【菜菜的sklearn课堂笔记】支持向量机-SVC真实数据案例:预测明天是否会下雨-建模与模型评估以及不同方向的调参
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_auc_score,roc_curve,recall_score
from time import time
import datetime
Ytrain = Ytrain.iloc[:,0].ravel()
Ytest = Ytest.iloc[:,0].ravel()
times = time()
# 首先用核函数来选择核函数
for kernel in ["linear","poly","rbf","sigmoid"]:
clf = SVC(kernel=kernel
,gamma="auto"
,degree=1
# 因为degree为1,如果数据是线性可分的则在poly上效果较好,此时再观察linear上的效果,如果也效果很好,在rbf和sigmoid上效果不好,可以认为该数据集使用线性优于非线性。反之同理
,cache_size=5000
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print(kernel,score,recall,auc)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
---
linear 0.844 0.46938775510204084 0.8690289302534202
00:02:535815
poly 0.8406666666666667 0.4577259475218659 0.868157066506069
00:02:909927
rbf 0.8133333333333334 0.30612244897959184 0.814872584420853
00:03:872351
sigmoid 0.6553333333333333 0.15451895043731778 0.4373077049068794
00:04:297040
# 从结果来看,显然这个数据集是线性可分的,所以后面我们不再考虑rbf和sigmoid
我们注意到,模型的准确度和auc面积还是勉勉强强,但是每个核函数下的recall都不太高。相比之下,其实线性模型的效果是最好的。那现在我们可以开始考虑了,在这种状况下,我们要向着什么方向进行调参呢?
我们可以有不同的目标:
- 我希望不计一切代价判断出少数类,得到最高的recall。
- 我们希望追求最高的预测准确率,一切目的都是为了让accuracy更高,我们不在意recall或者AUC。
- 我们希望达到recall,ROC和accuracy之间的平衡,不追求任何一个也不牺牲任何一个(也就是AUC面积最大)
最求最高Recall
如果我们想要的是最高的recall,可以牺牲我们准确度,希望不计一切代价来捕获少数类,那我们首先可以打开我们的class_weight参数,使用balanced模式来调节我们的recall:
times = time()
for kernel in ["linear","poly","rbf"]:
clf = SVC(kernel=kernel
,gamma="auto"
,degree=1
,cache_size=5000
,class_weight="balanced"
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print(kernel,score,recall,auc)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
---
linear 0.7966666666666666 0.7755102040816326 0.8700620635956569
00:02:817358
poly 0.7933333333333333 0.7638483965014577 0.8714479741767062
00:03:346269
rbf 0.8033333333333333 0.6005830903790087 0.8197131921048454
00:04:428787
在锁定了线性核函数之后,我甚至可以将class_weight调节得更加倾向于少数类,来不计代价提升recall。
times = time()
for kernel in ["linear","poly"]:
clf = SVC(kernel=kernel
,gamma="auto"
,degree=1
,cache_size=5000
,class_weight={0:1,1:10} # 增加class_weight会增加模型运算时间
# 这里可以直接写{1:10},但是要注意的是,这个意思不是两种类别1:10,而是标签为1的权重为10,省略的0:1,标签为0的权重为1
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print(kernel,score,recall,auc)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
---
linear 0.6366666666666667 0.9125364431486881 0.866360422425545
00:05:238580
poly 0.6346666666666667 0.9125364431486881 0.8668845486089237
00:06:047291
