【Pytorch with fastai】第 9 章 :表格建模深入探讨
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
分类嵌入
超越深度学习
数据集
Kaggle 比赛
看数据
决策树
处理日期
使用 TabularPandas 和 TabularProc
创建决策树
分类变量
随机森林
创建随机森林
包外错误
模型解释
预测置信度的树方差
特征重要性
删除低重要性变量
删除冗余功能
部分依赖
数据泄露
树解释器
外推和神经网络
外推问题
查找域外数据
使用神经网络
Ensembling(合奏)
Boosting
将嵌入与其他方法相结合
结论
表格建模采用表格形式的数据(如电子表格 或 CSV)。目标是根据其他列中的值预测一列中的值。在本章中,我们不仅会研究深度学习,还会研究更通用的机器学习技术,例如随机森林,因为它们可以根据您的问题给出更好的结果。
我们将看看我们应该如何预处理和清理数据以及如何在训练后解释我们的模型的结果,但首先我们将看到我们如何通过使用嵌入将包含类别的列输入到期望数字的模型中。
分类嵌入
在表格数据中,某些列可能包含数字数据,例如“年龄”,而 其他包含字符串值,如“sex”。数值数据可以直接输入模型(进行一些可选的预处理),但其他列需要转换为数字。由于其中的值对应不同的类别,所以我们常称这类变量为分类变量。第一类称为连续 变量。
连续变量和分类变量
连续变量是可以直接输入模型的数值数据,例如“年龄”,因为您可以直接对它们进行加法和乘法。分类变量包含许多离散级别,例如“电影 ID”,加法和乘法对其没有意义(即使它们存储为数字)。
2015 年底, Rossmann 销售竞赛在 Kaggle 上进行。参赛者获得了广泛的 德国各种商店的信息,并负责尝试预测几天的销售情况。目标是帮助公司正确管理库存并能够在不持有不必要库存的情况下满足需求。官方的训练集提供了很多关于店铺的信息。还允许参赛者使用额外的数据,只要这些数据是公开的并可供所有参与者使用。
其中一位金牌得主使用了深度学习,这是最先进的深度学习表格模型的最早已知示例之一。与其他金牌得主的方法相比,他们的方法涉及的基于领域知识的特征工程要少得多。论文 “分类变量的实体嵌入”描述了他们的方法。在本书网站上的一个仅在线章节中,我们展示了如何从头开始复制它并达到论文中显示的相同精度。在论文的摘要中,作者(Cheng Guo 和 Felix Bekhahn)说:
与单热编码相比,实体嵌入不仅减少了内存使用并加快了神经网络的速度,而且更重要的是,通过在嵌入空间中将相似值彼此靠近地映射,它揭示了分类变量的内在属性……[它]特别有用对于具有大量高基数特征的数据集,其他方法往往会过度拟合……由于实体嵌入定义了分类变量的距离度量,因此它可用于可视化分类数据和数据聚类。
在构建协同过滤模型时,我们已经注意到了所有这些要点。然而,我们可以清楚地看到,这些见解远远超出了协作过滤的范围。
该论文还指出(正如我们在前一章中讨论的那样)嵌入层完全等同于在每个单热编码输入层之后放置一个普通的线性层。作者使用图 9-1中的图表来展示这种等价性。请注意,“密集层”是一个与“线性层”含义相同的术语,one-hot 编码层代表输入。
洞察力很重要,因为我们已经知道如何训练线性层,所以这表明从架构和训练算法的角度来看,嵌入层只是另一层。我们在前一章的实践中也看到了这一点,当时我们构建了一个与下图完全一样的协同过滤神经网络。
正如我们分析电影评论的嵌入权重一样,作者 实体嵌入论文分析了其销售预测模型的嵌入权重。他们的发现非常惊人,并说明了他们的第二个关键见解:嵌入将分类变量转换为连续且有意义的输入。
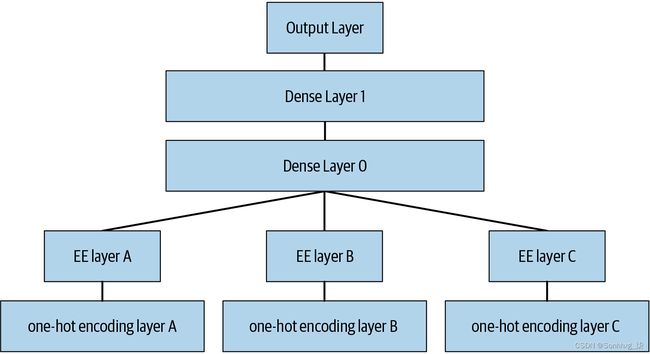
图 9-1。神经网络中的实体嵌入(由 Cheng Guo 和 Felix Berkhahn 提供)
图 9-2中的图像说明了这些想法。它们基于本文中使用的方法,以及我们添加的一些分析。
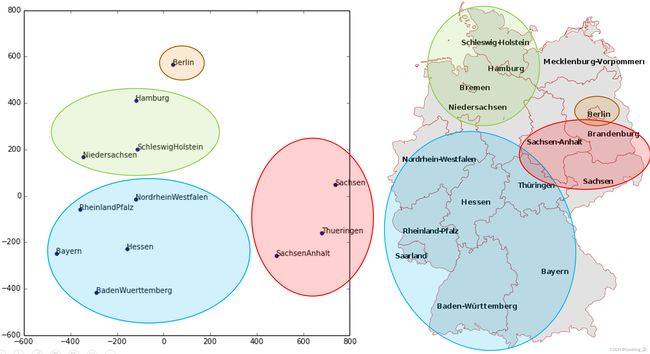
图 9-2。状态嵌入和地图(由 Cheng Guo 和 Felix Berkhahn 提供)
左边是State类别可能值的嵌入矩阵图。对于分类变量,我们将变量的可能值称为“水平”(或“类别”或“类”),因此这里一个水平是“柏林”,另一个是“汉堡”等。右边是德国地图。德国各州的实际物理位置不是所提供数据的一部分,但模型本身仅根据商店销售行为了解它们必须位于何处!
