论文笔记:Cross-Lingual Semantic Role Labeling with High-Quality Translated Training Corpus
基于高质量翻译训练语料库的跨语言语义角色标注
- 摘要
- 介绍
- 2 相关工作
- 3 SRL Translation(SRL 翻译)
- 4 The SRL Model
-
- 4.1 Word Representation(词语表征)
- 4.2 Encoding Layer
- 4.3 Output Layer
- 5 Experiments
-
- 5.1 Universal Proposition Bank
- 5.2 SRL Translation
- 5.3 Settings
- 5.4 Cross-Lingual Transfer from English
- 5.5 Multi-Source Transfer(多源传输)
- 5.6 Analysis
- 6 Conclusion
摘要
许多研究工作致力于语义角色标记(SRL),这对于自然语言理解至关重要。当大规模语料库可用于资源丰富的语言(如英语)时,监督方法取得了令人印象深刻的表现。而对于没有注释 SRL 数据集的低资源语言,获得有竞争力的性能仍然具有挑战性。跨语言 SRL 是解决该问题的一种很有前途的方法,它在模型转移和注释投影(model transferring and annotation projection) 的帮助下取得了很大进展。在本文中,我们提出了一种基于语料库翻译的新替代方案,从源黄金标准 SRL 注释构建目标语言的高质量训练数据集。在 Universal Proposition Bank 上的实验结果表明,基于翻译的方法非常有效,并且自动伪数据集可以显着提高目标语言 SRL 的性能。
介绍
语义角色标注(SRL)旨在捕捉句子的高级含义,如谁对谁做了什么,是促进广泛的自然语言处理(NLP)任务的基础任务。目前,由于有大量的标注数据,关于SRL的大部分研究工作都致力于英语。在这一点上,跨语言的SRL,特别是将资源丰富的源语言(如英语)的优势转移到标记数据稀缺甚至不可用的目标语言的SRL是非常重要的。
前人对跨语言SRL的研究大致可以分为两大类:模型迁移和标注投影。
前者基于语言无关的特征构建跨语言模型,例如跨语言单词表示和通用词性(POS)标签,可以直接将其转换为目标语言。后者基于源语言和目标语言之间的大规模平行语料库,其中源侧句子由源 SRL 标签器自动使用 SRL 标签注释,然后将源注释投影到目标侧句子上单词对齐。此外,标注投影可以自然地与模型传递相结合。
特别是,由于源端自动注释,注释投影中投影的SRL标记可能包含很多噪声。一个简单的解决方案是基于翻译的方法,该方法已被证明对跨语言依赖分析有效 。其核心思想是直接将黄金标准源训练数据翻译成目标语言,避免了源注释质量低下的问题。幸运的是,由于近年来神经机器翻译(NMT)的巨大进步,这种方法在跨语言迁移方面有很大的潜力。
SRL自动标注演示
对于源语言自动注释,所以投影到目标语言上可能包含噪音,为什么翻译过来就可以避免注释质量低了?
为此,本文研究了基于翻译的跨语言SRL方法。图1说明了以前的方法之间的差异。将源语言训练语料库中的句子翻译成目标语言,然后将源SRL注释投影到目标端,生成一组高质量的目标语言SRL语料库,用于训练目标SRL模型。进一步,我们将黄金标准源语料库和翻译目标语料库合并在一起,这可以看作是基于翻译的方法和模型转换的结合。我们的基线是一个简单的BiLSTM CRF模型(目前还不知道是啥),使用多语言语境化的单词表示(Peters等人,2018年;Devlin等人,2019年)。为了更好地探索混合语料库,我们采用了参数生成网络(PGN)(也还不知道是啥)来增强BiLSTM模块,该模块可以有效地捕捉语言差异(Platanios等人,2018年;Jia等人,2019年)。

