NNDL 实验六 残差网络实现CIFAR10
-
- 5.5 实践:基于ResNet18网络完成图像分类任务
-
- 5.5.1 数据处理
-
- 5.5.1.1 数据集介绍
- 5.5.1.2 数据读取
- 5.5.1.3 构造Dataset类
- 5.5.2 模型构建
-
- 什么是“预训练模型”?什么是“迁移学习”?(必做)
- 5.5.3 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
- 对比
- 5.5.4 模型评价
- 5.5.5 模型预测
- 用自己的话简单评价LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
-
- LeNet
- AlexNet
- VggNet
- GoogLeNet
- ResNet
- 总结:
- 参考
5.5 实践:基于ResNet18网络完成图像分类任务
在本实践中,我们实践一个更通用的图像分类任务。
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
这里,我们使用的计算机视觉领域的经典数据集:CIFAR-10数据集,网络为ResNet18模型,损失函数为交叉熵损失,优化器为Adam优化器,评价指标为准确率。
Adam优化器的介绍参考《神经网络与深度学习》第7.2.4.3节。
5.5.1 数据处理
5.5.1.1 数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为 32 × 32 32\times32 32×32像素。CIFAR-10数据集的示例如 图5.15 所示。

图5.15:CIFAR-10数据集示例
将数据集文件进行解压:直接将文件加入到kaggle,kaggle自动解压

5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_'+str(batch_id))
# 加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding = 'latin1')
imgs = batch['data'].reshape((len(batch['data']),3,32,32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path='/kaggle/input/cifar10data/cifar-10-batches-py/',
batch_id=1, mode='train')
查看数据的维度:
# 打印一下每个batch中X和y的维度
print ("batch of imgs shape: ",imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
![]()
可视化观察其中的一张样本图像和对应的标签,代码如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1,2,0))
plt.savefig('cnn-car.pdf')

5.5.1.3 构造Dataset类
构造一个CIFAR10Dataset类,其将继承自paddle.io.Dataset类,可以逐个数据进行处理。代码实现如下:
import torch
from torchvision.transforms import Normalize
class CIFAR10Dataset(torch.utils.data.DataLoader):
def __init__(self, folder_path='/kaggle/input/cifar10data/cifar-10-batches-py', mode='train'):
if mode == 'train':
# 加载batch1-batch4作为训练集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate([self.labels, labels_batch])
elif mode == 'dev':
# 加载batch5作为验证集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
# 加载测试集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path='/kaggle/input/cifar10data/cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='/kaggle/input/cifar10data/cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='/kaggle/input/cifar10data/cifar-10-batches-py', mode='test')
5.5.2 模型构建
对于Reset18这种比较经典的图像分类网络,飞桨高层API中都为大家提供了实现好的版本,大家可以不再从头开始实现。这里首先使用飞桨高层API中的Resnet18进行图像分类实验。
什么是“预训练模型”?什么是“迁移学习”?(必做)
参考:迁移学习,顾名思义,就是要进行迁移。放到人工智能和机器学习的学科里,迁移学习是一种学习的思想和模式。
首先机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可顺利地实现知识的迁移。

结合我认为的迁移学习,举一个例子,我认为迁移学习,就是将一个问题的解决方法迁移到另一个相似的问题中去,例如,当我们在玩DOTA玩的很熟的时候,然后我紧接着去玩LOL,我们就会自己玩的很熟,因为DOTA和LOL都是MOBA类游戏,这也证实了为什么好多英雄联盟的选手,是从DOTA和魔兽争霸转移过来的。
参考:预训练模型可以把迁移学习很好地用起来。这和小孩读书一样,一开始语文、数学、化学都学,读书、网上游戏等,在脑子里积攒了很多。当他学习计算机时,实际上把他以前学到的所有知识都带进去了。如果他以前没上过中学,没上过小学,突然学计算机就不懂这里有什么道理。这和我们预训练模型一样,预训练模型就意味着把人类的语言知识,先学了一个东西,然后再代入到某个具体任务,就顺手了,就是这么一个简单的道理。
预训练模型,顾名思义,根据要做的某些事,提前训练好一个模型,九年义务教育毕竟不是白教的,如果你没有经历过九年义务教育,那么你上大学,上高中,会怎么办。根本学不会什么东西的。
为什么我们要做预训练模型?
首先,预训练模型是一种迁移学习的应用,利用几乎无限的文本,学习输入句子的每一个成员的上下文相关的表示,它隐式地学习到了通用的语法语义知识。
第二,它可以将从开放领域学到的知识迁移到下游任务,以改善低资源任务,对低资源语言处理也非常有利。
第三,预训练模型在几乎所有NLP任务中都取得了目前最佳的成果。
最后,这个预训练模型+微调机制具备很好的可扩展性,在支持一个新任务时,只需要利用该任务的标注数据进行微调即可,一般工程师就可以实现。
预训练模型的三个技术
1、Transformer
给定一句话或是一个段落作为输入,首先将输入序列中各个词转换为其对应的词向量,同时加上每一个词的位置向量,体现词在序列的位置。然后将这些词向量输入到多层 Transformer 网络中,通过自注意力(self-attention)机制来学习词与词之间的关系,编码其上下文信息,再通过一个前馈网络经过非线性变化,输出综合了上下文特征的各个词的向量表示。
2、自监督学习
在预训练的模型中,AR(自回归)LM 和 AE(自动编码器)是最常用的自监督学习方法,其中,自回归 LM 旨在利用前面的词序列预测下个词的出现概率(语言模型)。自动编码器旨在对损坏的输入句子,比如遮掩了句子某个词、或者打乱了词序等,重建原始数据。通过这些自监督学习手段来学习单词的上下文相关表示。
3、微调
在做具体任务时,微调旨在利用其标注样本对预训练网络的参数进行调整。
5.5.3 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
#使用pretrained = True
from torchvision.models import resnet18
resnet = models.resnet18(pretrained=True)
#使用pretrained = False
resnet = models.resnet18(pretrained=False)
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.nn.functional as F
import torch.optim as opt
# 学习率大小
lr = 0.001
# 批次大小
batch_size = 64
# 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = torch.utils.data.DataLoader(dev_dataset, batch_size=batch_size)
test_loader =torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
# 定义网络
model = resnet18_model
# 定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍
optimizer = opt.Adam(lr=lr, params=model.parameters(), weight_decay=0.005)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy(is_logist=True)
# 实例化RunnerV3
runner = RunnerV3(model,optimizer,loss_fn,metric)
# 启动训练
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
不使用预训练的结果。