你还记得我们如何谈论嵌入之间的距离吗?这 该论文的作者根据商店之间的实际地理距离绘制了商店嵌入之间的距离(见图 9-3)。他们发现他们非常般配!
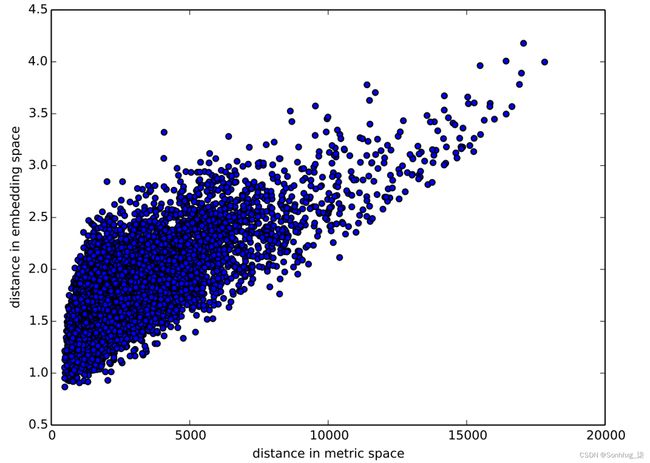
图 9-3。商店距离(由 Cheng Guo 和 Felix Berkhahn 提供)
我们甚至尝试绘制一周中的几天和一年中的几个月的嵌入,并发现日历上彼此靠近的日子和月份最终也作为嵌入结束, 如图 9-4所示。
在这两个示例中突出的是,我们为模型提供了关于离散实体(例如,德国各州或星期几)的基本分类数据,然后该模型学习了这些实体的嵌入,定义了它们之间的连续距离概念. 因为嵌入距离是根据数据中的真实模式学习的,所以该距离往往与我们的直觉相符。
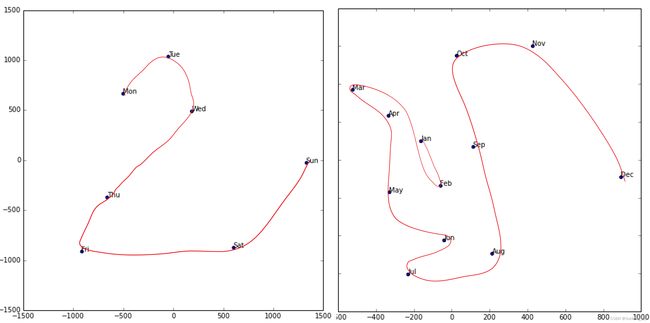
图 9-4。日期嵌入(由 Cheng Guo 和 Felix Berkhahn 提供)
此外,嵌入是连续的本身就很有价值,因为模型更善于理解连续变量。考虑到模型是由许多连续的参数权重和连续的激活值构建的,它们是通过梯度下降(一种用于寻找连续函数的最小值的学习算法)更新的,这并不奇怪。
另一个好处是我们可以以一种直接的方式将我们的连续嵌入值与真正连续的输入数据结合起来:我们 只需连接变量并将连接输入我们的第一个密集层。换句话说,原始分类数据在与原始连续输入数据交互之前由嵌入层转换。这就是 fastai、Guo 和 Berkhahn 处理包含连续变量和分类变量的表格模型的方式。
使用这种连接方法的一个例子是谷歌如何做它的 Google Play 上的推荐,如论文 “Wide & Deep Learning for Recommender Systems”中所述。图 9-5说明了这一点。
有趣的是,谷歌团队结合了我们的两种方法 在上一章中看到:点积(他们称之为叉积)和神经网络方法。
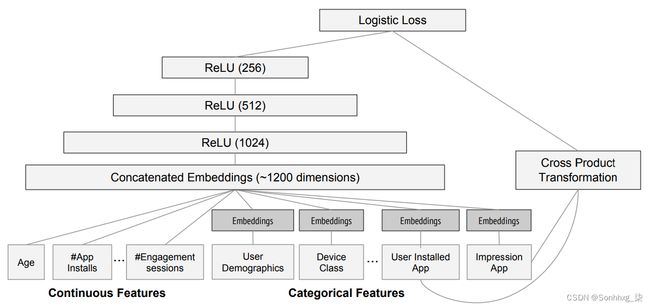
图 9-5。Google Play 推荐系统
让我们暂停一下。到目前为止,我们所有建模问题的解决方案都是训练深度学习模型。事实上,对于图像、声音、自然语言文本等复杂的非结构化数据,这是一个很好的经验法则。深度学习对于协同过滤也非常有效。但它并不总是分析表格数据的最佳起点。
超越深度学习
大多数机器学习课程都会抛出几十种算法 在你面前,对他们背后的数学进行简要的技术描述,也许还有一个玩具示例。您对展示的大量技术感到困惑,并且对如何应用它们知之甚少。
好消息是现代机器学习可以提炼成几个广泛适用的关键技术。最近的研究表明,绝大多数数据集都可以通过两种方法进行最佳建模:
-
决策树的集合(即随机森林和梯度提升机),主要用于结构化数据(例如您可能会在大多数公司的数据库表中找到)
-
使用 SGD(即浅层和/或深度学习)学习的多层神经网络,主要用于非结构化数据(如音频、图像和自然语言)
尽管深度学习几乎总是明显优于非结构化数据,但这两种方法往往会为多种结构化数据提供非常相似的结果。但是决策树的集合倾向于训练得更快,通常更容易解释,不需要特殊的 GPU 硬件来进行大规模推理,并且通常需要较少的 超参数调整。它们流行的时间也比深度学习长得多,因此围绕它们有一个更成熟的工具和文档生态系统。
最重要的是,对于决策树集成来说,解释表格数据模型的关键步骤要容易得多。有一些工具和方法可以回答相关问题,例如:数据集中的哪些列对您的预测最重要?它们与因变量有何关系?他们如何相互作用?哪些特定特征对于某些特定观察最重要?
因此,决策树集合是我们分析新表格数据集的第一种方法。
该指南的例外情况是数据集满足以下条件之一:
-
有一些非常重要的高基数分类变量(“基数”是指离散水平的数量 表示类别,因此高基数分类变量类似于邮政编码,可以有数千个可能的级别)。
-
有些列包含的数据最好用神经网络来理解,例如纯文本数据。
在实践中,当我们处理满足这些特殊条件的数据集时,我们总是同时尝试决策树集成和深度学习,看看哪个效果最好。在我们的协同过滤示例中,深度学习可能是一种有用的方法,因为我们至少有两个高基数分类变量:用户和电影。但在实践中,事情往往不那么一成不变,并且经常会混合使用高基数和低基数的分类变量和连续变量。
无论哪种方式,很明显我们需要将决策树集成添加到我们的建模工具箱中!
到目前为止,我们已经使用 PyTorch 和 fastai 完成了几乎所有繁重的工作。但是这些库主要是为进行大量矩阵乘法和导数的算法设计的(即深度学习之类的东西!)。决策树根本不依赖于这些操作,所以 PyTorch 用处不大。
相反,我们将主要依赖一个名为scikit-learn (也称为sklearn)的库。Scikit-learn 是一个流行的库,用于创建机器学习模型,使用未涵盖的方法 通过深度学习。此外,我们需要进行一些表格数据处理和查询,因此我们需要使用 Pandas 库。最后,我们还需要 NumPy,因为它是 sklearn 和 Pandas 都依赖的主要数字编程库。
我们没有时间在本书中深入探讨所有这些库,因此我们将只触及每个库的一些主要部分。为了进行更深入的讨论,我们强烈建议 Wes McKinney 的数据分析 Python (O'Reilly)。McKinney 是 Pandas 的创造者,所以您可以确定信息是准确的!