上面是语料库翻译,下面是注释投影
(这个图里面Auto-predicted指的是什么意思,自动标注SRL吗?)
我们基于 Universal Proposition Bank corpus (一种语料库)(v1.0) (Akbik et al., 2015; Akbik and Li, 2016) 对七种语言进行实验。首先,我们验证了我们的方法在单源 SRL 迁移中的有效性,其中英语作为源语言,其余语言作为目标语言。结果表明,基于翻译的方法对于跨语言 SRL 非常有效,并且在使用 PGN-BiLSTM 时性能进一步提高。此外,我们对多源 SRL 迁移进行了实验,其中对于每种目标语言,所有剩余的六种语言都用作源语言(这里的意思就是我训练的时候使用多种语言,迁移到其他语言上的效果)。可以观察到与单源设置相同的趋势。我们对这两种设置进行了详细的分析工作,以全面了解我们提出的方法。
总之,我们在这项工作中做出了以下两个主要贡献:
-
我们介绍了基于翻译的无监督跨语言 SRL 方法的第一项工作。我们为目标语言构建了一个高质量的伪训练语料库,然后在一系列设置下验证语料库的有效性。
-
我们利用多语言上下文词表示,并使用 PGNBiLSTM 模型加强多语言模型训练。
2 相关工作
了解语义角色标注SRL(Semantic Role Labeling)
语义角色标注(Semantic Role Labelling)
3 SRL Translation(SRL 翻译)
我们通过完全翻译从goldstandard源数据中提取自动目标数据,然后通过对齐(如何对齐的?—投影)将SRL谓词和参数投影到相应的单词中,自动生成目标语言的最终翻译SRL语料库。该方法已被证明对跨语言依赖分析有效(Tiedeman等人,2014年;Tiedeman,2015年;Tiedeman和Agic,2016年;Zhang等人,2019年)。与标注投影相比,我们可以在源端保证标注质量,因此也期望更高质量的目标语料库。此外,基于依赖关系的SRL可以通过这种方法受益更多,因为只需要将谓词词及其参数投影到目标端,而依赖关系解析应该涉及所有句子词。整个过程由两个步骤完成:翻译和投影。
上面那个翻译自动对齐的意思就是说,我们通过自动标注源语言的SRL,翻译的话,原来的是什么样的谓词,翻译过来应该保持不变,也就是原来是主语翻译过来他还是主语,原来是名词翻译过来还是名词。
Translating。首先,我们使用最先进的翻译系统为源SRL数据的句子生成目标翻译。给出一个源语句e1··en,我们将其翻译成目标语言的f1··fm。值得注意的是,最近在NMT方面取得的令人印象深刻的进展(Bahdanaau等人,2015年;Wu等人,2016年)极大地促进了我们的工作,这使我们的方法具有高质量的翻译。
Projecting. 然后,我们将源语句e1··en的相应谓词或参数增量投射到目标语句f1··fm(这个投影到目标语句是如何实现的?)。我们采用两种信息来辅助投影:(1)从源词ei到fj的对齐概率a(fj | ei),这可以通过单词对齐工具来计算;(2)词性标签分布p(t∗|fj)的目标句子词,可以从受监督的目标语言词性标记中派生,其中∈ [1,n],j∈ [1,m]和t∗ 表示任意的POS标记。
我们只关注源句中与SRL相关的词,并在谓词层面逐步执行该过程。对于句子中的每个谓语,我们收集谓语词及其角色词,然后将它们的角色标签投射到目标句子中。
从形式上讲,对于这些单词中的每一个(即ei),我们都有SRL角色标记rei及其POS标记tei,它们都已经在UPB中进行了注释。首先,我们找到对齐概率最高的目标词fj,将该词fj视为承载语义角色rei的对应投影。然后,我们通过以下公式计算该预测的置信度得分:

是词对齐对应和词性标签一致性的联合概率。
一对一的目标-源对齐 2(a) 是投影的理想条件。但是,给定单词可能存在多对一的情况,从而导致目标语言单词的语义角色冲突。对于这些情况,我们优先考虑谓词预测,否则只保留最高置信度的预测。图 2(b) 显示了一个谓词-参数冲突示例,其中保留了谓词投影,图 2© 显示了一个参数-参数冲突示例,其中保留了具有较高置信度分数的投影。

