数据导入与预处理-课程总结-01~03章
数据导入与预处理-课程总结-01~03章
- 第1章 数据预处理概述
-
- 1.1 基本概念
-
- 1.1.1 大数据项目开发流程
- 1.1.2 什么是数据预处理
- 1.1.3 数据质量
- 1.1.4 常见的数据问题
- 1.2 数据预处理
-
- 1.2.1 数据预处理流程
- 1.2.2 数据清理的处理方法
-
- 1.缺失值的处理方法
- 2. 异常值的处理方法
- 3. 重复值的处理方法
- 1.2.3 数据集成
-
- 1. 集成过程中需要处理的问题
- 2. 数据集成——实体识别
- 3. 数据集成——冗余属性识别
- 4. 数据冲突的检测与处理
- 1.2.4 数据变换
-
- 1. 规范化:
- 2. 数据变换——属性构造
- 1.2.5 数据规约
-
- 1.数据规约目的
- 2.数据规约方法
- 第2章 numpy库
-
- 2.1 数组对象
- 2.2 创建数组
- 2.3 访问数组元素
-
- 2.3.1 通过整数索引
- 2.3.2 使用花式索引访问元素
- 2.3.3 使用布尔索引访问元素
- 2.3.4 使用切片访问元素
- 2.4 数组运算
-
- 2.4.1 形状相同的数组运算
- 2.4.2 数组与常量运算
- 2.5 Numpy的约减即操作
-
- 2.5.1 约减操作
- 2.5.2 数组排序操作
- 2.5.3 数组转置
- 2.5.4 随机数生成
-
- 1. numpy的random库
- 第3章 pandas基础
-
- 3.1 series
-
- 3.1.1 创建series对象
- 3.1.2 Series属性
- 3.1.3 Series索引
-
- 1. 位置索引
- 2. 标签索引
- 3. 切片索引
- 4. 布尔索引
- 3.1.5 Series基本操作技巧
- 3.2 DataFrame
-
- 3.2.1 Dataframe简介
- 3.2.2 创建DataFrame对象
- 3.2.3 Dataframe:索引
-
- 1.选择行与列
- 2. df.loc[] - 按index选择行
- 3. df.iloc[] - 按照整数位置(从轴的0到length-1)选择行
- 4. 布尔型索引
- 3.2.4 DataFrame基本操作技巧
-
- 1. 数据查看、转置
- 2. 添加、修改、删除值
- 3. 排序
- 3.2.5 Index索引对象
-
- 1.索引对象概述
- 2. 索引对象操作
- 3. 使用索引对象操作数据
- 3.3 统计计算与统计描述
备注:本文主要是课程总结,不做过多的拓展,如果需要详细了解,可以查看本专栏系列内容,专栏链接直达
数据导入与预处理-课程总结-资料汇总贴
第1章 数据预处理概述
1.1 基本概念
1.1.1 大数据项目开发流程
数据采集
数据预处理
数据存储
数据分析挖掘
数据可视化
1.1.2 什么是数据预处理
从初始数据到得出分析或挖掘结果的整个过程中对数据经过的一系列操作称为数据预处理,它主要通过一系列的方法来清理脏数据、抽取精准的数据、调整数据 的格式,从而得到一组符合准确、完整、简洁等标准的高质量数据,保证该数据能更好地服务于数据分析或数据挖掘工作。
据统计发现,数据预处理的工作量占据整个数据挖 掘工作的60%,由此可见,数据预处理在数据挖掘 中扮演着举足轻重的角色
1.1.3 数据质量
相关性 :数据的相关性是指数据与特定的应用和领域有关。
准确性 :数据是正确的,数据存储在数据库中的值对应于真实世界的值。
时效性:是指数据仅在一定时间段内对决策具有价值的属性。数据的时效性很大程度上制约着决策的客观效果。
完整性:指信息具有一个实体描述的所有必需的部分,在传统关系型数据库中,完整性通常与空值(NULL)有关。一般包括记录的缺失和记录属性的缺失。
一致性:在数据库中是指在不同地方存储和使用的同一数据应当是等价的,表示数据有相等的值和相同的含义。
可信性:• 数据来源的权威性;• 数据的规范性;• 数据产生的时间。
可解释性:反映数据是否容易理解
1.1.4 常见的数据问题
数据缺失:数据缺失是一类属性值为空的问题。
数据重复:数据重复是一类同一条数据多次出现的问题。
数据异常:数据异常是一类个别数据远离数据集的问题
数据冗余:数据冗余是指数据中存在一些多余的、无意义的属性。
数据值冲突:数据值冲突是一类同一属性存在不同值的问题。
数据噪声:数据噪声是一类属性值不符合常理的问题。
1.2 数据预处理
1.2.1 数据预处理流程
初始数据–>数据清理–>数据集成–>数据变换–>数据规约。这些流程的顺序不是完全固定的,往往是相互交叉的。
初始数据获取是预处理的第一步,该步骤主要负责从文件、数据库、网页等众多渠道中获取数据,以得到预处理的初始数据,为后续的处理工作做好数据准备。
