表该文档的唯一键,可用于检索它。
可以将文档集合视为类似于关系数据库中的表,将文档视为类似于行。事实上,您可以通过这种方式将关系转换为文档集合。例如,您可以将表3-3和表3-4中的图书数据转换为三个 JSON 文档,如示例3-1、3-2和3-3所示。但是,文档集合比表格灵活得多。表中的所有行必须遵循相同的模式(例如,具有相同的列序列),而同一集合中的文档可以具有完全不同的模式。
示例 3-1。文件 1:harry_potter.json
{
"Title": "Harry Potter",
"Author": "J .K. Rowling",
"Publisher": "Banana Press",
"Country": "UK",
"Sold as": [
{"Format": "Paperback", "Price": "$20"},
{"Format": "E-book", "Price": "$10"}
]
} 示例 3-2。文件 2:sherlock_holmes.json
{
"Title": "Sherlock Holmes",
"Author": "Conan Doyle",
"Publisher": "Guava Press",
"Country": "US",
"Sold as": [
{"Format": "Paperback", "Price": "$30"},
{"Format": "E-book", "Price": "$15"}
]
} 示例 3-3。文档 3:the_hobbit.json
{
"Title": "The Hobbit",
"Author": "J.R.R. Tolkien",
"Publisher": "Banana Press",
"Country": "UK",
"Sold as": [
{"Format": "Paperback", "Price": "$30"},
]
} 因为文档模型不强制使用模式,所以它通常被称为无模式。这是误导性的,因为前面讨论过,存储在文档中的数据稍后会被读取。读取文档的应用程序通常假设文档的某种结构。文档数据库只是将假设结构的责任从写入数据的应用程序转移到读取数据的应用程序。
文档模型比关系模型具有更好的局部性。考虑表3-3和3-4中的图书数据示例,其中有关图书的信息分布在 Book 表和 Publisher 表(可能还有 Format 表)中。要检索有关一本书的信息,您必须查询多个表。在文档模型中,关于一本书的所有信息都可以存储在文档中,从而更容易检索。
但是,与关系模型相比,与跨表相比,跨文档执行联接更难且效率更低。例如,如果要查找价格低于 25 美元的所有书籍,则必须阅读所有文档,提取价格,将它们与 25 美元进行比较,然后返回包含价格低于 25 美元的书籍的所有文档。
由于文档模型和关系数据模型的不同优势,通常将这两种模型用于同一数据库系统中的不同任务。越来越多的数据库系统,例如 PostgreSQL 和 MySQL,都支持它们。
图模型
图模型是围绕“图”的概念。图由节点和边组成,边代表节点之间的关系。使用图结构存储其数据的数据库称为图数据库。如果在文档数据库中,每个文档的内容是优先级,那么在图形数据库中,数据项之间的关系是优先级。
因为关系是在图形模型中显式建模的,所以基于关系检索数据会更快。考虑图 3-5中的图形数据库示例。此示例中的数据可能来自简单的社交网络。在这个图中,节点可以是不同的数据类型:人、城市、国家、公司等。

