elasticsearch的基础使用(二)
一, Elasticsearch有几个核心概念。从一开始理解这些概念会对整个学习过程有莫大的帮助。
(1) 接近实时(NRT)
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒)。
(2) 集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
(3) 节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
(4) 索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database的概念。在一个集群中,如果你想,可以定义任意多的索引。
(5) 类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念。
(6)文档(document)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。文档类似于关系型数据库中Record的概念。实际上一个文档除了用户定义的数据外,还包括_index、_type和_id字段。
(7) 分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
*
允许你水平分割/扩展你的内容容量
*
允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因:
*
在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
*
扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
以上部分内容转自Elasticsearch入门
二,mappings,settings,字段类型
mappings 相当于关系型数据库的表结构,创建每个字段时主要用到4个属性
type:字段类型
index:是否索引,默认为true
format:如果type为日期date,可以设置日期格式,例如 “format”: “yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis”
analyzer:拆词器,可以使用ik_smart或者其他自定义拆词器以及默认拆词器
"mappings": {
"properties": {
"goodsName": {
"type": "text",
"fields": {
"first_letter": {
"type": "text",
"analyzer": "first_letter_pinyin_analyzer"
},
"full_pinyin": {
"type": "text",
"analyzer": "full_pinyin_analyzer"
},
"goodsName": {
"type": "text",
"analyzer": "ik_smart"
},
"goodsNameMax": {
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"promotionEndTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"promotionStartTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
settings 主要用于配置索引的解析器以及分片和复制,例如配置拼音拆词器
"settings": {
"index": {
"number_of_shards": "5",
"analysis": {
"filter": {
"first_letter_pinyin": {
"keep_joined_full_pinyin": "false",
"lowercase": "true",
"keep_original": "false",
"keep_first_letter": "true",
"keep_separate_first_letter": "true",
"type": "pinyin",
"limit_first_letter_length": "16",
"keep_full_pinyin": "false"
},
"full_pinyin": {
"keep_joined_full_pinyin": "true",
"lowercase": "true",
"none_chinese_pinyin_tokenize": "false",
"keep_none_chinese_together": "true",
"type": "pinyin",
"keep_none_chinese": "true",
"keep_full_pinyin": "false"
}
},
"analyzer": {
"full_pinyin_analyzer": {
"filter": [
"full_pinyin",
"unique"
],
"tokenizer": "ik_smart"
},
"first_letter_pinyin_analyzer": {
"filter": [
"first_letter_pinyin"
],
"tokenizer": "ik_smart"
}
}
},
"number_of_replicas": "1"
}
}
拼音分词器配置:
keep_first_letter : 启用此选项时,例如:刘德华> ldh,默认值:true
keep_separate_first_letter : 启用该选项时,将保留第一个字母分开,例如:刘德华> l,d,h,默认:假的,注意:查询结果也许是太模糊,由于长期过频
