背景
网易云信作为市场上领先的音视频/IM PaaS 服务提供商之一。对外提供产品服务主要以 SDK 形态,产品服务涉及平台主要有 Android/iOS/Windows/mac OS/Linux/Web,涉及到框架有:小序/RN/Fluttter/Electron/Cocos2d/Unity。
作为以 SDK 作为产品形态的企业研发人员,最主要的任务就是要确保 SDK 质量稳定与可靠,强调服务高质量与高可用,强调 API 易用性。为此云信基于 toB 丰富的研发经验,摸索出了一套针对 toB 的行之有效的质量保障体系。云信质量保障体系主要涵盖了两个阶段:研发阶段,线上运行阶段。
研发阶段质量保障
为了尽可能有效地保障研发阶段的代码质量,云信的代码质量保证步骤可以概括为下图:
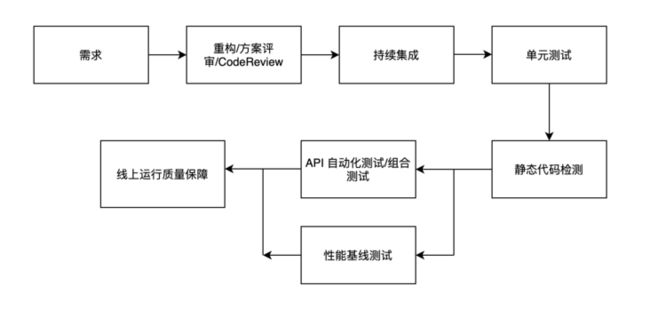
重构与方案评审
云信对于下文中符合时间长短定义的中变更以及重构以上定义的变更,都会组织专家进行方案评审工作。技术维度本质上是衡量创新的维度。因此一般可以从智能化,创新度,基础性,影响度等一级指标展开。
重构的定义:在不改变软件可观察行为的前提下,调整其结构,提高其可理解性,降低其修改成本。
重构的关键在于运用大量微小且保持软件行为的步骤,一步一步完成大规模的修改。即使重构没有完成,也可以随时停下来,保证代码的运作。
对于“可观察行为”的理解:从用户所关心的角度而言,重构前后的软件表现应当一致(SDK API 无变动,调用顺序没有发生变化、软件输入输出一致)。但是重构所带来的性能提升、接口改变、调用时序改变甚至潜在 bug 的优化都不放在“可观察”的范围内。
重构的原因:
- 当前架构不足以支撑未来的需求;
- 当前架构性能存在很大的优化空间;
重构的意义:
- 改进软件的设计,软件逻辑更加清晰,消除重复代码;
- 软件可读性更强,更容易理解;
- 解决代码架构不调整就无法根本上修复的 bug;
- 解决代码架构设计导致无法满足业务需求的问题;
重构划分:重构的划分可以按照规模程度、时间长短两个维度来定义。
按照规模程度划分:
- 小型重构:对代码的细节进行重构,主要是针对类、函数、变量等代码级别的重构。比如常见的规范命名(针对词不达意的变量再命名),消除超大函数,消除重复代码等。一般这类重构修改的地方比较集中,相对简单,影响比较小、时间较短。所以难度相对要低一些,我们完全可以在日常的随版开发中进行。