随着recall上升,我们的精确度下降得十分厉害,不过看起来AUC面积却还好,稳定保持在0.86左右。如果此时我们的目的就是追求一个比较高的AUC分数和比较好的recall,那我们的模型此时就算是很不错了。虽然现在,我们的精确度很低,但是我们的确精准地捕捉出了每一个雨天。
追求最高准确率
在我们现有的目标(判断明天是否会下雨)下,追求最高准确率而不顾recall其实意义不大, 但出于练习的目的,我们来看看我们能够有怎样的思路。
现在我们不在意Recall了,那首先要观察一下,样本不均衡状况。如果我们的样本非常不均衡,但是此时却有很多多数类被判错的话,那我们可以让模型任性地把所有地样本都判断为0,完全不顾少数类。(因为如果我们现在模型准确率是80%,但是少数类只占有2%,如果我们只追求准确率,全部预测为多数类甚至优于模型)
valuec = pd.Series(Ytest).value_counts()
valuec
---
0 1157
1 343
dtype: int64
valuec/valuec.sum()
---
0 0.771333
1 0.228667
dtype: float64
初步判断,可以认为我们其实已经将大部分的多数类判断正确了,所以才能够得到现在的正确率。为了证明我们的判断,我们可以使用混淆矩阵来计算我们的特异度,如果特异度非常高,则证明多数类上已经很难被操作了。
from sklearn.metrics import confusion_matrix as CM
clf = SVC(kernel="linear"
,gamma="auto"
,cache_size=5000
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
cm = CM(Ytest,result,labels=(1,0))
cm
---
array([[ 161, 182],
[ 52, 1105]], dtype=int64)
specificity = cm[1,1]/cm[1,:].sum()
specificity# 几乎所有的0都被判断正确了,还有不少1也被判断正确了
---
0.9550561797752809
可以看到,特异度非常高,此时此刻如果要求模型将所有的类都判断为0,则已经被判断正确的少数类会被误伤,整体的准确率一定会下降。而如果我们希望通过让模型捕捉更多少数类来提升精确率的话,却无法实现,因为一旦我们让模型更加倾向于少数类,就会有更多的多数类被判错。
可以试试看使用class_weight将模型向少数类的方向稍微调整,已查看我们是否有更多的空间来提升我们的准确率。如果在轻微向少数类方向调整过程中,出现了更高的准确率,则说明模型还没有到极限。
for i in np.linspace(0.01,0.05,10):
times = time()
clf = SVC(kernel="linear"
,gamma="auto"
,cache_size=5000
,class_weight={0:1,1:1+i}
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("i=",i)
print(score,recall,auc)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
---
……
i= 0.01888888888888889
0.8446666666666667 0.478134110787172 0.8691977593605661
00:02:667127
i= 0.02333333333333333
0.8453333333333334 0.48104956268221577 0.8691750808237853
00:02:451183
i= 0.027777777777777776
0.844 0.48104956268221577 0.869394306679333
00:02:484795
……
惊喜出现了,我们的最高准确度是84.53%,超过了我们之前什么都不做的时候得到的84.40%。可见,模型还是有潜力的。我们可以继续细化我们的学习曲线来进行调整:
# 细化
for i in np.linspace(0.01888888888888889,0.027777777777777776,10):
times = time()
clf = SVC(kernel="linear"
,gamma="auto"
,cache_size=5000
,class_weight={0:1,1:1+i}
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print(kernel,score,recall,auc)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
---
# 全都没有出现0.845
模型的效果没有太好,并没有再出现比我们的84.53%精确度更高的取值。可见,模型在不做样本平衡的情况下,准确度其实已经非常接近极限了,让模型向着少数类的方向调节,不能够达到质变。
经过细化反而没有出现一个峰值或者是平台,说明这个增大可能是巧合,但也可能是确实有一定的调整空间
如果我们真的希望再提升准确度,只能选择更换模型的方式,调整参数已经不能够帮助我们了。因为之前已经知道数据是线性可分的,因此我们试一下逻辑回归
from sklearn.linear_model import LogisticRegression as LR
logclf = LR(solver="liblinear").fit(Xtrain,Ytrain)
logclf.score(Xtest,Ytest)
---
0.8486666666666667