数据清理主要是将"脏"数据变成"干净"数据的过程,该过程中会通过一系列的方法对“脏”数据进行处理,以达到清除冗余数据、规范数据、纠正错误数据的目的。
数据集成主要是把多个数据源合并成一个数据源的过程,以达到增大数据量的目的。
数据变换主要是将数据转换成适当形式的过程,以降低数据的复杂度。
数据规约指在尽可能保持数据原貌的前提下,最大限度地精简数据量,其方法包括降低数据的维度、删除与分析或挖掘主题无关的数据等。
1.2.2 数据清理的处理方法
1.缺失值的处理方法
-
忽略元组
-
填充(人工,全局常量,平均值,插值)
-
删除
2. 异常值的处理方法
-
删除:异常值是否剔除,需视具体情况而定,因为有些异常值可能蕴含着有用的信息。
-
把异常值当作缺失值,删除或填充。
-
忽略。
3. 重复值的处理方法
-
删除:异常值是否剔除,需视具体情况而定,因为有些异常值可能蕴含着有用的信息。
-
忽略。
1.2.3 数据集成
1. 集成过程中需要处理的问题
- 实体识别
- 冗余与相关分析
- 数据冲突和检测
2. 数据集成——实体识别
实体识别的任务是检测和解决同名异义、异名同义、单位不统一的冲突。如:
同名异义:数据源A中的属性ID和数据源B中的属性ID分别描述的是菜品编号和订单编号,即描述的是不同的实体。
异名同义:数据源A中的sales_dt和数据源B中的sales_date都是是描述销售日期的,即A. sales_dt= B. sales_date。
单位不统一:描述同一个实体分别用的是国际单位和中国传统的计量单位
3. 数据集成——冗余属性识别
数据集成往往导致数据冗余,如:
同一属性多次出现
同一属性命名不一致导致重复
不同源数据的仔细整合能减少甚至避免数据冗余与不一致,以提高数据挖掘的速度和质量。对于
冗余属性要先分析检测到后再将其删除。有些冗余属性可以用相关分析检测到。给定两个数值型的属性A和B,根据其属性值,可以用相
关系数度量一个属性在多大程度上蕴含另一个属性。
4. 数据冲突的检测与处理
对现实世界的同一实体,来自不同数据源的属性定义不同。
原因:表示方法,度量单位、编码或比例的差异
1.2.4 数据变换
**目的:**将数据转换或统一成易于进行数据挖掘的数据存储形式,使得挖掘过程可能更有效。
方法策略:
光滑:去掉数据中的噪音;
属性构造:由给定的属性构造新的属性并添加到属性集中,帮助数据分析和挖掘;
聚集:对数据进行汇总或聚集;
规范化:将属性数据按比例缩放,使之落入一个小的特定区间;
离散化:数值属性用区间标签或概念标签替换;
由标称数据产生概念分层:属性,如street,可以泛化到较高的概念层,如city或country。
1. 规范化:
最小-最大规范化;
V ′ = V − m i n A m a x A − m i n A V^{'} = \frac{V-min_A}{max_A - min_A} V′=maxA−minAV−minA
零-均值规范化(z-score规范化);
V ′ = V − m e a n A s t a n d a r d _ d e v A V^{'} = \frac{V-mean_A}{standard\_dev_A} V′=standard_devAV−meanA
其中, m e a n A mean_A meanA、 s t a n d a r d _ d e v A standard\_dev_A standard_devA分别为属性A取值的均值和标准差。
小数定标规范化
V ′ = V 1 0 j V^{'} = \frac{V}{10^{j}} V′=10jV
其中 j j j是使 M a x ( ∣ V ′ ∣ ) < 1 Max(|V^{'}|)<1 Max(∣V′∣)<1的最下整数。
2. 数据变换——属性构造
在数据挖掘的过程中,为了帮助提取更有用的信息、挖掘更深层次的模式,提高挖掘结果的精度,
需要利用已有的属性集构造出新的属性,并加入到现有的属性集合中。
比如进行防窃漏电诊断建模时,已有的属性包括进入线路供入电量、该条线路上各大用户用电量
之和,记为供出电量。理论上供入电量和供出电量应该是相等的,但是由于在传输过程中的电能
损耗,会使得供入电量略大于供出电量,如果该条线路上的一个或多个大用户存在窃漏电行为,
会使供入电量远大于供出电量。反过来,为了判断是否存在有窃漏电行为的大用户,需要构造一
个新的关键指标–线损率,该过程就是构造属性,由线户关系图。新构造的属性线损率计算公式
如下:
线损率=(供入电量-供出电量)/供入电量
线损率的范围一般在3%~15%,如果远远超过该范围,就可以认为该条线路的大用户很大可能
存在窃漏电等用电异常行为。
1.2.5 数据规约
1.数据规约目的