图 3-5。一个简单的图形数据库示例
想象一下,您想找到所有出生在美国的人。给定这个图,你可以从节点 USA 开始,沿着边“within”和“born_in”遍历图,找到所有类型为“person”的节点。现在,想象一下,我们不使用图形模型来表示这些数据,而是使用关系模型。写一个 SQL 查询来找到每个出生在美国的人并不容易,特别是考虑到国家和人之间的跳数未知——徐振中和美国之间有 3 跳,而只有Chloe He 和美国之间的两跳。同样,使用文档数据库进行此类查询也没有简单的方法。
许多在一个数据模型中容易完成的查询在另一个数据模型中更难完成。选择正确的数据模型您的应用程序可以让您的生活变得如此轻松。
结构化数据与非结构化数据
结构化数据遵循预定义的数据模型,也称为数据模式。例如,数据模型可能指定每个数据项由两个值组成:第一个值“name”是最多 50 个字符的字符串,第二个值“age”是 0 到 200 之间的 8 位整数。预定义的结构使您的数据更易于分析。如果您想知道数据库中人们的平均年龄,您所要做的就是提取所有年龄值并将它们平均出来。
结构化数据的缺点是您必须将数据提交到预定义的模式。如果您的架构发生更改,您将不得不追溯更新所有数据,这通常会在此过程中导致神秘的错误。例如,您以前从未保留过用户的电子邮件地址,但现在您这样做了,因此您必须追溯更新所有以前用户的电子邮件信息。我的一位同事遇到的最奇怪的错误之一是,他们不能再在交易中使用用户的年龄,他们的数据模式将所有空年龄替换为 0,他们的 ML 模型认为交易是由 0 岁的人进行的. 18
由于业务需求会随着时间的推移而变化,因此提交预定义的数据模式可能会变得过于严格。或者,您可能拥有来自多个数据源的数据,这些数据超出了您的控制范围,并且不可能使它们遵循相同的架构。这就是非结构化数据变得有吸引力的地方。非结构化数据不遵循预定义的数据模式。它通常是文本,但也可以是数字、日期、图像、音频等。例如,由您的 ML 模型生成的日志文本文件是非结构化数据。
即使非结构化数据不遵循模式,它仍可能包含帮助您提取结构的内在模式。例如,以下文本是非结构化的,但您可以注意到每行包含两个用逗号分隔的值的模式,第一个值是文本的,第二个值是数字的。但是,不能保证所有行都必须遵循这种格式。即使该行不遵循此格式,您也可以向该文本添加新行。
Lisa, 43 Jack, 23 Huyen, 59
非结构化数据还允许更灵活的存储选项。例如,如果您的存储遵循模式,则您只能存储遵循该模式的数据。但是,如果您的存储不遵循模式,您可以存储任何类型的数据。无论类型和格式如何,您都可以将所有数据转换为字节串并将它们存储在一起。
用于存储结构化数据的存储库称为数据仓库。用于存储非结构化数据的存储库称为数据湖。数据湖通常用于在处理之前存储原始数据。数据仓库用于存储已处理为可供使用的格式的数据。表 3-5总结了主要差异结构化和非结构化数据之间。
| 结构化数据 | 非结构化数据 |
|---|---|
| 架构明确定义 | 数据不必遵循模式 |
| 易于搜索和分析 | 快速到达 |
| 只能处理具有特定模式的数据 | 可以处理来自任何来源的数据 |
| 架构更改会带来很多麻烦 | 无需担心架构更改(还),因为担心转移到使用此数据的下游应用程序 |
| 存储在数据仓库中 | 存储在数据湖中 |
数据存储引擎和处理
数据格式和数据模型指定了用户如何存储和检索数据的接口。存储引擎,也称为数据库,是数据如何在机器上存储和检索的实现。了解不同类型的数据库很有用,因为您的团队或相邻团队可能需要选择适合您的应用程序的数据库。
