Python爬虫及可视化大作业(附部分讲解)
全部代码及部分讲解(给需要的人,代码简单但是好在清楚呀,大家点进来看看,碎碎念就当玩笑调剂一下,不想看可以直接掠过吼,代码在下头)
怎么说呢,由于去年手欠选了一个双创课,到了交大作业的时候了,也头一回觉得记录编码过程中的种种对自己对别人很有用!!半个月的血泪史吧,写出来了,加上个人文档编辑能力比较好(嘿嘿嘿!)高分过(老师好严厉好害怕的说(꒦ິ⌓꒦ີ))
还是很开心的,这篇文章是写博客的开始啦!(头一回写碎碎念比较多,sorry啊)
这里先放代码,最近在写java和python的课设(计算机专业,懂得都懂),等忙完我再想想这些个过程里遇到的问题,然后再记录分享哈~~~~~~~~~碎碎念
我的代码属于是比较简单的,全程几个函数,也没有类(我承认是因为还没有学),主函数用prettytable简简单单搭了个系统的样子(没想到这个答辩的时候成了加分项)。了解过的同学应该能看出来这是跟着某站上的一个视频写出来的,但是没有用到flask(没有Pycharm专业版 ・᷄ὢ・᷅ ),中间加了些自己的东西,可视化是自己写的了。后来有试过爬其他的,但是由于当时太忙没来得及写完,以后再说啦
上代码:(不行了,本来只想放代码,但是后面稍微讲讲这个代码吧,现在感觉它稀碎稀碎的,下面这段是完整的代码)
(再叭叭一句,里面有些东西是不是感觉啰嗦,可以有但大可不必的那种,哈哈,是为了交作业凑行数,本来觉得也没啥,但是有个别的院的同学说他写了五百行,我就不行了,狮子座的胜负欲不合时宜地跑出来了,硬从四百拽到了六百多行)
代码里”写网址“的地方把网址加上去就可以,不然发不出去
import bs4
import urllib.request, urllib.error
import xlwt
import re
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
import numpy as np
from PIL import Image
import pyecharts.options as opt
from pyecharts.charts import Bar
import pyecharts.options as opts
import pandas as pd
from prettytable import PrettyTable
def main():
baseurl = "写网址"
askURL(baseurl)
datalist = getData(baseurl)
savepath = "豆瓣TOP250.xls"
saveData(datalist,savepath)
print("爬取完毕,可通过excel文件查看全部数据")
table1 = PrettyTable(['欢迎进入可视化界面'])
table1.add_row(['***1.词云图'])
table1.add_row(['***2.饼图'])
table1.add_row(['***3.柱状图'])
print(table1)
z = 1
while (z == 1):
x = int(input(['^^^请输入您的选择:']))
if x == 1:
table2 = PrettyTable(['欢迎查看词云图'])
table2.add_row(['***1.以概述为内容'])
table2.add_row(['***2.以中英文片名为内容'])
print(table2)
y= int(input(['^^^请输入您的选择:']))
if y == 1:
ciyun()
elif y == 2:
ciyundou()
else:
print('输入有误,请按规则输入!')
if x == 2:
table3 = PrettyTable(['欢迎查看饼图'])
table3.add_row(['***1.按评分划分影片数量饼图'])
table3.add_row(['***2.全部影片评价数饼图(图片可能引起不适,慎入!)'])
print(table3)
y = int(input(['^^^请输入您的选择:']))
if y == 1:
chart_rat()
elif y == 2:
chart_ratall()
else:
print('输入有误,请按规则输入!')
if x == 3:
table3 = PrettyTable(['欢迎查看柱状图(需移步浏览器查看)'])
table3.add_row(['***1.全部评价数、评分柱状图'])
table3.add_row(['***2.按评分划分影片数柱状图'])
table3.add_row(['***3.自定义评分区间查看影片数量柱状图'])
print(table3)
y = int(input(['^^^请输入您的选择:']))
if y == 1:
chart_Barall()
elif y == 2:
chart_Bar()
elif y == 3:
print("我们的评分划分为:[9.7 - 9.5, 9.4, 9.3, 9.2, 9.1, 9.0,8.9, 8.8, 8.7, 8.6, 8.5 - 8.3]")
beging = float(input("请选择您需要的起始(较低)评分:"))
ending = float(input("请选择您需要的终止(较高)评分:"))
chart_BarAuto(beging, ending)
else:
print('输入有误,请按规则输入!')
z = int(input('您是否需要继续查看可视化图像(是1否2):'))
# 规定各类信息分类规则
findLink = re.compile(r'')
findImgSrc = re.compile(r'(.*)')
findRating = re.compile(r'')
findJudge = re.compile(r'(\d*)人评价')
findIng = re.compile(r'(.*)')
findBd = re.compile(r'(.*?)
',re.S)
#得到指定一个url的网页内容
def askURL(url):
head = {
'''这个大括号里放浏览器头部信息,具体方法和书写要求有一些需要注意的地方,需要查一下'''
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i*25)
html = askURL(url)
soup = bs4.BeautifulSoup(html, "html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data = []
item = str(item)
#print(item)
#break
Link = re.findall(findLink, item)[0]
#print(Link)
data.append(Link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "")
data.append(otitle)
filename = "t2.txt"
with open(filename, 'a', encoding='utf-8') as f:
f.write(ctitle + '\n')
f.write(otitle + '\n')
else :
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
ing = re.findall(findIng, item)
if len(ing) != 0:
ing = ing[0].replace("。", "")
data.append(ing)
filename = "t1.txt"
with open(filename, 'a', encoding='utf-8') as f:
f.write(ing + '\n')
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub(' 那就稍微讲讲吧
首先一堆第三方库(头一回写博客,啰嗦比较多,但是我不管,我要哭,当时有几个库死活装不上,多方无解,差点放弃几个可视化了,最后竟然是靠舍友男朋友(一个学长)帮忙改了环境(想想就头疼)才装上的)
讲代码我用词可能会不太准确,但是应该没有大错误
然后是主函数,这边用了一个模拟程序入口,就是代码最后三行那个,所以主函数写在了开头,先把数据爬一遍,然后开始查看可视化,挺简单的就掠过啦,有问题大家评论问,看到一定会回的
然后是一堆正则表达式,用来规定读取各类信息的规则。因为爬取网页url爬下来的信息分门别类的。。。不知道咋用词了,先放一个影片——《肖申克的救赎》的url大家看看
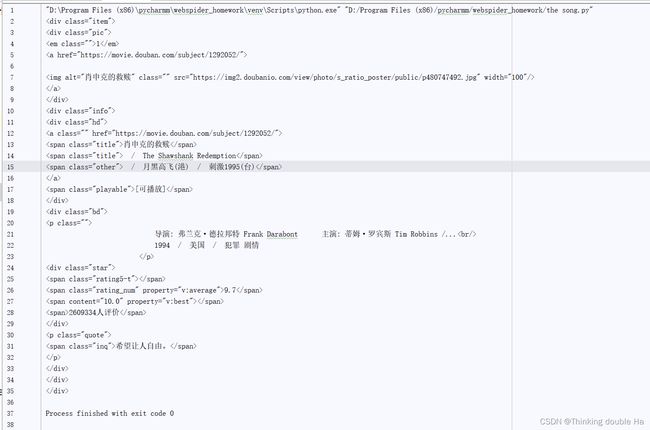
这个是在代码askURL里爬下来的,就是下面这段(#print(html)注释掉的这句执行出来就是这个影片的url啦)。不得不说,豆瓣的就是标准,怪不得用它教学,简直就是像医学生练扎针的时候遇到喜欢的血管喂(大家以后爬别的就知道了)。
def askURL(url):
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)正则表达式分别把这些信息搞到手就欧克了
然后是爬取、分析、保存数据,getData、askURL、saveData...建议大家移步b站看老师的专业讲解,中间有不一样的就是存了影片名称和简介到t1.txt 、t2.txt里,后面用来做词云图(可视化的一个)了
可视化部分是词云图(wordcloud),饼图(基于matplotlib的python数据可视化),柱状图(用pyecharts库)做的,建议大家可视化图表挑一个写就好(建议pyecharts),唉,本来想表现一下来着,然后因为这个被老师说了┭┮﹏┭┮
词云图第一个是“概述词云图”,用了字词拆分,刚开始完全没有意识到要把单个字删掉有什么意思,就没有删。我的词云图跟教程不太一样吧哈哈哈我只是单纯为了好看,别的没有考虑哈。现在的代码里不是有一行stopwords=STOPWORDS.add('的') 这个就是老师讲完赶紧加了一个,但还不是很完善,(其实我还是不明白有什么大用),我以为这个就是做出了好看来着(类似海报那种好看),后续给大家出词云图说明哈。图(还没有屏蔽“的”字的图):
是不是还可以,当时做出来给朋友看的时候由于——“人是你的了”被笑了还哈哈哈
后面名称词云图没有拆句子,不然真说不过去了,图长这样: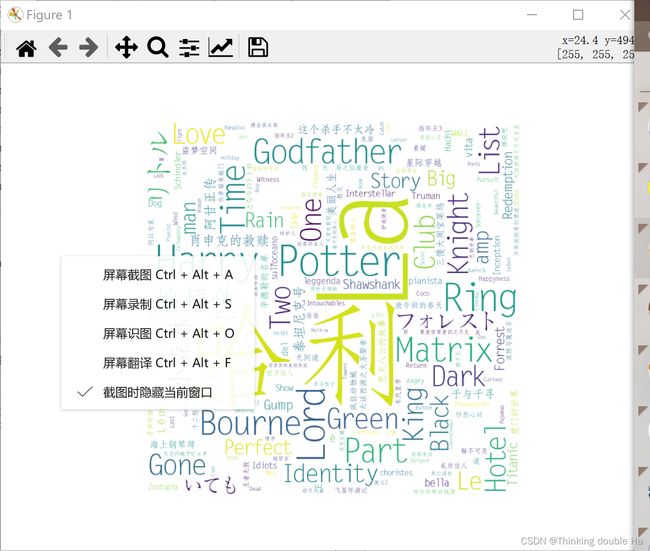
害呀,那个好看的图找不到了,大家凑活看
~~~~~戛然而止~~~~~
呜呜呜我能不能说感觉自己写的稀碎,更多的是记录而不是分享知识,我去面壁思过一会儿,以后看需要再讲剩下的(所以大家有需要的话记得评论区说呀)。
如果大家喜欢看这种加了血泪史的博客的话麻烦评论“哈哈哈”,我就不改碎碎念啦
错误肯定有,我还是个小菜鸡
各位大佬有疑问或者有指点可以评论区留言,感谢!
关注肯定也想要,聊天式写博客哈
不知道以后看到会不会羞于这个时候的不懂事
下次见,会有下次的