【深度学习】纵览轻量化卷积神经网络:SqueezeNet、MobileNet、ShuffleNet、Xception
转自 | 机器之心
本文就近年提出的四个轻量化模型进行学习和对比,四个模型分别是:SqueezeNet、MobileNet、ShuffleNet、Xception。
目录
一、引言
二、轻量化模型
2.1 SqueezeNet
2.2 MobileNet
2.3 ShuffleNet
2.4 Xception
三、网络对比
一、引言
自 2012 年 AlexNet 以来,卷积神经网络(简称 CNN)在图像分类、图像分割、目标检测等领域获得广泛应用。随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 CNN 网络,如 VGG、GoogLeNet、ResNet、DenseNet 等。由于神经网络的性质,为了获得更好的性能,网络层数不断增加,从 7 层 AlexNet 到 16 层 VGG,再从 16 层 VGG 到 GoogLeNet 的 22 层,再到 152 层 ResNet,更有上千层的 ResNet 和 DenseNet。虽然网络性能得到了提高,但随之而来的就是效率问题。
效率问题主要是模型的存储问题和模型进行预测的速度问题(以下简称速度问题)
第一,存储问题。数百层网络有着大量的权值参数,保存大量权值参数对设备的内存要求很高;
第二,速度问题。在实际应用中,往往是毫秒级别,为了达到实际应用标准,要么提高处理器性能(看英特尔的提高速度就知道了,这点暂时不指望),要么就减少计算量。
只有解决 CNN 效率问题,才能让 CNN 走出实验室,更广泛的应用于移动端。对于效率问题,通常的方法是进行模型压缩(Model Compression),即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决速度问题。
相比于在已经训练好的模型上进行处理,轻量化模型模型设计则是另辟蹊径。轻量化模型设计主要思想在于设计更高效的「网络计算方式」(主要针对卷积方式),从而使网络参数减少的同时,不损失网络性能。
本文就近年提出的四个轻量化模型进行学习和对比,四个模型分别是:SqueezeNet、MobileNet、ShuffleNet、Xception。
(PS:以上四种均不是模型压缩方法!!)
以下是四个模型的作者团队及发表时间

其中 ShuffleNet 论文中引用了 SqueezeNet;Xception 论文中引用了 MobileNet
二、轻量化模型
由于这四种轻量化模型仅是在卷积方式上做了改变,因此本文仅对轻量化模型的创新点进行详细描述,对实验以及实现的细节感兴趣的朋友,请到论文中详细阅读。
2.1 SqueezeNet
SqueezeNet 由伯克利&斯坦福的研究人员合作发表于 ICLR-2017,论文标题:
《SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5MB》
命名:
从名字——SqueezeNet 就知道,本文的新意是 squeeze,squeeze 在 SqueezeNet 中表示一个 squeeze 层,该层采用 1*1 卷积核对上一层 feature map 进行卷积,主要目的是减少 feature map 的维数(维数即通道数,就是一个立方体的 feature map,切成一片一片的,一共有几片)。
创新点:
1. 采用不同于传统的卷积方式,提出 fire module;fire module 包含两部分:squeeze 层+expand 层
创新点与 inception 系列的思想非常接近!首先 squeeze 层,就是 1*1 卷积,其卷积核数要少于上一层 feature map 数,这个操作从 inception 系列开始就有了,并美其名曰压缩,个人觉得「压缩」更为妥当。
