yolov5代码解读-训练
前言:
上两篇:yolov5代码解读-dataset、yolov5代码解读-网络架构
yolov5的数据处理模块和网络架构已经写完了,做好了这些基础工作,就可以来训练了。
代码已上传到github,数据集和权重文件已上传到百度网盘(链接在github里),如需下载请移步:https://github.com/scc-max/yolov5-scc
目录
- 前言:
- 参数解读
-
- 超参数hyp文件
- 命令行参数
- 训练流程
-
- 训练前
- 训练
参数解读
超参数hyp文件
在训练之前,先看一下有哪些超参数。在yolov5工程里面有一个 data文件夹,里面有一个hyp.scratch.yaml文件,可以用写字板或者记事本打开。
上面这些参数默认就好,没什么改动的必要。
lr:学习率就不用说了,在训练过程中会依次下降,初试学习率在第一行内容中。余弦退火就是为了动态降低学习率。
momentum: 动量,一般为0.95左右。
weight_decay:权重衰减,防止权重更新幅度过大,过拟合。
warmup:热身,让模型先热热身,熟悉熟悉数据,学习率要小,相当于只是去看看,还没正式训练呢,学习率太高说不定就学跑偏了。
下面是损失和图像增强的一些参数,大致也都默认就好。
命令行参数
这些是train.py里面的参数,前几个不用说,看一下就知道什么意思。
rect是指要不要做矩形训练,例如448×448给修改成448×w这样一个尺寸,默认是不做。
resume是指是否继续上次的训练,这是一个日志文件,在训练后会有一个last.pt,是保存的权重文件。store_true,就是没有默认的情况下就是False。因为我只有矿山一个类别,所以我的single-cls就是store false,然后默认为True了。如果是多类别的,这里要写store_true。
最后一个workers,windows系统一定要指定为0,指定其他的会百分百报错。windows和pytorch没有很好地兼容。
训练流程
训练前
日志文件
首先是定义日志文件的地址,然后加载了一些超参数例如epochs。
pt文件保存了best和last两种,best是使用了4个指标对模型参数做了评估,得分是:
sum([0.0, 0.0, 0.1, 0.9]*[精确度, 召回率, [email protected], [email protected]:0.95]
所以主要还是根据mAP值。
yolov5的日志文件做的非常好 ,在runs文件夹下记录了每一次迭代的结果,进入其中一次查看。
有权重文件,有tensorboard需要的events文件,有记录的超参数。还有标签的分布情况。有记录的精度和召回率情况,还有对其中几个batch的预测结果。在results文件中,记录了各个指标,其中有精度和召回率等。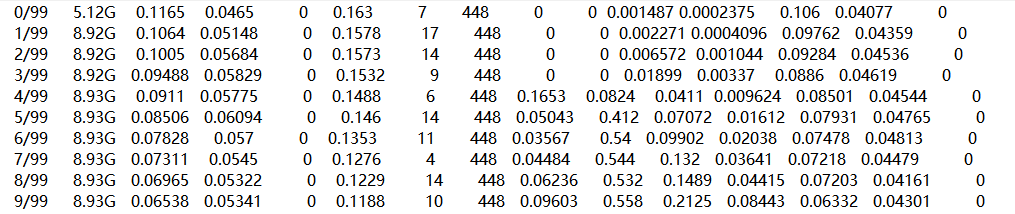
加载图像路径和类别信息
这一段是先设置了随机种子,然后记载data.yaml数据,读进来训练图像和测试图像的地址。在数据处理部分已经说过了,标签的地址是根据图像的地址替换掉’images’为’labels’得到的。所以这里只需要读图像地址就可以了。

这面这个就是data.yaml中的数据。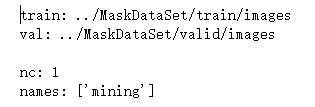
加载模型
之后就是加载模型了。一般都是需要用预训练模型的,如果没有预训练权重,就从之前解读的Model那里创建一个新model。如果有预训练权重,就加载一下。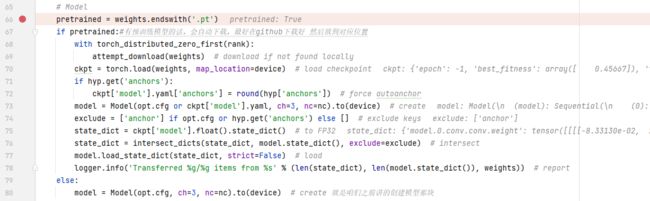
迁移学习
这一部分是做迁移学习的,也就是当数据量的时候,尝试冻住前面一些层,让他们不再更新了。但是据说没有必要。但是这段代码还是可以看看的,k是索引,v是具体的参数。如果确定freeze中的层数,有在k中的,或者说,k有在freeze中的,那么就把这层相关的v冻结掉,不再进行梯度下降和参数更新。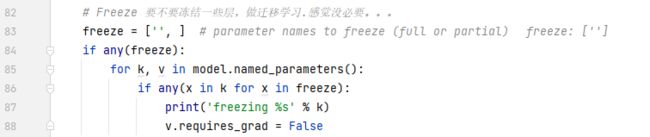
优化器
这一段是优化器,之前设置了batch_size是48,这里默认nbs是64,相当于32道64之间的batch size都按照64来更新了,可以看成即使你的显卡不太行,不能设置很大的batch size,也能在这里通过nbs人为增大batch size。不过64和48在这里并没有区别,因为有一个求round也就是取整的操作,最后结果都是1.