首先,让我们收集我们将使用的数据。
数据集
我们在本章中使用的数据集来自推土机蓝皮书 Kaggle 比赛,其描述如下:“比赛的目标是根据其用途、设备类型和配置来预测拍卖中特定重型设备的销售价格。数据来自拍卖结果发布,包括有关使用和设备配置的信息。”
这是一种非常常见的数据集和预测问题类型,类似于您在项目或工作场所中可能看到的问题。该数据集可在举办数据科学竞赛的网站 Kaggle 上下载。
Kaggle 比赛
Kaggle 是有抱负的数据科学家或任何人的绝佳资源 希望提高他们的机器学习技能。没有什么比获得动手实践和接收实时反馈更能帮助您提高技能了。
Kaggle 提供以下内容:
-
有趣的数据集
-
反馈你的表现
-
一个排行榜,看看什么是好的,什么是可能的,什么是最先进的
-
获奖选手分享有用的技巧和技巧的博客文章
到目前为止,我们所有的数据集都可以通过 fastai 的集成数据集系统下载。然而,我们将在本章中使用的数据集只能从 Kaggle 获得。因此,您需要在网站上注册,然后转到 比赛页面。在该页面上单击规则,然后单击我理解并接受。(虽然比赛已经结束,您不会参赛,但您仍然需要同意规则才能下载数据。)
下载 Kaggle 数据集的最简单方法是使用 Kaggle API。pip您可以通过在笔记本单元中使用和运行它来安装它:
!pip install kaggle您需要一个 API 密钥才能使用 Kaggle API;要获得一个,请在 Kaggle 网站上单击您的个人资料图片,然后选择“我的帐户”;然后单击创建新 API 令牌。这会将名为kaggle.json的文件保存到您的 PC。您需要在 GPU 服务器上复制此密钥。为此,请打开您下载的文件,复制内容,并将它们粘贴到与本章相关的笔记本中的以下单元格中的单引号内(例如,):creds = '{"username":"xxx","key":"xxx"}'
creds = ''然后执行这个单元格(这只需要运行一次):
cred_path = Path('~/.kaggle/kaggle.json').expanduser()
if not cred_path.exists():
cred_path.parent.mkdir(exist_ok=True)
cred_path.write(creds)
cred_path.chmod(0o600)现在你可以从 Kaggle 下载数据集了!选择将数据集下载到的路径:
path = URLs.path('bluebook')
pathPath('/home/sgugger/.fastai/archive/bluebook')
并使用 Kaggle API 将数据集下载到该路径并解压缩:
if not path.exists():
path.mkdir()
api.competition_download_cli('bluebook-for-bulldozers', path=path)
file_extract(path/'bluebook-for-bulldozers.zip')
path.ls(file_type='text')(#7) [Path('Valid.csv'),Path('Machine_Appendix.csv'),Path('ValidSolution.csv'),P
> ath('TrainAndValid.csv'),Path('random_forest_benchmark_test.csv'),Path('Test.
> csv'),Path('median_benchmark.csv')]
现在我们已经下载了我们的数据集,让我们来看看吧!
看数据
Kaggle 提供有关我们数据集某些字段的信息。Data页面解释train.csv中的关键字段如下:
SalesID
销售的唯一标识符。
MachineID
机器的唯一标识符。一台机器可以多次销售。
saleprice
机器在拍卖会上的售价(仅在train.csv中提供)。
saledate
销售日期。
在任何类型的数据科学工作中,直接查看数据以确保您了解格式、如何 它被存储,它持有什么类型的值,等等。即使你已经阅读了数据的描述,实际数据也可能不是你所期望的。我们将从将训练集读入 Pandas DataFrame 开始。low_memory=False通常,除非 Pandas 实际上耗尽内存并返回错误,否则最好也指定。默认情况下,该low_memory参数True 告诉 Pandas 一次只查看几行数据,以确定每一列中的数据类型。这意味着 Pandas 最终可能会对不同的行使用不同的数据类型,这通常会导致数据处理错误或以后出现模型训练问题。
让我们加载数据并查看列:
df = pd.read_csv(path/'TrainAndValid.csv', low_memory=False)df.columnsIndex(['SalesID', 'SalePrice', 'MachineID', 'ModelID', 'datasource',
'auctioneerID', 'YearMade', 'MachineHoursCurrentMeter', 'UsageBand',
'saledate', 'fiModelDesc', 'fiBaseModel', 'fiSecondaryDesc',
'fiModelSeries', 'fiModelDescriptor', 'ProductSize',
'fiProductClassDesc', 'state', 'ProductGroup', 'ProductGroupDesc',
'Drive_System', 'Enclosure', 'Forks', 'Pad_Type', 'Ride_Control',
'Stick', 'Transmission', 'Turbocharged', 'Blade_Extension',
'Blade_Width', 'Enclosure_Type', 'Engine_Horsepower', 'Hydraulics',
'Pushblock', 'Ripper', 'Scarifier', 'Tip_Control', 'Tire_Size',
'Coupler', 'Coupler_System', 'Grouser_Tracks', 'Hydraulics_Flow',
