教程详解 | 用 PaddleOCR 进行集装箱箱号检测识别
内容一览:基于 PaddleOCR 进行集装箱箱号检测,缩短记录集装箱箱号的时间,提高港口装卸效率。
关键词:PaddleOCR 文字识别 在线教程
国际航运咨询分析机构 Alphaliner 在今年 3 月公布的一组数据,2021 年集装箱吞吐量排名前 30 的榜单中,上海港以 4702.5 万标箱的「成绩单」雄踞鳌头。
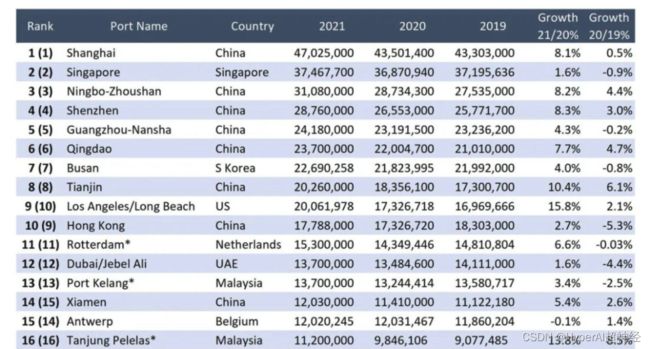
全球百大集装箱港口,更是在 2021 年共完成集装箱吞吐量 6.76 亿 TEU。如此大规模的集装箱数量,使得箱号识别的压力骤增, 传统的由人对集装箱号进行识别记录的方式成本高、效率低,运营条件落后。
随着经济和社会的发展,在港口经营中引入人工智能,已经成为传统港口在市场竞争中蜕变升维的关键。
本文将从环境准备到模型训练,演示如何借助 PaddleOCR,进行集装箱箱号检测识别。
直接查看代码教程:
https://openbayes.com/console/open-tutorials/containers/XJsxhLTnKNu
用少量数据实现箱号检测识别任务
集装箱号是指装运出口货物集装箱的箱号,填写托运单时必填此项。 标准箱号的构成采用ISO6346 (1995) 标准,由 11 位编码组成,以箱号 CBHU 123456 7 为例,它包括 3 个部分:
第一部分由 4 个英文字母组成, 前 3 个字母表示箱主、经营人,第 4 个字母表示集装箱类型。CBHU 表示箱主和经营人为中远集运的标准集装箱。
第二部分由 6 位数字组成, 表示箱体注册码,是集装箱箱体持有的唯一标识。
第三部分为校验码,由前面 4 个字母和 6 位数字经过校验规则运算得到,用于识别在校验时是否发生错误。

本教程基于PaddleOCR进行集装箱箱号检测识别任务, 使用少量数据分别训练检测、识别模型,最后将他们串联在一起实现集装箱箱号检测识别的任务
环境准备
- 在 OpenBayes 控制台启动一个「模型训练」的容器, 环境选择 PaddlePaddle 2.3,资源选择 RTX 3090 或其他 GPU 类型。
暂无平台账号的,请访问以下地址先行注册:
https://openbayes.com/console/signup
- 在 Jupyter 中打开一个 Terminal 窗口, 然后执行如下命令:
cd PaddleOCR-release-2.5 #进入PaddleOCR-release-2.5文件夹
pip install -r requirements.txt #安装PaddleOCR所需依赖
python setup.py install #安装PaddleOCR
数据集介绍
本教程使用集装箱箱号数据集 (ContainerNumber-OCR Dataset),该数据包含 3003 张分辨率为 1920×1080 的集装箱图像。
查看数据集详细信息,请访问:
https://openbayes.com/console/open-tutorials/datasets/BzuGVEOJv2T/3
- PaddleOCR 检测模型训练标注规则如下,中间用 “\t” 分隔:
" 图像文件名 json.dumps编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
其中 json.dumps 编码前的图像标注信息是包含多个字典的 list ,字典中的 points 表示文本框 4 个点的坐标 (x, y),从左上角的点开始顺时针排列。
transcription 表示当前文本框的文字,当其内容为“###”时,表示该文本框无效,在训练时会跳过。
- PaddleOCR 识别模型训练标注规则如下,中间用 “\t” 分隔:
" 图像文件名 图像标注信息 "
train_data/rec/train/word_001.jpg 简单可依赖
train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
数据整理
3.1 检测模型所需数据准备
将数据集 3000 张图片按 2:1 划分成训练集和验证集,运行以下代码:
from tqdm import tqdm
finename = "all_label.txt"
f = open(finename)
lines = f.readlines()
t = open('det_train_label.txt','w')
v = open('det_eval_label.txt','w')
count = 0
for line in tqdm(lines):
if count < 2000:
t.writelines(line)
count += 1
else:
v.writelines(line)
f.close()
t.close()
v.close()
3.2 识别模型所需数据准备
根据检测部分的注释,裁剪数据集尽可能只包含文字部分图片作为识别的数据,运行以下代码:

完整代码详见:
https://openbayes.com/console/open-tutorials/containers/XJsxhLTnKNu
