6.基于深度学习的轴承故障诊断--傅里叶变换fft
该专栏将较为详细的介绍如何利用深度学习进行故障诊断方面的学术研究,主要以轴承为例,包括深度学习常用框架Tensorflow的搭建以及使用,并会记录完整搭建过程,并以卷积神经网络与循环神经网络为例进行代码编写和实际运行,相信经过本次学习,你能够入门开始着手研究。
完成该专栏的学习,你将会收获以下知识:
1.Anaconda的安装以及使用,深度学习框架Tensorflow2的安装以及使用
2.学会如何利用卷积神经网络与循环神经网络进行轴承故障诊断-以凯斯西楚大学轴承数据集为例
3.学会一些常用调参技巧
4.入门利用深度学习进行故障诊断的学术研究
说明:
1.专栏所涉及代码会全部公开在本人的github上,欢迎交流以及star。
https://github.com/boating-in-autumn-rain?tab=repositories
2.该专栏涉及数据集以及相关安装包在公众号《秋雨行舟》回复轴承即可领取。
3.对于该项目有疑问的可以公众号留言,看到了就会回复。
4.该专栏对应的视频可在B站搜索《秋雨行舟》进行观看学习。
1维卷积进行分类实验:
# 博客:https://blog.csdn.net/qq_38918049/article/details/124948664?spm=1001.2014.3001.5501
# github:https://github.com/boating-in-autumn-rain?tab=repositories
# 微信公众号:秋雨行舟
# B站:秋雨行舟
#
# 该项目涉及数据集以及相关安装包在公众号《秋雨行舟》回复轴承即可领取。
# 对于该项目有疑问的可以在上述四个平台中留言,看到了就会回复。
# 该项目对应的视频可在B站搜索《秋雨行舟》进行观看学习。
# 欢迎交流学习,共同进步
from tensorflow import keras
from sklearn.metrics import confusion_matrix
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
from datetime import datetime
from tensorflow_core.python.keras import layers
import tensorflow as tf
#如果是GPU,需要去掉注释,如果是CPU,则注释
# gpu = tf.config.experimental.list_physical_devices(device_type='GPU')
# assert len(gpu) == 1
# tf.config.experimental.set_memory_growth(gpu[0], True)
import random
import matplotlib.pyplot as plt
from scipy.fftpack import fft
import numpy as np
from fft.preprocess import prepro
def fft_data():
length = 784
number = 300 # 每类样本的数量
normal = True # 是否标准化
rate = [0.5, 0.25, 0.25] # 测试集验证集划分比例
path = r'../sign/data/0HP'
x_train, y_train, x_valid, y_valid, x_test, y_test = prepro(
d_path=path,
length=length,
number=number,
normal=normal,
rate=rate,
enc=False, enc_step=28)
y_valid, y_test = y_valid[:, np.newaxis], y_test[:, np.newaxis]
x_test = np.vstack((x_valid, x_test))
y_test = np.vstack((y_valid, y_test))
x_train = np.array(x_train)
y_train = np.array(y_train)
x_test = np.array(x_test)
y_test = np.array(y_test)
y_test = np.squeeze(y_test)
return x_train, y_train, x_valid, y_valid, x_test, y_test
def fft_transform():
x_train0, y_train0, x_valid0, y_valid0, x_test0, y_test0 = fft_data()
x_train1 = []
x_valid1 = []
x_test1 = []
N = 784
for i in range(len(x_train0)):
y1 = x_train0[i]
yf1 = abs(fft(y1)) / N # 归一化处理
yf2 = yf1[range(int(len(yf1) / 2))] # 由于对称性,只取一半区间
# yf2 = yf1[range(N)]
x_train1.append(yf2)
for i in range(len(x_valid0)):
y2 = x_valid0[i]
yf3 = abs(fft(y2)) / N # 归一化处理
yf4 = yf3[range(int(len(yf1) / 2))] # 由于对称性,只取一半区间
# yf4 = yf3[range(N)]
x_valid1.append(yf4)
for i in range(len(x_test0)):
y2 = x_test0[i]
yf3 = abs(fft(y2)) / N # 归一化处理
yf4 = yf3[range(int(len(yf1) / 2))] # 由于对称性,只取一半区间
# yf4 = yf3[range(N)]
x_test1.append(yf4)
x_train3 = np.array(x_train1)
x_valid3 = np.array(x_valid1)
x_test3 = np.array(x_test1)
return x_train3, y_train0, x_valid3, y_valid0, x_test3, y_test0
x_train, y_train, x_valid, y_valid, x_test, y_test = fft_transform()
# 绘制FFT结果
# plt.plot(x_train[0])
# plt.title('FFT of Mixed wave)', fontsize=10, color='#F08080')
# plt.show()
print(x_train.shape)
print(x_valid.shape)
