Python--简单的深度学习CNN睁闭眼分类
Python–简单的深度学习CNN睁闭眼分类
数据集:闭眼(CEW)和睁眼(LFW)两个文件夹,闭眼数据共1189张图片,睁眼数据为LFW中George_W_Bush共530张图片.测试集从中随机复制330张图片.数据集可调整增加.

数据准备:root为数据集地址.将数据转为网络可用的tensor量.
class MyDataset(Dataset):
def __init__(self, root, transform=None, target_transform=None, loader=default_loader):
list = os.listdir(root)
imgs = []
i = 0
for l in list:
l = root + '/' + l
for home, dirs, files in os.walk(l):
for filename in files:
imgs.append((os.path.join(home, filename), i))
i = i + 1
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index): # index键
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB')
img = img.resize((48, 48), Image.ANTIALIAS)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_data = MyDataset(root + '/train', transform=transforms.ToTensor())
test_data = MyDataset(root + '/test', transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True) #每次训练64个,打乱
test_loader = DataLoader(dataset=test_data, batch_size=64)
构建网络:CNN网络
#构建网络
class cnn_net(nn.Module):
def __init__(self):
super(cnn_net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) #128*24*24
self.fc1 = nn.Linear(128*24*24, 1024)
self.relu3 = nn.ReLU()
self.drop = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(1024, 2)
def forward(self, x):
out = self.conv1(x)
out = self.relu1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.pool1(out)
out = out.view(-1, 128*24*24)
out = self.fc1(out)
out = self.relu3(out)
out = self.drop(out)
out = self.fc2(out)
return out
model = cnn_net()
print(model)
# optimizer = torch.optim.SGD(model.parameters(), lr=LR)
optimizer = torch.optim.Adam(model.parameters()) # Adam优化器
loss_func = torch.nn.CrossEntropyLoss() # 交叉熵
训练和测试:
for epoch in range(4):
print('epoch {}'.format(epoch + 1))
# training
train_loss = 0.
train_acc = 0.
for batch_x, batch_y in train_loader:
batch_x, batch_y = Variable(batch_x), Variable(batch_y)
#print(batch_x.size())
out = model(batch_x) # 前向
#print(out.size())
#print(batch_y.size())
loss = loss_func(out, batch_y.squeeze())
train_loss += loss.item() # 每次误差加起来
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
optimizer.zero_grad() # 梯度置0
loss.backward() # 反传
optimizer.step() # 更新所有参数
print('Accuracy: {:.6f}, Train Loss: {:.6f}'.format(train_acc / (len(train_data)), train_loss / (len(train_data))))
# evaluation--------------------------------
model.eval() # 关闭dropout
eval_loss = 0.
eval_acc = 0.
for batch_x, batch_y in test_loader:
# batch_x, batch_y = Variable(batch_x.to(device)), Variable(batch_y.to(device))
batch_x, batch_y = Variable(batch_x), Variable(batch_y)
out = model(batch_x)
loss = loss_func(out, batch_y)
eval_loss += loss.item()
pred = torch.max(out, 1)[1]
eval_correct = (pred == batch_y).sum()
eval_acc += eval_correct.item()
print('Accuracy: {:.6f}, Test Loss: {:.6f}'.format(eval_acc / (len(test_data)), eval_loss / (len(test_data))))
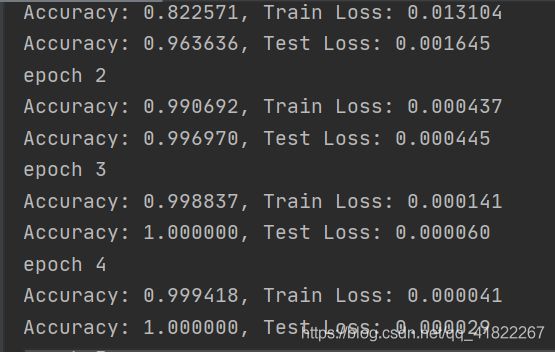
测试结果:从结果来看,这个网络还是较好的,训练到第三代可以看出测试集正确率达到了100%,是因为我的测试集直接从训练集里面复制过来的,也有可能是我的数据集不够大,后续会对其余数据集进行测试。
本人第一次尝试写博客,可能有些地方写的不会太详细,有不懂的或不对的请多多指正,嘿嘿!