CramNet: Camera-Radar Fusion with Ray-Constrained Cross-Attention for Robust 3D Object Detection论文笔记
原文链接:https://arxiv.org/abs/2210.09267
1.引言
图像和平面雷达在相互垂直的维度上缺失了信息:图像缺乏深度信息而雷达缺乏高度(俯仰角)信息,这使得相机数据与雷达数据的对应属于多对多的关系,仅靠几何条件难以找到准确的匹配。
本文提出3种可能的融合方案:
- 以透视图为主:相信图像的深度估计,将图像提升到3D空间,然后寻找最近的雷达点(不考虑高度);若未知深度,则将像素投影为射线,然后进行匹配。
- 以鸟瞰图为主:相信雷达的俯仰角估计;但从雷达图像很难直接估计俯仰角,可借助地图得到俯仰角信息;因此雷达的俯仰角通常不准确。
- 跨视图匹配:使用地图或深度估计提升雷达图像像素与RGB图像像素,然后在联合3D空间进行匹配。
本文设计的CramNet使得第三种方案成为可能。
本文提出射线约束的交叉注意力机制,利用雷达得到更好的深度估计:将雷达响应与像素射线匹配,正确的像素投影位置应该是存在雷达反射的位置。此外,本文在训练阶段的融合处使用模态丢弃(dropout),使得模型能在某一模态失效时工作。
2.相关工作
基于雷达的3D目标检测:调频连续波(FMCW)雷达通常有两种表达:射频(RF)图像和雷达点云。RF图像通常是使用原始雷达信号进行快速傅里叶变换得到,而雷达点云则是通过在RF图像检测峰值(如使用恒定虚警率(CFAR)算法)得到。雷达点云的召回率不够高,且损失了上下文信息,因此可能不适合单一模态的检测。本文使用RF图像进行检测,即便是单一模态也有较好的性能。
3.用于鲁棒3D目标检测的CramNet
3.1 总体结构
如图所示,本文的方法分为3个阶段:2D前景分割、2D到3D的投影和点云融合、以及3D前景点云检测。

阶段1:2D前景分割。该步骤能将耗昂贵的3D操作限制在前景点上。具体来说,输入RGB图像(![]() )和RF图像(
)和RF图像(![]() ),使用相同的轻型U-Net提取2D特征,预测前景分割掩膜
),使用相同的轻型U-Net提取2D特征,预测前景分割掩膜![]() 和
和![]() 。对于图像特征提取还可使用更强大的多尺度特征提取器(如FPN)。
。对于图像特征提取还可使用更强大的多尺度特征提取器(如FPN)。
训练时,使用3D边界框的2D投影作为真实前景。并使用focal损失分类:

其中 为像素总数,
为像素总数,![]() 和
和![]() 是前景和背景像素的集合,
是前景和背景像素的集合, 是像素
是像素 属于前景像素的预测概率,
属于前景像素的预测概率,![]() 为控制惩罚的超参数。前景预测概率大于阈值
为控制惩罚的超参数。前景预测概率大于阈值 的像素会被视为前景,其中设置得较小以获得高召回率,因为下一步能处理FP而不能恢复FN。
的像素会被视为前景,其中设置得较小以获得高召回率,因为下一步能处理FP而不能恢复FN。
阶段2:2D到3D投影和点云融合。 将预测的前景点投影到3D空间。对于图像,使用额外的卷积预测像素深度,其中深度真值从投影到图像上的 激光雷达点云和3D边界框 获得。投影3D边界框的原因是激光雷达点云可能不够提供充分的深度信息(如超出激光雷达范围、受到天气影响等等)。训练时,在有效区域使用L2损失(称为![]() )估计深度,并依靠相机内外参投影到3D空间。
)估计深度,并依靠相机内外参投影到3D空间。
对于雷达,使用传感器高度作为点的高度,将雷达点云转换到3D空间。若存在地图信息,可以加上道路高度以处理非平面场景(如山丘)。
3D点云的融合方法中,选择一种模态作为主要传感器并从其余模态收集特征 这一方法最为常用,但主要传感器失效会导致模型失效。本文直接在联合3D空间中放置两种点云并为每个点附加模态编码。这样,一种模态失效时仍可进行检测。