print(x_test.shape)
print(y_train.shape)
print(y_valid.shape)
print(y_test.shape)
y_train = [int(i) for i in y_train]
y_valid = [int(i) for i in y_valid]
y_test = [int(i) for i in y_test]
# 打乱顺序
index = [i for i in range(len(x_train))]
random.seed(1)
random.shuffle(index)
x_train = np.array(x_train)[index]
y_train = np.array(y_train)[index]
index1 = [i for i in range(len(x_valid))]
random.shuffle(index1)
x_valid = np.array(x_valid)[index1]
y_valid = np.array(y_valid)[index1]
index2 = [i for i in range(len(x_test))]
random.shuffle(index2)
x_test = np.array(x_test)[index2]
y_test = np.array(y_test)[index2]
print(x_train.shape)
print(x_valid.shape)
print(x_test.shape)
print(y_train)
print(y_valid)
print(y_test)
print("x_train的最大值和最小值:", x_train.max(), x_train.min())
print("x_test的最大值和最小值:", x_test.max(), x_test.min())
x_train = tf.reshape(x_train, (len(x_train), 392, 1))
x_valid = tf.reshape(x_valid, (len(x_valid), 392, 1))
x_test = tf.reshape(x_test, (len(x_test), 392, 1))
# 保存最佳模型
class CustomModelCheckpoint(keras.callbacks.Callback):
def __init__(self, model, path):
self.model = model
self.path = path
self.best_loss = np.inf
def on_epoch_end(self, epoch, logs=None):
val_loss = logs['val_loss']
if val_loss < self.best_loss:
print("\nValidation loss decreased from {} to {}, saving model".format(self.best_loss, val_loss))
self.model.save_weights(self.path, overwrite=True)
self.best_loss = val_loss
# 模型定义
def mymodel():
inputs = keras.Input(shape=(x_train.shape[1], x_train.shape[2]))
h1 = layers.Conv1D(filters=8, kernel_size=3, strides=1, padding='same', activation='relu')(inputs)
h1 = layers.MaxPool1D(pool_size=2, strides=2, padding='same')(h1)
h1 = layers.Conv1D(filters=16, kernel_size=3, strides=1, padding='same', activation='relu')(h1)
h1 = layers.MaxPool1D(pool_size=2, strides=2, padding='same')(h1)
h1 = layers.Flatten()(h1)
h1 = layers.Dropout(0.6)(h1)
h1 = layers.Dense(32, activation='relu')(h1)
h1 = layers.Dense(10, activation='softmax')(h1)
deep_model = keras.Model(inputs, h1, name="cnn")
return deep_model
model = mymodel()
model.summary()
startdate = datetime.utcnow() # 获取当前时间
# 编译模型
model.compile(
optimizer=keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=256, epochs=50, verbose=1,
validation_data=(x_valid, y_valid),
callbacks=[CustomModelCheckpoint(
model, r'best_fft_1dcnn.h5')])
#加载模型
model.load_weights(filepath='best_fft_1dcnn.h5')
# 编译模型
model.compile(loss='sparse_categorical_crossentropy', optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
# 评估模型
scores = model.evaluate(x_test, y_test, verbose=1)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
y_predict = model.predict(x_test)
y_pred_int = np.argmax(y_predict, axis=1)
print(y_pred_int[0:5])
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_int, digits=4))
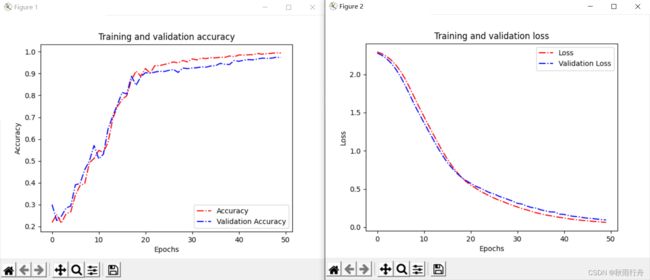
def acc_line():
# 绘制acc和loss曲线
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc)) # Get number of epochs
# 画accuracy曲线
plt.plot(epochs, acc, 'r', linestyle='-.')