for C in np.linspace(1,5,20):
logclf = LR(solver="liblinear",C=C).fit(Xtrain,Ytrain)
print(C,logclf.score(Xtest,Ytest))
---
……
1.2105263157894737 0.8486666666666667
1.4210526315789473 0.85
1.631578947368421 0.8493333333333334
……
for C in np.linspace(1.2105263157894737,1.631578947368421,20):
logclf = LR(solver="liblinear",C=C).fit(Xtrain,Ytrain)
print(C,logclf.score(Xtest,Ytest))
---
……
1.3434903047091413 0.8493333333333334
1.365650969529086 0.8493333333333334
1.3878116343490305 0.85
1.4099722991689752 0.85
……
1.5650969529085872 0.85
1.5872576177285318 0.85
1.6094182825484764 0.8493333333333334
1.631578947368421 0.8493333333333334
尽管我们实现了非常小的提升,但可以看出来,模型的精确度还是没有能够实现质变。也许,要将模型的精确度提升到90%以上,我们需要集成算法:比如,梯度提升树。
追求平衡
我们前面经历了多种尝试,选定了线性核,并发现调节class_weight并不能够使我们模型有较大的改善。现在我们来试试看调节线性核函数的C值能否有效果:
个人理解,选定线性核是为了整个数据集确定的,与目标关系不大;class_weight是针对高召回的,也可略微用于整体正确率;C是用于整体准确率的。所以这里调整只是演示如何调整,而不是因为追求平衡,所以调节C
import matplotlib.pyplot as plt
recallall = []
aucall = []
scoreall = []
C_range = np.linspace(0.01,20,20)
for C in C_range:
times = time()
clf = SVC(kernel="linear"
,C=C
,cache_size=5000
,class_weight="balanced"
).fit(Xtrain,Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest,result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
recallall.append(recall)
aucall.append(auc)
scoreall.append(score)
print(C,score,recall,auc)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
print(max(aucall),C_range[aucall.index(max(aucall))])
---
0.01 0.8 0.7521865889212828 0.8706340666900172
00:00:398692
1.0621052631578947 0.796 0.7755102040816326 0.8700242660343556
00:03:217720
……
20.0 0.7946666666666666 0.7725947521865889 0.8700469445711363
00:39:439777
0.8706340666900172 0.01# 巧了0.01就是最大的
plt.figure()
plt.plot(C_range,recallall,c='red',label='recall')
plt.plot(C_range,aucall,c='k',label='auc')
plt.plot(C_range,scoreall,c='orange',label='accuracy')
plt.legend(loc=4)
plt.show()
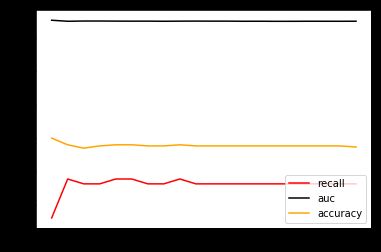
可以观察到几个现象。
首先,我们注意到,随着C值逐渐增大,模型的运行速度变得越来越慢。对于SVM这个本来运行就不快的模型来说,巨大的C值会是一个比较危险的消耗。所以正常来说,我们应该设定一个较小的C值范围来进行调整。
其次,当C到1以上之后,模型的表现开始逐渐稳定,在C逐渐变大之后,模型的效果并没有显著地提高。可以认为我们设定的C值范围太大了,然而再继续增大或者缩小C值的范围, AUC面积也只能够在0.87上下进行变化了,调节C值不能够让模型的任何指标实现质变。
我们把目前为止最佳的C值带入模型,看看我们的准确率,Recall的具体值:
clf = SVC(kernel="linear"
,C=0.01
,cache_size=5000
,class_weight="balanced"
).fit(Xtrain,Ytrain)
FPR,Recall,thresholds = roc_curve(Ytest,clf.decision_function(Xtest),pos_label=1)
area = roc_auc_score(Ytest,clf.decision_function(Xtest))
plt.figure()