用于帮助从原有庞大数据集中获得一个精简的数据集合,并使这一精简数据集保持原有数据集的完整性,这样在精简数据集上进行数据挖掘显然效率更高,并且挖掘出来的结果与使用原有数据集所获得结果是基本相同。
2.数据规约方法
维归约-主成分分析,属性子集选择
数量归约
第2章 numpy库
具体参考:
猿创征文|数据导入与预处理-第2章-numpy
2.1 数组对象
秩(rank):NumPy 数组的维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推。
axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;
axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
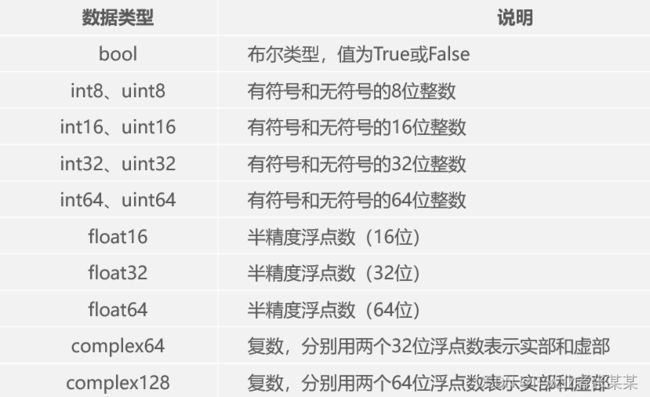
NumPy 的数组中比较重要 ndarray 对象属性有:

numpy的常用数据类型
2.2 创建数组
创建二维数组
# 创建二维数组
array_2d = np.array([[1, 2, 3],
[4, 5, 6]])
print(array_2d)
创建其它数组
numpy中使用zeros()、ones()、empty()函数创建一个基于指定数值的数组,其中zeros()函数用于创建一个元素值都为0的数组;ones()函数用于创建一个元素值都为1的数组;empty()函数用于创建一个元素值都为随机数的数组。
2.3 访问数组元素
2.3.1 通过整数索引
import numpy as np
array_2d = np.arange(1, 7).reshape(2, 3)
print(array_2d[1]) # 获取索引为1的一行元素
print(array_2d[1, 2]) # 获取行索引为1、列索引为2的元素
2.3.2 使用花式索引访问元素
访问一维数组
import numpy as np
array_1d = np.arange(1, 10)
print(array_1d[[2, 5, 8]]) # 访问索引为[2,5,8]的元素
使用花式索引访问二维数组
array_2d = np.arange(1, 10).reshape((3, 3))
print(array_2d[[0, 2]]) # 访问索引为[0, 2]的元素
2.3.3 使用布尔索引访问元素
布尔索引指以布尔值组成的数组或列表为索引。当使用布尔索引访问数组时,会将布尔索引对应的数组或列表的元素作为索引,以获取索引为True时对应位置的元素。
array_2d = np.arange(1, 10).reshape((3, 3))
print(array_2d > 5) # 使用布尔索引访问数组
2.3.4 使用切片访问元素
一维数组的切片操作
array_1d = np.array([10, 20, 30, 40, 50, 60])
print(array_1d[1:3]) # 访问索引为1、2的元素
print(array_1d[:3]) # 访问前两个元素
print(array_1d[:-1]) # 访问除末尾元素之外的元素
print(array_1d[:]) # 访问全部的元素
print(array_1d[::2]) # 访问开头到末尾、步长为2的元素
二维数组的切片操作
arr_2d = np.array([[1, 2, 3],
[4, 5, 6], [7, 8, 9]])
print(arr_2d[:2]) # 使用切片访问前两行的元素
print(arr_2d[:2, 0:1]) # 使用切片访问前两行、第一列的元素
2.4 数组运算
2.4.1 形状相同的数组运算
无论是形状相同的数组,还是形状不同的数组,它们之间都可以执行算术运算。与Python列表不同,数组在参与算术运算时无需遍历每个元素,便可以对每个元素执行批量运算,效率更高。
In [1]: import numpy as np
In [2]: a = np.array(10)
In [3]: b = np.linspace(1,10,10) # 一维,长度为10
In [5]: a = np.arange(10)
In [6]: a
Out[6]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [7]: b
Out[7]: array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
In [8]: a + b # 数组加法
Out[8]: array([ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.])