plt.plot(epochs, val_acc, 'b', linestyle='dashdot')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(["Accuracy", "Validation Accuracy"])
plt.figure()
# 画loss曲线
plt.plot(epochs, loss, 'r', linestyle='-.')
plt.plot(epochs, val_loss, 'b', linestyle='dashdot')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(["Loss", "Validation Loss"])
# plt.figure()
plt.show()
acc_line()
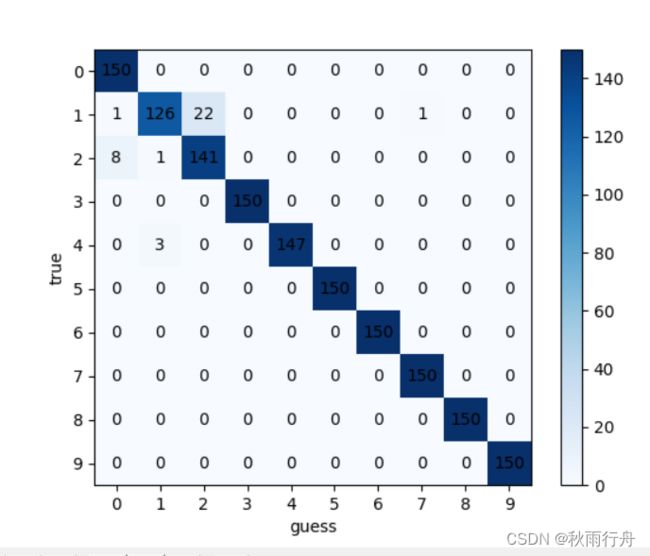
# 绘制混淆矩阵
def confusion():
y_pred_gailv = model.predict(x_test, verbose=1)
y_pred_int = np.argmax(y_pred_gailv, axis=1)
print(len(y_pred_int))
con_mat = confusion_matrix(y_test.astype(str), y_pred_int.astype(str))
print(con_mat)
classes = list(set(y_train))
classes.sort()
plt.imshow(con_mat, cmap=plt.cm.Blues)
indices = range(len(con_mat))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('guess')
plt.ylabel('true')
for first_index in range(len(con_mat)):
for second_index in range(len(con_mat[first_index])):
plt.text(first_index, second_index, con_mat[second_index][first_index], va='center', ha='center')
plt.show()
confusion()二维卷积进行分类实验:
# 博客:https://blog.csdn.net/qq_38918049/article/details/124948664?spm=1001.2014.3001.5501
# github:https://github.com/boating-in-autumn-rain?tab=repositories
# 微信公众号:秋雨行舟
# B站:秋雨行舟
#
# 该项目涉及数据集以及相关安装包在公众号《秋雨行舟》回复轴承即可领取。
# 对于该项目有疑问的可以在上述四个平台中留言,看到了就会回复。
# 该项目对应的视频可在B站搜索《秋雨行舟》进行观看学习。
# 欢迎交流学习,共同进步
from tensorflow import keras
from sklearn.metrics import confusion_matrix
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
from datetime import datetime
from tensorflow_core.python.keras import layers
import tensorflow as tf
#如果是GPU,需要去掉注释,如果是CPU,则注释
# gpu = tf.config.experimental.list_physical_devices(device_type='GPU')
# assert len(gpu) == 1
# tf.config.experimental.set_memory_growth(gpu[0], True)
import random
import matplotlib.pyplot as plt
from scipy.fftpack import fft
import numpy as np
from fft.preprocess import prepro
def fft_data():
length = 784
number = 300 # 每类样本的数量
normal = True # 是否标准化
rate = [0.5, 0.25, 0.25] # 测试集验证集划分比例
path = r'../sign/data/0HP'
x_train, y_train, x_valid, y_valid, x_test, y_test = prepro(
d_path=path,
length=length,
number=number,
normal=normal,
rate=rate,
enc=False, enc_step=28)
y_valid, y_test = y_valid[:, np.newaxis], y_test[:, np.newaxis]
x_test = np.vstack((x_valid, x_test))
y_test = np.vstack((y_valid, y_test))
x_train = np.array(x_train)
y_train = np.array(y_train)
x_test = np.array(x_test)
y_test = np.array(y_test)
y_test = np.squeeze(y_test)
return x_train, y_train, x_valid, y_valid, x_test, y_test