最后,我们设置一个阈值α来去除低置信度的投影。如果谓词投影的置信度分数低于α,则该谓词的所有角色也将被删除。对于置信度低于α的参数投影,我们直接删除单个参数,而不影响其他投影。
4 The SRL Model
在这项工作中,我们关注基于依赖关系的SRL,识别给定谓词的语义角色(He等人,2017)。这项任务可以被视为一个标准的序列标记问题,这里利用了一个简单的多层BiLSTM CRF模型,该模型利用上下文化的单词表示法(He et al.,2018b;Xia et al.,2019;He et al.,2019)存档了最先进的性能。特别是,我们通过在BiLSTM上使用PGN模块(这是个啥?)(Hochreiter和Schmidhuber,1997),调整了模型,以更好地支持多语言输入。图3显示了总体架构。

SRL模型的总体架构
谓词指示符嵌入+POS表示词性标记+词表征经过一个PGN-LSTM,传入CRFs
(下面这俩具体的东西还没看)
- PGN为了提升seq2seq模型预测出的Unknown Words的能力,我们引入PGN(指针生成网络,Pointer Generator Network),作用是来针对UNK问题中的OOV(超出词表外的词,Out of Vocabulary)进行处理,能够通过拷贝输入的词进行填充以满足句意的需要[1]。
- CRFs条件随机场是一种用于序列预测的判别模型。
4.1 Word Representation(词语表征)
给定特定语言的输入句子s=w1···wn,并且wp(p表示位置)是谓语词,我们使用三种特征来源来表示每个词: (1) 词形,(2)词性标记和(3)谓语指示符:
(就是根据这三个来表示一个句子)

其中t1··tn是输入句子的通用词性标记序列。对于词性标记和谓词指示符,我们使用嵌入方法获得它们的向量表示。 我们比较了跨语言 SRL 的三种词形表示:(1) 多语言词嵌入,(2) 多语言 ELMo 表示 (Peters et al., 2018),以及 (3) 多语言 BERT 表示 (Devlin et al., 2019) )。请注意,我们使用来自 BERT 输出的内部单词片段表示的平均向量作为完整的单词表示。
4.2 Encoding Layer
我们采用 PGN-BiLSTM (Platanios et al., 2018; Jia et al., 2019) 对输入序列 x1···xn 进行编码,这是首次引入用于跨域迁移学习以捕获域差异。在这里,我们将其用于旨在对语言特征进行建模的多语言设置。
与 vanilla BiLSTM 模块相比,PGN-BiLSTM 动态选择 BiLSTM 的语言感知参数。设 V 是 BiLSTM 单元的所有参数的扁平化向量,语言感知 VL 由以下公式产生:

其中 WPGN 表示 PGN-BiLSTM 中 vanilla BiLSTM 部分的参数,包括输入、遗忘、输出门和单元模块的权重,eL 是语言 L 的嵌入表示。 PGN-BiLSTM 的参数生成机制如图 4 所示。接下来,我们从 VL 导出模块参数以计算 BiLSTM 输出。整个过程可以形式化为:


它与普通 BiLSTM 的不同之处在于 eL 是获得 BiLSTM 参数的一个额外输入。具体来说,我们采用三层双向 PGNLSTM 作为编码器。
4.3 Output Layer
给定句子 s = w1 · · · wn 的编码器输出 h1 · · · hn,我们使用 CRF (Lafferty et al., 2001) 计算每个候选输出 y = y1 · · · yn 的概率:
其中 W 和 T 是 CRF 的参数,Z 是概率计算的归一化因子。 Viterbi 算法用于搜索最高概率的输出 SRL 标签序列。
5 Experiments
5.1 Universal Proposition Bank
我们的实验基于 Universal Proposition Bank (UPB, v1.0) 2,它建立在 Universal Dependency Treebank (UDT, v1.4)3 和 Proposition Bank (PB, v3.0)4 之上。在 UPB 中,跨所有语言构建一致的基于依赖关系的通用 SRL 注释。特别是,我们基于来自 UDT v1.4 的英语 EWT 子集和 PB v3.0 中的英语语料库组装了英语 SRL 数据集。最后,我们选择了总共七种语言作为我们的数据集,包括 IE 的英语 (EN) 和德语 (DE)。德语家族、法语 (FR)、意大利语 (IT)、西班牙语 (ES)5 和葡萄牙语 (PT) IE.Romance 家族和 Uralic 家族的芬兰语 (FI)。表1详细显示了数据统计。