In [9]: a - b # 数组减法
Out[9]: array([-1., -1., -1., -1., -1., -1., -1., -1., -1., -1.])
In [10]: a * b
Out[10]: array([ 0., 2., 6., 12., 20., 30., 42., 56., 72., 90.])
In [11]: a / b # 数组除法
Out[11]:
array([0. , 0.5 , 0.66666667, 0.75 , 0.8 ,
0.83333333, 0.85714286, 0.875 , 0.88888889, 0.9 ])
In [12]: a % b # 数组取余
Out[12]: array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
In [13]: a ** 2 # 数组元素平方
Out[13]: array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81], dtype=int32)
In [14]: np.multiply(a , b)
Out[14]: array([ 0., 2., 6., 12., 20., 30., 42., 56., 72., 90.])
2.4.2 数组与常量运算
数组与常量的运算
形状相同的数组之间的任何算术运算都会应用到各元素,同样地,数组与标量执行算术运算时也会将标量应用到各元素,以方便各元素与标量直接进行相加、相减、相乘、相除等基础操作。
import numpy as np
arr_2d = np.array([[1, 2, 3], [4, 5, 6]])
num = 10
print(arr_2d + num) # 数组与标量相加
输出为:
[[11 12 13]
[14 15 16]]
2.5 Numpy的约减即操作
2.5.1 约减操作
约减:表示将众多数据按照某种规则合并成一个或几个数据。
约减之后,数据的个数在总量上是减少的。
在这里,“约减”的“减”并非减法之意,而是元素的减少。比如说,数组的加法操作就是一种“约减”操作,因为它对众多元素按照加法指令实施操作,最后合并为少数的一个或几个值。
axis=0表示按照垂直方向约减
axis=1表示按照水平方向约减
In [43]: a = np.ones((2, 3))
In [45]:
In [45]: a.sum(axis=0)
Out[45]: array([2., 2., 2.])
In [46]: a.sum(axis=1)
Out[46]: array([3., 3.])
In [47]: a.sum()
Out[47]: 6.0
2.5.2 数组排序操作
numpy中使用sort()方法实现数组排序功能,数组的每行元素默认会按照从小到大的顺序排列,返回排序后的数组。
In [68]: a = np.array([[1,2,3],[4,5,6],[9,8,7],[5,3,1]])
In [69]: a
Out[69]:
array([[1, 2, 3],
[4, 5, 6],
[9, 8, 7],
[5, 3, 1]])
In [70]: a.sort(axis = 1)
In [71]: a
Out[71]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[1, 3, 5]])
In [72]: a = np.array([[1,2,3],[4,5,6],[9,8,7],[5,3,1]])
In [73]: a.sort(axis = 0)
In [74]: a
Out[74]:
array([[1, 2, 1],
[4, 3, 3],
[5, 5, 6],
[9, 8, 7]])
In [75]:
axis:表示排序的轴编号,默认为-1,代表沿着末尾的轴排序。
kind:表示排序的算法,默认为’quicksort’(快速排序)。
order:表示按哪个字段排序。
2.5.3 数组转置
熟悉数组的转置,可以通过T属性、transpose()方法、swapaxes()方法实现数组转置操作
2.5.4 随机数生成
1. numpy的random库
python里随机数生成主要有两种方式,一种是random库,另一种是numpy.random。我目前后一种用的比较多,因此就先介绍后一种中一些(我)可能常用的,第一种等有时间了再整理。

返回数据在[0,1)之间,具有均匀分布
语法:rand(d0,d1,d2…)
In [23]: np.random.rand(3,4)
Out[23]:
array([[0.58496659, 0.10987918, 0.73306144, 0.84831449],
[0.17575706, 0.03498951, 0.17905576, 0.58961677],
[0.66099259, 0.26250776, 0.2900706 , 0.16465037]])
返回具有标准正态分布,均值为0,方差为1
语法:randn(d0,d1,d2…)
In [24]: np.random.randn(3,4)
Out[24]:
array([[ 1.65273029, 0.73261963, 0.83941063, -0.52498145],
