从开源模型、框架到自研,声网 Web 端虚拟背景算法正式发布

根据研究发现,在平均 38 分钟的视频会议里面,大概会有 13 分钟左右的时间用于处理和干扰相关的事情。同时研究也表明在参加在线会议的时候,人们更加倾向于语音会议,其中一个关键原因就是大家不希望个人隐私暴露于公众的视野。
如何在视频会议中突出演讲者,减少背景当中的干扰信息,并提升人们对视频会议的参与热情成为了实时音视频技术所要解决的问题,而实时虚拟背景正是一项这样的技术。不同于绿幕等传统技术手段,虚拟背景通过机器学习推理对实时视频内容当中的人像进行分割,实现对人像外内容的替换。因此用户无需对现实环境中的背景进行布置即可使用,具有便捷高效的优点。

2021 年 8 月,声网落地了基于 Web SDK 的第一个虚拟背景插件版本,实现了背景替换与背景虚化功能。在近期发布的虚拟背景插件更新中,该功能得到进一步提升,目前已可支持图片虚拟背景、基于 CSS 色值的纯色背景、3 档不同程度的虚化背景。机器学习推理引擎也从通用机器学习框架升级为 Agora AI 实现,不仅整体包增量从 3M 降低至 1M,运算性能实现了 30% 以上的提高,新的 API 也更为易用。
回顾声网 Web SDK 虚拟背景功能的研发过程,主要经历了三个阶段:
第一阶段 开源模型 + 开源机器学习框架
在这一阶段,我们基于 MediaPipe selife 人像分割模型和TFlite机器学习框架完成了虚拟背景在 Web 平台的工程化实践。实现了从图像采集、实时处理到编码发送的完整管线。在这一个过程中,我们对影响处理性能的关键因素进行了大量分析,并对这些性能瓶颈进行了针对性的优化。同时我们也对不同机器学习框架在 Web 人像分割的应用场景进行了定制和优化,这其中包括对 MediaPipe 和 TFlite 框架的定制。
MediaPipe 使用 TFlite 作为机器学习推理引擎,MediaPipe 的 TFlite 人像分割模型所使用的算子除了包含 TFlite 支持的通用算子,还包含 MediaPipe 提供的特殊算子。在实践中,我们将 MediaPipe 人像分割模型所依赖的 MediaPipe 特殊算子直接移植到 TFlite,实现了 selife segmentation 模型脱离 MediaPipe 框架直接在 TFlite 上的运行。同时使用自研 WebGL 算法替代 Mediapipe 提供的图形处理功能。这样就消除工程对 MediaPipe 的依赖,不仅降低了 MediaPipe 带来的整体包增量,同时使机器学习运算和图像处理解耦,整体方案更具灵活性。
由于 TFlite 在 Web 平台采用 WebAssembly 移植实现,而 WebAssembly VM 环境和真实系统架构存在较大区别。这就需要对支撑 TFlite 运算的不同矩阵/向量运算后端框架的性能进行评估。TFlite 提供了 XNNPACK、Eigen、ruy 三种矩阵运算后端。经分析对比他们在 WebAssembly 下单帧推理时间表现如下:
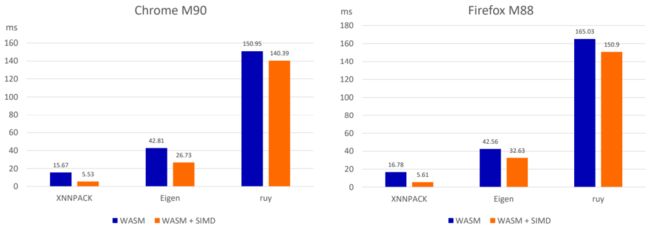
■TFlite 不同运算后端下的性能表现
依据分析结果将 TFlite 在 WebAssembly 上的运算后端调整为 XNNPACK 后,整体运算性能得到了大幅提升。