阶段3:3D前景点云检测。对融合点云使用动态柱体化/体素化,然后使用2D/3D稀疏卷积。最后仿照RSN的方法预测边界框。
真实的中心性热图中,点 处的值为:
处的值为:
![]()
其中![]() 是包含的边界框的中心的集合,
是包含的边界框的中心的集合,![]() 是与边界框中心
是与边界框中心 最近的点,
最近的点, 是常数。因此,点的中心性与其到最近边界框中心的距离成反比。
是常数。因此,点的中心性与其到最近边界框中心的距离成反比。
使用focal损失预测热图:
其中![]() 是指示函数,
是指示函数, 和
和![]() 分别是预测和真实热图,
分别是预测和真实热图,![]() 决定了真实中心性的阈值,
决定了真实中心性的阈值,![]() 和
和![]() 为超参数。
为超参数。
3D边界框被参数化为![]() ,即边界框中心相对体素中心的偏移量、长宽高和朝向角。除朝向角使用区间损失外,其余各项均使用SmoothL1损失训练。此外还引入IoU损失以提高检测精度。具体的细节见RSN模型的文章;总的边界框损失为:
,即边界框中心相对体素中心的偏移量、长宽高和朝向角。除朝向角使用区间损失外,其余各项均使用SmoothL1损失训练。此外还引入IoU损失以提高检测精度。具体的细节见RSN模型的文章;总的边界框损失为:
其中 是真实热图值大于阈值
是真实热图值大于阈值![]() 的边界框数,
的边界框数,![]() (
( )和
)和![]() (
(![]() )分别是真实和预测边界框(朝向角)。
)分别是真实和预测边界框(朝向角)。
整个模型被端到端训练,总的损失函数为
![]()
3.2 射线约束的交叉注意力
本文提出使用射线约束的交叉注意力机制提高图像的深度估计精度,如下图所示。

本文观察到图像前景像素对应的最优3D位置通常伴随着雷达响应的峰值,因此使用沿着像素射线的雷达特征修正估计的深度。具体来说,先沿着像素射线,以估计深度为中心采样雷达特征,最终的3D位置就由像素特征和这些雷达特征的匹配来确定。
设像素的估计深度为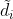 ,对应的3D位置为
,对应的3D位置为![]() 。首先沿着像素射线,以
。首先沿着像素射线,以![]() 为中心采样
为中心采样![]() 个点,即
个点,即![]() ,其中
,其中 为深度误差超参数,而
为深度误差超参数,而 从1变化到
从1变化到 。这样,得到采样点集
。这样,得到采样点集![]() 。然后采样相应位置的雷达特征
。然后采样相应位置的雷达特征![]() 。该图像像素的特征记为
。该图像像素的特征记为![]() 。最终的3D位置
。最终的3D位置![]() 由交叉注意力机制得到:
由交叉注意力机制得到:
![]()
其中像素特征![]() 为查询,采样的雷达特征集合
为查询,采样的雷达特征集合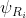 为键,而采样的3D点集
为键,而采样的3D点集![]() 为值。因此最终位置是通过将查询与最活跃的键匹配,并与相应的值关联得到的。
为值。因此最终位置是通过将查询与最活跃的键匹配,并与相应的值关联得到的。
这一操作的时间复杂度近似与![]() 成比例,其中为前景点数且很小,因此该操作是很便宜的。
成比例,其中为前景点数且很小,因此该操作是很便宜的。
3.3 传感器丢弃
在训练时使用传感器丢弃机制以应对传感器失效问题。具体来说,设 与
与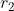 是两个
是两个![[0,1]](http://img.e-com-net.com/image/info8/8777b12420fe47dea8295caddad6bdb6.gif) 范围内的随机数,
范围内的随机数,![]() 为丢弃概率,
