【节点分类】python实现:4种(GNN,GAN,SAGE,APPNP)图神经网络(-dgl库-pytorch-cuda-)
信息系统建模作业,要求是使用四种不同的节点表征方法两个3k+数据集
环境:pytorch cuda11.1 dgl-0.6.1
(cuda环境配置指路:我发的第一篇文章)
dgl库各种网络功能介绍:
https://zhuanlan.zhihu.com/p/161853672


参考代码资料:
GNN
GAT
SAGE
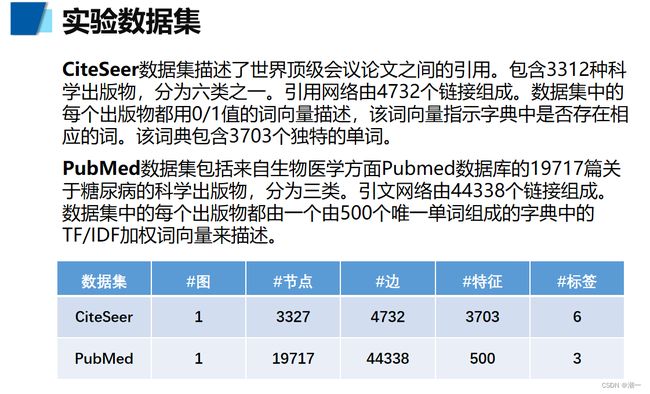
数据集:CiteSeer PubMed
目录
- GraphConv基础图卷积
- GATConv注意力机制
- SAGEConv采样聚类适用于大规模图
- APPNPConv-PageRank的改良版本
- 分类结果
GraphConv基础图卷积
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.data import citation_graph as citegrh
from dgl.nn.pytorch.conv.graphconv import GraphConv
#加载数据集,另一个数据集使用citegrh.load_pubmed()
dataset = citegrh.load_citeseer()
print('Number of categories:', dataset.num_classes)
#dataset是list,数据集为单图,g是graph类
g = dataset[0]
#数据放在gpu上
g = g.to('cuda')
#构造网络
class GCN(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(GCN, self).__init__()
self.conv1 = GraphConv(in_feats, h_feats) #特征维度映射
self.conv2 = GraphConv(h_feats, num_classes) #映射到节点类别
def forward(self, g, in_feat):
# g:数据Graph信息,经过归一化的邻接矩阵
# in_feat:节点初始化特征信息
h = self.conv1(g, in_feat)
h = F.relu(h)
h = self.conv2(g, h)
return h
# 实例化GCN模型在gpu上,hidden维度设定为16,输入维度和输出维度由数据集确定。
model = GCN(g.ndata['feat'].shape[1], 16, dataset.num_classes).to('cuda')
#训练网络
def train(g, model):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_val_acc = 0
best_test_acc = 0
#.ndata属性是一个dict,含五个key
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
val_mask = g.ndata['val_mask']
test_mask = g.ndata['test_mask']
for e in range(100):
# Forward
logits = model(g, features)
# Compute prediction
pred = logits.argmax(1) #每个样本全连接输出中最大的值,预测值
# Compute loss
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print('In epoch {}, loss: {:.3f}, val acc: {:.3f} (best {:.3f}), test acc: {:.3f} (best {:.3f})'.format(
e, loss, val_acc, best_val_acc, test_acc, best_test_acc))
train(g, model)
GATConv注意力机制
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.data import citation_graph as citegrh
import time
def load_data():
data = citegrh.load_pubmed() #list
g = data[0] # 单图
g = g.to('cuda') #放到gpu上
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
test_mask = g.ndata['test_mask']
val_mask = g.ndata['val_mask']
return g, features, labels, train_mask, test_mask, val_mask
#构造注意力图网络
class GATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim):
super(GATLayer, self).__init__()
self.g = g
# step1 : 下层嵌入的线性变换
self.fc = nn.Linear(in_dim, out_dim, bias=False)
# step2 : 计算邻居节点对的非标准化注意力得分
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
def edge_attention(self, edges):
# 计算step2需要的edge UDF
z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
a = self.attn_fc(z2)
return {'e': F.leaky_relu(a)}
def message_func(self, edges):
# step 3 & 4需要的message UDF
return {'z': edges.src['z'], 'e': edges.data['e']}
def reduce_func(self, nodes):
# 3 & 4 reduce UDF
# step3 : 标准化每个节点的入边的注意力得分
alpha = F.softmax(nodes.mailbox['e'], dim=1)
# step4 : 聚合邻居节点的嵌入信息,并按照注意力得分缩放
h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