Expand 层分别用 1*1 和 3*3 卷积,然后 concat,这个操作在 inception 系列里面也有。
SqueezeNet 的核心在于 Fire module,Fire module 由两层构成,分别是 squeeze 层+expand 层,如下图 1 所示,squeeze 层是一个 1*1 卷积核的卷积层,expand 层是 1*1 和 3*3 卷积核的卷积层,expand 层中,把 1*1 和 3*3 得到的 feature map 进行 concat。
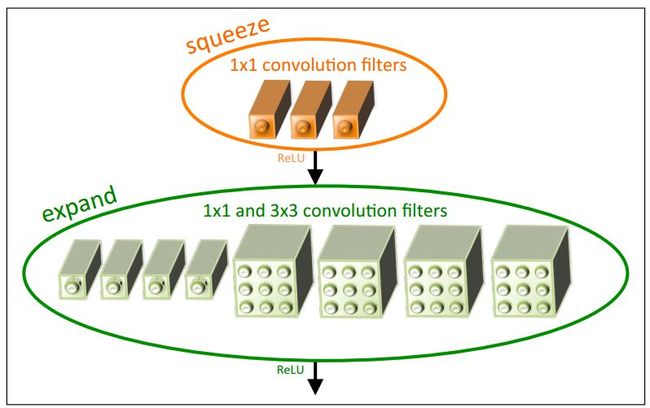
具体操作情况如下图所示:

Fire module 输入的 feature map 为 H*W*M 的,输出的 feature map 为 H*M*(e1+e3),可以看到 feature map 的分辨率是不变的,变的仅是维数,也就是通道数,这一点和 VGG 的思想一致。
首先,H*W*M 的 feature map 经过 Squeeze 层,得到 S1 个 feature map,这里的 S1 均是小于 M 的,以达到「压缩」的目的,详细思想可参考 Google 的 Inception 系列。
其次,H*W*S1 的特征图输入到 Expand 层,分别经过 1*1 卷积层和 3*3 卷积层进行卷积,再将结果进行 concat,得到 Fire module 的输出,为 H*M*(e1+e3) 的 feature map。
fire 模块有三个可调参数:S1,e1,e3,分别代表卷积核的个数,同时也表示对应输出 feature map 的维数,在文中提出的 SqueezeNet 结构中,e1=e3=4s1。
讲完 SqueezeNet 的核心——Fire module,看看 SqueezeNet 的网络结构,如下图所示:
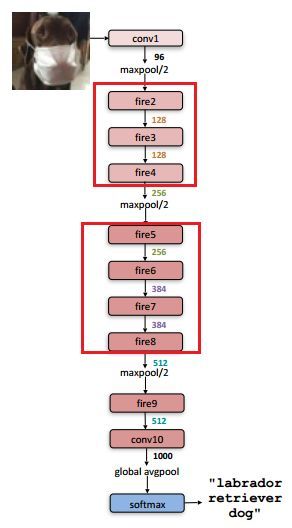
网络结构设计思想,同样与 VGG 的类似,堆叠的使用卷积操作,只不过这里堆叠的使用本文提出的 Fire module(图中用红框部分)
看看 Squezeenet 的参数数量以及性能:
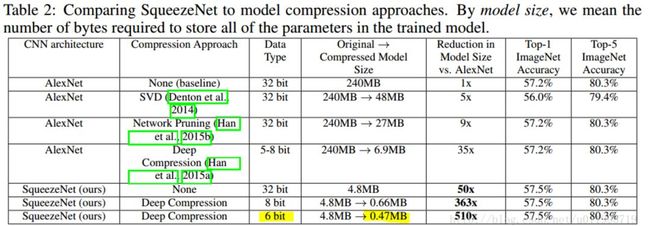
在这里可以看到,论文题目中提到的小于 0.5M,是采用了 Deep Compression 进行模型压缩之后的结果!!
看了上图再回头看一看论文题目:
SqueezeNet :AlexNet-level accuracy with 50x fewer parameters and <0.5MB
标!题!党!SqueezeNet < 0.5MB, 这个是用了别的模型压缩技术获得的,很容易让人误以为 SqueezeNet 可以压缩模型!!
SqueezeNet 小结:
1 Fire module 与 GoogLeNet 思想类似,采用 1*1 卷积对 feature map 的维数进行「压缩」,从而达到减少权值参数的目的;
2 采用与 VGG 类似的思想——堆叠的使用卷积,这里堆叠的使用 Fire module
SqueezeNet 与 GoogLeNet 和 VGG 的关系很大!
2.2 MobileNet
MobileNet 由 Google 团队提出,发表于 CVPR-2017,论文标题:
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
命名:
MobileNet 的命名是从它的应用场景考虑的,顾名思义就是能够在移动端使用的网络模型。
创新点:
1. 采用名为 depth-wise separable convolution 的卷积方式代替传统卷积方式,以达到减少网络权值参数的目的。
通过采用 depth-wise convolution 的卷积方式,达到:1. 减少参数数量 2. 提升运算速度。(这两点是要区别开的,参数少的不一定运算速度快!还要看计算方式!)
depth-wise convolution 不是 MobileNet 提出来的,也是借鉴,文中给的参考文献是 2014 年的博士论文——《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
depth-wise convolution 和 group convolution 是类似的,depth-wise convolution 是一个卷积核负责一部分 feature map,每个 feature map 只被一个卷积核卷积;group convolution 是一组卷积核负责一组 feature map,每组 feature map 只被一组卷积核卷积。Depth-wise convolution 可以看成是特殊的 group convolution,即每一个通道是一组。
MobileNets 精华在于卷积方式——depth-wise separable convolution;采用 depth-wise separable convolution,会涉及两个超参:Width Multiplier 和 Resolution Multiplier 这两个超参只是方便于设置要网络要设计为多小,方便于量化模型大小。
MobileNet 将标准卷积分成两步:
第一步 Depth-wise convolution, 即逐通道的卷积,一个卷积核负责一个通道,一个通道只被一个卷积核「滤波」;
第二步,Pointwise convolution,将 depth-wise convolution 得到的 feature map 再「串」起来,注意这个「串」是很重要的。「串」作何解?为什么还需要 pointwise convolution?作者说:However it only filters input channels, it does not combine them to create new features. Soan additional layer that computes a linear combination ofthe output of depth-wise convolution via 1 × 1 convolutionis needed in order to generate these new features。
从另外一个角度考虑,其实就是:输出的每一个 feature map 要包含输入层所有 feature map 的信息。然而仅采用 depth-wise convolution,是没办法做到这点,因此需要 pointwise convolution 的辅助。
「输出的每一个 feature map 要包含输入层所有 feature map 的信息」这个是所有采用 depth-wise convolution 操作的网络都要去解决的问题,ShuffleNet 中的命名就和这个有关!详细请看 2.3
Standard convolution、depth-wise convolution 和 pointwise convolution 示意图如下:

其中输入的 feature map 有 M 个,输出的 feature map 有 N 个。
对 Standard convolution 而言,是采用 N 个大小为 DK*DK 的卷积核进行操作(注意卷积核大小是 DK*DK, DK*DK*M 是具体运算时一个卷积核的大小!)
而 depth-wise convolution + pointwise convolution 需要的卷积核呢?
Depth-wise convolution :一个卷积核负责一个通道,一个通道只被一个卷积核卷积;则这里有 M 个 DK*DK 的卷积核;
Pointwise convolution:为了达到输出 N 个 feature map 的操作,所以采用 N 个 1*1 的卷积核进行卷积,这里的卷积方式和传统的卷积方式是一样的,只不过采用了 1*1 的卷积核;其目的就是让新的每一个 feature map 包含有上一层各个 feature map 的信息!在此理解为将 depth-wise convolution 的输出进行「串」起来。
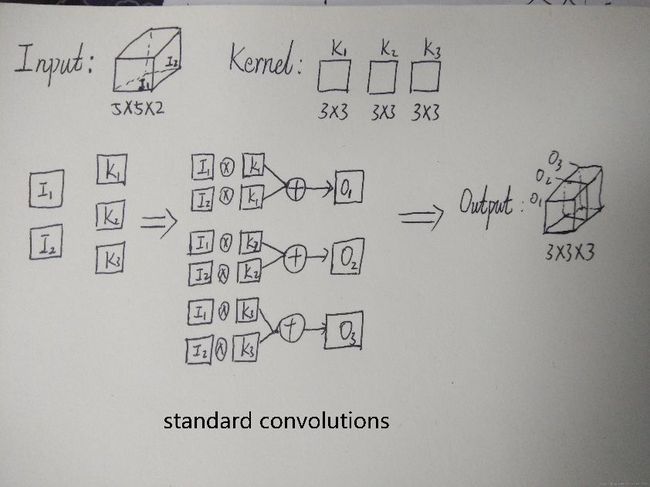
下面举例讲解 Standard convolution、depth-wise convolution 和 pointwise convolution。
假设输入的 feature map 是两个 5*5 的,即 5*5*2;输出 feature map 数量为 3,大小是 3*3(因为这里采用 3*3 卷积核)即 3*3*3。
标准卷积是将一个卷积核(3*3)复制 M 份(M=2), 让二维的卷积核(面包片)拓展到与输入 feature map 一样的面包块形状。
Standard 过程如下图,X 表示卷积,+表示对应像素点相加,可以看到对于 O1 来说,其与输入的每一个 feature map 都「发生关系」,包含输入的各个 feature map 的信息。
Depth-wise 过程如下图,可以看到 depth-wise convolution 得出的两个 feature map——fd1 和 fd2 分别只与 i1 和 i2「发生关系」,这就导致违背上面所承认的观点「输出的每一个 feature map 要包含输入层所有 feature map 的信息」,因而要引入 pointwise convolution。

那么计算量减少了多少呢?通过如下公式计算:
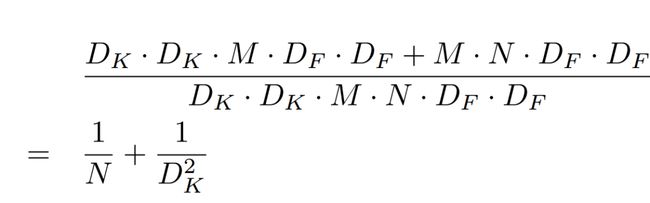
其中 DK 为标准卷积核大小,M 是输入 feature map 通道数,DF 为输入 feature map 大小,N 是输出 feature map 大小。本例中,DK=3,M=2,DF=5,N=3,参数的减少量主要就与卷积核大小 DK 有关。在本文 MobileNet 的卷积核采用 DK=3,则大约减少了 8~9 倍计算量。
看看 MobileNet 的网络结构,MobileNet 共 28 层,可以发现这里下采样的方式没有采用池化层,而是利用 depth-wise convolution 的时候将步长设置为 2,达到下采样的目的。
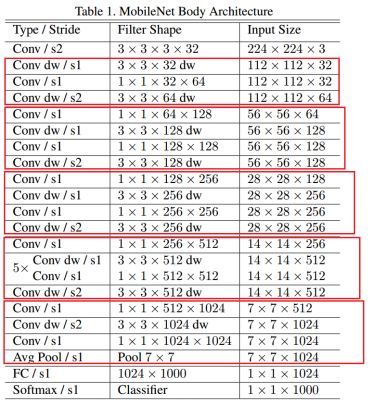
1.0 MobileNet-224 与 GoogLeNet 及 VGG-16 的对比:

可以发现,相较于 GoogLeNet,虽然参数差不多,都是一个量级的,但是在运算量上却小于 GoogLeNet 一个量级,这就得益于 depth-wise convolution!
MobileNet 小结:
1. 核心思想是采用 depth-wise convolution 操作,在相同的权值参数数量的情况下,相较于 standard convolution 操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
2. depth-wise convolution 的思想非首创,借鉴于 2014 年一篇博士论文:《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
3. 采用 depth-wise convolution 会有一个问题,就是导致「信息流通不畅」,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise convolution 解决这个问题。在后来,ShuffleNet 采用同样的思想对网络进行改进,只不过把 point-wise convolution 换成了 channel shuffle,然后给网络美其名曰 ShuffleNet,欲知后事如何,请看 2.3 ShuffleNet
2.3 ShuffleNet
ShuffleNet 是 Face++团队提出的,与 MobileNet 一样,发表于 CVPR-2017,但晚于 MobileNet 两个月才在 arXiv 上公开。论文标题:
《ShuffleNet:An Extremely Efficient Convolutional Neural Network for Mobile Devices》
命名:
一看名字 ShuffleNet,就知道 shuffle 是本文的重点,那么 shuffle 是什么?为什么要进行 shuffle?
shuffle 具体来说是 channel shuffle,是将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的「信息流通不畅」问题。(MobileNet 是用 point-wise convolution 解决的这个问题)
因此可知道 shuffle 不是什么网络都需要用的,是有一个前提,就是采用了 group convolution,才有可能需要 shuffle!!为什么说是有可能呢?因为可以用 point-wise convolution 来解决这个问题。
创新点:
1. 利用 group convolution 和 channel shuffle 这两个操作来设计卷积神经网络模型, 以减少模型使用的参数数量。
其中 group convolutiosn 非原创,而 channel shuffle 是原创。channel shuffle 因 group convolution 而起,正如论文中 3.1 标题:. Channel Shuffle for Group Convolution;
采用 group convolution 会导致信息流通不当,因此提出 channel shuffle,所以 channel shuffle 是有前提的,使用的话要注意!
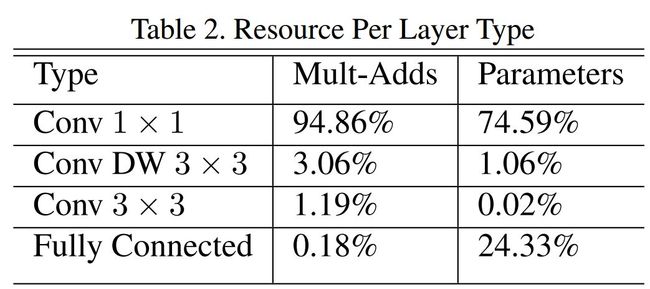
对比一下 MobileNet,采用 shuffle 替换掉 1*1 卷积,这样可以减少权值参数,而且是减少大量权值参数,因为在 MobileNet 中,1*1 卷积层有较多的卷积核,并且计算量巨大,MobileNet 每层的参数量和运算量如下图所示:
ShuffleNet 的创新点在于利用了 group convolution 和 channel shuffle,那么有必要看看 group convolution 和 channel shuffle。
Group convolution
Group convolution 自 Alexnet 就有,当时因为硬件限制而采用分组卷积;之后在 2016 年的 ResNeXt 中,表明采用 group convolution 可获得高效的网络;再有 Xception 和 MobileNet 均采用 depth-wise convolution, 这些都是最近出来的一系列轻量化网络模型。depth-wise convolution 具体操作可见 2.2 MobileNet 里边有简介。
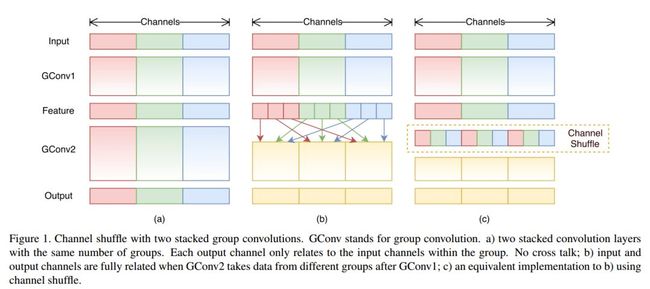
如下图 (a) 所示, 为了提升模型效率,采用 group convolution,但会有一个副作用,即:「outputs from a certain channel are only derived from a small fraction of input channels.」
于是采用 channel shuffle 来改善各组间「信息流通不畅」问题,如下图 (b) 所示。
具体方法为:把各组的 channel 平均分为 g(下图 g=3)份,然后依次序的重新构成 feature map
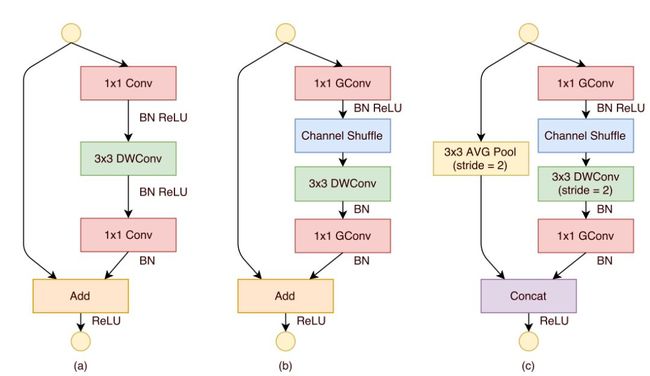
Channel shuffle 的操作非常简单,接下来看看 ShuffleNet,ShuffleNet 借鉴了 Resnet 的思想,从基本的 resnet 的 bottleneck unit 逐步演变得到 ShuffleNet 的 bottleneck unit,然后堆叠的使用 ShuffleNet bottleneck unit 获得 ShuffleNet;
下图展示了 ShuffleNet unit 的演化过程
图 (a):是一个带有 depth-wise convolution 的 bottleneck unit;
图 (b):作者在 (a) 的基础上进行变化,对 1*1 conv 换成 1*1 Gconv,并在第一个 1*1 Gconv 之后增加一个 channel shuffle 操作;
图 (c):在旁路增加了 AVG pool,目的是为了减小 feature map 的分辨率;因为分辨率小了,于是乎最后不采用 Add,而是 concat,从而「弥补」了分辨率减小而带来的信息损失。
文中提到两次,对于小型网络,多多使用通道,会比较好。
「this is critical for small networks, as tiny networks usually have an insufficient number of channels to process the information」
所以,以后若涉及小型网络,可考虑如何提升通道使用效率
至于实验比较,并没有给出模型参数量的大小比较,而是采用了 Complexity (MFLOPs) 指标,在相同的 Complexity (MFLOPs) 下,比较 ShuffleNet 和各个网络,还专门和 MobileNet 进行对比,由于 ShuffleNet 相较于 MobileNet 少了 1*1 卷积层,所以效率大大提高了嘛,贴个对比图随意感受一下好了

ShuffleNet 小结:
1. 与 MobileNet 一样采用了 depth-wise convolution,但是针对 depth-wise convolution 带来的副作用——「信息流通不畅」,ShuffleNet 采用了一个 channel shuffle 操作来解决。
2. 在网络拓扑方面,ShuffleNet 采用的是 resnet 的思想,而 mobielnet 采用的是 VGG 的思想,2.1 SqueezeNet 也是采用 VGG 的堆叠思想
2.4 Xception
Xception 并不是真正意义上的轻量化模型,只是其借鉴 depth-wise convolution,而 depth-wise convolution 又是上述几个轻量化模型的关键点,所以在此一并介绍,其思想非常值得借鉴。
Xception 是 Google 提出的,arXiv 的 V1 版本 于 2016 年 10 月公开。论文标题:
《Xception: Deep Learning with Depth-wise Separable Convolutions》
命名:
Xception 是基于 Inception-V3 的,而 X 表示 Extreme,为什么是 Extreme 呢?因为 Xception 做了一个加强的假设,这个假设就是:
we make the following hypothesis: that the mapping of cross-channels correlations and spatial correlations in the feature maps of convolutional neural networks can be entirely decoupled
创新点:
1. 借鉴(非采用)depth-wise convolution 改进 Inception V3
既然是改进了 Inception v3,那就得提一提关于 inception 的一下假设(思想)了。
「the fundamental hypothesis behind Inception is that cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly」
简单理解就是说,卷积的时候要将通道的卷积与空间的卷积进行分离,这样会比较好。(没有理论证明,只有实验证明,就当它是定理,接受就好了,现在大多数神经网络的论文都这样。
既然是在 Inception V3 上进行改进的,那么 Xception 是如何一步一步的从 Inception V3 演变而来。
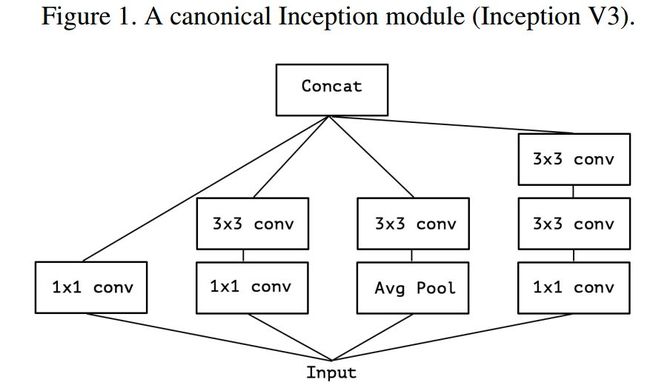
下图 1 是 Inception module,图 2 是作者简化了的 inception module(就是只保留 1*1 的那条「路」,如果带着 avg pool,后面怎么进一步假设嘛~)

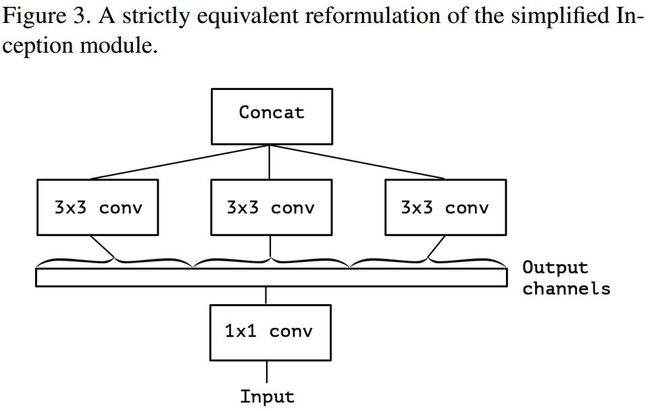
假设出一个简化版 inception module 之后,再进一步假设,把第一部分的 3 个 1*1 卷积核统一起来,变成一个 1*1 的,后面的 3 个 3*3 的分别「负责」一部分通道,如图 3 所示;最后提出「extreme」version of an Inception,module Xception 登场,,先用 1*1 卷积核对各通道之间(cross-channel)进行卷积,如图 4 所示,
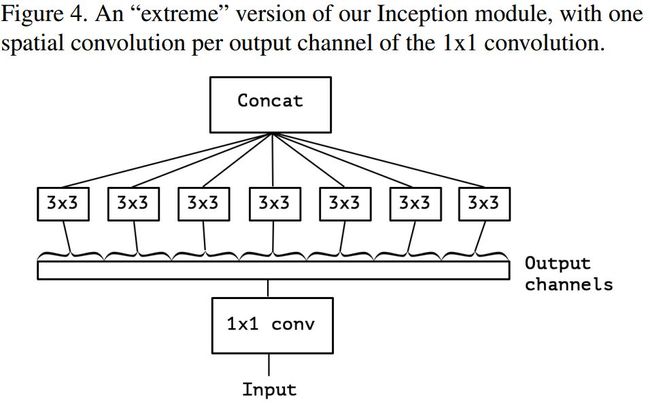
作者说了,这种卷积方式和 depth-wise convolution 几乎一样。Depth-wise convolution 较早用于网络设计是来自:Rigid-Motion Scatteringfor Image Classification,但是具体是哪一年提出,不得而知;至少 2012 年就有相关研究,再比如说 AlexNet,由于内存原因,AlexNet 分成两组卷积 ;想深入了解 Depth-wise convolution 的可以查阅本论文 2.Prior work,里面有详细介绍。
Xception 是借鉴 Rigid-Motion Scatteringfor Image Classification 的 Depth-wise convolution,是因为 Xception 与原版的 Depth-wise convolution 有两个不同之处
第一个:原版 Depth-wise convolution,先逐通道卷积,再 1*1 卷积; 而 Xception 是反过来,先 1*1 卷积,再逐通道卷积;
第二个:原版 Depth-wise convolution 的两个卷积之间是不带激活函数的,而 Xception 在经过 1*1 卷积之后会带上一个 Relu 的非线性激活函数;

Xception 结构如上图所示,共计 36 层分为 Entry flow;Middle flow;Exit flow。。
Entry flow 包含 8 个 conv;Middle flow 包含 3*8 =24 个 conv;Exit flow 包含 4 个 conv,所以 Xception 共计 36 层。
文中 Xception 实验部分是非常详细的,实现细节可参见论文。

Xception 小结:
Xception 是基于 Inception-V3,并结合了 depth-wise convolution,这样做的好处是提高网络效率,以及在同等参数量的情况下,在大规模数据集上,效果要优于 Inception-V3。这也提供了另外一种「轻量化」的思路:在硬件资源给定的情况下,尽可能的增加网络效率和性能,也可以理解为充分利用硬件资源。
三、网络对比
本文简单介绍了四个轻量化网络模型,分别是 SqueezeNet、 MobileNet、 ShuffleNet 和 Xception,前三个是真正意义上的轻量化网络,而 Xception 是为提升网络效率,在同等参数数量条件下获得更高的性能。
在此列出表格,对比四种网络是如何达到网络轻量化的。
实现轻量化技巧

这么一看就发现,轻量化主要得益于 depth-wise convolution,因此大家可以考虑采用 depth-wise convolution 来设计自己的轻量化网络,但是要注意「信息流通不畅问题」。
解决「信息流通不畅」的问题,MobileNet 采用了 point-wise convolution,ShuffleNet 采用的是 channel shuffle。MobileNet 相较于 ShuffleNet 使用了更多的卷积,计算量和参数量上是劣势,但是增加了非线性层数,理论上特征更抽象,更高级了;ShuffleNet 则省去 point-wise convolution,采用 channel shuffle,简单明了,省去卷积步骤,减少了参数量。
学习了几个轻量化网络的设计思想,可以看到,并没有突破性的进展,都是借鉴或直接使用前几年的研究成果。希望广大研究人员可以设计出更实在的轻量化网络。
通过这几篇论文的创新点,得出以下可认为是发 (Shui) 论文的 idea:
1. 采用 depth-wise convolution,再设计一个方法解决「信息流通不畅」问题,然后冠以美名 XX-Net。(看看 ShuffleNet 就是)
2. 针对 depth-wise convolution 作文章,卷积方式不是千奇百怪么?各种卷积方式可参考 Github(https://github.com/vdumoulin/conv_arithmetic),挑一个或者几个,结合起来,只要参数量少,实验效果好,就可以发 (Shui) 论文。
3. 接着第 2,如果设计出来一个新的卷积方式,如果也存在一些「副作用」,再想一个方法解决这个副作用,再美其名曰 XX-Net。就是自己「挖」个坑,自己再填上去。
个人介绍: 余霆嵩,广东工业大学研三学生,研究方向:深度学习,目标检测,图像分类,模型压缩
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码