optimizer用的是sgd,这个在之前的opt参数里有写。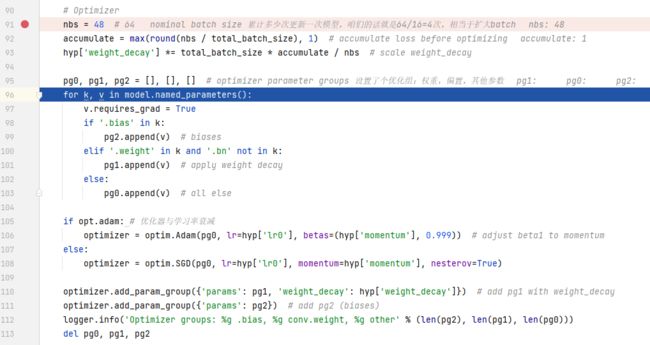
看一看k和v。k是参数名字,v是具体的参数类,有很多的属性,不过这里只看一下它的数据长什么样子。![]()
![]()
继续训练
下面这一部分,是要不要继续训练。如果是,就先去读日志文件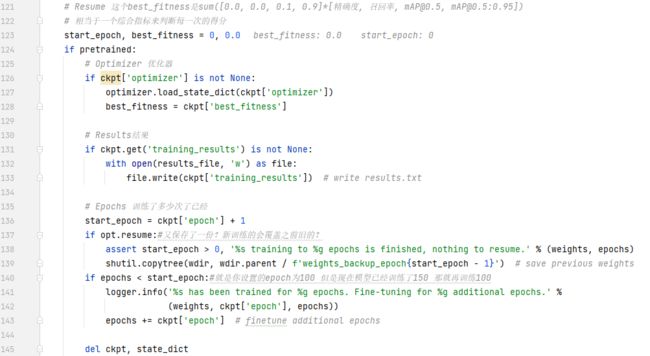
预训练权重,也就是.pt文件,一般是有的。这时就会走这条继续训练的路了。从ckpt里面加载一些参数。
多机多卡
这一部分先检查了一下img的大小,是不是32的倍数。,后面就是训练时设备的选择了。
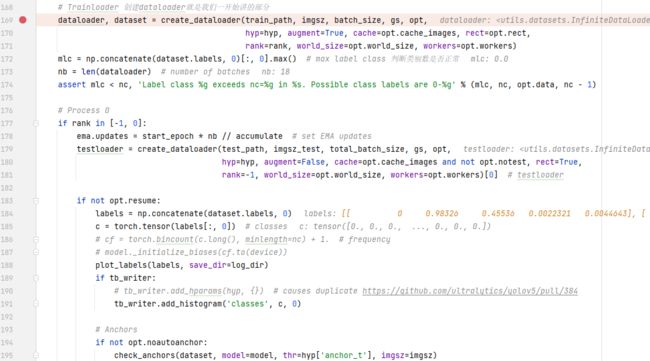
- DP模式:单机多卡,但是这个情况也会出现一些问题,例如主卡爆掉,其他卡利用率上不去。当然,这是要修改底层和与硬件相关的问题,怎么优化还得靠人家框架官方。
- DDP模式:多机多卡,能解决DP不均衡,主卡爆掉的问题,也就是单机多卡也能用,但是这个一般人也用不到,家里有条件的时候再去研究吧。
data loader
终于开始加载数据了,之前已经说过了数据处理,这里直接加载处理好的数据就可以了。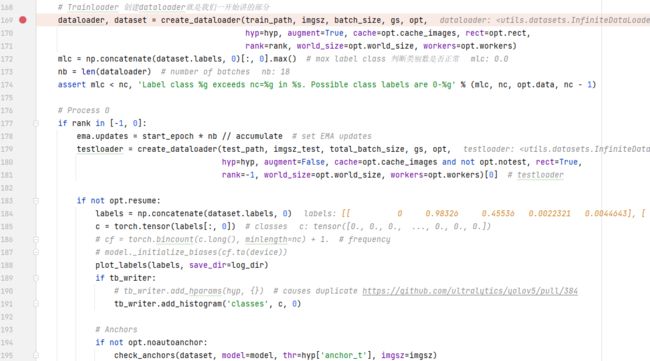
模型参数
这部分是修改模型参数,标签只有1个,然后cls就变成了1/80。
训练