第二阶段 自研模型 + 开源机器学习框架
在第二阶段的研发重点是自研模型及算法的研发和工程化,通过海量训练样本对各类场景的覆盖,声网逐步实现了自研人像分割模型的算法迭代,输出的自研模型和算法在人像分割精度、画面稳定性、计算性能等方面对比开源模型形成了较大的综合优势。出于对机器学习生态和模型兼容性的考虑,工程化所用的机器学习框架也从 TFlite 切换到了 Onnxruntime。在进行 onnxruntime 的 WebAssembly 移植的过程中,Web 团队使用了包含了 SIMD 和多线程在内的多项优化手段对运算性能进行提升。值得一提的是,我们将 Onnxruntime WebAssembly SIMD 优化过程中的部分工作成果提交至 Onnxruntime 开源社区,并被合入项目主线。
至此,声网发布了 Web SDK v4.5.0,并在 npmjs 上线了独立的 Web 虚拟背景插件,成为音视频云 toB 行业中首先在 Web SDK 产品中支持该功能的服务商。
第三阶段 自研模型 + Agora AI 机器学习框架
在人像分割模型逐步演进同时,出于对计算性能的无限探索和对用户体验的无止境追求,声网高性能计算团队同时也对基于 Agora AI 框架的人像分割模型工程化开展了研究,在使用了包含计算图优化,内存自动复用,算子 WebAssembly 优化在内的多项技术手段后,将原模型处理算法在 Web 平台上的整体性能提升了 30% 左右。
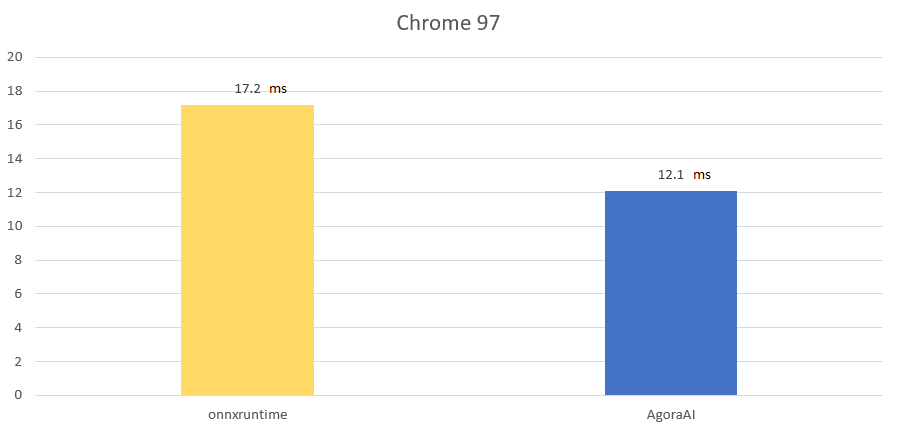
■Agora 人像分割模型在某测试设备上的单帧推理时间
Web SDK 团队在使用 Agora AI 对 onnxruntime 进行替换后,虚拟背景插件的整体包大小从之前的 3M 降低至 1M,有效提升了用户在 Web 环境下的插件加载速度,实现了用户体验的较大提升。
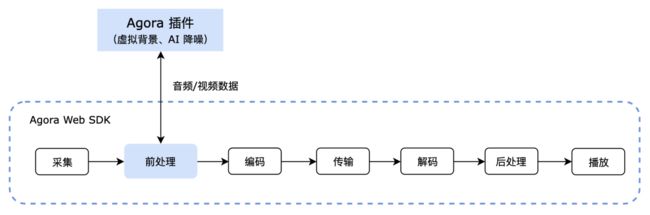
■Agora Web SDK 媒体处理管线
在近期发布的 WebSDK v4.10.0 中,我们同时对虚拟背景插件进行了更新,新的虚拟背景插件不仅包含上述提升,同时它也基于 WebSDK 新的插件机制实现,提供了更易用 API。目前新的虚拟背景插件使用了新的包名通过 npm 发布,如果对该功能感兴趣可点击**「此处」**访问 Agora 官网文档进行了解。
■npmjs上的声网Web虚拟背景插件
展望
技术无止境、需求恒久远。在未来的研发过程中,声网虚拟背景在效果方面将针对强光照、背景暗光、复杂背景等更丰富应用场景进行研究和突破,并针对高分辨率场景下的人像边缘、发丝等细节的保留进行优化。

■高清图像人像分割的细节保留
在算法方面将实现从单帧图像推理到视频连续帧推理的尝试。从而满足用户在各类更复杂环境下的虚拟背景体验需求。让我们拭目以待!
最后,如果大家想体验目前 Web 端的虚拟背景,可以访问 videocall.agora.io,创建房间后,在设置中开启。
Dev for Dev专栏介绍
Dev for Dev(Developer for Developer)是声网Agora 与 RTC 开发者社区共同发起的开发者互动创新实践活动。透过工程师视角的技术分享、交流碰撞、项目共建等多种形式,汇聚开发者的力量,挖掘和传递最具价值的技术内容和项目,全面释放技术的创造力。