通常,数据库针对两种类型的工作负载进行了优化,事务处理和分析处理,它们之间存在很大差异,我们将在本节中介绍。然后,我们将介绍 ETL(提取、转换、加载)过程的基础知识,您在生产环境中构建 ML 系统时将不可避免地遇到这些过程。
交易和分析处理
传统上,交易是指购买或出售某物的行为。在数字世界中,一个交易是指任何类型的操作:发推文、通过拼车服务订购乘车、上传新车型、观看 YouTube 视频等等。尽管这些不同的事务涉及不同类型的数据,但它们的处理方式在应用程序中是相似的。事务在生成时插入,偶尔会在某些内容发生更改时更新,或者在不再需要时删除。19这种类型的处理称为在线事务处理(OLTP)。
由于这些交易通常涉及用户,因此需要快速处理(低延迟),以免让用户等待。处理方法需要具有高可用性——也就是说,处理系统需要在用户想要进行交易的任何时候都可用。如果您的系统无法处理交易,则该交易将无法通过。
事务数据库旨在处理在线事务并满足低延迟、高可用性的要求。当人们听到事务数据库时,他们通常会想到 ACID(原子性、一致性、隔离性、持久性)。这是他们的需要快速提醒的人的定义:
原子性
保证一个事务中的所有步骤作为一个组成功完成。如果事务中的任何步骤失败,则所有其他步骤也必须失败。例如,如果用户付款失败,您不希望仍为该用户分配驱动程序。
一致性
为了保证所有通过的交易必须遵循预定义的规则。例如,交易必须由有效用户进行。
隔离
保证两个事务同时发生,就好像它们是孤立的一样。访问相同数据的两个用户不会同时更改它。例如,您不希望两个用户同时预订同一个司机。
耐用性
为了保证事务一旦提交,即使在系统故障的情况下也将保持提交状态。例如,在您叫车后,您的手机没电了,您仍然希望您的车能来。
但是,事务数据库不必须是 ACID,一些开发人员发现 ACID 限制太多。根据 Martin Kleppmann 的说法,“不符合 ACID 标准的系统有时会称为 BASE,它代表B asically A vailable、S oft state 和E最终一致性。这比 ACID 的定义还要模糊。” 20
因为每个事务通常作为一个单元与其他事务分开处理,所以事务数据库通常是行优先的。这也意味着事务数据库可能无法有效解决诸如“旧金山 9 月份所有游乐设施的平均价格是多少?”之类的问题。这种分析问题需要在多行数据的列中聚合数据。分析数据库就是为此目的而设计的。它们对允许您从不同角度查看数据的查询非常有效。我们将这种类型的处理称为在线分析处理(OLAP)。
但是,OLTP 和 OLAP 这两个术语都已经过时了,如图 3-6所示,原因有三。一、事务型数据库和分析型数据库的分离是由于技术的限制——很难拥有能够有效处理事务和分析查询的数据库。然而,这种分离正在被关闭。今天,我们拥有可以处理分析查询的事务数据库,例如CockroachDB。我们还有可以处理事务查询的分析数据库,例如Apache Iceberg和DuckDB。
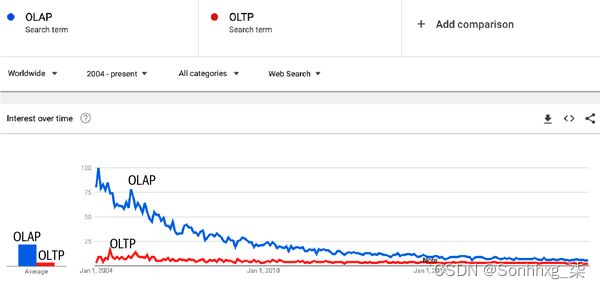
图 3-6。根据Google 趋势,截至 2021 年,OLAP 和 OLTP 已过时
其次,在传统的 OLTP 或 OLAP 范式中,存储和处理是紧密耦合的——数据的存储方式也是数据的处理方式。这可能导致相同的数据存储在多个数据库中,并使用不同的处理引擎来解决不同类型的查询。过去十年中一个有趣的范例是将存储与处理(也称为计算)分离,许多数据供应商都采用了这种模式,包括 Google 的 BigQuery、Snowflake、IBM 和 Teradata。21在这个范例中,数据可以存储在同一个地方,顶部有一个处理层,可以针对不同类型的查询进行优化。