'Track_Type', 'Undercarriage_Pad_Width', 'Stick_Length', 'Thumb',
'Pattern_Changer', 'Grouser_Type', 'Backhoe_Mounting', 'Blade_Type',
'Travel_Controls', 'Differential_Type', 'Steering_Controls'],
dtype='object')
有很多专栏供我们查看!尝试查看数据集以了解每个数据集包含何种信息。我们很快就会看到如何在最有趣的位上“归零”。
此时,下一步是处理序数列。这是指包含字符串或类似内容的列,但这些字符串所在的列 有一个自然的顺序。例如,这里是水平 ProductSize:
df['ProductSize'].unique()array([nan, 'Medium', 'Small', 'Large / Medium', 'Mini', 'Large', 'Compact'], > dtype=object)
我们可以像这样告诉 Pandas 这些级别的合适排序:
sizes = 'Large','Large / Medium','Medium','Small','Mini','Compact'df['ProductSize'] = df['ProductSize'].astype('category')
df['ProductSize'].cat.set_categories(sizes, ordered=True, inplace=True)最重要的数据列是因变量—— 我们要预测的一个。回想一下,模型的指标是一个反映预测好坏的函数。重要的是要注意项目正在使用什么指标。通常,选择指标是项目设置的重要部分。在许多情况下,选择一个好的指标需要的不仅仅是选择一个已经存在的变量。它更像是一个设计过程。您应该仔细考虑哪个指标或指标集实际衡量对您重要的模型质量概念。如果没有变量表示该指标,您应该查看是否可以从可用变量构建指标。
然而,在这种情况下,Kaggle 告诉我们使用什么指标:实际拍卖价格和预测拍卖价格之间的均方根对数误差 (RMLSE)。 我们只需要做少量处理就可以使用它:我们获取价格的对数,以便该m_rmse值的 将给我们最终需要的东西:
dep_var = 'SalePrice'df[dep_var] = np.log(df[dep_var])我们现在准备探索我们的第一个表格数据机器学习算法:决策树。
决策树
顾名思义,决策树集成依赖于决策树。 让我们从这里开始吧!决策树会询问一系列关于数据的二元(是或否)问题。在每个问题之后,树的该部分的数据被分为是和否分支,如图 9-6所示。在一个或多个问题之后,可以根据所有先前的答案进行预测,或者需要另一个问题。
这一系列问题现在是一个过程,用于获取任何数据项,无论是来自训练集中的项目还是新数据,并将该项目分配给一个组。即,在提出和回答问题之后,我们可以说该项目与所有其他训练数据项目属于同一组,这些训练数据项目产生了相同的问题答案集。但这有什么好处呢?我们模型的目标是预测项目的值,而不是将它们分配到训练数据集中的组中。价值在于我们现在可以为这些组中的每一个分配一个预测值——对于回归,我们采用组中项目的目标均值。

图 9-6。决策树的一个例子
让我们考虑一下如何找到要问的正确问题。当然,我们不想自己创造所有这些问题——这就是计算机的用途!这 训练决策树的基本步骤可以很容易地写下来:
-
依次循环遍历数据集的每一列。
-
对于每一列,依次遍历该列的每个可能级别。
-
尝试根据数据是否大于或小于该值(或者如果它是分类变量,则根据它们是否等于或不等于该分类变量的水平)将数据分成两组。
-
找出这两组中每一组的平均售价,看看它与该组中每件设备的实际售价有多接近。将其视为一个非常简单的“模型”,其中我们的预测只是商品组的平均销售价格。
-
在遍历所有列和每个列的所有可能级别后,选择使用该简单模型给出最佳预测的分割点。
-
基于这个选定的拆分,我们现在有两组数据。将每个组视为一个单独的数据集,并通过返回每个组的步骤 1 为每个组找到最佳拆分。
-
递归地继续这个过程,直到你达到每个组的一些停止标准——例如,当它只有 20 个项目时停止进一步拆分一个组。
虽然这是一个很容易自己实现的算法(这样做是一个很好的练习),但我们可以通过使用 sklearn 中内置的实现来节省一些时间。
然而,首先,我们需要做一些数据准备。
这是一个值得思考的富有成效的问题。如果您认为定义决策树的过程本质上是选择一个关于变量的拆分问题序列,您可能会问自己,我们怎么知道这个过程选择了正确的序列?规则是选择产生最佳拆分的拆分问题(即,最准确地将项目分为两个不同的类别),然后将相同的规则应用于拆分产生的组,依此类推。这在计算机科学中被称为“贪心”方法。您能想象这样一种场景,在这种情况下,提出一个“不那么强大”的拆分问题可以更好地拆分(或者我应该说是沿着后备箱!)并带来更好的整体结果吗?
处理日期
我们需要做的第一个数据准备是丰富我们的 日期的表示。我们刚刚描述的决策树的基本基础是二分法——将一组分成两部分。我们查看序数变量并根据变量的值是否大于(或低于)阈值来划分数据集,我们查看分类变量并根据变量的水平是否为特定水平来划分数据集。因此,该算法有一种基于序数和分类数据划分数据集的方法。
但这如何适用于常见的数据类型,即日期?您可能希望将日期视为序数值,因为说一个日期大于另一个日期是有意义的。然而,日期与大多数序数值略有不同,因为某些日期在性质上不同于其他日期,而这通常与我们正在建模的系统相关。
为了帮助我们的算法智能地处理日期,我们希望我们的模型知道的不仅仅是一个日期比另一个日期更近还是更不近。我们可能希望我们的模型根据该日期是星期几、某天是否是假期、它是几月等等来做出决定。为此,我们将每个日期列替换为一组日期元数据列,例如假日、星期几和月份。这些列提供了我们认为有用的分类数据。
fastai 带有一个函数可以为我们做这件事——我们只需要传递一个包含日期的列名:
df = add_datepart(df, 'saledate')当我们在那里时,让我们对测试集做同样的事情:
df_test = pd.read_csv(path/'Test.csv', low_memory=False)
df_test = add_datepart(df_test, 'saledate')我们可以看到我们的 DataFrame 中现在有很多新列:
' '.join(o for o in df.columns if o.startswith('sale'))'saleYear saleMonth saleWeek saleDay saleDayofweek saleDayofyear
> saleIs_month_end saleIs_month_start saleIs_quarter_end saleIs_quarter_start
> saleIs_year_end saleIs_year_start saleElapsed'
这是一个很好的第一步,但我们需要做更多的清洁工作。为此,我们将使用名为TabularPandas和 的 fastai 对象TabularProc。
使用 TabularPandas 和 TabularProc
第二个准备过程是确保我们可以处理 字符串和丢失的数据。开箱即用,sklearn 也做不到。相反,我们将使用 fastai 的类TabularPandas,它包装了一个 Pandas DataFrame 并提供了一些便利。要填充 a TabularPandas,我们将使用两个TabularProcsCategorify和 FillMissing。ATabularProc就像一个普通的Transform,除了以下几点:
-
在适当地修改对象后,它返回传递给它的完全相同的对象。
-
它在首次传入数据时运行一次转换,而不是在访问数据时延迟运行。
Categorify是TabularProc用数字分类列替换列的。FillMissing是一个TabularProc用列的中值替换缺失值,并创建一个新的布尔列,该列为缺失值的True任何行设置为。您将使用的几乎每个表格数据集都需要这两个转换,因此这是您数据处理的一个很好的起点:
procs = [Categorify, FillMissing]TabularPandas还将处理将数据集拆分为训练和验证集。但是,我们需要非常小心我们的验证集。我们希望将其设计成Kaggle 用来评判比赛的测试集。
回想一下第 1 章中讨论的验证集和测试集之间的区别。验证集是我们从训练中保留下来的数据,以确保训练过程不会过度拟合训练数据。测试集是我们自己隐藏得更深的数据,以确保我们在 探索各种模型架构和超参数时不会过度拟合验证数据。
我们看不到测试集。但我们确实希望定义我们的验证数据,使其与训练数据具有与测试集相同的关系。
在某些情况下,只需随机选择数据点的一个子集即可。这不是其中一种情况,因为它是一个时间序列。
如果您查看测试集中表示的日期范围,您会发现它涵盖了从 2012 年 5 月开始的六个月时间段,该时间段晚于训练集中的任何日期。这是一个很好的设计,因为比赛主办方希望确保模型能够预测未来。但这意味着如果我们要有一个有用的验证集,我们也希望验证集在时间上晚于训练集。Kaggle 训练数据在 2012 年 4 月结束,因此我们将定义一个更窄的训练数据集,它只包含 2011 年 11 月之前的 Kaggle 训练数据,我们将定义一个包含 2011 年 11 月之后数据的验证集。
为此,我们使用np.where,一个有用的函数,它返回(作为元组的第一个元素)所有True值的索引:
cond = (df.saleYear<2011) | (df.saleMonth<10)
train_idx = np.where( cond)[0]
valid_idx = np.where(~cond)[0]
splits = (list(train_idx),list(valid_idx))TabularPandas需要被告知哪些列是连续的,哪些是分类的。我们可以使用辅助函数自动处理cont_cat_split:
cont,cat = cont_cat_split(df, 1, dep_var=dep_var)to = TabularPandas(df, procs, cat, cont, y_names=dep_var, splits=splits)A 的TabularPandas行为很像 fastaiDatasets对象,包括提供train和valid属性:
len(to.train),len(to.valid)(404710, 7988)
我们可以看到数据仍然显示为类别的字符串(我们在这里只显示几列,因为整个表格太大而无法放在一个页面上):
to.show(3)| state | ProductGroup | Drive_System | Enclosure | SalePrice | |
|---|---|---|---|---|---|
| 0 | Alabama | WL | #na# | EROPS w AC | 11.097410 |
| 1 | North Carolina | WL | #na# | EROPS w AC | 10.950807 |
| 2 | New York | SSL | #na# | OROPS | 9.210340 |
但是,底层项目都是数字的:
to.items.head(3)| state | ProductGroup | Drive_System | Enclosure | |
|---|---|---|---|---|
| 0 | 1 | 6 | 0 | 3 |
| 1 | 33 | 6 | 0 | 3 |
| 2 | 32 | 3 | 0 | 6 |
将分类列转换为数字只需将每个唯一级别替换为数字即可。与级别关联的数字在列中显示时是连续选择的,因此转换后分类列中的数字没有特殊含义。例外情况是,如果您首先将列转换为 Pandas 有序类别(就像我们之前所做的ProductSize那样),在这种情况下,将使用您选择的顺序。我们可以通过查看classes属性来查看映射:
to.classes['ProductSize'](#7) ['#na#','Large','Large / Medium','Medium','Small','Mini','Compact']
由于处理数据到这一点需要一分钟左右的时间,我们应该保存它——这样,以后我们可以继续我们的工作 这里无需重新运行前面的步骤。fastai 提供了save 一种使用 Python 的pickle系统保存几乎任何 Python 对象的方法:
(path/'to.pkl').save(to)要稍后再读回,您可以输入:
to = (path/'to.pkl').load()现在所有这些预处理都已完成,我们已准备好创建决策树。
创建决策树
首先,我们定义自变量和因变量:
xs,y = to.train.xs,to.train.y
valid_xs,valid_y = to.valid.xs,to.valid.y现在我们的数据都是数字的,并且没有缺失值,我们可以创建一个决策树:
m = DecisionTreeRegressor(max_leaf_nodes=4)
m.fit(xs, y);为了简单起见,我们告诉 sklearn 只创建四个叶节点。要查看它学到了什么,我们可以显示树:
draw_tree(m, xs, size=7, leaves_parallel=True, precision=2)
理解这张图是理解决策树的最好方法之一,所以我们将从顶部开始,逐步解释每个部分。
当所有数据都在一个组中时,顶部节点表示完成任何拆分之前的初始模型。这是最简单的模型。它是问零个问题的结果,并且总是预测值是整个数据集的平均值。在本例中,我们可以看到它预测销售价格的对数值为 10.1。它给出的均方误差为 0.48。其平方根为 0.69。(请记住,除非您看到m_rmse, 或均方根误差,你看的是开平方前的值,所以它只是差的平方的平均值。)我们还可以看到这一组有 404,710 条拍卖记录——这就是我们训练的总规模放。此处显示的最后一条信息是找到的最佳拆分的决策标准,即基于 coupler_system列进行拆分。
向左下方移动,该节点向我们展示了 360,847 条coupler_system小于 0.5 的设备拍卖记录。该组因变量的平均值为 10.21。从初始模型向下并向右移动会将我们带到coupler_system大于 0.5 的记录。
底行包含我们的叶节点:没有答案的节点,因为没有更多的问题需要回答。此行的最右侧是包含coupler_system大于 0.5 的记录的节点。平均值为 9.21,因此我们可以看到决策树算法确实找到了将高价值拍卖结果与低价值拍卖结果分开的单一二元决策。仅询问 coupler_system预测的平均值为 9.21 与 10.1。
在第一个决策点之后返回到顶部节点,我们可以看到基于询问是否YearMade小于或等于 1991.5,已经进行了第二个二元决策拆分。对于符合此条件的组(请记住,这是基于 coupler_system和的两个二元决策YearMade),平均值为 9.97,并且该组中有 155,724 条拍卖记录。对于该判定为假的拍卖组,平均值为 10.4,共有 205,123 条记录。因此,我们可以再次看到决策树算法成功地将我们较昂贵的拍卖记录分成了价值显着不同的两组。
我们可以使用 Terence Parr 强大的dtreeviz 库显示相同的信息:
samp_idx = np.random.permutation(len(y))[:500]
dtreeviz(m, xs.iloc[samp_idx], y.iloc[samp_idx], xs.columns, dep_var,
fontname='DejaVu Sans', scale=1.6, label_fontsize=10,
orientation='LR') 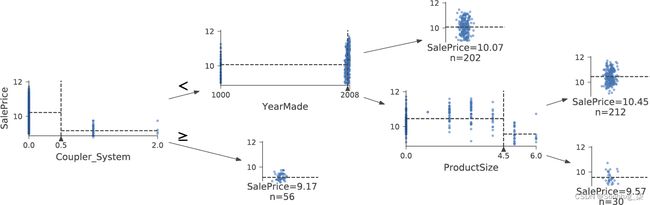
这显示了每个分割点的数据分布图表。我们可以清楚地看到我们的 YearMade数据有问题:显然有 1000 年制造的推土机!据推测,这只是一个缺失值代码(该值不会以其他方式出现在数据中,并且在缺失值的情况下用作占位符)。出于建模目的,1000 很好,但如您所见,这个离群值使我们感兴趣的值的可视化变得更加困难。所以,让我们用 1950 替换它:
xs.loc[xs['YearMade']<1900, 'YearMade'] = 1950
valid_xs.loc[valid_xs['YearMade']<1900, 'YearMade'] = 1950这种变化使树可视化中的分裂更加清晰,即使它不会以任何显着方式改变模型的结果。这是一个很好的例子,说明决策树对数据问题的弹性如何!
m = DecisionTreeRegressor(max_leaf_nodes=4).fit(xs, y)
dtreeviz(m, xs.iloc[samp_idx], y.iloc[samp_idx], xs.columns, dep_var,
fontname='DejaVu Sans', scale=1.6, label_fontsize=10,
orientation='LR')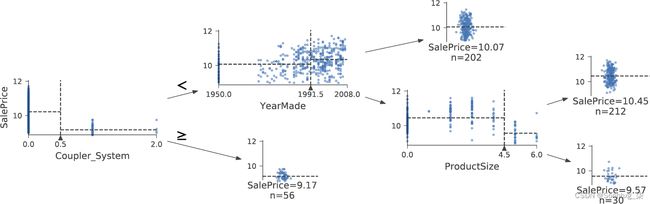
现在让我们用决策树算法构建一个更大的 树。在这里,我们没有传递任何停止条件,例如 max_leaf_nodes:
m = DecisionTreeRegressor()
m.fit(xs, y);我们将创建一个小函数来检查均值根 我们模型 ( m_rmse) 的平方误差,因为这是评判比赛的方式:
def r_mse(pred,y): return round(math.sqrt(((pred-y)**2).mean()), 6)
def m_rmse(m, xs, y): return r_mse(m.predict(xs), y)m_rmse(m, xs, y)0.0
那么,我们的模型是完美的,对吧?没那么快……记住,我们真的需要 检查验证集,以确保我们没有过度拟合:
m_rmse(m, valid_xs, valid_y)0.337727
哎呀——看起来我们可能过度拟合了。原因如下:
m.get_n_leaves(), len(xs)(340909, 404710)
我们的叶节点几乎和数据点一样多!那 似乎有点过于热情了。实际上,sklearn 的默认设置允许它继续拆分节点,直到每个叶节点中只有一项。让我们更改停止规则以告诉 sklearn 确保每个叶节点包含至少 25 个拍卖记录:
m = DecisionTreeRegressor(min_samples_leaf=25)
m.fit(to.train.xs, to.train.y)
m_rmse(m, xs, y), m_rmse(m, valid_xs, valid_y)(0.248562, 0.32368)
这样看起来好多了。让我们再次检查叶子的数量:
m.get_n_leaves()12397
合理多了!