表 1:UPB 的统计数据,其中 Fam。表示语言家族,IE.Ge 指印欧日耳曼语,IE.Ro 指印欧罗曼语,Ura 表示乌拉尔语。
5.2 SRL Translation
我们专注于无监督的跨语言SRL,假设没有黄金标准的目标语言SRL语料库可用。我们的目标是从黄金标准的源语言SRL数据集中通过语料库翻译来构建伪训练数据集。句子翻译采用谷歌翻译系统,并使用FastAlign工具包(Dyer等人,2013)来获得单词对齐。为了获得准确的词对齐,我们收集了一组平行的语料库来扩充fast Align7的训练数据集。翻译句子的通用词性标签是由有监督的单语词性标记器产生的,分别在相应的UDT v1.4数据集上进行训练。
5.3 Settings
Multi-lingual word representations. : 正如4.1节中提到的,我们调查了三种多语种单词的表征:
(1)单词嵌入(EMB):利用MUSE将所有单一语言的快速文本单词嵌入到通用空间中(Lample等人,2018年)。
(2)Elmo:使用七种语言的混合数据集来训练多语言Elmo(Mulcaire等人,2019年)。
(3)BERT:直接使用官方发布的多语种BERT(base, cased version)(Devlin et al., 2019).
Hyperparameters. 超参数 : 对于 SRL 翻译,只有一个超参数,即投影置信度阈值α,用于过滤低质量的翻译 SRL 句子。图 5 显示了在不同α 下每种语言在初步实验中的表现。因此,我们将所有语言的 α 普遍设置为 0.4。对于神经 SRL 模型,多语言词嵌入、ELMo 和 BERT 的维度大小分别为 300、1024 和 768。 POS 标记、谓词指示符和语言 ID 嵌入大小分别为 100、100 和 32。 LSTM 的隐藏大小设置为 650。我们利用批量大小为 50 的在线训练,并使用 Adam 算法优化模型参数,初始速率为 0.0005。训练在整个训练数据集上执行,双语迁移 80 次迭代和多语言迁移 300 次迭代,没有提前停止。
Baselines. : 为了测试我们的 PGN 模型的有效性,我们还将它与几个基线进行了比较。首先,我们使用 vanilla BiLSTM 代替 BASIC 来表示我们的模型,特别是,在整个工作中,该模型被用于所有单语训练。此外,我们采用了两个更强的基线,即郭等人提出的 MoE 模型。 (2018)和Chen等人提出的MAN-MoE模型。 (2019),分别。这两个模型都旨在基于多种语言的语料库有效地训练模型,类似于我们的 PGN 模型。
Evaluation :我们使用 F1 分数作为衡量每种目标语言模型性能的主要指标。每个模型训练五次并报告平均值。我们使用 Dan Bikel 的随机解析评估比较器进行显着性检验。
5.4 Cross-Lingual Transfer from English
我们首先分别进行了从英语源到其他六种目标语言的跨语言迁移实验,这一直是跨语言调查的典型设置(Wang et al., 2019)。结果总结在表2中。我们仅使用源语料库(SRC),仅使用翻译的目标语料库(TGT)和源和目标的混合语料库(SRC&TGT)列出了F-scores,比较了性能不同的多语言单词表示以及不同的多语言 SRL 模型。