第三,“在线”已成为一个超载的术语,可以表示许多不同的含义。在线过去只是意味着“连接到互联网”。然后,它也变成了“生产中”的意思——我们说一个特性在该特性被部署到生产中之后就上线了。
在当今的数据世界中,在线可能指的是您的数据被处理和提供的速度:在线、近线或离线。根据维基百科,在线处理意味着数据可以立即用于输入/输出。Nearline是near-online的缩写,意思是数据不是立即可用的,但可以在没有人工干预的情况下快速上线。离线意味着数据不能立即可用,需要一些人工干预才能在线。22
ETL:提取、转换和加载
在关系数据模型的早期,数据大多是结构化的。提取数据时不同的来源,它首先转换为所需的格式,然后再加载到目标目的地,如数据库或数据仓库。这个过程称为ETL,代表提取、转换和加载。
甚至在 ML 之前,ETL 在数据世界中风靡一时,今天它仍然与 ML 应用程序相关。ETL 是指将数据进行通用处理和聚合成您想要的形状和格式。
提取是从所有数据源中提取您想要的数据。其中一些将损坏或格式错误。在提取阶段,您需要验证您的数据并拒绝不符合您要求的数据。对于被拒绝的数据,您可能必须通知来源。由于这是该过程的第一步,因此正确执行可以为您节省大量下游时间。
转换是该过程的主要部分,大部分数据处理都在此完成。您可能想要加入来自多个来源的数据并清理它。您可能希望标准化值范围(例如,一个数据源可能使用“男性”和“女性”作为性别,但另一个使用“M”和“F”或“1”和“2”)。您可以应用诸如转置、去重、排序、聚合、派生新特征、更多数据验证等操作。
加载决定了将转换后的数据加载到目标位置的方式和频率,目标位置可以是文件、数据库或数据仓库。
ETL 的想法听起来简单但功能强大,它是许多组织中数据层的底层结构。ETL 过程的概述如图 3-7所示。
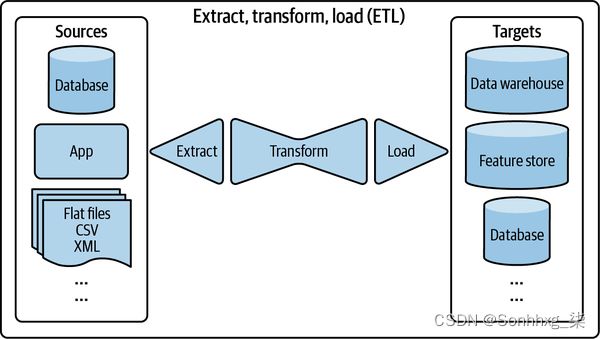
图 3-7。ETL 过程概述
当互联网刚开始无处不在,硬件变得如此强大时,收集数据突然变得如此容易。数据量快速增长。不仅如此,数据的性质也发生了变化。数据源的数量不断增加,数据模式也在不断发展。
发现很难保持数据结构化,一些公司有这样的想法:“为什么不将所有数据存储在数据湖中,这样我们就不必处理架构更改?无论哪个应用程序需要数据,都可以从那里提取原始数据并进行处理。” 这种先将数据加载到存储中然后再对其进行处理的过程有时称为ELT(提取、加载、转换)。这种范例允许数据快速到达,因为在存储数据之前几乎不需要处理。
然而,随着数据的不断增长,这个想法变得不那么有吸引力了。在大量原始数据中搜索您想要的数据是低效的。23与此同时,随着公司转向在云上运行应用程序以及基础设施变得标准化,数据结构也变得标准化。将数据提交到预定义的模式变得更加可行。
随着公司权衡存储结构化数据与存储非结构化数据的利弊,供应商不断发展以提供结合数据湖的灵活性和数据仓库的数据管理方面的混合解决方案。例如,Databricks 和 Snowflake 都提供数据湖库解决方案。
数据流模式
在这一章中,我们一直在讨论数据格式、数据模型、数据存储和数据处理单个进程的上下文。大多数时候,在生产中,您没有一个流程,而是多个流程。出现了一个问题:我们如何在不共享内存的不同进程之间传递数据?