return {'h': h}
def forward(self, h):
# step1
z = self.fc(h)
self.g.ndata['z'] = z
# step2
self.g.apply_edges(self.edge_attention)
# step 3 & 4
self.g.update_all(self.message_func, self.reduce_func)
return self.g.ndata.pop('h')
# 用单头注意力构建多头注意力层
class MultiHeadGATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim, num_heads, merge='cat'):
super(MultiHeadGATLayer, self).__init__()
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(GATLayer(g, in_dim, out_dim))
self.merge = merge
def forward(self, h):
head_outs = [attn_head(h) for attn_head in self.heads]
if self.merge == 'cat':
# concat 输出特征
return torch.cat(head_outs, dim=1)
else:
# 聚合信息,用mean方法
return torch.mean(torch.stack(head_outs))
class GAT(nn.Module):
def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
super(GAT, self).__init__()
self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
# 输入维度是hidden_dim * num_heads,输出是多头连接的
# 输出层是一个注意力头
self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
def forward(self, h):
h = self.layer1(h)
h = F.elu(h)
h = self.layer2(h)
return h
# 加载数据
g, features, labels, train_mask, test_mask, val_mask = load_data()
# 实例化网络,两个注意力头,每个头的 hidden size = 8
net = GAT(g,in_dim=features.size()[1],hidden_dim=8,out_dim=7,num_heads=2).to('cuda')
# create optimizer
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
best_val_acc = 0
best_test_acc = 0
# main loop
dur = []
for epoch in range(100):
if epoch >= 3:
t0 = time.time()
logits = net(features)
# Compute prediction
pred = logits.argmax(1)
# Compute loss
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 5 == 0:
print('In epoch {}, loss: {:.3f}, val acc: {:.3f} (best {:.3f}), test acc: {:.3f} (best {:.3f})'.format(
epoch, loss, val_acc, best_val_acc, test_acc, best_test_acc))
SAGEConv采样聚类适用于大规模图
import dgl
import numpy as np
import torch
import torch as th
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from dgl.nn.pytorch.conv.sageconv import SAGEConv
import time
from dgl.data import citation_graph
import tqdm
# 邻居采样器
class NeighborSampler(object):
def __init__(self, g, fanouts):
"""
g 为 DGLGraph;
fanouts 为采样节点的数量,两个参数,分别指一阶邻居采样和二阶邻居采样数
"""
self.g = g
self.fanouts = fanouts
def sample_blocks(self, seeds):
seeds = th.LongTensor(np.asarray(seeds))
blocks = []
for fanout in self.fanouts:
# 对每个节点实现邻居采样,返回对应子图
# replace=True 用采样节点代替所有邻居节点
frontier = dgl.sampling.sample_neighbors(g, seeds, fanout, replace=True)
# 将子图frontier转为可以传递消息的二部图
block = dgl.to_block(frontier, seeds)
# 获取新图的源节点作为种子节点
# srcdata表示源节点信息,因采样和聚合是相反的操作过程
seeds = block.srcdata[dgl.NID]
blocks.insert(0, block)
return blocks
# 构建适用于大图的sage网络
class GraphSAGE(nn.Module):
def __init__(self,
in_feats,
n_hidden,
n_classes,
n_layers,
activation,
dropout):
super().__init__()
self.n_layers = n_layers
self.n_hidden = n_hidden
self.n_classes = n_classes
self.layers = nn.ModuleList()
# 输入层,四种聚合方式,此处使用"gcn"
# 参数 : 输入特征,输出特征,聚合方式(特征drop概率=0,输出层bias=True,归一化=None,更新节点特征的激活函数=None)
self.layers.append(SAGEConv(in_feats, n_hidden, 'gcn'))