实验
由于数据比较少,为了模型更好和更快的收敛,这里选用 PaddleOCR 中的 PP-OCRv3 模型进行检测和识别。
PP-OCRv3 在 PP-OCRv2 的基础上,中文场景端到端 Hmean 指标相比于 PP-OCRv2 提升 5% , 英文数字模型端到端效果提升 11% 。
详细优化细节请参考 PP-OCRv3 技术报告。
4.1 检测模型
4.1.1 检测模型配置
PaddleOCR 提供了许多检测模型, 在路径 PaddleOCR-release-2.5/configs/det 下可找到模型及其配置文件。如我们选用模型 ch_PP-OCRv3_det_student.yml,配置文件路径为:PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
使用前需对其进行必要的设置,如训练参数、数据集路径等。将部分关键配置展示如下:
#关键训练参数
use_gpu: true #是否使用显卡
epoch_num: 1200 #训练epoch个数
save_model_dir: ./output/ch_PP-OCR_V3_det/ #模型保存路径
save_epoch_step: 200 #每训练200epoch,保存一次模型
eval_batch_step: [0, 100] #训练每迭代100次,进行一次验证
pretrained_model: ./PaddleOCR-release
2.5/pretrain_models/ch_PP-OCR_V3_det/best_accuracy.pdparams #预训练模型路径
#训练集路径设置
Train:
dataset:
name: SimpleDataSet
data_dir: /input0/images #图片文件夹路径
label_file_list:
- ./det_train_label.txt #标签路径
4.1.2 模型微调
在 notebook 中运行如下命令对模型进行微调,其中 -c 传入的为配置好的模型文件路径:
leOCR-release-2.5/tools/train.py \
-c PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
使用默认超参数,模型 ch_PP-OCRv3_det_student 在训练集上训练 385 个 epoch 后,模型在验证集上的 hmean 达到:96.96% ,此后再无明显增长:
[2022/10/11 06:36:09] ppocr INFO: best metric, hmean: 0.969551282051282, precision: 0.9577836411609498,
recall: 0.981611681990265, fps: 20.347745459258228, best_epoch: 385
4.2 识别模型
4.2.1 识别模型配置
PaddleOCR 提供了许多识别模型。在路径 PaddleOCR-release-2.5/configs/rec 下可找到模型及其配置文件。
如我们选用模型 ch_PP-OCRv3_rec_distillation,其配置文件路径在:
PaddleOCR-release-2.5/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
使用前需对其进行必要的设置,如训练参数、数据集路径等。 将部分关键配置展示如下:
#关键训练参数
use_gpu: true #是否使用显卡
epoch_num: 1200 #训练epoch个数
save_model_dir: ./output/rec_ppocr_v3_distillation #模型保存路径
save_epoch_step: 200 #每训练200epoch,保存一次模型
eval_batch_step: [0, 100] #训练每迭代100次,进行一次验证
pretrained_model: ./PaddleOCR-release-2.5/pretrain_models/PPOCRv3/best_accuracy.pdparams #预训练模型路径
#训练集路径设置
Train:
dataset:
name: SimpleDataSet
data_dir: ./RecTrainData/ #图片文件夹路径
label_file_list:
- ./rec_train_label.txt #标签路径
4.2.2 模型微调
在 notebook 中运行如下命令对模型进行微调,其中 -c 传入的为配置好的模型文件路径:
%run PaddleOCR-release-2.5/tools/train.py \
-c PaddleOCR-release-2.5/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
使用默认超参数,模型 ch_PP-OCRv3_rec_distillation 在训练集上训练 136 个 epoch 后,模型在验证集上的精度达到:96.11% ,此后再无明显增长:
[2022/10/11 20:04:28] ppocr INFO: best metric, acc: 0.9610600272522444, norm_edit_dis: 0.9927426548965615,
Teacher_acc: 0.9540291998159589, Teacher_norm_edit_dis: 0.9905629345025616, fps: 246.029195787707, best_epoch: 136
结果展示
5.1 检测模型推理
在 notebook 中运行如下命令使用微调过的模型检测测试图片中的文字,其中:
- Global.infer_img 为图片路径或图片文件夹路径
- Global.pretrained_model 为微调过的模型
- Global.save_res_path 为推理结果保存路径
%run PaddleOCR-release-2.5/tools/infer_det.py \
-c PaddleOCR-release-2.5/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
-o Global.infer_img="/input0/images" Global.pretrained_model="./output/ch_PP-OCR_V3_det/best_accuracy" Global.save_res_path="./output/det_infer_res/predicts.txt"
5.2 识别模型推理
在 notebook 中运行如下命令使用微调过的模型检测测试图片中的文字,其中:
Global.infer_img为图片路径或图片文件夹路径Global.pretrained_model为微调过的模型Global.save_res_path为推理结果保存路径
%run PaddleOCR-release-2.5/tools/infer_rec.py \
-c PaddleOCR-release-2.5/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \
-o Global.infer_img="./RecEvalData/" Global.pretrained_model="./output/rec_ppocr_v3_distillation/best_accuracy" Global.save_res_path="./output/rec_infer_res/predicts.txt"
5.3 检测识别模型串联推理
5.3.1 模型转换
在串联推理前首先需要将训练保存的模型转换成推理模型,分别执行如下检测命令即可。 其中:
-c传入要转换模型的配置文件路径-o Global.pretrained_model为要被转换的模型文件Global.save_inference_dir为转换得到推理模型的储存路径

5.3.2 模型串联推理
转换完毕后,PaddleOCR 提供了检测和识别模型的串联工具,可以将训练好的任一检测模型和任一识别模型串联成两阶段的文本识别系统。
输入图像经过文本检测、检测框矫正、文本识别、得分过滤四个主要阶段输出文本位置和识别结果。
执行代码如下,其中:
image_dir为单张图像或者图像集合的路径det_model_dir为检测 inference 模型的路径rec_model_dir为识别 inference 模型的路径
可视化识别结果默认保存到 ./inference_results 文件夹里面。
%run PaddleOCR-release-2.5/tools/infer/predict_system.py \
--image_dir="OCRTest" \
--det_model_dir="./output/det_inference/" \
--rec_model_dir="./output/rec_inference/Student/"

查看完整教程,请访问:
https://openbayes.com/console/open-tutorials/containers/XJsxhLTnKNu
关于 PaddleOCR 和 OpenBayes
PaddleOCR 是一种基于百度飞桨的 OCR 工具库,包含总模型仅 8.6M 的超轻量级中文 OCR,同时支持多种文本检测、文本识别的训练算法、服务部署和端侧部署。
更多详情请访问:
https://github.com/PaddlePaddle/PaddleOCR
了解 OpenBayes
OpenBayes 是国内领先的机器智能研究机构,提供算力容器、自动建模、自动调参等多项 AI 开发相关的基础服务。
同时 OpenBayes 还上线了数据集、教程、模型等众多主流公开资源, 供开发者快速学习并创建理想的机器学习模型。
现在访问 openbayes.com 并注册
即可享用
600 分钟/周的 RTX 3090
以及 300 分钟/周 的 CPU 免费计算时
注:每周赠送的资源将于每周一下午到账
查看并运行完整教程,访问以下链接:
https://openbayes.com/console/open-tutorials/containers/XJsxhLTnKNu
—— 完 ——