当数据从一个进程传递到另一个进程时,我们说数据从一个进程流向另一个进程,这给了我们一个数据流。数据流的三种主要模式:
-
数据通过数据库
-
使用请求通过服务传递的数据,例如 REST 和 RPC API 提供的请求(例如,POST/GET 请求)
-
通过 Apache Kafka 和 Amazon Kinesis 等实时传输的数据
我们将在本节中逐一介绍。
数据通过数据库
在两者之间传递数据的最简单方法流程是通过数据库进行的,我们在“数据存储引擎和处理”一节中讨论过。例如,要将数据从进程 A 传递到进程 B,进程 A 可以将该数据写入数据库,而进程 B 只需从该数据库中读取。
然而,由于两个原因,这种模式并不总是有效。首先,它要求两个进程必须能够访问同一个数据库。这可能是不可行的,特别是如果这两个流程由两个不同的公司运行。
其次,它需要两个进程来访问数据库中的数据,并且从数据库中读取/写入可能很慢,这使得它不适合具有严格延迟要求的应用程序——例如,几乎所有面向消费者的应用程序。
数据通过服务传递
在两个进程之间传递数据的一种方法是通过连接这两个进程的网络直接发送数据。至将数据从进程 B 传递给进程 A,进程 A 首先向进程 B 发送请求,指定 A 需要的数据,然后 B 通过同一网络返回请求的数据。因为进程通过请求进行通信,所以我们说这是请求驱动的。
这种数据传递模式与面向服务的架构紧密耦合。服务是可以远程访问的进程,例如通过网络。在此示例中,B 作为 A 可以向其发送请求的服务公开给 A。为了使 B 能够从 A 请求数据,A 还需要作为服务向 B 公开。
相互通信的两个服务可以由不同的公司在不同的应用程序中运行。例如,一项服务可能由跟踪当前股票价格的证券交易所运行。另一项服务可能由一家投资公司运行,它请求当前的股票价格并使用它们来预测未来的股票价格。
相互通信的两个服务也可以是同一应用程序的一部分。将应用程序的不同组件构建为单独的服务允许每个组件彼此独立地进行开发、测试和维护。将应用程序构建为单独的服务可为您提供微服务架构。
要将微服务架构置于 ML 系统的上下文中,假设您是一名 ML 工程师,正在为一家拥有 Lyft 等拼车应用程序的公司解决价格优化问题。实际上,Lyft 在其微服务架构中有数百种服务,但为了简单起见,我们只考虑三项服务:
司机管理服务
预测给定区域下一分钟有多少司机可用。
乘车管理服务
预测给定区域下一分钟将请求多少次乘车。
价格优化服务
预测每次骑行的最优价格。打车的价格应该足够低,让乘客愿意支付,但又要足够高,让司机愿意开车,让公司盈利。
因为价格取决于供应(可用的司机)和需求(请求的乘车),价格优化服务需要来自司机管理和乘车管理服务的数据。每次用户请求乘车时,价格优化服务都会请求预测的乘车次数和预计的司机人数,以预测此次乘车的最优价格。24
最流行的请求样式用于通过网络传递数据的方法是 REST(代表性状态传输)和 RPC(远程过程调用)。他们的详细分析超出了本书的范围,但一个主要区别是 REST 是为网络请求而设计的,而 RPC “试图向远程网络服务发出请求,看起来就像在您的编程中调用函数或方法一样语言。” 正因为如此,“REST 似乎是公共 API 的主要风格。RPC 框架的主要关注点是同一组织拥有的服务之间的请求,通常在同一数据中心内。” 25
REST 架构的实现被称为 RESTful。尽管很多人认为 REST 是 HTTP,但 REST 并不确切地说是 HTTP,因为 HTTP 只是 REST 的一种实现。26
数据通过实时传输
了解动机对于实时交通,让我们回到前面的拼车应用示例,其中包含三个简单的服务:司机管理、乘车管理和价格优化。在上一节中,我们讨论了价格优化服务如何需要来自乘车和驾驶员管理服务的数据来预测每次乘车的最优价格。
现在,假设司机管理服务还需要从乘车管理服务中知道乘车次数,才能知道要调动多少司机。它还想知道来自价格优化服务的预测价格,以将其用作对潜在司机的激励(例如,如果您现在上路,您可以获得 2 倍的激增费用)。同样,乘车管理服务也可能需要来自驾驶员管理和价格优化服务的数据。如果我们像上一节中讨论的那样通过服务传递数据,这些服务中的每一个都需要向其他两个服务发送请求,如图 3-8所示。