[-2.06807352, 0.20780148, 1.57492915, 0.98535171],
[ 0.76163315, 0.29797001, 0.79840516, 1.81377089]])
第3章 pandas基础
猿创征文|数据导入与预处理-第3章-pandas基础
3.1 series
3.1.1 创建series对象
In [1]: import pandas as pd
In [2]: ser_obj = pd.Series(['Python', 'Java', 'PHP'], index = ['one', 'two', 'three'])
In [3]: ser_obj
输出为:
Out[4]:
one Python
two Java
three PHP
dtype: object
3.1.2 Series属性
Series的index和values属性
In [5]: print(ser_obj.index,type(ser_obj.index))
Index(['one', 'two', 'three'], dtype='object') <class 'pandas.core.indexes.base.Index'>
In [6]: print(ser_obj.values,type(ser_obj.values))
['Python' 'Java' 'PHP'] <class 'numpy.ndarray'>
3.1.3 Series索引
包括:位置下标 / 标签索引 / 切片索引 / 布尔型索引
1. 位置索引
# 位置下标,类似序列
s = pd.Series(np.random.rand(5))
s
输出为:
Out[18]:
0 0.453055
1 0.208872
2 0.917167
3 0.238751
4 0.720561
dtype: float64
2. 标签索引
s = pd.Series(np.random.rand(5), index = ['a','b','c','d','e'])
s
输出为:
Out[22]:
a 0.037435
b 0.536072
c 0.051238
d 0.906477
e 0.474856
dtype: float64
3. 切片索引
# 切片索引
s1 = pd.Series(np.random.rand(5))
s2 = pd.Series(np.random.rand(5), index = ['a','b','c','d','e'])
print('-----')
print(s1[1:4],s1[4])
print(s2['a':'c'],s2['c'])
print(s2[0:3],s2[3])
print('-----')
输出为:
-----
1 0.792143
2 0.876208
3 0.542396
dtype: float64 0.3478167781738142
a 0.338142
b 0.314807
c 0.716646
dtype: float64 0.7166457177011984
a 0.338142
b 0.314807
c 0.716646
dtype: float64 0.7435841750851758
-----
4. 布尔索引
s = pd.Series(np.random.rand(3)*100)
s[4] = None # 添加一个空值
s
输出为:
Out[28]:
0 10.7214
1 72.9608
2 23.8594
4 None
dtype: object
bs1 = s > 50
print(bs1, type(bs1), bs1.dtype)
输出为:
0 False
1 True
2 False
4 False
dtype: bool <class ‘pandas.core.series.Series’> bool
3.1.5 Series基本操作技巧
本部分主要包括数据查看 / 重新索引 / 对齐 / 添加、修改、删除值等。
数据查看
# 数据查看
s = pd.Series(np.random.rand(50))
s.head(10)
s.tail()
重新索引reindex
# 重新索引reindex
# .reindex将会根据索引重新排序,如果当前索引不存在,则引入缺失值
s = pd.Series(np.random.rand(3), index = ['a','b','c'])
s1 = s.reindex(['c','b','a','d'])
数据对齐
# Series对齐 数据对齐
s1 = pd.Series(np.random.rand(3), index = ['Jack','Marry','Tom'])
s2 = pd.Series(np.random.rand(3), index = ['Wang','Jack','Marry'])
s1 + s2
输出为:
Out[41]:
Jack 0.954397
Marry 1.388826
Tom NaN
Wang NaN
dtype: float64
Series 和 ndarray 之间的主要区别是,Series 上的操作会根据标签自动对齐
index顺序不会影响数值计算,以标签来计算
空值和任何值计算结果仍然为空值
数据删除
In [44]:
# 删除:.drop
s = pd.Series(np.random.rand(5), index = list('ngjur'))
