当Transformer遇见U-Net!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Amusi | 来源:CVer
前言
留给Transformer + U-Net 组合命名的缩写不多了...
之前盘点了目前已公开的5篇MICCAI 2021上的Transformer+医学图像分割的工作,详见:Transformer一脚踹进医学图像分割!看5篇MICCAI 2021有感
没想到大家这么喜欢这篇文章,收藏量高的可怕...
那么本文将盘点Tranformer + U-Net组合的论文工作,其中Transformer作为大热的发论文神器,U-Net作为医学图像分割的霸主,两者碰撞已然成为目前医学图像分割领域研究的大热点。
一、TransUNet:用于医学图像分割的Transformers强大编码器
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation

作者单位:JHU, 电子科大, 斯坦福大学等
代码:https://github.com/Beckschen/TransUNet
论文:https://arxiv.org/abs/2102.04306
一句话总结:同时具有Transformers和U-Net的优点,表现SOTA!性能优于AttnUNet、V-Net等网络,代码刚刚开源!
医学图像分割是开发医疗保健系统(尤其是疾病诊断和治疗计划)的必要先决条件。在各种医学图像分割任务中,U形架构(也称为U-Net)已成为事实上的标准,并取得了巨大的成功。但是,由于卷积运算的固有局部性,U-Net通常在明确建模远程依赖关系方面显示出局限性。设计用于序列到序列预测的transformer已经成为具有先天性全局自注意力机制的替代体系结构,但由于low-level细节不足,可能导致定位能力受到限制。
在本文中,我们提出了TransUNet,它同时具有Transformers和U-Net的优点,是医学图像分割的强大替代方案。

一方面,Transformer将来自卷积神经网络(CNN)特征图的标记化图像块编码为提取全局上下文的输入序列。另一方面,解码器对编码的特征进行上采样,然后将其与高分辨率的CNN特征图组合以实现精确的定位。
我们认为,借助U-Net的组合,通过恢复localized 空间信息,可以将Transformers用作医学图像分割任务的强大编码器。TransUNet在各种医疗应用(包括多器官分割和心脏分割)上均比各种竞争方法具有更高的性能。


二、MedT:用于医学图像分割的Transformer
Medical Transformer: Gated Axial-Attention for Medical Image Segmentation

代码(已开源):
https://github.com/jeya-maria-jose/Medical-Transformer
论文:https://arxiv.org/abs/2102.10662
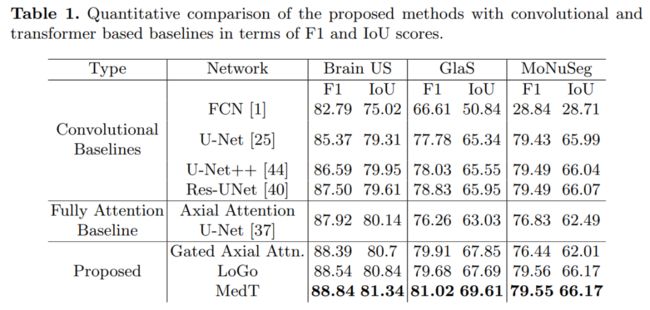
一句话总结:表现SOTA!并提出局部-全局训练策略(LoGo),进一步提高性能,优于Res-UNet、U-Net++等网络,代码刚刚开源!作者单位:JHU, 新泽西州立大学
在过去的十年中,深度卷积神经网络已被广泛用于医学图像分割,并显示出足够的性能。但是,由于卷积架构中存在固有的inductive biases,因此他们对图像中的远程依存关系缺乏了解。最近提出的利用自注意力机制的基于Transformer的体系结构对远程依赖项进行编码,并学习高度表达的表示形式。