图 3-8。在请求驱动的架构中,每个服务都需要向另外两个服务发送请求
只有三个服务,数据传递已经变得复杂。想象一下拥有数百甚至数千种服务,就像主要互联网公司所拥有的那样。服务间数据传递可能会爆炸并成为瓶颈,从而减慢整个系统的速度。
请求驱动的数据传递是同步的:目标服务必须侦听请求才能通过。如果价格优化服务向司机管理服务请求数据,而司机管理服务宕机,价格优化服务将不断重发请求,直到超时。如果价格优化服务在收到响应之前就宕机了,那么响应就会丢失。一个服务宕机会导致所有需要它的数据的服务宕机。
如果有一个代理来协调服务之间的数据传递怎么办?与让服务直接相互请求数据并创建复杂的服务间数据传递网络不同,每个服务只需要与代理进行通信,如图 3-9所示。例如,不是让其他服务向驾驶员管理服务请求下一分钟的驾驶员预测数量,而是每当驾驶员管理服务做出预测时,将该预测广播给代理怎么办?无论哪个服务需要来自驱动程序管理服务的数据,都可以检查该代理以获取最新预测的驱动程序数量。同样,只要价格优化服务预测下一分钟的激增费用,该预测就会广播给经纪人。

图 3-9。使用代理,服务只需与代理进行通信,而无需与其他服务进行通信
从技术上讲,数据库可以是代理——每个服务都可以将数据写入数据库,而其他需要数据的服务可以从该数据库中读取数据。但是,正如“数据通过数据库”一节中提到的,对于具有严格延迟要求的应用程序来说,从数据库读取和写入太慢了。我们不是使用数据库来代理数据,而是使用内存存储来代理数据。实时传输可以被认为是服务之间数据传递的内存存储。
向实时传输广播的一段数据称为事件。因此,这种架构也称为事件驱动。实时传输有时称为事件总线。
请求驱动架构适用于更多依赖逻辑而不是数据的系统。事件驱动架构更适合数据量大的系统。
两种最常见的实时传输类型是 pubsub(发布-订阅的缩写)和消息队列。在 pubsub 模型中,任何服务都可以实时传输发布到不同的主题,任何订阅主题的服务都可以读取该主题中的所有事件。产生数据的服务并不关心哪些服务使用它们的数据。Pubsub 解决方案通常有一个保留策略——数据将在实时传输中保留一段时间(例如,7 天),然后才会被删除或移动到永久存储(如 Amazon S3)。请参见图3-10。

图 3-10。传入事件在被丢弃或移动到更永久的存储之前存储在内存中
在消息队列模型中,一个事件通常有目标消费者(有目标消费者的事件称为消息),消息队列负责将消息传递给正确的消费者。
pubsub 解决方案的示例是Apache Kafka 和 Amazon Kinesis。27消息队列的例子有 Apache RocketMQ 和 RabbitMQ。在过去的几年里,这两种范式都获得了很大的关注。图 3-11显示了一些使用 Apache Kafka 和 RabbitMQ 的公司。

图 3-11。使用 Apache Kafka 和 RabbitMQ 的公司。资料来源:Stackshare的截图
批处理与流处理
一旦您的数据到达数据库、数据湖或数据仓库等数据存储引擎,它就会成为历史数据数据。这与流数据(仍在流入的数据)相反。历史数据通常在批处理作业中处理 - 定期启动的作业。例如,每天一次,您可能希望启动批处理作业来计算最后一天所有游乐设施的平均激增费用。
在批处理作业中处理数据时,我们将其称为批处理。几十年来,批处理一直是一个研究主题,公司已经提出了 MapReduce 和 Spark 等分布式系统来有效地处理批处理数据。
当您在 Apache Kafka 和 Amazon Kinesis 等实时传输中拥有数据时,我们说您拥有流式数据。流处理是指对流数据进行计算。流数据的计算也可以定期启动,但周期是通常比批处理作业的周期短得多(例如,每五分钟而不是每天)。每当需要时,也可以启动对流数据的计算。例如,每当用户请求乘车时,您都会处理数据流以查看当前可用的驱动程序。
如果处理得当,流处理可以提供低延迟,因为您可以在生成数据后立即处理数据,而无需先将其写入数据库。许多人认为流处理的效率低于批处理,因为您无法利用 MapReduce 或 Spark 等工具。情况并非总是如此,原因有两个。首先,Apache Flink 等流技术被证明具有高度可扩展性和完全分布式,这意味着它们可以并行进行计算。其次,流处理的优势在于有状态计算。考虑您希望在 30 天试用期间处理用户参与度的情况。如果您每天都开始这个批处理作业,那么您必须每天在过去 30 天内进行计算。通过流处理,