- 中大型重构:是对代码顶层进行重构,包括对系统结构、模块结构、代码结构、类关系的重构,具体表现有系统内部运行逻辑发生了变化,模块调用时序发生了调整,模块处理耗时&内存发生变更,系统内模块依赖方式发生了变更等等。一般采取的手段是进行服务分层、业务模块化、组件化、代码抽象复用等。这类重构可能需要进行原则再定义、模式再定义甚至业务逻辑再定义。涉及到的代码调整和修改多,所以影响比较大、耗时较长、带来的风险比较大(项目叫停风险、代码 bug 风险、业务漏洞风险)。
按照时间长短划分:
- 小变更:一般对于 1 人日以内工作量的需求为小变更;
- 中变更:1-4 人日以上称为中变更,但不涉及到模块的主流程的变更;
- 重构:个人工作量超过一周,也就是 5 个工作日的,涉及到 pipeline 流程中的多个模块变更。
Code Review
云信采用 Gitlab + 自建辅助检测服务器的方式确保 Code Review 的流程被执行到位。

同时为了配合 Code Review 合规性检查中的“至少有 2 名评审人评审通过,且其中至少一名为模块的代码评审人”这个通过标准,需要整理和确定各个模块的代码评审人。后续合规性检查中会结合列表中的评审人进行校验。
持续集成
高可用 CI/CD 平台建设
《重构-改善代码既有的设计》作者 Martin Fowler 大师在《持续集成》一书中的定义,“持续集成是一种软件开发实践。在持续集成中,团队成员频繁集成他们的工作成果,一般每人每天至少集成一次,也可以多次。每次集成会经过自动构建(包括自动测试)的检验,以尽快发现集成错误。许多团队发现这种方法可以显著减少集成引起的问题,并可以加快团队合作软件开发的速度。
从整个研发阶段的保障流程可以看出,持续集成是关键一环。而对于云信来讲传统的 Jenkins 服务或者 Overmind 相关管理系统根本无法满足任务并发 40 几个上的要求以及单个任务能够输出 4-6 个平台产物的诉求,于是需要云信自研一套高可用 CI/CD 的平台。
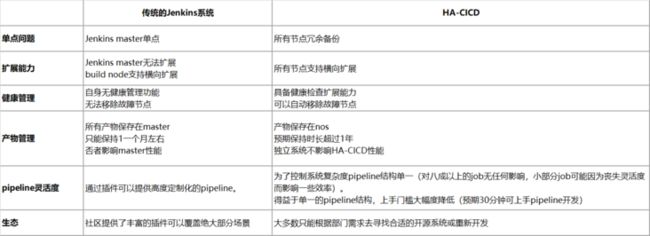
传统的 Jenkins 服务
原生 Jenkins 是一拖多结构。全局唯一的 Jenkins master 是整个集群的核心节点,负责集群中所有的事务,甚至可以负责构建任务。因此存在 Jenkins master 单点故障, 一旦任务多了之后就会发生严重的 Block 情况,执行一个构建任务也许需要十几个小时。
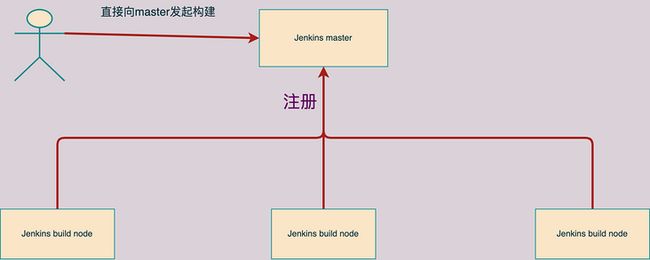
高可用 CI/CD 服务
为了解决以上 Jenkins master 的单点故障,满足任务的高并发,自研了一套高可用服务。
