ECCV2022细粒度图像检索SEMICON学习记录
论文题目:SEMICON: A Learning-to-hash Solution for Large-scale Fine-grained Image Retrieval
论文链接:http://www.weixiushen.com/publication/eccv22_SEMICON.pdf
代码链接:https://github.com/aassxun/SEMICON
动机
大多数现有的深度哈希方法仅支持通用目标检索,如汽车、飞机,这无法满足我们的实际需求。因此,最近关于深度哈希的工作已经开始关注细粒度图像检索,这需要准确检索图像的类别,例如不同种类的动植物等,而不仅是通用类别。
创新点
作者提出了 Suppression-Enhancing Mask based attention and Interactive Channel transformatiON (SEMICON)。SEMICON 有两个分支:一个是全局特征学习分支,具有单个全局哈希单元,用于表示目标 (全局) 级别的含义;另一个是局部模式学习分支,具有多个局部哈希单元,用于表示多个局部级别的含义。此外,SEMICON 还有两个关键模块,Suppression-Enhancing Mask based attention (SEM) 和 Interactive Channel transformatiON (ICON)。SEM 应用于局部模式学习分支的每个学习阶段,动态地定位关键图像区域。对于 ICON,则在每个特征张量上使用该模块,将特征的通道作为 token embeddings (token 常用于 NLP中,每个单词为一个 token,在 CV 中,通常将图像中的一个 patch 作为一个 token),实现不同通道之间的交互。这篇文章的创新点可以总结为以下两点:
(1) 提出了 SEMICON,用于处理细粒度的哈希学习任务;
(2) 设计了 SEM 和 ICON 来分别维持不同激活区域之间的关系以及建立不同通道之间的相关性。
方法论
整体框架
通常,全局和局部特征在细粒度的视觉任务中都至关重要。因此,SEMICON 的整体框架维持了一个全局特征学习分支和一个局部模式学习分支,如下图所示。相应地,哈希码的学习也由两个单元组成,即全局级哈希映射单元和局部级哈希映射单元。具体来说,全局级哈希映射单元被用于捕获目标级二进制哈希码,而局部级哈希映射单元被划分为 m 个子线性编码器,有利于显式地获得部分级二进制哈希码。因此,SEMICON 最终学习的哈希码包含目标级和部分级含义。此外,作者提出的基于抑制增强掩模的注意力 (SEM) 模块和交互式通道转换 (ICON) 模块被用于生成有区别度的全局级特征和相关的局部级特征。
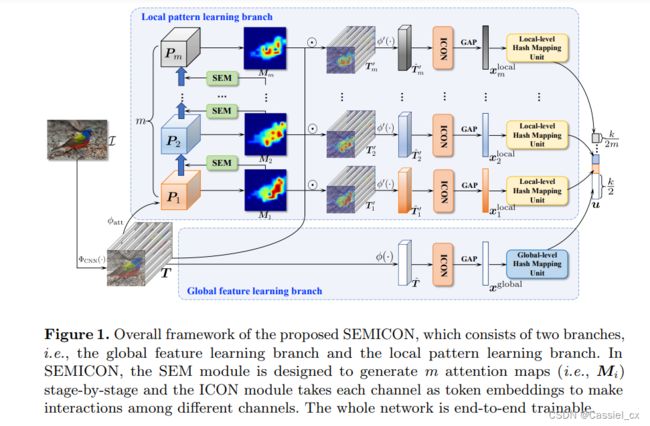
对于每张输入图片 I,经过主干网络提取深度激活张量,公式如下:

随后,T 会经过一个全局转换网络  ,该网络由卷积层堆叠而成,被用于提取全局特征,公式如下:
,该网络由卷积层堆叠而成,被用于提取全局特征,公式如下:

其中,![]() 为全局转换网络中的参数。
为全局转换网络中的参数。
此外,T 也会经过局部模式学习分支,该分支由注意力引导 ![]() 组成,该引导被用于在第一阶段中生成注意力掩码
组成,该引导被用于在第一阶段中生成注意力掩码 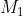 ,生成的掩码与 T 逐元素相乘,公式如下:
,生成的掩码与 T 逐元素相乘,公式如下:

随后,SEM 模块被用于在接下来的 m-1 个阶段中生成注意力掩码  。此外,为了获得一个特定于语义信息的表示,
。此外,为了获得一个特定于语义信息的表示,![]() 还会经过一个局部转换网络
还会经过一个局部转换网络 ![]() (该网络与全局转换网络具有相同的结构),公式如下:
(该网络与全局转换网络具有相同的结构),公式如下:
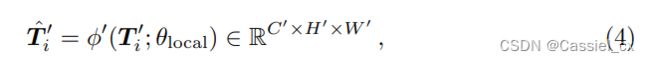
随后,ICON 分别作用在 ![]() 和
和 ![]() ,在各张量中产生跨通道的交互。
,在各张量中产生跨通道的交互。
最后, ![]() 和
和 ![]() 还会经过全局平均池化层 (GAP),产生全局特征
还会经过全局平均池化层 (GAP),产生全局特征 ![]() 和 m 个局部特征
和 m 个局部特征 ![]() 。为了生成二进制码,二进制码映射模块由 m + 1 个线性编码器组成,
。为了生成二进制码,二进制码映射模块由 m + 1 个线性编码器组成,
![]()
这些编码器将 ![]() 映射为
映射为 ![]() 。 最终,哈希码学习模块将作用在
。 最终,哈希码学习模块将作用在 ![]() ,以生成最终二进制哈希码,
,以生成最终二进制哈希码,
![]()
SEM
SEM 模块可以维持不同激活区域之间的关系。具体来说,对于张量 T,通过以下公式可获得注意力引导 P,
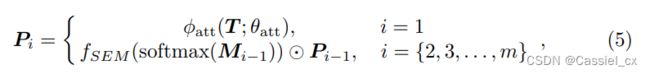
获得  后,再经过一个 1*1 卷积就可得到 。至于剩下的 m-1 个注意力图,则由 SEM 生成,这不仅有助于抑制(而不是简单地擦除)先前最具辨别力的区域,还有助于增强其他激活的区域。作者首先通过 softmax 函数来计算前一阶段的注意力图
后,再经过一个 1*1 卷积就可得到 。至于剩下的 m-1 个注意力图,则由 SEM 生成,这不仅有助于抑制(而不是简单地擦除)先前最具辨别力的区域,还有助于增强其他激活的区域。作者首先通过 softmax 函数来计算前一阶段的注意力图 ![]() 中每个单元的权重:
中每个单元的权重:
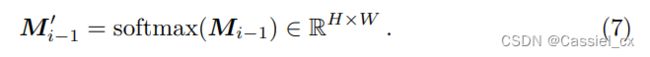
随后,对该注意力图中的所有权重 (共 H×W 个),求出均值和标准差。随后对每个单元的权重进行如下操作 (![]() ),
),
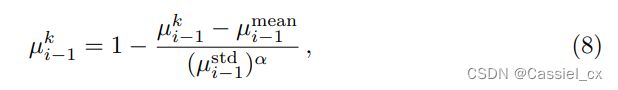
![]()
其中,α 用于正则化判别区域的抑制率和其他激活区域的增强率。
此外,前一阶段的注意力引导 ![]() 通过执行 element-wise Hadamard product 变为
通过执行 element-wise Hadamard product 变为  (不太理解,需看代码辅助理解)。 第 i 个注意力图 随后由第 i 个 1×1 卷积层
(不太理解,需看代码辅助理解)。 第 i 个注意力图 随后由第 i 个 1×1 卷积层 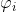 生成,
生成,
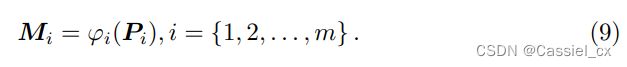
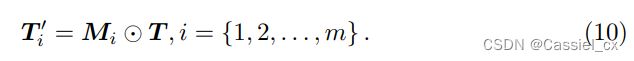
通过执行这种基于抑制-增强掩码的注意力操作,前一阶段的注意力引导中最具辨别力的区域将被部分抑制 (不是简单的 erasing)。同时,那些未激活的区域将被进一步抑制,而其他激活的区域将受到关注。因此,可以保持前一阶段的激活区域与之后生成的激活区域之间的关系。

ICON
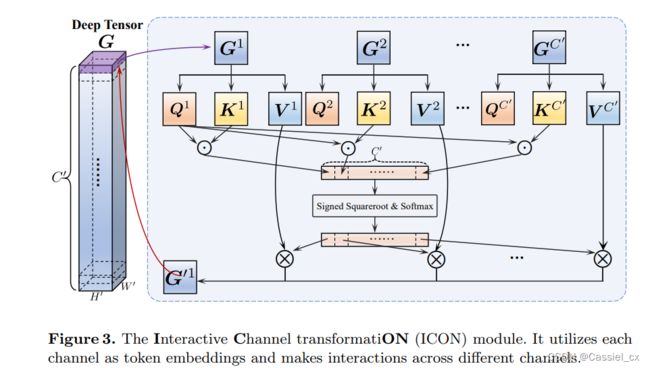
ICON 的框架图如上图所示。在所有通道上直接执行交互式通道变换的计算复杂度是相当大的。 因此,对于给定的张量 ![]() ,作者将其分成几个部分,并设计了一个两阶段的交互式通道转换模块 (如下图所示),可以直接在传统的深度哈希框架中使用,以减少计算开销。
,作者将其分成几个部分,并设计了一个两阶段的交互式通道转换模块 (如下图所示),可以直接在传统的深度哈希框架中使用,以减少计算开销。
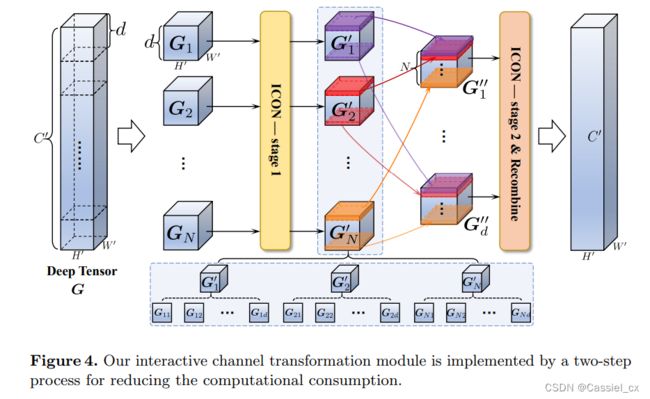
具体来说,第一阶段是由堆叠的 N 个 identical parts 组成。给定 G,将深度张量划分为 N 个长度 (图中为 d) 相等的子张量 ![]() ,
,![]() 。对每个
。对每个  进行交互通道转换操作,生成
进行交互通道转换操作,生成 ![]() ,以便在子张量内部通过不同通道进行交互。第一阶段中的交互式通道转换操作可以描述为将唯一的 query
,以便在子张量内部通过不同通道进行交互。第一阶段中的交互式通道转换操作可以描述为将唯一的 query ![]() 以及 key-value 对
以及 key-value 对  、
、 映射到输出
映射到输出 ![]() ,
,![]() 、 以及 由 经过 1*1 卷积层产生。上述操作可用以下公式描述,
、 以及 由 经过 1*1 卷积层产生。上述操作可用以下公式描述,