这促使我们探索基于Transformer的解决方案,并研究将基于Transformer的网络体系结构用于医学图像分割任务的可行性。提出用于视觉应用的大多数现有的基于Transformer的网络体系结构都需要大规模的数据集才能正确地进行训练。但是,与用于视觉应用的数据集相比,对于医学成像而言,数据样本的数量相对较少,从而难以有效地训练用于医学应用的Transformer。
为此,我们提出了Gated Axial-Attention模型,通过在自注意力模块中引入附加的控制机制来扩展现有体系结构。
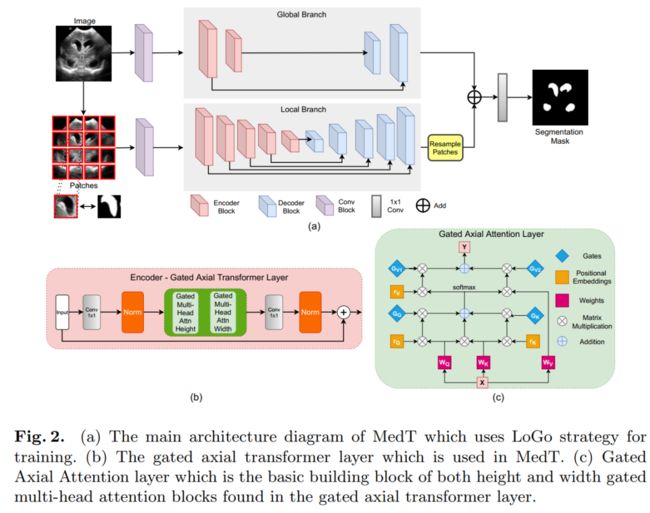
此外,为了有效地在医学图像上训练模型,我们提出了局部-全局训练策略(LoGo),可以进一步提高性能。
具体来说,我们对整个图像和patch进行操作以分别学习全局和局部特征。在三个不同的医学图像分割数据集上对提出的Medical Transformer(MedT)进行了评估,结果表明,与基于卷积和其他基于transformer的其他架构相比,它具有更好的性能。

三、SpecTr:用于高光谱病理图像分割的光谱Transformer
SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation

作者单位:华东师范, JHU, 上海交大
代码:https://github.com/hfut-xc-yun/SpecTr
论文:https://arxiv.org/abs/2103.03604
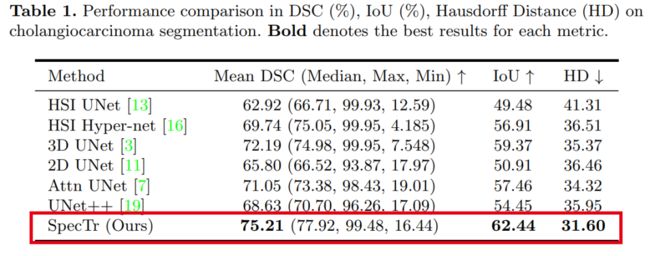
一句话总结:表现SOTA!性能优于UNet++、Attn UNet等网络,代码即将开源!
高光谱成像(HSI)为依赖于高精度病理图像分割的各种应用(例如计算病理学和精密医学)释放了巨大的潜力。由于高光谱病理图像甚至可以从可见光谱中受益于丰富而详细的光谱信息,因此实现高精度高光谱病理图像分割的关键是沿高光谱光谱带对背景进行建模。
受Transformer强大的上下文建模能力的启发,我们在此首次将跨光谱带的上下文特征学习公式化为高光谱病理图像分割,作为transformer的逐序列预测程序。

为了辅助频谱上下文学习过程,我们引入了两个重要的策略:
(1)稀疏方案使学习的上下文关系变得稀疏,从而消除了对冗余频带的干扰;
(2)频谱归一化,即每个频谱带的单独组归一化,减轻了由频带的不均匀底层分布引起的麻烦。
我们将我们的方法命名为Spectral Transformer(SpecTr),它具有两个好处:
(1)具有对光谱带之间的长期依赖性建模的强大能力,
(2)它共同探索了HSI的空间光谱特征。
实验表明,在高光谱病理图像分割基准测试中,SpecTr优于其他竞争方法,而无需进行预训练。

四、TransBTS:基于Transformer的多模态脑肿瘤分割
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer

作者单位:北京科技大学, 北卡等
代码:https://github.com/Wenxuan-1119/TransBTS
论文:https://arxiv.org/abs/2103.04430
一句话总结:我们提出了在3D CNN中利用Transformer进行3D MRI脑肿瘤分割的首次尝试:TransBTS,与TransUNet不同的是,本网络基于3D CNN,可一次处理image slices,表现SOTA!优于Attention U-Net、V-Net等,代码刚刚开源!
可以受益于使用自注意力机制进行全局(远程)信息建模的Transformer最近在自然语言处理和2D图像分类中获得了成功。但是,局部和全局特征对于密集的预测任务至关重要,尤其是对于3D医学图像分割而言。
在本文中,我们首次利用3D CNN中的Transformer进行MRI脑肿瘤分割,并提出了一种基于编码器-解码器结构的新型网络TransBTS。
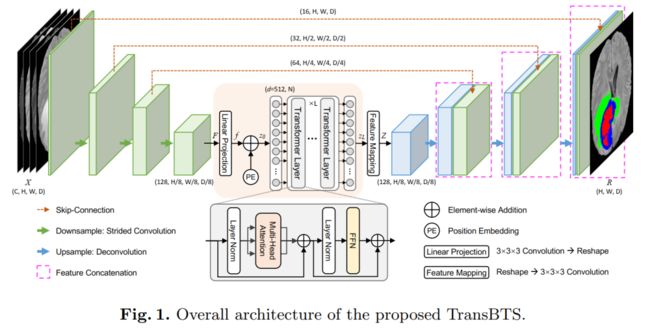
为了捕获本地3D上下文信息,编码器首先使用3D CNN提取体积空间特征图。同时,对用于映射tokens的特征图进行了精心的改进,这些tokens被馈送到Transformer中进行全局特征建模。解码器利用Transformer嵌入的功能并执行渐进式上采样以预测详细的分割图。
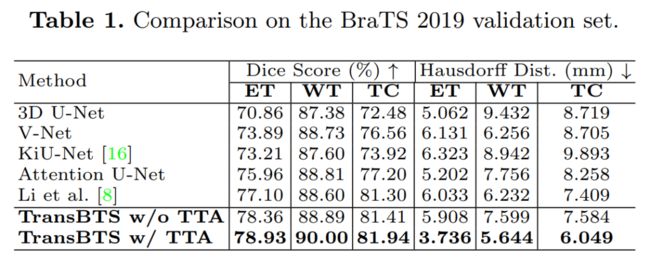
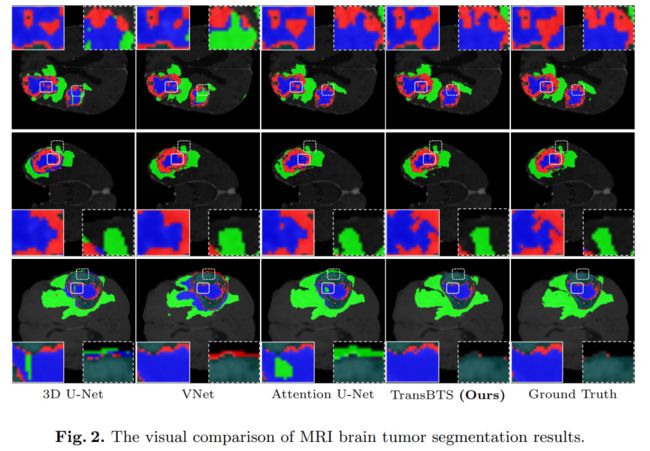
BraTS 2019数据集上的实验结果表明,TransBTS优于3D MRI扫描中脑肿瘤分割的最新方法。
五、U-Net Transformer:用于医学图像分割的自注意力和交叉注意力
U-Net Transformer: Self and Cross Attention for Medical Image Segmentation

作者单位:法国国立工艺学院等
论文:https://arxiv.org/abs/2103.06104
一句话总结:U-Transformer 可还行!使用自注意力和交叉注意力模块来建模远程交互和空间依赖性,性能优于Attn U-Net等网络。
对于复杂和低对比度的解剖结构,医学图像分割仍然特别具有挑战性。在本文中,我们介绍了U-Transformer网络,该网络将U形结构与来自Transformers的自注意力和交叉注意力相结合,用于图像分割。

U-Transformer克服了U-Net无法建模远程上下文交互和空间依赖性的问题,这对于在具有挑战性的上下文中进行精确分割至关重要。为此,注意力机制在两个主要级别上合并:自注意模块利用编码器特征之间的全局交互,而跳跃连接中的交叉注意力通过滤除非语义来实现U-Net解码器中的精细空间恢复特征。


在两个腹部CT图像数据集上进行的实验表明,与U-Net和local Attention U-Net相比,U-Transformer带来了巨大的性能提升。我们还强调了同时使用自注意力和交叉注意力的重要性,以及U-Transformer带来的出色的可解释性功能。


六、UNETR:用于3D医学图像分割的Transformer
UNETR: Transformers for 3D Medical Image Segmentation

作者单位:NVIDIA
论文:https://arxiv.org/abs/2103.10504
一句话总结:将3D医学图像分割任务重新设计为1D 序列到序列的预测问题,表现SOTA!性能优于SegResNet、Att-UNet等网络,
近年来,具有收缩路径和扩展路径(例如,编码器和解码器)的全卷积神经网络(FCNN)在各种医学图像分割应用中表现出突出的地位。在这些体系结构中,编码器通过学习全局上下文表示形式扮演着不可或缺的角色,而全局上下文表示形式将被解码器进一步用于语义输出预测。尽管取得了成功,但作为FCNN的主要构建模块的卷积层的局限性限制了在此类网络中学习远程空间相关性的能力。
受自然语言处理(NLP)Transformer在远程序列学习中的最新成功的启发,我们将volumetric(3D)医学图像分割的任务重新设计为序列到序列的预测问题。特别是,我们介绍了一种称为UNEt TRansformers(UNETR)的新颖体系结构,该体系结构使用纯Transformers作为编码器来学习输入量的序列表示并有效地捕获全局多尺度信息。

转换器编码器通过不同分辨率的跳跃连接直接连接到解码器,以计算最终的语义分割输出。
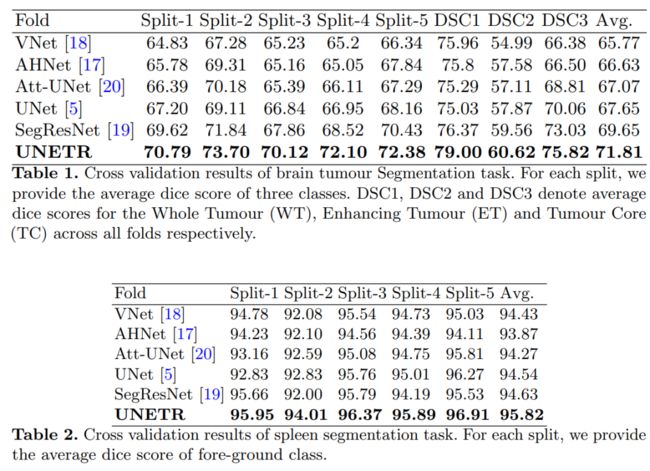
我们已经使用医学分割MSD数据集广泛验证了我们提出的模型在不同成像方式(即MR和CT)上对体积脑肿瘤和脾脏分割任务的性能,并且我们的结果始终证明了良好的基准。
七、Swin-Unet:Unet形状的纯Transformer的医学图像分割
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation

单位:慕尼黑工业大学, 复旦大学, 华为(田奇等人)
代码:https://github.com/HuCaoFighting/Swin-Unet
论文:https://arxiv.org/abs/2105.05537
一句话总结:首个基于纯Transformer的U-Net形的医学图像分割网络,其中利用Swin Transformer构建编码器、bottleneck和解码器,表现SOTA!性能优于TransUnet、Att-UNet等,代码即将开源!
在过去的几年中,卷积神经网络(CNN)在医学图像分析中取得了里程碑式的进展。尤其是,基于U形架构和跳跃连接的深度神经网络已广泛应用于各种医学图像任务中。但是,尽管CNN取得了出色的性能,但是由于卷积操作的局限性,它无法很好地学习全局和远程语义信息交互。
在本文中,我们提出了Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer。
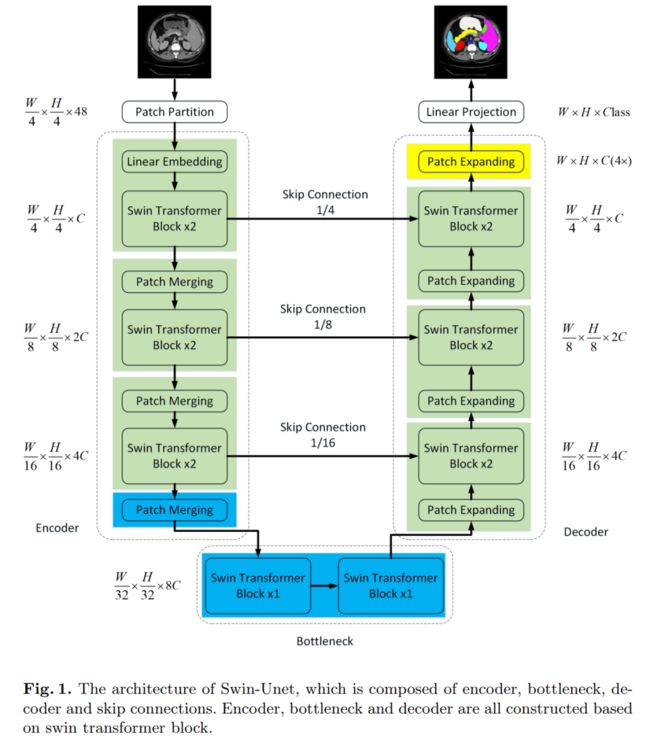
标记化的图像块通过跳跃连接被馈送到基于Transformer的U形En-Decoder架构中,以进行局部全局语义特征学习。具体来说,我们使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征。
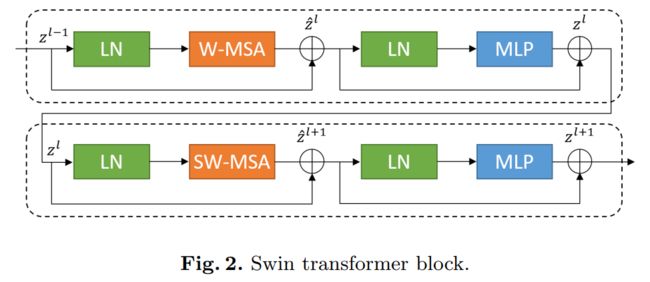
并设计了具有patch扩展层的基于对称Swin Transformer的解码器来执行上采样操作,以恢复特征图的空间分辨率。在对输入和输出进行4倍的直接下采样和上采样的情况下,对多器官和心脏分割任务进行的实验表明,基于纯Transformer的U形编码器/解码器网络优于那些全卷积或者Transformer和卷积的组合。