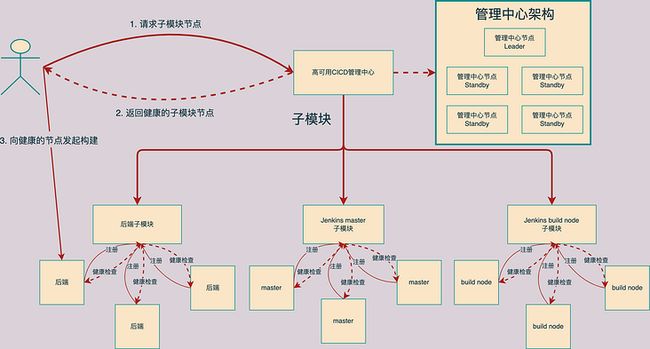
高可用 CI/CD 管理中心负责维护系统中的所有节点的状态。要加入集群的所有的高可用 CI/CD 后端,Jenkins master 节点, 打包机节点都要向高可用 CI/CD 管理中心注册。需要使用集群中某个子模块节点的时候也要向管理中心申请。同时管理中心会定期检查每个节点的健康状况,确保每次申请返回的都是健康的节点。
管理中心由一个 Leader 和四个 Standby 组成。Leader 是管理中心的核心,负责集群中所有决策,所有的 Standby 会同步 Leader 的数据,一旦 Leader 故障,其中一个 Standby 就可以通过选举成为新的 Leader。
效果对比
静态代码检测
代码检查可以有效地提高代码质量,快速定位代码隐藏的错误和缺陷,帮助代码设计人员更关注于分析和解决代码设计缺陷,显著减少代码逐行检查上花费的时间,提高软件可靠性并节省软件开发和测试成本。静态代码检查可以检查出的主要问题有:变量未初始化、数据类型不匹配、返回局部变量、数据越界、内存可能存在泄露点等。
单元测试
单元是人为规定的最小的被测功能模块。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。单元测试是为开发代码质量保驾护航的一个重要环节,云信已经在音视频 SDK 开始逐步落地单元测试,确保复杂音视频 SDK 系统的各个子系统与子功能功能的可用性以及稳定性。
基线对齐
针对不同的场景、不同的手机性能等级,云信都会有自己的性能基线(产品出厂的标准),包括内存占用情况、功耗情况、音频的 MOS 分、QoS(在开启音视频,不同弱网情况下关注卡顿率、码率变化、分辨率等情况)、视频首帧的传输时间。
API 接口测试
云信自研了一套 Hermens 自动化平台系统,用于 API 接口的测试工作。
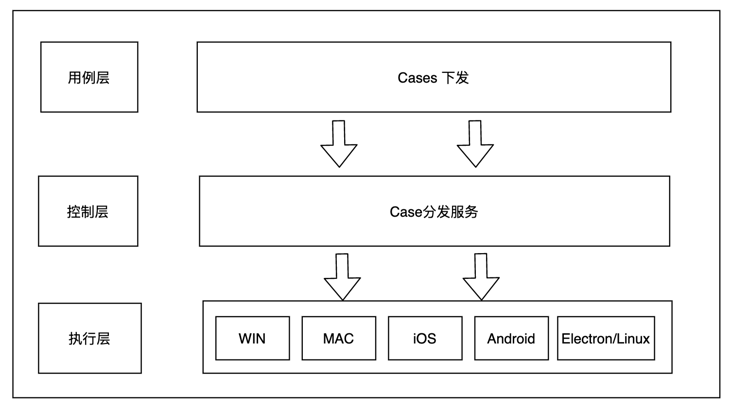
以上是 Hermens 自动化测试平台系统的架构,该系统涵盖了以下几种测试范畴。
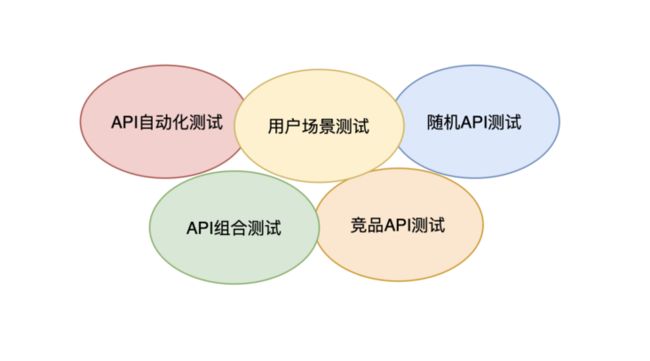
- API 自动化测试
研发人员可自主通过脚本写 API 测试用例,集成到 CI 的构建 pipeline 中去,作为研发阶段的一个环节,做到 Daily Build 的自动化测试。 - 用户场景测试
通过模拟用户的各种使用场景如 1对1 场景、KTV 场景、直播场景等等, 模拟 API 的调用。 - 随机 API 测试