limit_first_letter_length : 设置first_letter结果的最大长度,默认值:16
keep_full_pinyin : 当启用该选项,例如:刘德华> [ liu,de,hua],默认值:true
keep_joined_full_pinyin : 启用此选项时,例如:刘德华> [ liudehua],默认值:false
keep_none_chinese : 在结果中保留非中文字母或数字,默认值:true
keep_none_chinese_together : 保持非中文字一起,默认值:true,如:DJ音乐家- > DJ,yin,yue,jia,当设置为false,例如:DJ音乐家- > D,J,yin,yue,jia,注意:keep_none_chinese必须先启动
keep_none_chinese_in_first_letter : 第一个字母不能是中文,例如:刘德华AT2016- > ldhat2016,default:true
keep_none_chinese_in_joined_full_pinyin : 保持非中文字母加入完整拼音,例如:刘德华2016- > liudehua2016,默认:false
none_chinese_pinyin_tokenize : 打破非中国信成单独的拼音项,如果他们拼音,默认值:true,如:liudehuaalibaba13zhuanghan- > liu,de,hua,a,li,ba,ba,13,zhuang,han,注意: keep_none_chinese和keep_none_chinese_together应首先启用
keep_original : 当启用此选项时,也将保留原始输入,默认值:false
lowercase : 小写非中文字母,默认值:true
trim_whitespace : 默认值:true
remove_duplicated_term : 当启用此选项时,将删除重复项以保存索引,例如:de的> de,默认值:false注意:位置相关查询可能受影响
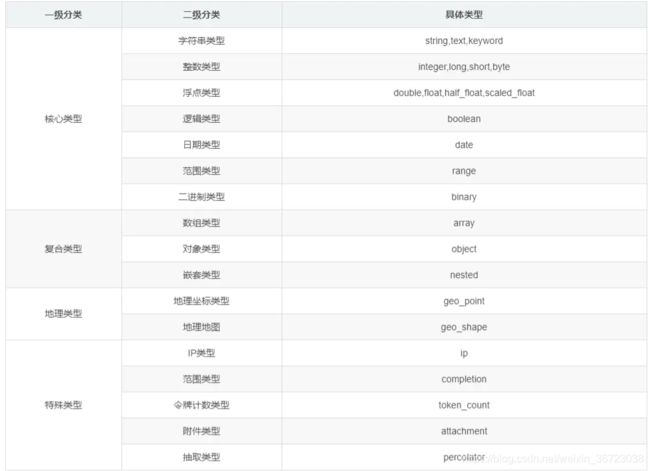
字段类型:
三, 常用查询:match_all,match,match_phrase,multi_match,query_string,range,term
match_all 查询所有
GET /goods_new/_search
{
"query": { "match_all": {}}
}
match 模糊匹配,根据当前字段类型拆词,keyword不会拆词,其他默认拆成单个词
GET /bizpower_goods_new/_search
{
"query": { "match": {"goodsName":"两用扳手"}},
"profile": "true"
}
match_phrase 模糊匹配,当做一个短语,不拆词
GET /goods_new/_search
{
"query": { "match_phrase": {"goodsName":"两用扳手"}}
}
multi_match 模糊匹配
GET /goods_new/_search
{
"query": {
"multi_match": {
"query": "公制两用扳手套装",
"fields": [ "goodsName", "categoryName"]
}
},
"profile": "true"
}
query_string
GET /goods_new/_search
{
"query": {
"query_string": {
"query": "扳手套装"
}
}
}
range 范围查询
GET /goods_new/_search
{
"query": {
"range": {
"webPrice0": {"gte":1679,"lt":2000}
}
}
}
term 字段查询,如果是数组就是包含
GET /goods_new/_search
{
"query": {
"term": {
"categoryIds": "259544"
}
},
"profile": "true"
}
四, bool 联合查询 must: 类似 and,must_not :不等于,should: 类似 or ,must和should不能一起使用,例如a&b & (c or d)不对,正确使用 a&b&c or a&b&d
GET /goods_new/_search
{
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{
"term": {
"categoryIds": {"value": "259544"}
}
},
{
"match": {
"goodsName": "不等于"
}
},
{
"match": {
"brandId": 19262
}
}
]
}
},
{
"bool": {
"must": [
{
"term": {
"categoryIds": {"value": "259544"}
}
},
{
"match": {
"goodsName": "不等于"
}
},
{
"match": {
"brandId": 19068
}
}
]
}
}
]
}
}
}
五, 特殊查询与分析
_analyze 单独分词某个词的拆词结果
GET /goods_new/_analyze
{
“explain”: true,
“analyzer”: “ik_smart”,
“text”: “扳手套装”
}
profile 分析查询语句
GET /goods_new/_search
{
“query”: {
“term”: {
“categoryIds”: “259544”
}
},
“profile”: “true”
}
_termvectors 分析当前文档某个字段当前的拆词结果
GET /goods_new/_doc/197059/_termvectors?fields=goodsName