# 隐藏层
for i in range(1, n_layers - 1):
self.layers.append(SAGEConv(n_hidden, n_hidden, 'gcn'))
# 输出层
self.layers.append(SAGEConv(n_hidden, n_classes, 'gcn'))
self.dropout = nn.Dropout(dropout)
self.activation = activation
# block是采样获得的子图(二部图)
# x表示节点特征
def forward(self, blocks, x):
h = x
for l, (layer, block) in enumerate(zip(self.layers, blocks)):
h_dst = h[:block.number_of_dst_nodes()]
h = layer(block, (h, h_dst))
if l != len(self.layers) - 1:
h = self.activation(h)
h = self.dropout(h)
return h
# 用于评估测试
def inference(self, g, x, batch_size):
nodes = th.arange(g.number_of_nodes())
for l, layer in enumerate(self.layers):
y = th.zeros(g.number_of_nodes(),
self.n_hidden if l != len(self.layers) - 1 else self.n_classes)
for start in tqdm.trange(0, len(nodes), batch_size):
end = start + batch_size
batch_nodes = nodes[start:end]
block = dgl.to_block(dgl.in_subgraph(g, batch_nodes), batch_nodes)
input_nodes = block.srcdata[dgl.NID]
h = x[input_nodes]
h_dst = h[:block.number_of_dst_nodes()]
h = layer(block, (h, h_dst))
if l != len(self.layers) - 1:
h = self.activation(h)
h = self.dropout(h)
y[start:end] = h.cpu()
x = y
return y
# 计算准确率
def evaluate(model, g, inputs, labels, val_mask, batch_size):
"""
评估模型,调用 model 的 inference 函数
"""
model.eval()
with torch.no_grad():
label_pred = model.inference(g, inputs, batch_size)
model.train()
return (torch.argmax(label_pred[val_mask], dim=1) == labels[val_mask]).float().sum() / len(label_pred[val_mask])
def load_subtensor(g, labels, seeds, input_nodes, device):
"""
将一组节点的特征和标签复制到 GPU 上。
"""
batch_inputs = g.ndata['features'][input_nodes].to(device)
batch_labels = labels[seeds].to(device)
return batch_inputs, batch_labels
# 参数设置
gpu = 0
num_epochs = 50
num_hidden = 16
num_layers = 2
fan_out = '5,10'# 一阶采样5,二阶10
batch_size = 50
log_every = 1 # 记录日志的频率
eval_every = 5
lr = 0.001
dropout = 0.5
num_workers = 0
if gpu >= 0:
device = th.device('cuda:%d' % gpu)
else:
device = th.device('cpu')
# 读取数据,另一个数据集使用citation_graph.CiteseerGraphDataset()
data = citation_graph.PubmedGraphDataset()
graph = data[0] # 取单图
train_mask = graph.ndata['train_mask']
val_mask = graph.ndata['val_mask']
test_mask = graph.ndata['test_mask']
features = graph.ndata['feat']
in_feats = features.shape[1]
labels = graph.ndata['label']
n_classes = data.num_classes
# Construct graph
g = data.__getitem__(0) #为DGL.Graph类
g.ndata['features'] = features
train_nid = th.LongTensor(np.nonzero(train_mask)[0])
val_nid = th.LongTensor(np.nonzero(val_mask)[0])
train_mask = th.BoolTensor(train_mask)
val_mask = th.BoolTensor(val_mask)
test_mask = th.BoolTensor(test_mask)
# Create sampler
sampler = NeighborSampler(g, [int(fanout) for fanout in fan_out.split(',')])
# Create PyTorch DataLoader for constructing blocks
dataloader = DataLoader(
dataset=train_nid.numpy(),
batch_size=batch_size,
collate_fn=sampler.sample_blocks,
shuffle=True,
drop_last=False,