通过模拟用户随机调用 API, 验证 SDK 系统是否存在崩溃的问题或者功能错乱问题,确保系统的容错性,保证系统的健康。 - API 组合测试
通过 API 组合测试,验证一些重要的 API 组合调用功能的可用性以及幂等性。 - 竞品 API 测试
通过写竞品 DEMO,模拟双方系统相同参数输入,获取双方系统的表现差异性,从而优化与改进 SDK,如输入相同的音视频参数,通过录制音视频通话,通过音视频专家和工具,对比双方在用户可感知范围上的差异。
线上运行阶段质量保障
正如德内拉.梅多斯《系统之美》书中所讲,理想的系统应该有适应性、自组织性、层次性特性。适应性是因为系统内部结构存在很多互相影响的反馈回路,正是这些回路相互支撑,即使在系统遭受巨大的扰动时,仍然能够以多种不同的方式使系统恢复至原有状态。自组织性是指系统具有学习多元化复杂化进化的能力,系统能够通过自主学习能够衍生出新的事物或者技术。层次性是指一个大系统中包含了若干小子系统,系统和子系统的包含和生成关系就被称为层次性,各个子系统内部的联系要多于并强于子系统之间的联系。云信遵从以上理想系统的三个特性方向思考与构建系统。
如果把线上质量打磨想象成是一个系统工程的话,SDK 版本在众多的试验场灰度是系统的输入,系统输出是一个质量稳定与可靠的 SDK,反馈回路有两条:
- 线上客户到 SO 团队,再流转到研发团队的反馈回路;
- 异常主动感知系统建立的反馈回路。
通过以上版本质量的系统化工程的打造与实施,能够有效地确保交付给大客户的版本是稳定可靠的,具体质量打磨策略如下:
质量打磨策略
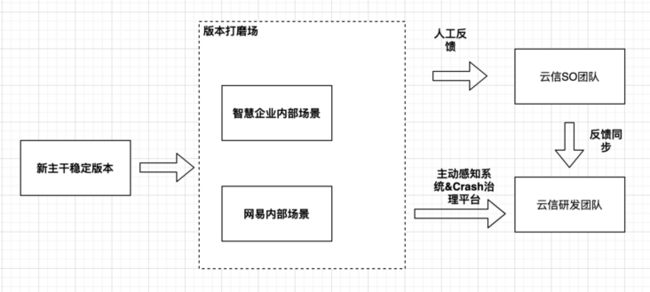
版本质量打磨策略
由上图可知,线上质量打磨策略系统,反馈回路主要有以下两条通道:
- 客户通过电话/微信/QQ 等线上服务平台反馈(Bug 、API 调用方式、场景方案等易用性问题反馈);
- 异常感知系统(CRASH/ANR/OOM/内存泄漏异常、接口调用顺序异常、性能(内存/CPU)异常、业务异常等等);
通过对以上两条回路反馈的问题进行版本问题修复,然后重新发布,不断系统迭代增强,直到线上场景覆盖、日活、 bug 率达到预期的标准,才被允许能交付给大客户。
异常感知系统(先于用户发现)
为了能够及时发现线上服务异常,先于客户发现问题,在客户服务上争取主动,提升客户的满意度。云信构建了一整套完整的 SDK 主动异常感知与监控系统以及线上应急响应系统,该系统涵盖了各个 C 端,各个平台,Android/iOS/macOS/Linux/Windows(Web 端是基于云音乐异常监控平台&自建了一套异常追踪系统),对于用户的异常(代码运行异常\业务异常)进行了立体式的异常监控。
