数据增强综述及albumentations代码使用
数据增强综述及albumentations代码使用
- 基于基本图形处理的数据增强
- 基于深度学习的数据增强
- 其他讨论
- albumentations代码使用
-
- 1.像素级变换
-
- Blur
- CLAHE
- ChannelDropout
- ChannelShuffle
- ColorJitter
- Downscale
- Emboss
- Equalize
- FDA
- FancyPCA
- GaussNoise
- GaussianBlur
- GlassBlur
- HistogramMatching
- HueSaturationValue
- ISONoise
- ImageCompression
- InvertImg
- MedianBlur
- MotionBlur
- MultiplicativeNoise
- PixelDistributionAdaptation
- Posterize
- RGBShift
- RandomBrightnessContrast
- RandomFog
- RandomGamma
- RandomRain
- RandomShadow
- RandomSnow
- RandomSunFlare
- RandomToneCurve
- Sharpen
- Solarize
- Superpixels
- ToGray
- ToSepia
- 2.几何空间变化
-
- Affine
- CenterCrop
- CoarseDropout
- Crop
- CropAndPad
- ElasticTransform
- Flip
- GridDistortion
- GridDropout
- HorizontalFlip
- LongestMaxSize
- NoOp
- OpticalDistortion
- PadIfNeeded
- Perspective
- PiecewiseAffine
- RandomCrop
- RandomGridShuffle
- RandomResizedCrop
- RandomRotate90
- RandomScale
- RandomSizedCrop
- Resize
- Rotate
- SafeRotate
- ShiftScaleRotate
- Transpose
- VerticalFlip
- 3.组合与随机选择
- 4.固定随机种子
- 5.在dataloader中使用
- 6.目标检测框数据增强
- 7.自定义数据增强
- 8.自定义一个目标检测的数据增强方式
- 其他数据增强代码
本文涉及到的资料:
1.A survey on Image Data Augmentation for Deep Learning
2.Albumentations: Fast and Flexible Image Augmentations
3.Code
禁止任何形式的转载!!!
基于基本图形处理的数据增强
1.翻转;2.旋转;3.缩放变换;4.色彩空间(RGB、YUV、CMY、HSV,在图像情感分析中会影响标签。最简单的方法就是只改变一个通道。对比度、直方图均衡、白平衡等);
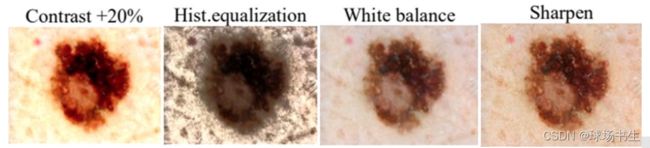
几何和色彩变换很有用,因为它们很容易实现。有许多图像处理库可以使水平翻转和旋转等操作轻松上手。但也存在一些缺点包括额外的内存、变换计算成本和额外的训练时间。必须手动观察一些几何变换,例如平移或随机裁剪,以确保它们没有改变图像的标签。
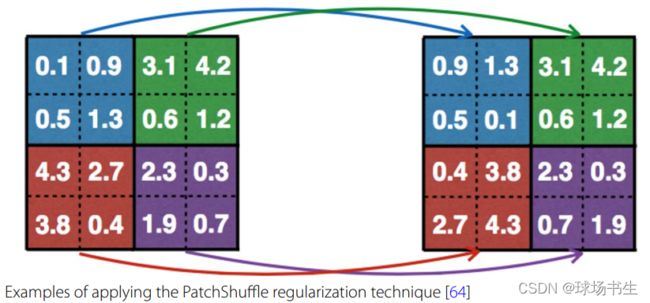
5.裁剪;6.平移;7.噪声注入(椒盐噪声、高斯噪声…);8.滤波器(例如锐化和模糊,PatchShuffle正则:在滑动窗口的时候随机交换像素值,如下图所示。2*2的核0.05的交换率)。缺点是与CNN的机制相似,通过修改网络层就可以实现,而不是通过这种数据增强的方式。
9.Mixing images图像混合
通过平均像素值将图像混合在一起是一种非常违反直觉的数据增强方法。 即将两张图像及其标签平均化为一个新数据(Mixup)。这样做产生的图像对于人类观察者来说看起来不像是有用的转换。