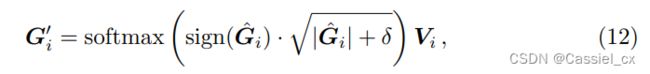
其中,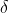 为一个固定的正数偏置项。
为一个固定的正数偏置项。
为了让不同的子张量进行交互,将 ![]() 中每个特征图视为一个 token (每个
中每个特征图视为一个 token (每个 ![]() 均有 d 个特征图),并将各
均有 d 个特征图),并将各 ![]() 中相同位置的特征图重组为
中相同位置的特征图重组为 ![]() (可参考上图)。具体来说,每个
(可参考上图)。具体来说,每个 ![]() 由 N 个通道组成,
由 N 个通道组成,
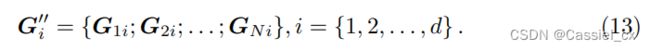
随后,ICON 的第二阶段会作用在 ![]() 上,处理过程与 ICON 的第一阶段相同。在这两个阶段之间,作者采用了 BN 和 ReLU,并在每一阶段之后都采用了残差连接。
上,处理过程与 ICON 的第一阶段相同。在这两个阶段之间,作者采用了 BN 和 ReLU,并在每一阶段之后都采用了残差连接。
哈希码学习
作者基于全局和局部特征,进行了哈希码学习。假设有 q 个数据查询点 ![]() 以及 p 个数据库点
以及 p 个数据库点 ![]() ,对于每个
,对于每个  和
和  ,它们均由一个全局特征及 m 个局部特征组成,
,它们均由一个全局特征及 m 个局部特征组成,
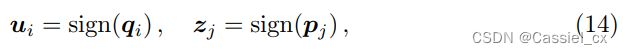
![]()
其中,k 为最终二进制哈希码的长度。哈希学习的目标是学习查询点和数据库点的二进制哈希码,并同时保持它们的相似性。哈希码的学习过程可表示为:

其中,Γ 表示所有数据库点的索引,Ω ⊆ Γ 表示查询集点的索引,![]() 表示成对监督信息,β 和 γ 为权衡两部分的超参数。
表示成对监督信息,β 和 γ 为权衡两部分的超参数。
实验
作者在 CUB200-2011、Aircraft、Food101、NABirds以及 VegFru 共五个数据集上进行实验,实验结果如下,

与 SOTA 方法 ![]() 相比,SEMICON 在 Aircraft 和 VegFru 数据集上分别提升了 11.42% 和 17.17% 的 mAP。此外,SEMICON 在中等规模细粒度数据集 (例如 CUB200-2011 和 Aircraft) 以及大规模细粒度数据集 (例如 NABirds 和 VegFru) 上都获得了优异的结果。这些结果验证了 SEMICON 的有效性,以及它在细粒度检索中的实用性。
相比,SEMICON 在 Aircraft 和 VegFru 数据集上分别提升了 11.42% 和 17.17% 的 mAP。此外,SEMICON 在中等规模细粒度数据集 (例如 CUB200-2011 和 Aircraft) 以及大规模细粒度数据集 (例如 NABirds 和 VegFru) 上都获得了优异的结果。这些结果验证了 SEMICON 的有效性,以及它在细粒度检索中的实用性。
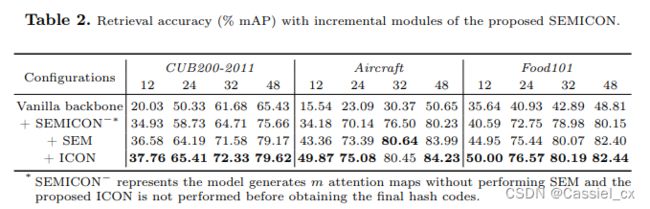
消融实验的结果如下,
结论
这篇文章提出了 SEMICON 来处理大规模细粒度图像检索任务。SEMICON 中包含了 SEM 和 ICON,分别用于保持不同激活区域之间的关系以及捕获细粒度部分的相关性。此外,通过包含全局级和局部级两个单元的哈希映射模块,可分别从具有不同级别的特征中生成最终学习的二进制哈希码。