八、DS-TransUNet:医学图像分割的双Swin Transformer U-Net
DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation

作者单位:哈工大(深圳)
论文:https://arxiv.org/abs/2106.06716
一句话总结:将Swin Transformer作为编码器、解码器,再引入U型设计结构,表现SOTA!性能优于TransFuse、PraNet和FANet等网络。
得益于深度学习的发展,自动医学图像分割取得了长足的进步。然而,现有的大多数方法都基于卷积神经网络(CNN),由于卷积运算中感受野的限制,无法建立远程依赖关系和全局上下文连接。受到 Transformer 在对远程上下文信息建模的成功启发,一些研究人员在设计基于 Transformer 的 U-Net 的强大变体方面付出了相当大的努力。此外,视觉Transformer中使用的patch划分通常会忽略每个patch内部的像素级内在结构特征。
为了缓解这些问题,我们提出了一种称为双 Swin Transformer U-Net (DS-TransUNet) 的新型深度医学图像分割框架,这可能是首次尝试将分层 Swin Transformer 的优点同时纳入标准的编码器和解码器U 形架构,以提高不同医学图像的语义分割质量。

与许多先前基于 Transformer 的解决方案不同,所提出的 DS-TransUNet 首先采用基于 Swin Transformer 的双尺度编码器子网络来提取不同语尺度的粗粒度和细粒度特征表示。作为我们 DS-TransUNet 的核心组件,我们提出了一个精心设计的 Transformer Interactive Fusion (TIF) 模块,通过自注意力机制有效地建立不同尺度特征之间的全局依赖关系。
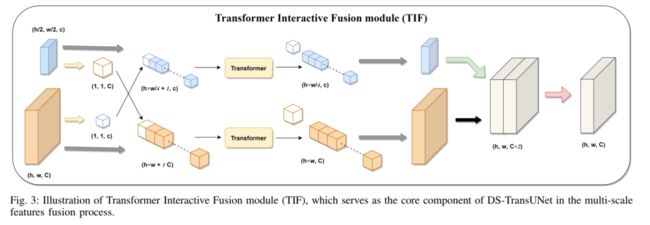
此外,我们还将 Swin Transformer 块引入解码器,以在上采样过程中进一步探索远程上下文信息。跨越四个典型医学图像分割任务的大量实验证明了 DS-TransUNet 的有效性,并表明我们的方法明显优于最先进的方法。



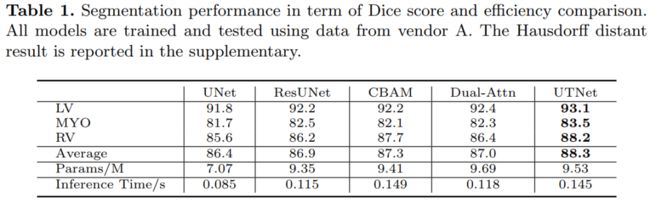
九、UTNet:用于医学图像分割的混合Transformer架构
UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation

作者单位:罗格斯大学等
论文:https://arxiv.org/abs/2107.00781
一句话总结:表现SOTA!性能优于ResUNet等网络。
Transformer 架构已经在许多自然语言处理任务中取得成功。然而,它在医学视觉中的应用在很大程度上仍未得到探索。
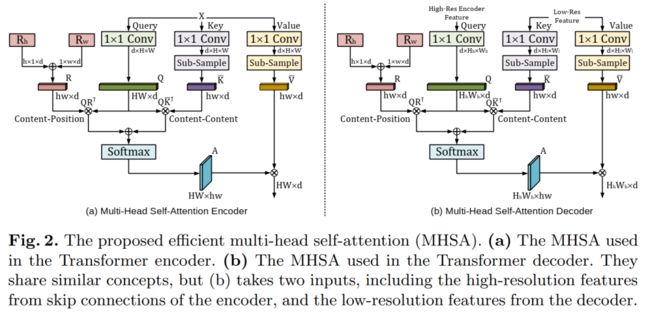
在这项研究中,我们提出了 UTNet,这是一种简单而强大的混合 Transformer 架构,它将自注意力集成到卷积神经网络中,以增强医学图像分割。

UTNet 在编码器和解码器中应用自注意力模块,以最小的开销捕获不同规模的远程依赖。为此,我们提出了一种有效的自注意力机制以及相对位置编码,将自注意力操作的复杂性从 O(n2) 显著降低到近似 O(n)。还提出了一种新的自注意力解码器,以从编码器中跳过的连接中恢复细粒度的细节。
我们的方法解决了 Transformer 需要大量数据来学习视觉归纳偏差的困境。我们的混合层设计允许在不需要预训练的情况下将 Transformer 初始化为卷积网络。我们已经在多标签、multi-vendor 心脏磁共振成像队列上评估了 UTNet。UTNet 展示了对最先进方法的卓越分割性能和鲁棒性,有望在其他医学图像分割上很好地泛化。

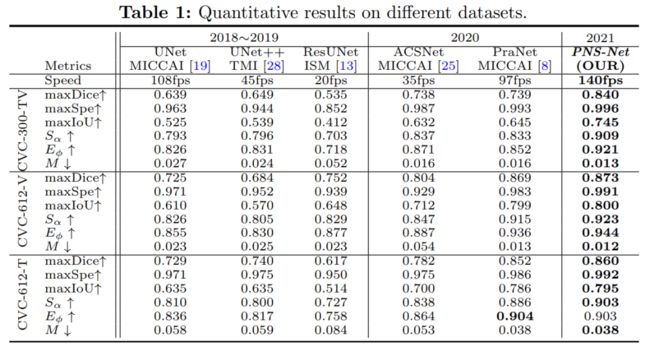
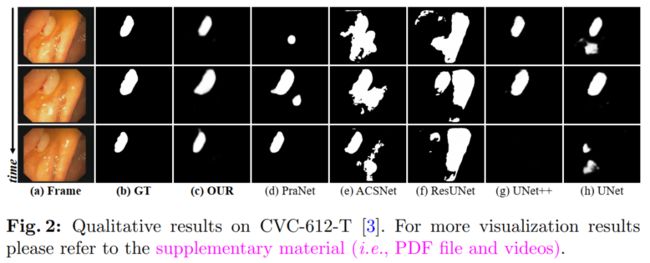
十、PNS-Net:用于视频息肉分割的渐进归一化自注意力网络
Progressively Normalized Self-Attention Network for Video Polyp Segmentation

作者单位:IIAI, 武汉大学, SimulaMet
论文:https://arxiv.org/abs/2105.08468
代码:https://github.com/GewelsJI/PNS-Net
一句话总结:表现SOTA!性能优于PraNet、ResUNet等网络。
现有的视频息肉分割 (VPS) 模型通常采用卷积神经网络 (CNN) 来提取特征。然而,由于其有限的感受野,CNNs 不能充分利用连续视频帧中的全局时间和空间信息,导致假阳性分割结果。
在本文中,我们提出了新颖的 PNS-Net(渐进归一化自注意力网络),它可以在单个 RTX 2080 GPU 上以实时速度(~140fps)有效地从息肉视频中学习表示,无需后处理。

我们的 PNS-Net 完全基于基本的归一化自注意力块,完全配备了递归和 CNN。在具有挑战性的 VPS 数据集上进行的实验表明,所提出的 PNS-Net 实现了最先进的性能。我们还进行了大量实验来研究通道拆分、软注意力和渐进式学习策略的有效性。我们发现我们的 PNS-Net 在不同的设置下运行良好,使其成为 VPS 任务的一个有前途的解决方案。
上述10篇医学图像分割论文下载
后台回复:医学图像分割,即可下载上述论文PDF
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看