Samplepairing是另一种增强方式,流程如下所示:

也可以使用非线性方法将图像组合成新的训练数据(CutMix):

另外还有YOLOV4里的mosaic增强:每次读取四张图片;分别对四张图片进行翻转、缩放、色域变化等,并且按照四个方向位置摆好;进行图片的组合和框的组合。

或者是裁剪之后拼接在一起:

这种技术的一个明显缺点是,从人类的角度来看,它毫无意义。 从混合图像中发现的性能提升很难理解或解释。 对此的一种可能解释是,增加的数据集大小会导致对线条和边缘等低级特征的表示更加稳健。 此外,如果我们对训练数据进行分区,假如前 100 个时期使用原始图像和混合图像进行训练,而后 50 个时期仅使用原始图像进行训练,那么看看性能如何变化会很有趣。 在关于课程学习curriculum learning的数据增强的设计讨论了这些类型的策略。
10.随机擦除Cutout,受dropout的启发。


基于深度学习的数据增强
1.特征空间增强;在CNN的高级层中发现的低维表征被称为特征空间。SMOTE是一种流行的增强方法,用于缓解类不平衡问题。 该技术通过加入 k 个最近邻以形成新实例而应用于特征空间。

自编码器的工作原理是让网络的编码器将图像映射到低维向量表示中,这样网络的解码器可以将这些向量重建回原始图像,这种编码表征可用于特征空间增强,通过在每个样本的 3 个最近邻之间进行外推以生成新数据。特征空间增强的一个缺点是很难解释向量数据,虽然可以使用自动编码器网络将新向量恢复为图像。 对于深度 CNN,大量的自动编码器训练起来非常困难且耗时。 最后,Wong 等人。 发现当可以在数据空间中变换图像时,数据空间增强将优于特征空间增强。
2.对抗训练;这与之前描述的传统增强技术形成鲜明对比。 对抗性增强可能不代表可能出现在测试集中的例子,但它们可以改善学习决策边界中的弱点 。但尚不清楚这是否有助于减少过度拟合。

3.基于GAN的数据增强;GAN虽然不是唯一的生成模型,然而他在计算速度和结果质量方面处于领先地位。另一个值得一提的生成建模VAE,以扩展 GAN 框架以提高使用VAE生成的样本的质量。变分自动编码器学习数据点的低维表示,与之前说的特征空间增强相同。想象一个由自动编码器创建的大小为 5 × 1 的向量。这些向量可能包括“头部向左转”、“头部居中”和“头部向右转”。自动编码器学习这些数据点的低维表示,从而可以使用向量运算(例如加法和减法)来模拟新的3D旋转。变分自动编码器输出可以通过将它们输入到 GAN 中来进一步改进。

4.风格迁移Neural Style Transfer;这有点类似于色彩空间照明转换。 神经风格转移扩展了光照变化,并支持不同纹理和艺术风格的编码。 选择什么样的风格是一种挑战。例如自动驾驶,需要夜间模式,冬季至夏季或雨水至阳光明媚的规模。
5.元学习数据增强;元学习的一个缺点是它是一个相对较新的概念,还没有经过大量测试。 此外,元学习方案实施起来可能既困难又耗时。
其他讨论
1.许多研究人员一直尝试找到一种策略来选择训练时的图片达到优于随机选择训练数据时的性能。 比如前期先不使用数据增强,在训练后期再使用数据增强。
2.分辨率的影响。使用下采样的图片会带来信息丢失,使用更大的图片,会增加计算量。训练和测试的图片分辨率不一样也可以带来影响。
albumentations代码使用
albumentations是一个基于OpenCV的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分类、分割、检测)的接口,使用非常方便。
pip 方式安装:pip install -U albumentations
简单的使用示例:
import albumentations as A
from cv2 import cv2
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
#A.RandomBrightnessContrast(p=0.2),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("1.jpg")
#image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]
cv2.imshow('transformed',transformed_image)
cv2.waitKey(0)
cv2.imwrite('transformed.png',transformed_image)
1.像素级变换
Blur
A.Blur(blur_limit=5,p=1),#blur_limit [3,inf]