def fft_transform():
x_train0, y_train0, x_valid0, y_valid0, x_test0, y_test0 = fft_data()
x_train1 = []
x_valid1 = []
x_test1 = []
N = 784
for i in range(len(x_train0)):
y1 = x_train0[i]
yf1 = abs(fft(y1)) / N # 归一化处理
# yf2 = yf1[range(int(len(yf1) / 2))] # 由于对称性,只取一半区间
yf2 = yf1[range(N)]
x_train1.append(yf2)
for i in range(len(x_valid0)):
y2 = x_valid0[i]
yf3 = abs(fft(y2)) / N # 归一化处理
# yf4 = yf3[range(int(len(yf1) / 2))] # 由于对称性,只取一半区间
yf4 = yf3[range(N)]
x_valid1.append(yf4)
for i in range(len(x_test0)):
y2 = x_test0[i]
yf3 = abs(fft(y2)) / N # 归一化处理
# yf4 = yf3[range(int(len(yf1) / 2))] # 由于对称性,只取一半区间
yf4 = yf3[range(N)]
x_test1.append(yf4)
x_train3 = np.array(x_train1)
x_valid3 = np.array(x_valid1)
x_test3 = np.array(x_test1)
return x_train3, y_train0, x_valid3, y_valid0, x_test3, y_test0
x_train, y_train, x_valid, y_valid, x_test, y_test = fft_transform()
# 绘制FFT结果
# plt.plot(x_train[0])
# plt.title('FFT of Mixed wave)', fontsize=10, color='#F08080')
# plt.show()
print(x_train.shape)
print(x_valid.shape)
print(x_test.shape)
print(y_train.shape)
print(y_valid.shape)
print(y_test.shape)
y_train = [int(i) for i in y_train]
y_valid = [int(i) for i in y_valid]
y_test = [int(i) for i in y_test]
# 打乱顺序
index = [i for i in range(len(x_train))]
random.seed(1)
random.shuffle(index)
x_train = np.array(x_train)[index]
y_train = np.array(y_train)[index]
index1 = [i for i in range(len(x_valid))]
random.shuffle(index1)
x_valid = np.array(x_valid)[index1]
y_valid = np.array(y_valid)[index1]
index2 = [i for i in range(len(x_test))]
random.shuffle(index2)
x_test = np.array(x_test)[index2]
y_test = np.array(y_test)[index2]
print(x_train.shape)
print(x_valid.shape)
print(x_test.shape)
print(y_train)
print(y_valid)
print(y_test)
print("x_train的最大值和最小值:", x_train.max(), x_train.min())
print("x_test的最大值和最小值:", x_test.max(), x_test.min())
x_train = tf.reshape(x_train, (len(x_train), 28, 28, 1))
x_valid = tf.reshape(x_valid, (len(x_valid), 28, 28, 1))
x_test = tf.reshape(x_test, (len(x_test), 28, 28, 1))
# 保存最佳模型
class CustomModelCheckpoint(keras.callbacks.Callback):
def __init__(self, model, path):
self.model = model
self.path = path
self.best_loss = np.inf
def on_epoch_end(self, epoch, logs=None):
val_loss = logs['val_loss']
if val_loss < self.best_loss:
print("\nValidation loss decreased from {} to {}, saving model".format(self.best_loss, val_loss))
self.model.save_weights(self.path, overwrite=True)
self.best_loss = val_loss
def mymodel():