plt.plot(FPR,Recall,color='r',label="ROC curve (area = %0.4f)"%area)
plt.plot([0,1],[0,1],color='k',linestyle='--')
plt.xlim([-0.05,1.05])
plt.ylim([-0.05,1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("Recall")
plt.title("Receiver operating characteristic example")
plt.legend(loc=4)
plt.show()
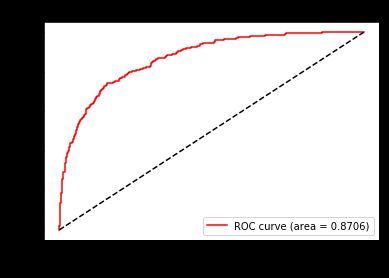
以此模型作为基础,我们来求解最佳阈值:
maxindex = (Recall - FPR).tolist().index(max(Recall - FPR))
thresholds[maxindex] # thresholds是指decision_function的阈值
---
0.13157937002864406
基于我们选出的最佳阈值,我们来认为确定y_predict,并确定在这个阈值下的recall和准确度的值:
from sklearn.metrics import accuracy_score
times = time()
clf = SVC(kernel="linear",C=0.01,cache_size=5000,class_weight="balanced").fit(Xtrain,Ytrain)
prob = pd.DataFrame(clf.decision_function(Xtest))
prob.loc[:,"y_pred"].value_counts()
---
0.0 1064
1.0 436
Name: y_pred, dtype: int64
prob.loc[prob.iloc[:,0] >= 0.13157937002761821,"y_pred"] = 1
prob.loc[prob.iloc[:,0] < 0.13157937002761821,"y_pred"] = 0
# 这里为什么大就是1,小就是0没有找到原因,暂时的方法是value_counts一下,看哪个多,哪个就是0,因为准确率高,且不同类数量差别么明显
times = time()
score = accuracy_score(Ytest,prob.loc[:,"y_pred"].values)
recall = recall_score(Ytest,prob.loc[:,'y_pred'])
print(score,recall)
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
---
0.8206666666666667 0.7434402332361516
00:00:001993
反而还不如我们不调整时的效果好。可见,如果我们追求平衡,那SVC本身的结果就已经非常接近最优结果了。调节阈值,调节参数C和调节class_weight都不一定有效果。但整体来看,我们的模型不是一个糟糕的模型,但这个结果如果提交到kaggle参加比赛是绝对不足够的。如果大家感兴趣,还可以更加深入地探索模型,或者换别的方法来处理特征
关于导出和导入Xtrain,Xtest,Ytrain,Ytest
导出for data,st in zip([Xtrain,Xtest,Ytrain,Ytest],['Xtrain','Xtest','Ytrain','Ytest']): pd.DataFrame(data).to_csv(r'D:\ObsidianWorkSpace\SklearnData\tmp\\'+st+'.csv')导入
Xtrain = pd.read_csv(r'D:\ObsidianWorkSpace\SklearnData\tmp\Xtrain.csv',index_col=0).values Xtest = pd.read_csv(r'D:\ObsidianWorkSpace\SklearnData\tmp\Xtest.csv',index_col=0).values Ytrain = pd.read_csv(r'D:\ObsidianWorkSpace\SklearnData\tmp\Ytrain.csv',index_col=0).values.ravel() Ytest = pd.read_csv(r'D:\ObsidianWorkSpace\SklearnData\tmp\Ytest.csv',index_col=0).values.ravel()
SVM总结&结语
在两周的学习中,我们逐渐探索了SVC在sklearn中的全貌,我们学习了SVM原理,包括决策边界,损失函数,拉格朗日函数,拉格朗日对偶函数,软间隔硬间隔,核函数以及核函数的各种应用。我们了解了SVC类的各种重要参数,属性和接口,其中参数包括软间隔的惩罚系数C,核函数kernel,核函数的相关参数gamma,coef0和degree,解决样本不均衡的参数class_weight,解决多分类问题的参数decision_function_shape,控制概率的参数probability,控制计算内存的参数cache_size,属性主要包括调用支持向量的属性support_vectors_和查看特征重要性的属性coef_。接口中,我们学习了最核心的decision_function。除此之外,我们介绍了分类模型的模型评估指标:混淆矩阵和ROC曲线,还介绍了部分特征工程和数据预处理的思路。
下篇文章解释一下decision_function