CLAHE
A.CLAHE(clip_limit=5,tile_grid_size=(8, 8),p=1)
ChannelDropout
A.ChannelDropout(channel_drop_range=(1,1),fill_value=0,p=1)

ChannelShuffle
A.ChannelShuffle(p=1)
ColorJitter
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2,p=1)
Downscale
A.Downscale(scale_min=0.25,scale_max=0.25,interpolation=cv2.INTER_NEAREST,p=1) #降低图像质量

Emboss
A.Emboss(alpha=(0.2, 0.5), strength=(0.2, 0.7),p=1) #浮雕 alpha平衡浮雕和原始图像
Equalize
A.Equalize(p=1)#均衡图像直方图
FDA
#风格迁移 傅里叶域适应
A.FDA([target_image], beta_limit=0.5,p=1, read_fn=lambda x: x) beta_limit迁移系数

FancyPCA
A.FancyPCA(alpha=0.3,p=1)

GaussNoise
A.GaussNoise(var_limit=(10.0, 50.0), mean=0, per_channel=True,p=1)
GaussianBlur
A.GaussianBlur(blur_limit=(3, 7), sigma_limit=0, p=1)

GlassBlur
A.GlassBlur (sigma=0.7, max_delta=4, iterations=2, mode='fast', p=1)

HistogramMatching
#它处理输入图像的像素,使其直方图与参考图像的直方图匹配。如果图像有多个通道,则只要输入图像和参考中的通道数相等,就可以为每个通道独立进行匹配。
#直方图匹配可用作图像处理的轻量级归一化,例如特征匹配,特别是在图像从不同来源或不同条件(即照明)拍摄的情况下。
#A.HistogramMatching ([reference_image], blend_ratio=(0.5, 1.0), read_fn=lambda x: x,p=1)
参考图:


HueSaturationValue
A.HueSaturationValue (hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20,p=1)
ISONoise
A.ISONoise (color_shift=(0.01, 0.05), intensity=(0.1, 0.5),p=1)
ImageCompression
A.ImageCompression (quality_lower=40, quality_upper=80, compression_type=0, p=1)#0 ImageCompressionType.JPEG

InvertImg
A.InvertImg(p=1)
MedianBlur
A.MedianBlur (blur_limit=9,p=1) #使用具有随机孔径线性大小的中值滤镜模糊输入图像

MotionBlur
A.MotionBlur(blur_limit=9,p=1)

MultiplicativeNoise
#将图像乘以随机数或数字数组
A.MultiplicativeNoise (multiplier=(0.85, 1.15), per_channel=False, elementwise=True, p=1)#将图像乘以随机数或数字数组
PixelDistributionAdaptation
A.PixelDistributionAdaptation ([target_image], blend_ratio=(0.25, 1.0), read_fn=lambda x: x, transform_type='pca', p=1)
参考图:
Posterize
A.Posterize (num_bits=4, p=1)#减少每个颜色通道的位数

RGBShift
A.RGBShift (r_shift_limit=20, g_shift_limit=20, b_shift_limit=20,p=1) #随机偏移输入RGB图像的每个通道的值。

RandomBrightnessContrast
A.RandomBrightnessContrast (brightness_limit=0.3, contrast_limit=0.3, brightness_by_max=True,p=1)

RandomFog
A.RandomFog (fog_coef_lower=0.3, fog_coef_upper=1, alpha_coef=0.08,p=1)

RandomGamma
A.RandomGamma (gamma_limit=(60, 120), eps=None,p=1)
RandomRain
#下雨的类型 = [None, "drizzle", "heavy", "torrestial"]
#A.RandomRain (slant_lower=-10, slant_upper=10, drop_length=20, drop_width=1, drop_color=(200, 200, 200), blur_value=7, brightness_coefficient=0.7, rain_type=None,p=1)

RandomShadow
A.RandomShadow (shadow_roi=(0, 0.5, 1, 1), num_shadows_lower=1, num_shadows_upper=2, shadow_dimension=5,p=1)

RandomSnow
A.RandomSnow (snow_point_lower=0.1, snow_point_upper=0.3, brightness_coeff=2.5,p=1)
RandomSunFlare
A.RandomSunFlare (flare_roi=(0, 0, 1, 0.5), angle_lower=0, angle_upper=1, num_flare_circles_lower=6, num_flare_circles_upper=10, src_radius=400, src_color=(255, 255, 255),p=1)

RandomToneCurve
A.RandomToneCurve (scale=0.2,p=1)#通过操纵图像的色调曲线,随机更改图像的亮区和暗区之间的关系

Sharpen
A.Sharpen (alpha=(0.2, 0.5), lightness=(0.5, 1.0),p=1)
Solarize
A.Solarize (threshold=128,p=1)#反转所有高于阈值的像素值

Superpixels
#将图像部分/完全转换为其超像素表示形式。此实现使用 skimage 的 SLIC 算法版本。
A.Superpixels (p_replace=0.1, n_segments=100, max_size=128, interpolation=1,p=1)

ToGray
A.ToGray(p=1)

ToSepia
A.ToSepia (p=1)#将棕褐色滤镜应用于输入 RGB 图像
2.几何空间变化
Affine
A.Affine (scale=None, translate_percent=None, translate_px=None, rotate=None, shear=None, interpolation=1, mask_interpolation=0, cval=0, cval_mask=0, mode=0, fit_output=False,p=1)

CenterCrop
A.CenterCrop (height=256, width=256, p=1)

CoarseDropout
A.CoarseDropout (max_holes=10, max_height=15, max_width=15, min_holes=None, min_height=None, min_width=None, fill_value=0, mask_fill_value=None,p=1)

Crop
A.Crop(x_min=20, y_min=10, x_max=356, y_max=360,p=1)

CropAndPad
#按像素量或图像大小的分数裁剪和填充图像。裁剪会删除侧面的像素(即从给定的完整图像中提取子图像)。填充会向侧面添加像素(例如黑色像素)。
A.CropAndPad (px=30, percent=None, pad_mode=0, pad_cval=0, pad_cval_mask=0, keep_size=True, sample_independently=True, interpolation=1,p=1)

ElasticTransform
#弹性变形
A.ElasticTransform (alpha=1, sigma=50, alpha_affine=50, interpolation=1, border_mode=4, value=None, mask_value=None,p=1)

Flip
A.Flip(p=1)#水平 垂直 或者都有可能
GridDistortion
A.GridDistortion (num_steps=5, distort_limit=0.3, interpolation=1, border_mode=4, value=None, mask_value=None,p=1)

GridDropout
A.GridDropout (ratio=0.5, unit_size_min=None, unit_size_max=None, holes_number_x=None, holes_number_y=None, shift_x=0, shift_y=0, random_offset=False, fill_value=0, mask_fill_value=None,p=1)

HorizontalFlip
A.HorizontalFlip(p=1)

LongestMaxSize
A.LongestMaxSize(max_size=500, interpolation=1,p=1)#以最长边来缩放

NoOp
A.NoOp() #啥也不做
OpticalDistortion
A.OpticalDistortion (distort_limit=0.6, shift_limit=0.6, interpolation=1, border_mode=4, value=None, mask_value=None,p=1)

PadIfNeeded
A.PadIfNeeded (min_height=600, min_width=800, pad_height_divisor=None, pad_width_divisor=None, position='center', border_mode=4, value=None, mask_value=None,p=1)
Perspective
#对输入执行随机四点透视转换
A.Perspective (scale=(0.05, 0.1), keep_size=True, pad_mode=0, pad_val=0, mask_pad_val=0, fit_output=False, interpolation=1,p=1)

PiecewiseAffine
A.PiecewiseAffine (scale=(0.03, 0.05), nb_rows=4, nb_cols=4, interpolation=1, mask_interpolation=0, cval=0, cval_mask=0, mode='constant', absolute_scale=False, keypoints_threshold=0.01,p=1)

RandomCrop
A.RandomCrop (height=300, width=300,p=1)

RandomGridShuffle
A.RandomGridShuffle (grid=(3, 3),p=1)
RandomResizedCrop
#cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4. Default: cv2.INTER_LINEAR.
A.RandomResizedCrop (height=400, width=400, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=1, p=1)

RandomRotate90
A.RandomRotate90(p=1)
RandomScale
A.RandomScale (scale_limit=0.1, interpolation=1,p=1) #图片大小会改变