inputs = keras.Input(shape=(x_train.shape[1], x_train.shape[2], x_train.shape[3]))
h1 = layers.Conv2D(filters=8, kernel_size=(3, 3), strides=(1,1), padding='same', activation='relu')(inputs)
h1 = layers.MaxPool2D(pool_size=(2,2), strides=(2, 2), padding='same')(h1)
h1 = layers.Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu')(h1)
h1 = layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='same')(h1)
h1 = layers.Flatten()(h1)
h1 = layers.Dense(32, activation='relu')(h1)
h1 = layers.Dense(10, activation='softmax')(h1)
deep_model = keras.Model(inputs, h1, name="cnn")
return deep_model
model = mymodel()
model.summary()
startdate = datetime.utcnow() # 获取当前时间
# 编译模型
model.compile(
optimizer=keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=256, epochs=50, verbose=1,
validation_data=(x_valid, y_valid),
callbacks=[CustomModelCheckpoint(
model, r'best_fft_2dcnn.h5')])
#加载模型
model.load_weights(filepath='best_fft_2dcnn.h5')
# 编译模型
model.compile(loss='sparse_categorical_crossentropy', optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
# 评估模型
scores = model.evaluate(x_test, y_test, verbose=1)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
y_predict = model.predict(x_test)
y_pred_int = np.argmax(y_predict, axis=1)
# print(y_pred_int[0:5])
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_int, digits=4))
def acc_line():
# 绘制acc和loss曲线
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc)) # Get number of epochs
# 画accuracy曲线
plt.plot(epochs, acc, 'r', linestyle='-.')
plt.plot(epochs, val_acc, 'b', linestyle='dashdot')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(["Accuracy", "Validation Accuracy"])
plt.figure()
# 画loss曲线
plt.plot(epochs, loss, 'r', linestyle='-.')
plt.plot(epochs, val_loss, 'b', linestyle='dashdot')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(["Loss", "Validation Loss"])
plt.show()
acc_line()
# 绘制混淆矩阵
def confusion():
y_pred_gailv = model.predict(x_test, verbose=1)
y_pred_int = np.argmax(y_pred_gailv, axis=1)
print(len(y_pred_int))
con_mat = confusion_matrix(y_test.astype(str), y_pred_int.astype(str))
print(con_mat)
classes = list(set(y_train))
classes.sort()
plt.imshow(con_mat, cmap=plt.cm.Blues)
indices = range(len(con_mat))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('guess')
plt.ylabel('true')
for first_index in range(len(con_mat)):
for second_index in range(len(con_mat[first_index])):
plt.text(first_index, second_index, con_mat[second_index][first_index], va='center', ha='center')
plt.show()
confusion()
实验截图:
傅里叶变换结果:

准确率与损失值截图:
混淆矩阵: