正则表达式对字符串处理
正则表达式可谓是字符处理中的神器,无论是爬虫的数据处理,还是读取文件中信息处理,正则表达式都是一个非常好用的东西。今天就让我们一起用一道例题看一看一些简单正则表达式的用法吧!
正则表达式匹配规则:
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| re{ n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
题目要求:
有一些参考文献的格式如下:
文献名称、文献来源-会议、年份、页面范围、或
文献名称、文献来源-期刊、年份、卷(期)、页面范围.
文献和文献来源中间有一个空格,文献名称、来源都不含。对于会议文献,年份和页面中间也有空格。
对于期刊文献,年份、卷、期和页面中间没有空格。
对下面一段英文进行分割:
A large scale study of web password of habits.The International Conference on WWW ,2007,657-666.On user choice in graphical password schemes . The 13th USENIX Security Symposium,2004,15-28. The Polyanna hypothesis . Journal of Verbal and Learning Behavior ,1969,8(1):1-8. Support Vector Machine . Journal of Machine Learning ,1992,8(12):110-119.
要求:提取文献名称,文献来源,分年,页面范围。如果是期刊的话,还需要提取卷、期。
输出样例:
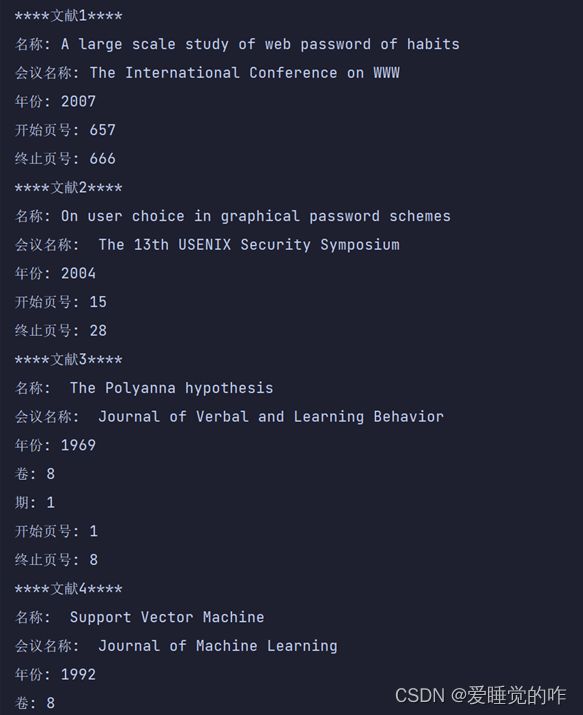
完整代码:
import re
book_str = "A large scale study of web password of habits." \
"The International Conference on WWW ,2007,657-666." \
"On user choice in graphical password schemes . " \
"The 13th USENIX Security Symposium,2004,15-28. " \
"The Polyanna hypothesis . Journal of Verbal and " \
"Learning Behavior ,1969,8(1):1-8. Support Vector" \
" Machine . Journal of Machine Learning ,1992,8(12):110-119."
pattern = r'[,|.]' # 定义分隔符
result = re.split(pattern, book_str) # 以pattern的值 分割字符串
str_list = ["名称:","会议名称:","年份:","开始页号:","终止页号:","卷:","期:"]
print("****文献1****")
print(str_list[0],result[0])
print(str_list[1],result[1])
print(str_list[2],result[2])
print(str_list[3],result[3][:3:])
print(str_list[4],result[3][4::])
print("****文献2****")
print(str_list[0],result[4])
print(str_list[1],result[5])
print(str_list[2],result[6])
print(str_list[3],result[7][:2:])
print(str_list[4],result[7][3::])
print("****文献3****")
print(str_list[0],result[8])
print(str_list[1],result[9])
print(str_list[2],result[10])
print(str_list[5],result[11][0])
print(str_list[6],result[11][2])
print(str_list[3],result[11][5])
print(str_list[4],result[11][7])
print("****文献4****")
print(str_list[0],result[12])
print(str_list[1],result[13])
print(str_list[2],result[14])
print(str_list[5],result[15][0])
print(str_list[6],result[15][2:4:])
print(str_list[3],result[15][6:9:])
print(str_list[4],result[15][10::])
总结:
- 核心代码为两行:
pattern = r'[,|.]' # 定义分隔符
result = re.split(pattern, book_str) # 以pattern的值 分割字符串
- 第一行定义分割符的集合,即之后的英文是根据这个分隔符集合中的元素来分割的。
- 第二行用正则表达式中的re.split方法,第一个参数pattern是上面定义的分割字符串的列表,第二个参数是是要进行处理的字符串,这里选的就是book_str,既是题目要求的操作的字符串。注意,这里的返回对象是一个列表。
- 将上述切割结果的列表打印出来,根据我们的需要,用列表的索引和字符串的切割方法,可以逐个打出我们所需要的内容。
- 定义了一个str_list = ["名称:","会议名称:","年份:","开始页号:","终止页号:","卷:","期:"],用来储存名称,这样既可以利用索引进行输出啦!