s1 = s.drop(['g','j'])
输出为:
Out[46]:
n 0.820846
u 0.321654
r 0.560360
dtype: float64
数据修改
# 修改
s = pd.Series(np.random.rand(3), index = ['a','b','c'])
s[['b','c']] = 200
s
输出为:
Out[58]:
a 0.933075
b 200.0
c 200.0
dtype: float64
3.2 DataFrame
3.2.1 Dataframe简介
DataFrame是一个结构类似于二维数组或表格的对象,与Series类对象相比,DataFrame类对象也由索引和数据组成,但该对象有两组索引,分别是行索引和列索引。
DataFrame类对象的行索引位于最左侧一列,列索引位于最上面一行,且每个列索引对应着一列数据。DataFrame类对象其实可以视为若干个公用行索引的Series类对象的组合。
3.2.2 创建DataFrame对象
demo_arr = np.array([['a', 'b', 'c'],['d', 'e', 'f']])
df_obj = pd.DataFrame(demo_arr,index = ['row_01','row_02'],columns=['col_01', 'col_02', 'col_03'])
df_obj
输出为:
col_01 col_02 col_03
row_01 a b c
row_02 d e f
3.2.3 Dataframe:索引
Dataframe既有行索引也有列索引,可以被看做由Series组成的字典(共用一个索引)
选择列 / 选择行 / 切片 / 布尔判断
1.选择行与列
# 选择行与列
df = pd.DataFrame(np.random.rand(12).reshape(3,4)*100,
index = ['one','two','three'],
columns = ['a','b','c','d'])
print(df)
data1 = df['a']
data2 = df[['a','c']]
print(data1,type(data1))
print(data2,type(data2))
print('-----')
# 按照列名选择列,只选择一列输出Series,选择多列输出Dataframe
data3 = df.loc['one']
data4 = df.loc[['one','two']]
print(data2,type(data3))
print(data3,type(data4))
# 按照index选择行,只选择一行输出Series,选择多行输出Dataframe
输出为:

2. df.loc[] - 按index选择行
# df.loc[] - 按index选择行
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1)
print(df2)
print('-----')
data1 = df1.loc['one']
data2 = df2.loc[1]
print(data1)
print(data2)
print('单标签索引\n-----')
# 单个标签索引,返回Series
# data3 = df1.loc[['two','three','five']] #不再支持不存在的index,本例为'five'
data4 = df2.loc[[3,2,1]]
#print(data3)
print(data4)
print('多标签索引\n-----')
# 多个标签索引,如果标签不存在,则返回NaN
# 顺序可变
data5 = df1.loc['one':'three']
data6 = df2.loc[1:3]
print(data5)
print(data6)
print('切片索引')
# 可以做切片对象
# 末端包含
# 核心笔记:df.loc[label]主要针对index选择行,同时支持指定index,及默认数字index
输出为:

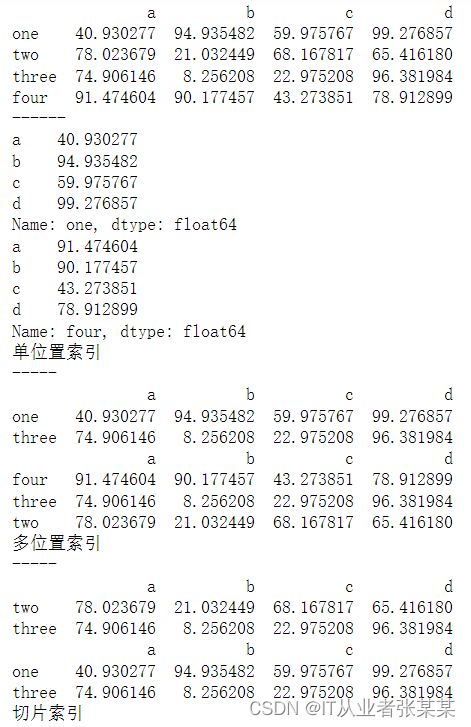
3. df.iloc[] - 按照整数位置(从轴的0到length-1)选择行
# df.iloc[] - 按照整数位置(从轴的0到length-1)选择行
# 类似list的索引,其顺序就是dataframe的整数位置,从0开始计
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
print(df.iloc[0])
print(df.iloc[-1])
#print(df.iloc[4])
print('单位置索引\n-----')
# 单位置索引
# 和loc索引不同,不能索引超出数据行数的整数位置
print(df.iloc[[0,2]])
print(df.iloc[[3,2,1]])
print('多位置索引\n-----')
# 多位置索引
# 顺序可变
print(df.iloc[1:3])
print(df.iloc[::2])
print('切片索引')
# 切片索引
# 末端不包含
输出为:
4. 布尔型索引