由于批处理的发生频率远低于流处理,因此在 ML 中,批处理通常用于计算变化较少的特征,例如司机的评分(如果司机有数百次骑行,他们的评分不太可能发生显着变化从一天到下一天)。批量特征——通过批处理提取的特征——也称为静态特征。
流处理用于计算快速变化的特征,例如现在有多少司机可用,最后一分钟请求了多少乘车,接下来两分钟将完成多少乘车,最后一趟的中位数价格该区域有 10 个游乐设施,等等。这些关于系统当前状态的特征对于做出最佳价格预测很重要。流特征——通过流处理提取的特征——也称为动态特征。
对于许多问题,您不仅需要批处理功能或流功能,而且两者都需要。您需要能够处理流数据和批处理数据并将它们连接在一起以输入 ML 模型的基础架构。我们将在第 7 章讨论更多关于如何将批特征和流特征一起使用来生成预测的内容。
要对数据流进行计算,您需要一个流计算引擎(就像 Spark 和 MapReduce 是批处理计算引擎一样)。对于简单的流计算,你可能可以摆脱 Apache Kafka 等实时传输的内置流计算能力,但 Kafka 流处理在处理各种数据源的能力方面受到限制。
对于利用流式特征的 ML 系统,流式计算很少是简单的。应用程序中使用的流功能(例如欺诈检测和信用评分)的数量可能达到数百甚至数千。流特征提取逻辑可能需要沿不同维度进行连接和聚合的复杂查询。提取这些特征需要高效的流处理引擎。为此,您可能需要研究 Apache Flink、KSQL 和 Spark Streaming 等工具。在这三个引擎中,Apache Flink 和 KSQL 更受业界认可,为数据科学家提供了很好的 SQL 抽象。
流处理更加困难,因为数据量是无限的,并且数据以可变的速率和速度进入。让流处理器做批处理比让批处理处理器做流处理更容易。Apache Flink 的核心维护者已经多年来一直争论批处理是流处理的特例。28
概括
本章建立在第 2 章围绕数据在开发 ML 系统中的重要性所建立的基础之上。在本章中,我们了解到选择正确的格式来存储我们的数据以使将来更容易使用数据非常重要。我们讨论了不同的数据格式以及行主要格式与列主要格式以及文本与二进制格式的优缺点。
我们继续介绍三种主要的数据模型:关系、文档和图形。尽管鉴于 SQL 的流行,关系模型是最著名的,但这三种模型今天都被广泛使用,并且每种模型都适用于特定的一组任务。
当谈到与文档模型相比的关系模型时,许多人认为前者是结构化的,而后者是非结构化的。结构化数据和非结构化数据之间的划分非常不稳定——主要问题是谁必须承担承担数据结构的责任。结构化数据意味着写入数据的代码必须采用该结构。非结构化数据意味着读取数据的代码必须采用结构。
我们继续本章的数据存储引擎和处理。我们研究了针对两种不同类型的数据处理优化的数据库:事务处理和分析处理。我们一起研究了数据存储引擎和处理,因为传统上存储与处理相结合:用于事务处理的事务数据库和用于分析处理的分析数据库。然而,近年来,许多供应商都致力于将存储和处理解耦。今天,我们拥有可以处理分析查询的事务数据库和可以处理事务查询的分析数据库。
在讨论数据格式、数据模型、数据存储引擎和处理时,假设数据位于流程中。但是,在生产中工作时,您可能会使用多个流程,并且您可能需要在它们之间传输数据。我们讨论了三种数据传递模式。最简单的模式是通过数据库。流程中最流行的数据传递模式是通过服务传递数据。在这种模式下,一个进程被公开为另一个进程可以发送数据请求的服务。这种数据传递模式与微服务架构紧密耦合,其中应用程序的每个组件都设置为服务。
在过去十年中变得越来越流行的一种数据传递模式是通过 Apache Kafka 和 RabbitMQ 等实时传输进行数据传递。这种数据传递模式介于通过数据库和通过服务之间:它允许异步数据以相当低的延迟传递。
由于实时传输中的数据与数据库中的数据具有不同的属性,因此它们需要不同的处理技术,如“批处理与流处理”一节中所述。数据库中的数据通常在批处理作业中处理并产生静态特征,而实时传输中的数据通常使用流计算引擎处理并产生动态特征。有人认为批处理是流处理的一种特殊情况,流计算引擎可以用来统一两个处理管道。