可视化观察训练集与验证集的准确率及损失变化情况。
plot_training_loss_acc(runner, fig_name='cnn-loss4.pdf')

使用预训练的结果

对比
结果图像如上图所示,我们发现使用预训练模型后,模型训练的时间短,速度快,但是准确率和误差相比于未使用预训练模型基本一致。使用预训练模型之后收敛的更快,就像我们学习知识的时候如果我们提前预习了,那么老师在授课的时候,我们一定会学习更好更快相比于其他人。
在本实验中,使用了第7章中介绍的Adam优化器进行网络优化,如果使用SGD优化器,会造成过拟合的现象,在验证集上无法得到很好的收敛效果。可以尝试使用第7章中其他优化策略调整训练配置,达到更高的模型精度。
5.5.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
![]()
5.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:

用自己的话简单评价LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
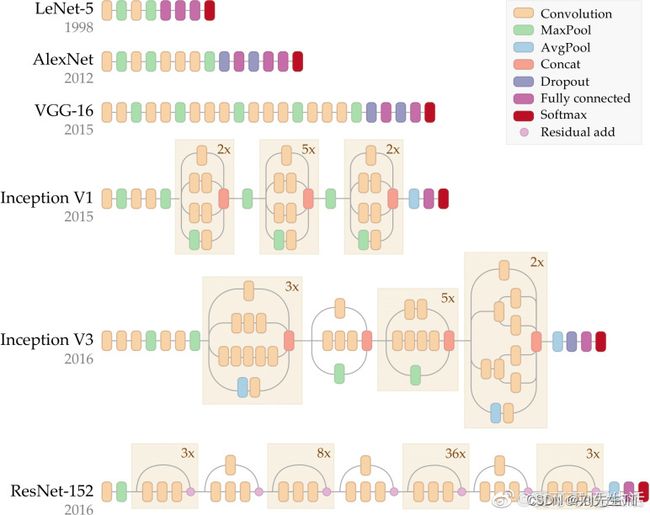
LeNet
LeNet是由深度学习的开山鼻祖LeCun发明的,是用来解决手写数字识别问题的。LeNet共七层。

其中从输入开始,经过一层55的卷积层,之后经历一层最大池化,经历最大池化之后经历一层55的卷积,在经历一层最大池化,最后进行全连接层,直到最后输出数为10。
AlexNet
AlexNet是由另一个深度学习的开山鼻祖Hinton带领他的学生开发出来的并在ImageNet中获得了冠军。
网络结构如下图所示。

AlexNet使用两个GPU训练来提升速度,使用GPU训练。与CPU不同的是,GPU转为执行复杂的数学和几何计算而设计,AlexNet使用了2个GPU来提升速度,分别放置一半卷积核。并且使用Dropout防止过拟合,
VggNet

vggnet严格使用33小尺寸卷积和池化层构造深度CNN,取得较好的效果。小卷积能减少参数,方便堆叠卷积层来增加深度(加深了网络,减少了卷积)。即vggnet=更深的Alex net+conv(33)
GoogLeNet
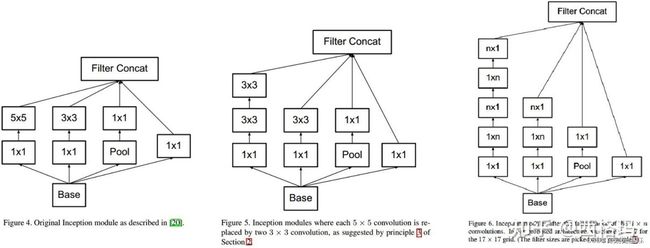
googlenet设计了inception结构来降低通道数,减少计算复杂度,其中inception结构包括以下几种
ResNet
Resnet从避免梯度消失或爆炸的角度,使用残差连接结构使网络可以更深

总结:
通过这次实验,用自己的电脑跑残差网络,跑了半天才跑出来,但是我用Kaggle跑代码,仅仅用了十分钟就把残差网络跑出来了,可见硬件的重要性,这次主要是复刻上课学习的理论知识,用框架实现出来,了解了预训练和迁移学习,基本就是字面意思,还是比较好理解的。
参考
一文读懂LeNet、AlexNet、VGG、GoogleNet、ResNet到底是什么? - 知乎 (zhihu.com)
一文了解 预训练