# 布尔型索引
# 和Series原理相同
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
b1 = df < 20
print(b1,type(b1))
print(df[b1]) # 也可以书写为 df[df < 20]
print('------')
# 不做索引则会对数据每个值进行判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b2 = df['a'] > 50
print(b2,type(b2))
print(df[b2]) # 也可以书写为 df[df['a'] > 50]
print('------')
# 单列做判断
# 索引结果保留 单列判断为True的行数据,包括其他列
b3 = df[['a','b']] > 50
print(b3,type(b3))
print(df[b3]) # 也可以书写为 df[df[['a','b']] > 50]
print('------')
# 多列做判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b4 = df.loc[['one','three']] < 50
print(b4,type(b4))
print(df[b4]) # 也可以书写为 df[df.loc[['one','three']] < 50]
print('------')
# 多行做判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
输出为:

3.2.4 DataFrame基本操作技巧
数据查看、转置 / 添加、修改、删除值 / 对齐 / 排序
1. 数据查看、转置
# 数据查看、转置
df = pd.DataFrame(np.random.rand(16).reshape(8,2)*100,
columns = ['a','b'])
print(df.head(2))
print(df.tail())
# .head()查看头部数据
# .tail()查看尾部数据
# 默认查看5条
print(df.T)
# .T 转置
2. 添加、修改、删除值
# 添加与修改
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
# 新增列/行并赋值
df['e'] = 10
df.loc[4] = 20
# 索引后直接修改值
df['e'] = 20
df[['a','c']] = 100
# del语句 - 删除列
del df['a']
# drop()删除行,inplace=False → 删除后生成新的数据,不改变原数据
df.drop([1,2])
# drop()删除列,需要加上axis = 1,inplace=False → 删除后生成新的数据,不改变原数据
df.drop(['d'], axis = 1)
3. 排序
排序1 - 按值排序 .sort_values
pandas中可以使用sort_values()方法将Series、DataFrmae类对象按值的大小排序。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False,
kind='quicksort', na_position='last', ignore_index=False)
by:表示根据指定的列索引名(axis=0或’index’)或行索引名(axis=1或’columns’)进行排序。
axis:表示轴编号(排序的方向),0代表按行排序,1代表按列排序。
ascending:表示是否以升序方式排序,默认为True。若设置为False,则表示按降序方式排序。
na_position:表示缺失值的显示位置,可以取值为’first’(首位)或’last’(末位)。
排序2 - 索引排序 .sort_index
pandas中提供了一个sort_index()方法,使用sort_index()方法可以让Series类对象DataFrame类对象按索引的大小进行排序。
sort_index(axis=0, level=None, ascending=True, inplace=False,
kind='quicksort', na_position='last', sort_remaining=True,
ignore_index: bool = False)
axis:表示轴编号(排序的方向),0代表按行排序,1代表按列排序。
level:表示按哪个索引层级排序,默认为None。
ascending:表示是否以升序方式排序,默认为True。若设置为False,则表示按降序方式排序。
kind:表示排序算法,可以取值为’quicksort’、 'mergesort’或’heapsort’,默认为‘quicksort’。
3.2.5 Index索引对象
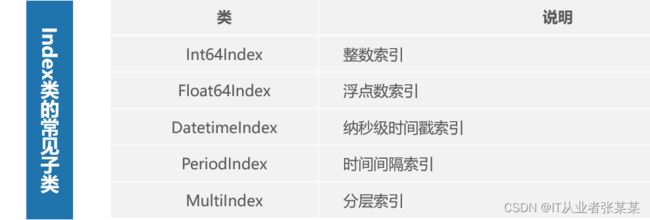
1.索引对象概述
Index类的常见子类,包括MultiIndex、Int64Index、DatetimeIndex等
掌握分层索引,可以通过多种方式熟练地创建分层索引。
在创建Series类对象或DataFrame类对象时,既可以使用自动生成的整数索引,也可以使用自定义的标签索引。无论哪种形式的索引,都是一个Index类的对象。