num_workers=num_workers)
# Define model and optimizer
model = GraphSAGE(in_feats, num_hidden, n_classes, num_layers, F.relu, dropout)
loss_fcn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# Training loop
best_val_acc = 0
for epoch in range(num_epochs):
for step, blocks in enumerate(dataloader):
tic_step = time.time()
input_nodes = blocks[0].srcdata[dgl.NID] #特殊二部图,输入节点的特征向量
seeds = blocks[-1].dstdata[dgl.NID] #输出节点的标签
# Load the input features as well as output labels
batch_inputs, batch_labels = load_subtensor(g, labels, seeds, input_nodes, device) #输入节点的特征和标签
# Compute loss and prediction
batch_inputs = batch_inputs.to("cpu")
batch_labels = batch_labels.to("cpu")
batch_pred = model(blocks, batch_inputs).to(device)
batch_pred = batch_pred.to("cpu")
loss = loss_fcn(batch_pred, batch_labels).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('| Loss {:.4f}'.format(loss.item()))
if epoch % 5 == 0:
train_acc = evaluate(model, g, g.ndata['features'], labels, train_mask, batch_size)
val_acc = evaluate(model, g, g.ndata['features'], labels, val_mask, batch_size)
print('Epoch {:05d} | Val ACC {:.4f} | Train ACC {:.4f}'.format(epoch, val_acc.item(), train_acc.item()))
# 模型训练完毕,检查test集合的acc
acc_test = evaluate(model, g, g.ndata['features'], labels, test_mask, batch_size)
print('Test ACC: %.4f' % (acc_test.item()))
APPNPConv-PageRank的改良版本
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.data import citation_graph as citegrh
from dgl.nn.pytorch.conv.graphconv import GraphConv
from dgl.nn.pytorch.conv.appnpconv import APPNPConv
dataset = citegrh.load_citeseer() #更换数据集使用citegrh.load_pubmed()
print('Number of categories:', dataset.num_classes)
# 单图
g = dataset[0]
# 数据放在gpu上
g = g.to('cuda')
# 构造APPNP网络,该网络使用类似PageRank框架更新节点嵌入
class APPNP(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(APPNP, self).__init__()
self.conv1 = GraphConv(in_feats, h_feats)
# APPNP层,特征维度不变。
'''
k : int, The number of iterations
alpha : float, The teleport probability
'''
self.conv2 = APPNPConv(k=3, alpha=0.5)
# 维度映射到节点类别
self.conv3 = GraphConv(h_feats, num_classes)
def forward(self, g, in_feat):
h1 = self.conv1(g, in_feat)
h2 = self.conv2(g, h1)
h = self.conv2(g, h2)
return h
# 实例化到gpu,hidden维度设定为16,输入维度和输出维度由数据集确定。
model = APPNP(g.ndata['feat'].shape[1], 16, dataset.num_classes).to('cuda')
def train(g, model):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_val_acc = 0
best_test_acc = 0
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
val_mask = g.ndata['val_mask']
test_mask = g.ndata['test_mask']
for e in range(3000):
# Forward
logits = model(g, features)
# Compute prediction
pred = logits.argmax(1) #每个样本全连接输出中最大的值,预测值
# Compute loss
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print('In epoch {}, loss: {:.3f}, val acc: {:.3f} (best {:.3f}), test acc: {:.3f} (best {:.3f})'.format(
e, loss, val_acc, best_val_acc, test_acc, best_test_acc))
train(g, model)
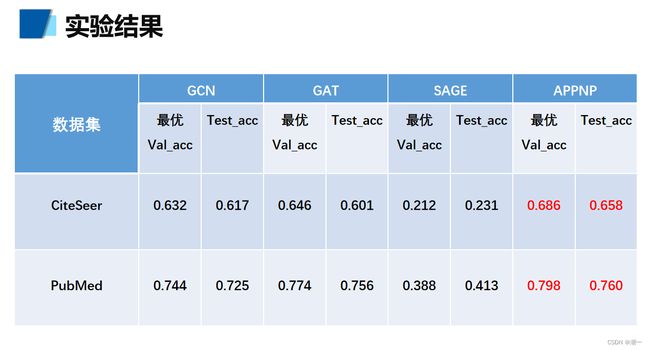
分类结果