Multilingual word representations.(多语言单词表示) : 首先,我们评估了三种不同的多语言单词表示的有效性。我们分别使用 SRC 和 TGT 语料库比较它们在两种设置下的表现。根据结果,我们发现多语言上下文化词表示(即 BERT 和 ELMo)在两种设置下都更好,这与之前的研究一致(Mulcaire 等人,2019;Schuster 等人,2019)。有趣的是,多语言 BERT 的表现比 ELMo 差,这可以解释为 ELMo 表示是基于涉及重点七种语言的语料库进行预训练的。这表明官方发布的多语种 BERT 可以进一步改进,因为单语种 BERT 已被证明比 ELMo 产生更好的性能。
Translated target. : 接下来,我们考虑将翻译后的目标仅作为训练数据来检查伪数据集的有效性。如表 2 所示,我们发现翻译后的数据集可以带来明显优于源基线整体语言的性能,导致平均 F1 得分增加 51.1− 44.4 = 6.7。结果表明,语料库翻译是跨语言SRL的一种有效方法。该观察结果与之前的跨语言依赖解析工作一致(Tiedemann 和 Agic,2016;Zhang 等人,2019)。通过直接的金标准语料库翻译,生成的伪训练数据不仅可以保持高质量的 SRL 注释,还可以有效地捕捉语言差异,从而获得比源基线模型更好的性能。
Combining source and pseudo target. ** :进一步,我们将伪翻译的目标语料库和源语言语料库结合在一起来训练目标SRL模型。根据表2中的数字,我们看到所有语言都可以实现进一步的改进**,平均改进为55.8-51.1=4.7(BASIC用于公平比较)。注意,由于几个源句在翻译过程中被过滤,这可能是获得收益的原因,我们通过设置α=0(即,不过滤句子)来进行更公平的线下比较。类似的收益仍然可以实现。考虑到翻译的句子在语义上与金本位源中的对应句子在语义上是相等的,可能的原因有两方面:(1)由于数据驱动的翻译模式,翻译的句子可能在语言表达上存在偏见;(2)语料库翻译中丢弃的冲突注释是重要的,这是对我们模型的补充。
Language-aware encoder. :最后,我们考察了PGN-BiLSTM模块在使用源和目标数据集的混合语料库进行训练时捕获特定语言信息的有效性。如表2所示,我们可以看到,PGN的语言感知编码器可以显著提高F1成绩,平均提高60.355.8=4.5。此外,我们还分别报告了MOE和MAN-MOE的结果,这两种方法也利用了语言信息。所有的结果都证明了特定语言信息的有效性,并且我们的PGN模型是最有效的。
5.5 Multi-Source Transfer(多源传输)
此外,我们研究了多源迁移学习的设置,其中除给定目标语言之外的所有其他语言都用作源语言,旨在全面研究我们基于翻译的方法的有效性。
(消融实验)
Overall performances.(整体表现) : 多源 SRL 迁移的结果如表 3 所示。通常,结果与源英语的单源跨语言迁移具有相似的趋势,其中多语言 ELMo 表现最好,在翻译目标上训练的 SRL 模型数据集显示出比使用源数据集训练的更好的性能,源语言和目标语言数据集的混合语料库带来了最好的性能,这可以通过我们最终的 PGN 模型和语言感知编码器进一步改进。我们还将 PGN 模型与 MoE 和 MAN-MoE 进行了比较,显示出稍好的性能,这表明了 PGN-BiLSTM 模块的有效性。此外,我们可以看到多源模型在所有情况下都优于单源模型,这与之前的研究(Lin et al., 2019)直观且一致。

Fine-grained bilingual transfer(细粒度的双语迁移) :接下来,我们通过检查每个源目标语言对的性能来研究单个双语 SRL 迁移,旨在发现哪种语言对目标语言最有利,并试图回答是否所有源语言都对目标语言有用。表 4 显示了结果,其中跨语言模型在源数据集和翻译目标数据集的混合语料库上进行训练。首先,我们可以看到属于一个家族的语言可以相互受益,在大多数情况下(即 EN-DE、FR-IT-ES-PT)带来比其他语言更好的性能。其次,All 表示的多源迁移能够在所有语言中获得更好的性能,这进一步证明了它相对于单源迁移的优势。