Index是一个基类,它派生了许多子类。
2. 索引对象操作
设置索引
In [8]:
info = pd.DataFrame([('William', 'C'), ('Smith', 'Java'), ('Parker', 'Python'), ('Phill', np.nan)], index=[1, 2, 3, 4], columns=('name', 'Language'))
info
输出为:
Out[8]:
name Language
1 William C
2 Smith Java
3 Parker Python
4 Phill NaN
set_index() 将已存在的列标签设置为 DataFrame 行索引。除了可以添加索引外,也可以替换已经存在的索引。比如您也可以把 Series 或者一个 DataFrme 设置成另一个 DataFrame 的索引。示例如下:
In [6]:
import pandas as pd
import numpy as np
info = pd.DataFrame({'Name': ['Parker', 'Terry', 'Smith', 'William'], 'Year': [2011, 2009, 2014, 2010], 'Leaves': [10, 15, 9, 4]})
info.set_index('Name')
输出为:
Out[6]:
Year Leaves
Name
Parker 2011 10
Terry 2009 15
Smith 2014 9
William 2010 4
重置索引
您可以使用 reset_index() 来恢复初始行索引,示例如下:
info = pd.DataFrame([('William', 'C'), ('Smith', 'Java'), ('Parker', 'Python'), ('Phill', np.nan)], index=[1, 2, 3, 4], columns=('name', 'Language'))
info
输出为:
Out[11]:
name Language
1 William C
2 Smith Java
3 Parker Python
4 Phill NaN
In [13]: info.reset_index()
输出为:
Out[13]:
index name Language
0 1 William C
1 2 Smith Java
2 3 Parker Python
3 4 Phill NaN
3. 使用索引对象操作数据
使用单层索引访问数据
无论是创建Series类对象还是创建DataFrame类对象,根本目的在于对Series类对象或DataFrame类对象中的数据进行处理,但在处理数据之前,需要先访问Series类对象或DataFrame类对象中的数据。
pandas中可以使用[]、loc、iloc、at和iat这几种方式访问Series类对象和DataFrame类对象的数据。
使用[]访问数据
变量[索引]
需要说明的是,若变量的值是一个Series类对象,则会根据索引获取该对象中对应的单个数据;若变量的值是一个DataFrame类对象,在使用“[索引]”访问数据时会将索引视为列索引,进而获取该列索引对应的一列数据。
使用loc和iloc访问数据
pandas中也可以使用loc和iloc访问数据。
变量.loc[索引]
变量.iloc[索引]
以上方式中,"loc[索引]"中的索引必须为自定义的标签索引,而"iloc[索引]"中的索引必须为自动生成的整数索引。需要说明的是,若变量是一个DataFrame类对象,它在使用"loc[索引]"或"iloc[索引]"访问数据时会将索引视为行索引,获取该索引对应的一行数据。
使用at和iat访问数据
pandas中还可以使用at和iat访问数据,与前两种方式相比,这种方式可以访问DataFrame类对象的单个数据。
变量.at[行索引, 列索引]
变量.iat[行索引, 列索引]
以上方式中,"at[行索引, 列索引]"中的索引必须为自定义的标签索引,"iat[行索引, 列索引]"中的索引必须为自动生成的整数索引。
使用分层索引访问数据
掌握分层索引的使用方式,可以通过[]、loc和iloc访问Series类对象和DataFrame类对象的数据
pandas中除了可以通过简单的单层索引访问数据外,还可以通过复杂的分层索引访问数据。与单层索引相比,分层索引只适用于[]、loc和iloc,且用法大致相同。
使用[]访问数据
由于分层索引的索引层数比单层索引多,在使用[]方式访问数据时,需要根据不同的需求传入不同层级的索引。
变量[第一层索引]
变量[第一层索引][第二层索引]
以上方式中,使用
变量[第一层索引]
可以访问第一层索引嵌套的第二层索引及其对应的数据;
使用
变量[第一层索引][第二层索引]
可以访问第二层索引对应的数据。
使用loc和iloc访问数据
使用iloc和loc也可以访问具有分层索引的Series类对象或DataFrame类对象。
变量.loc[第一层索引] # 访问第一层索引对应的数据
变量.loc[第一层索引][第二层索引] # 访问第二层索引对应的数据
变量.iloc[整数索引] # 访问第二层索引对应的数据
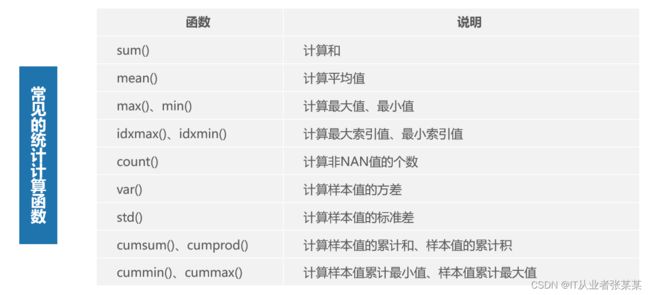
3.3 统计计算与统计描述
常见的统计计算函数