这部分就开始训练了,前面有个1000次的迭代热身,之后是一个sacler,混合精度,这个可以使得训练速度大大加快。因为大多数框架都是用的fp32(32bit存储一个数据)的精度,但是一般用不到那么高的精度,混合使用fp16和fp32能大大提高训练速度。这个是pytorch1.6以上才有的功能。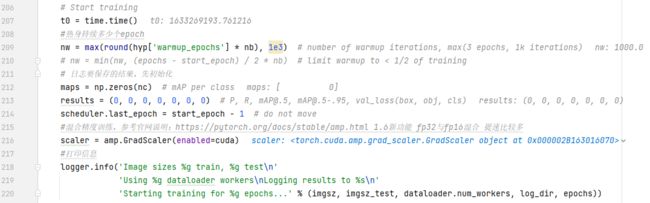
这一部分代码不会走,if这条路。rank代表不同的模式,单机单卡,多机多卡等。一般一个gpu的话,rank = -1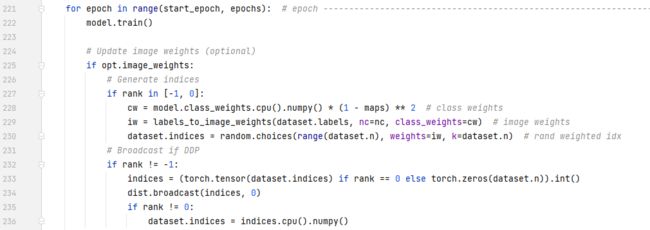
先创建一个损失,然后把dataloader放到进度条里面,为了后面可以一个batch一个batch做训练,并对每一个batch打印进度。初始化mloss,4维,要存放4个数。
开始一个batch的训练,先热身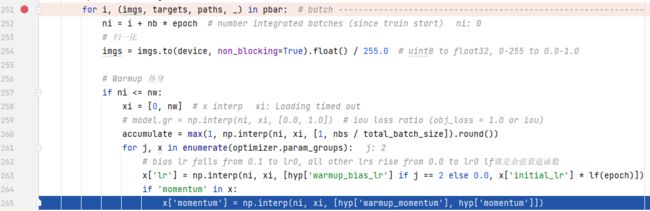
多尺度:没使用
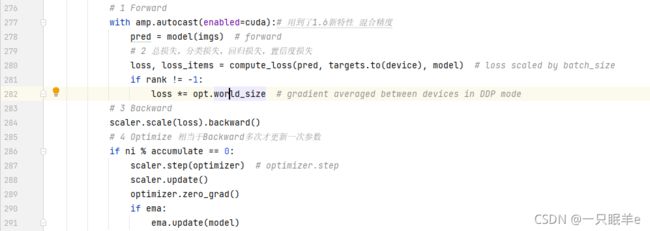
前向传播,反向传播,优化。这部分说说一下。前向传播时把img送到model,然后得到一个预测结果(pred),基于这个结果计算损失。之后就是根据loss进行一次反向传播。但是优化的时候不是根据batch,而是根据accumalate,这个之前说过,是累计的batch,相当于放大的batch。不过这里accumalate和batch是一样的,也就是都是训练一个batch更新一次梯度。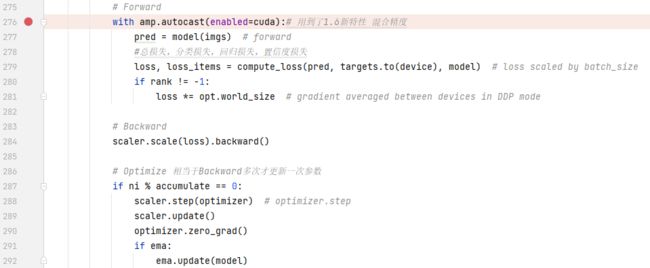
对loss和loss item,看一下compute loss的返回值。loss items存放了对box,obj,cls和总的loss。
打印和画图。这里更新了之前初始化为zeros(shape为4)张量的mloss。mloss这个公式是计算batch平均损失,i是当前batch的索引,从0开始。loss items是当前batch的loss,mloss*i是之前i个batch的损失。最后/i+1则是计算这些当前epoch内batch的平均损失了。这个mloss后面写进results文件有用到。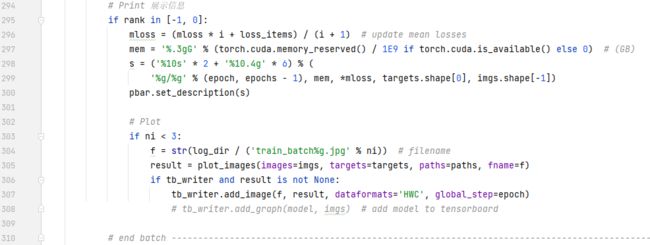
这一部分显示设置学习率衰减,然后就是计算test的一些指标。比如map,计算results。
第一行初始化的lr也为了后面做准备,里面一共有3项,lr0,lr1,lr2。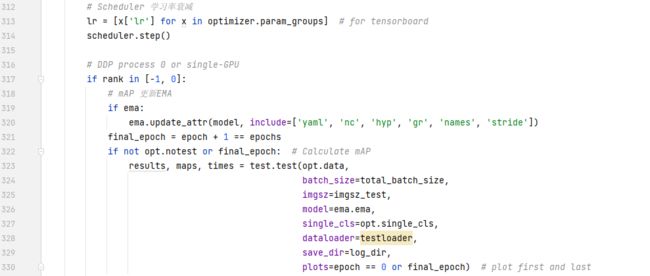
这是前面对results的初始化![]()
这是test.test的返回结果。![]()
主要看这段代码的最后一行,把x写进去,对应的tags是上面那个tags数组。这里对于mloss写了mloss的前三项(一共4项)。再加上results的6项,再加一个lr,一共10项。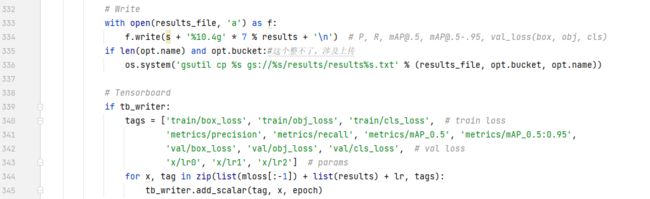
更新mAP,保存模型,结束训练。
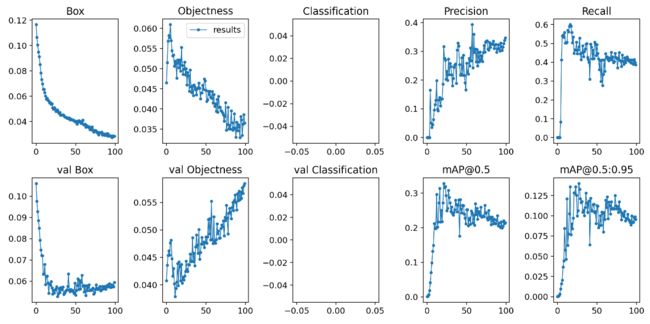
最后把results里面的内容给画出来了。
最后强调一下核心四件套:forward、loss、backward、optimizer。
如果觉得还不错,点个赞鼓励一下吧~