此外,我们详细研究了 PGN 模型,旨在了解它们对特定语言信息进行建模的能力。我们通过简单地可视化每个源-目标语言对的语言 ID 嵌入 eL 来检查它,其中描述了它们的欧几里得距离。直观地说,如果目标语言和源语言之间的距离更近,则可以获得更好的性能。图 6 显示了热图矩阵。我们可以看到整体趋势与表 4 的结果高度相似,这与我们的直觉是一致的。

5.6 Analysis
在这里,我们进行详细分析以了解翻译后的目标数据集的收益。我们选取三种有代表性的语言进行分析,包括德语(DE)、法语(FR)和芬兰语(FI),每个家庭一种语言,主要比较四种模型,包括三种模型(即SRC、TGT和SRC&TGT) PGN) 的英语单源迁移和多源迁移的最终 PGN 模型。
Performances by the SRL roles. : 首先,我们根据 SRL 角色研究跨语言的 SRL 性能。我们选择四个具有代表性的角色进行比较,包括 A0(代理)、A1(患者)、A2(工具、有益、属性)和 AM-TMP(时间),并报告它们的 F1 分数。图 7 显示了结果。整体来看,角色A0在所有语言和所有模型中取得了最好的F1分数,A1排名第二,A2和AM-TMP稍差。这种趋势可以通过这些标签的分布来解释,其中 A0 是最频繁的,A2 和 AM-TMP 的频率低于 A0 和 A1。第二个可能的原因可能是由于大多数 A0 和 A1 词是概念词,可以更容易地被跨语言模型转移。
此外,我们可以看到,所有三种语言和所有标签的不同模型的趋势都是相同的,其中多源传输表现最好,单源 SRC+TGT 排名第二,我们的基线模型是最后一个。观察结果与整体趋势一致,证明了稳定性,也进一步验证了我们提出的模型的有效性。

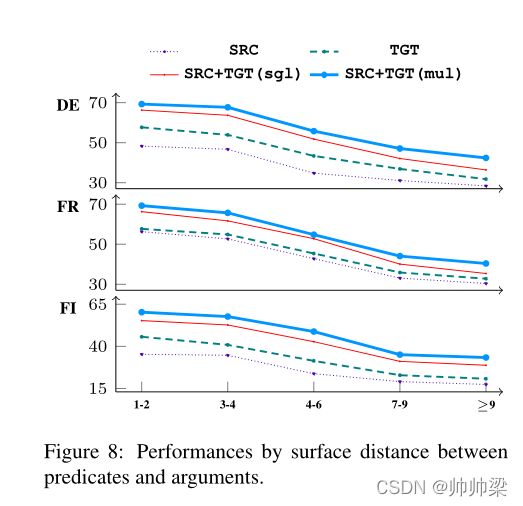
Performances by the distances to the predicate.(通过到谓词的距离来表现) :其次,我们根据与谓词的距离来研究 SRL 的性能。直观地说,长距离关系更加困难,因此我们预计 SRL 性能会随着距离的增加而下降,因为 SRL 实际上检测了角色词与其谓词之间的关系。图 8 显示了 F1 分数。首先,对于所有设置,我们可以看到 SRL 性能随着距离的增加而下降,这证实了我们的直觉。此外,不同模型之间的趋势与整体结果相同,证明了我们方法的有效性。
6 Conclusion
我们提出了一种基于翻译的跨语言 SRL 替代方案。关键思想是通过语料库翻译从源语言的黄金标准 SRL 注释构建目标语言的高质量数据集。此外,我们将黄金标准源 SRL 语料库和伪翻译目标语料库结合在一起,以增强跨语言 SRL 模型。我们研究了具有不同类型的多语言单词表示的跨语言 SRL 模型。此外,我们提出了一种 PGN-BiLSTM 编码器,以更好地利用不同语言的混合语料库。在 UPB v1.0 数据集上的实验结果表明,基于翻译的方法是一种有效的跨语言 SRL 迁移方法。通过使用所有选定语言的翻译数据集(包括单源和多源传输)可以实现显着改进。提供实验分析以深入了解所提出的方法。