RandomSizedCrop
A.RandomSizedCrop (min_max_height=[100,300], height=400, width=400, w2h_ratio=1.0, interpolation=1,p=1)

Resize
A.Resize (height=200, width=200, interpolation=1,p=1)

Rotate
A.Rotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=1)
#cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101. Default: cv2.BORDER_REFLECT_101

SafeRotate

A.SafeRotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=1)
ShiftScaleRotate
#随机应用仿射变换:平移、缩放和旋转输入
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.1, rotate_limit=45, interpolation=1, border_mode=4, value=None, mask_value=None, shift_limit_x=None, shift_limit_y=None,p=1)

Transpose
A.Transpose(p=1)
VerticalFlip
A.VerticalFlip(p=1)
3.组合与随机选择
OneOf()里的概率是会归一化的,你可以理解为权重。当OneOf()被选择之后,会从里面选择一个进行数据增强,所以当里面只有一个选项的时候(只要不是0)任何概率都会被选中。
transform=A.Compose([
A.MotionBlur(blur_limit=9,p=0.5),
A.OneOf([
# 高斯噪点
A.GaussianBlur(blur_limit=(3, 7), sigma_limit=0,p=0.5),
A.GaussNoise(var_limit=(10.0, 50.0), mean=0, per_channel=True,p=0.3)
], p=0.7),
A.OneOf([
A.Rotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=0.5)
],p=0.5)
])
print(transform[0].transforms_ps)
print(transform[1].transforms_ps)
[0.625, 0.37499999999999994] #第一个OneOf里面的概率
[1.0]#第二个OneOf里面的概率
4.固定随机种子
当设置一个全局的随机种子之后,每次增强产生的照片都会是一样的
import random
random.seed(1)
transform=A.Compose([
A.Rotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=1)
])
5.在dataloader中使用
需要注意一点就是,这里转换的图片是0-255的numpy格式,所以最后一般需要归一化和转成tensor
from albumentations.pytorch import ToTensorV2
import albumentations as A
def get_valid_transforms():
return A.Compose([
A.CenterCrop(CFG['img_size'], CFG['img_size'], p=1.),
A.Resize(CFG['img_size'], CFG['img_size']),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], max_pixel_value=255.0, p=1.0),
A.ToTensorV2(p=1.0),
], p=1.)
train_dataset = DatasetRetriever(
image_ids=df_folds[df_folds['fold'] != fold_number].index.values,
marking=marking,
transforms=get_valid_transforms(),##直接传入
test=False,
)
6.目标检测框数据增强
在对目标检测的数据进行增强时,还需要对标签中的bbox进行调整。目前有两种常见的边框表达方式:

因此,它现在有一个附加参数,设置边界框坐标的格式。此值是必需的,因为 Albumentation 需要知道边界框的坐标源格式才能正确应用增强。
transform = A.Compose([
A.RandomCrop(width=450, height=450),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
], bbox_params=A.BboxParams(format='coco', min_area=1024, min_visibility=0.1, label_fields=['class_labels']))
参数说明:
- format:有四种可以选择的:pascal_voc, albumentations, coco, yolo
- Min_area:是一个像素值。如果扩展后的边界框的面积小于min_area, Albumentations将删除该框。所以返回的边界框列表不会包含那个边界框。
- Min_visibility:是一个介于0和1之间的值。如果扩展后的边界框面积与扩展前的边界框面积的比值小于min_visibility, Albumentations将删除该框。因此,如果扩展过程削减了边界框的大部分,那么该框将不会出现在扩展边界框的返回列表中。
除了坐标之外,每个边界框还应具有关联的类标签,用于指示哪个对象位于边界框内。有两种方法可以传递边界框的标签:
- 通过将标签作为附加值添加到坐标列表中,可以将标签与边界框坐标一起传递。[23, 74, 295, 388, ‘dog’]、[377, 294, 252, 161, ‘cat’]。类标签可以是任何类型:整数、字符串或任何其他 Python 数据类型。例如,作为类标签的整数值将如下所示:[23, 74, 295, 388, 18]、[377, 294, 252, 161, 17]。也可以使用多个值[23, 74, 295, 388, ‘dog’, ‘animal’]
- 可以将边界框的标签作为单独的列表传递(首选方式)。[23, 74, 295, 388], [377, 294, 252, 161], and [333, 421, 49, 49] 标签为[‘cat’, ‘dog’, ‘sports ball’], or [18, 17, 37]。如果一个边界框在扩展后被删除,Albumentations也将删除该框的类标签。
下面展示首选的方式,这里我采用的是VOC的数据格式。
#读入图片、边框和类别信息
image = cv2.imread("001556.jpg")
bboxes =[[66,32,155,245],[308,31,435,294]]
class_labels =['horse1','horse2']
#定义变换
transform=A.Compose([
A.MotionBlur(blur_limit=9,p=0.5),
A.OneOf([
# 高斯噪点
A.GaussianBlur(blur_limit=(3, 7), sigma_limit=0,p=0.5),
A.GaussNoise(var_limit=(10.0, 50.0), mean=0, per_channel=True,p=0.3)
], p=0.7),
A.OneOf([
A.Rotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=0.5)
],p=0.5)
],bbox_params=A.BboxParams(format='pascal_voc', min_area=20, min_visibility=0.1, label_fields=['class_labels']))
#获得变换后的图像并画出前后的边框
# Augment an image
transformed = transform(image=image,bboxes=bboxes,class_labels=class_labels)
transformed_image = transformed["image"]
transformed_bboxes = transformed['bboxes']
transformed_class_labels = transformed['class_labels']
print(transformed_image.shape)
#画框
for i in range(len(transformed_bboxes)):
x1,y1,x2,y2=transformed_bboxes[i]
cv2.rectangle(transformed_image,(int(x1),int(y1)),(int(x2),int(y2)),color=[255,0,0],thickness=2)
for i in range(len(bboxes)):
x1,y1,x2,y2=bboxes[i]
cv2.rectangle(image,(int(x1),int(y1)),(int(x2),int(y2)),color=[0,0,255],thickness=2)

此外值得注意的是,有些几何变换的数据增强在目标检测中不适用,请在这里查看

7.自定义数据增强
首先定义一个自定义的转换函数,再将其送给A.Lambda:
#自定义数据增强
# 定义一个用于图片转换的函数
def hflip_image(image, **kwargs):
return cv2.flip(image, 1)
#组合
transform=A.Compose([
A.Lambda(name='自己定义的数据增强', image=hflip_image, p=1),
A.MotionBlur(blur_limit=9,p=0.5),
A.OneOf([
A.GaussianBlur(blur_limit=(3, 7), sigma_limit=0,p=0.5),# 高斯噪点
A.GaussNoise(var_limit=(10.0, 50.0), mean=0, per_channel=True,p=0.3)
], p=0.7),
A.OneOf([
A.Rotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=0.5)
],p=0.1)
])

8.自定义一个目标检测的数据增强方式
#自定义数据增强
# 定义一个用于图片转换的函数
def hflip_image(image, **kwargs):
return cv2.flip(image, 1)
def hflip_bbox(bbox, **kwargs):
new_bbox=(1-bbox[2],bbox[1],1-bbox[0],bbox[3])#交换横坐标 注意这里是归一化之后的坐标
return new_bbox
#组合
transform=A.Compose([
A.Lambda(name='自己定义的数据增强',image=hflip_image,bbox=hflip_bbox, p=1),
A.RandomCrop(width=450, height=330,p=1),
A.MotionBlur(blur_limit=9,p=0.5),
A.OneOf([
# 高斯噪点
A.GaussianBlur(blur_limit=(3, 7), sigma_limit=0,p=0.5),
A.GaussNoise(var_limit=(10.0, 50.0), mean=0, per_channel=True,p=0.3)
], p=0.7),
A.OneOf([
A.Rotate (limit=90, interpolation=1, border_mode=4, value=None, mask_value=None,p=0.5)
],p=0.2)
],bbox_params=A.BboxParams(format='pascal_voc', min_area=20, min_visibility=0.1, label_fields=['class_labels']))

这里apply_to_bbox会调用你传入的自定义函数,会将目标框一个一个的送入进行处理。

其他数据增强代码
许多非常受欢迎的项目已被整合
https://github.com/CrazyVertigo/awesome-data-augmentation