以下是整个系统的架构图:
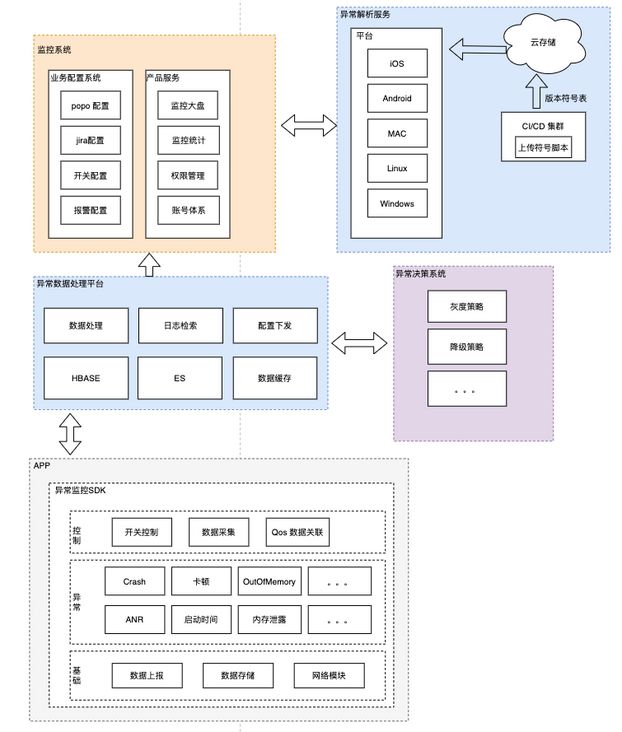
代码异常监控模块
支持 Android/iOS/Windows 的平台层与 Native 库的 Crash(如异常监控模块支持Android jvm Crash 异常、也支持 Native 库的异常)、线程卡顿、OOM 、内存泄漏、ANR 等异常的捕获。
业务异常监控服务
除了以上代码上的异常,云信正在完善一系列的异常传感器(业务异常模型),音视频业务异常建设(无声、音频视频卡顿、首帧耗时、httpdns 高可用异常数据的监控)、用户使用量异常监控、API 调用顺序异常。

账号体系
传统的异常捕获系统是基于 App 维度来统计 Crash 等异常信息的,而做 PaaS 的,希望是看到具体的 PaaS 产品及对应的 SDK 维度来统计 Crash 信息,因此设计了三级的账号体系,以支持每个层级来做聚合统计监控。
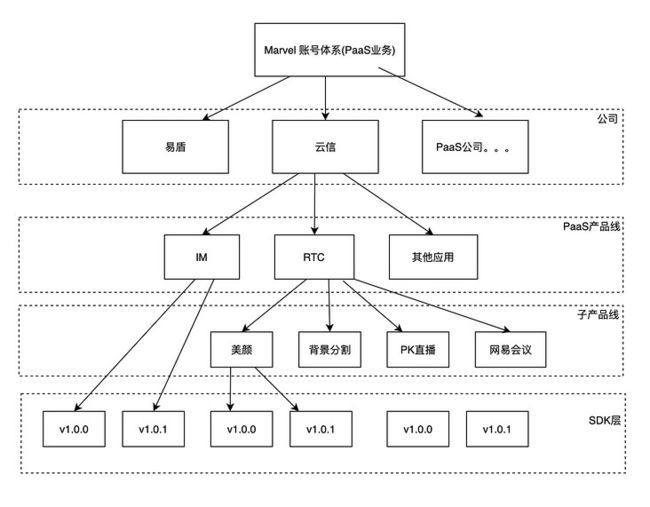
三级账号体系说明如下:
- 公司级别。如易盾、云信等 PaaS 服务厂商;
- 公司产品 SKU。如云信有 IM SDK、RTC SDK、播放器 SDK;
- SKU 下的子产品。如 RTC SDK 下有美颜、背景替换、水印等插件化的子产品;
监控系统
当线上发生 Crash 异常、线程卡顿异常、ANR 、OOM 等异常的时候,系统会自动创建 Jira ,同时 Jira 流转到指定的模块负责人。同时能够查看整体的 Crash 率、Crash 具体的堆栈信息、堆栈信息的反解。

异常解析服务
支持 Android/iOS Crash 堆栈的反解服务,未来将支持 Windows/Linux/mac/Flutter 平台的异常反解服务。所有 CI 出的产物的符号文件都将自动上传上传到 NOS 服务,当用户需要进行 Crash 堆栈信息的反解的时候,异常解析服务会基于 Crash 对应的公司、产品、子产品号版本号、BuildId 等信息进行精准的解析。
总结
以上内容为云信针对 toB SDK 质量保障体系的思考与建设实践。质量保障体系涵盖了研发阶段与版本交付阶段,从高可用的 CI/CD 建设、单测、静态代码测试、自动化测试、性能基线测试,再到异常主动感知系统的建设,每一个环节的实施与落地,云信最终希望交付给客户具有优秀的用户体验、可靠而稳定的产品服务。