为丢弃概率,![]() 与
与![]() 为第二阶段各模态生成的点云,则在训练时:
为第二阶段各模态生成的点云,则在训练时:
![]()
![]()
其中![]() 为零矩阵。
为零矩阵。
仅在融合时丢弃模态的原因是需要正常训练交叉注意力机制。若在测试时,雷达有很强的噪声,会导致均匀的注意力图,几乎不会对图像像素的3D位置产生影响。
4.实验
4.1 数据集与评估
本文使用RADIATE数据集。
评估:仅评估那些同时出现在雷达图像与RGB图像中的物体,且最大范围为100m。对相机单一模态的实验,不考虑那些不包含激光雷达点的物体(超过70m),因为激光雷达测量范围外的深度估计是不准确的。
4.2 实施细节
训练与推断:不使用2D数据增广,而是使用3D数据增广(包含x轴翻转和绕z轴旋转点云)。
4.3 在RADIATE数据集上的性能
实验表明,本文仅使用雷达的方法(相应的模型称为CramNet-R)性能较好,因为模型能在分割时有效过滤雷达噪声,然后在后续阶段关注剩下的雷达信号。而仅使用图像的方法(相应的模型称为CramNet-C)性能很差,因为:
- 极端天气对相机的影响比雷达更严重;
- 在极端天气下,用于深度监督的激光雷达的有效范围严重下降。
第4.5节的实验表明,在Waymo Open数据集上,本文的CramNet-C方法性能与其余方法相当。
本文的融合方法能进一步超过CramNet-R的性能,表明融合的有效性。
4.4 消融研究
射线约束交叉注意力和传感器丢弃的作用:实验表明,去掉二者任意一个均会带来明显的性能下降。
雷达图像的作用:本文将雷达图像根据不同的强度阈值过滤,得到不同数量的雷达点云,但实验表明性能有非常严重的下降。因此雷达的RF图像包含了对3D目标检测关键的信息。
4.5 检测鲁棒性
丢弃传感器数据的位置:本文实验了在不同位置丢弃传感器数据时模型的性能,包含“输入”(在输入处就完全丢弃某个模态)、“常规”(随机丢弃一些点而不管其来自哪个传感器)、“点云”(在融合点云时完全丢弃某个模态)、“点的特征”(丢弃来自某传感器的点的特征,仅保留其位置)。实验表明上述丢弃设置的性能依次增加。最后一种方法的性能最好的原因可能是:
- 减小了网络对特征的依赖性,因为特征受噪声的影响最大;
- 保留了2D特征提取器和交叉注意力机制的训练。
虽然未在此处提出,但本文在其它地方表示,RADIATE数据集的图像质量相对较差也是原因之一。
传感器丢弃提高了对输入损坏的鲁棒性:为相机图像添加不同方差的高斯白噪声后,使用传感器丢弃训练的模型比不使用传感器丢弃的模型性能更高,且噪声越大,性能差异越大。
4.7 可视化
仅基于图像的方法会导致漏检以及不准确的定位;仅基于雷达的方法会因为缺少外观信息导致误检;基于融合的方法则融合了二者优势,提供了最准确的检测。
5.结论
局限性:图像的一个像素对应3D空间中的一条射线,而雷达读数(范围,水平角)对应3D空间中的一个弧。像素射线与雷达的弧相交能得到其对应关系,但目前本文的方法使用笛卡尔坐标表达雷达图像,可能不能达到最优。也许可以使用极坐标表达雷达信号并使用极卷积网络和球形体素化。
A.附录
A.1 在Waymo Open数据集上的实验
实验表明本文的CramNet-C方法在远距离检测的性能远高于SotA,这表明本文先进行前景分割的方案能更有效地处理远距离物体,而无需处理深度估计的不确定性。
A.2 关于延迟与前景阈值的消融研究
预期的情况是,设置较低的前景阈值能带来更好的性能,但会增加模型的延迟。
但实验表明,更低的前景阈值会导致更低的延迟。
A.3 关于融合超参数的消融研究
总的来说,模型对融合超参数不太敏感。模型的性能随深度误差的增大先增大后减小,且仅需少量采样点。
随着传感器丢弃概率的增大,模型的性能同样先增后减。这说明太频繁地丢弃传感器数据同样对模型不利。
去掉模态编码会使得模型有较大的性能下降,这表明模态编码是模型能够分辨不同传感器特征的关键。