这是我对叶节点多于数据项的过度拟合决策树的直觉。考虑游戏二十个问题。在那个游戏中,选择者偷偷想象一个物体(比如,“我们的电视机”),然后猜测者可以提出 20 个是或否的问题来尝试猜测物体是什么(比如“它比面包盒大吗?” ). 猜测者并不是要预测一个数值,而只是要从所有可想象的对象集合中识别出一个特定的对象。当您的决策树的叶子数多于域中可能的对象数时,它本质上是一个训练有素的猜测者。它已经了解了识别训练集中特定数据项所需的问题序列,并且它仅通过描述该项目的值来“预测”。这是一种记忆训练集的方式——即过度拟合。
构建决策树是创建数据模型的好方法。它非常灵活,因为它可以清楚地处理变量之间的非线性关系和相互作用。但我们可以看到,在它的泛化能力(我们可以通过创建小树来实现)和它在训练集上的准确性(我们可以通过使用大树来实现)之间存在根本的折衷。
那么我们如何才能两全其美呢?我们将在处理完一个重要的缺失细节后立即向您展示:如何处理分类变量。
分类变量
在上一章中,当使用深度学习网络时,我们通过对它们进行单热编码并将它们提供给嵌入层来处理分类变量。 嵌入层帮助模型发现这些变量不同级别的含义(分类变量的级别没有内在含义,除非我们使用 Pandas 手动指定排序)。在决策树中,我们没有嵌入层——那么这些未经处理的分类变量如何在决策树中做任何有用的事情呢?例如,如何使用产品代码之类的东西?
简短的回答是:它就是有效!考虑一种情况,其中一种产品代码在拍卖中的价格远高于其他任何一种。在那种情况下,任何二进制拆分都会导致一个产品代码属于某个组,并且该组将比另一组更昂贵。因此,我们的简单决策树构建算法将选择该拆分。稍后,在训练期间,该算法将能够进一步拆分包含昂贵产品代码的子组,并且随着时间的推移,树将锁定那个昂贵的产品。
也可以使用单热编码将单个分类变量替换为多个单热编码列,其中每一列 表示变量的可能水平。Pandas 有一种get_dummies 方法可以做到这一点。
但是,实际上并没有任何证据表明这种方法可以改善最终结果。因此,我们通常会尽可能避免使用它,因为它最终会使您的数据集更难使用。2019年,这个问题Marvin Wright 和 Inke König 在论文“Splitting on Categorical Predictors in Random Forests”中进行了探讨:
名义预测变量的标准方法是考虑k个预测变量类别的所有 2 k − 1 − 1 个 2-分区。然而,这种指数关系会产生大量需要评估的潜在拆分,增加了计算复杂度并限制了大多数实现中可能的类别数量。对于二元分类和回归,结果表明,对每个拆分中的预测变量类别进行排序会导致与标准方法完全相同的拆分。这降低了计算复杂性,因为对于具有k个类别的标称预测变量,只需考虑k − 1 个拆分。
现在您了解了决策树的工作原理,是时候采用两全其美的解决方案了:随机森林。
随机森林
1994 年,伯克利教授 Leo Breiman 在退休一年后, 发表了一份名为 “Bagging Predictors”的小型技术报告,结果证明这是现代机器学习中最有影响力的思想之一。报道开始:
Bagging 预测器是一种生成多个版本的预测器并使用它们来获得聚合预测器的方法。版本的聚合平均值……多个版本是通过对学习集进行引导复制并将其用作新的学习集而形成的。测试……表明套袋可以显着提高准确性。关键因素是预测方法的不稳定性。如果扰动学习集会导致构建的预测器发生显着变化,那么装袋可以提高准确性。
这是 Breiman 提议的程序:
-
随机选择数据行的一个子集(即“学习集的引导复制”)。
-
使用此子集训练模型。
-
保存该模型,然后多次返回步骤 1。
-
这将为您提供多个训练有素的模型。要进行预测,请使用所有模型进行预测,然后取每个模型预测的平均值。
此过程称为装袋。它基于一个深刻而重要的见解:虽然每个在数据子集上训练的模型都会比在完整数据集上训练的模型产生更多的错误,但这些错误不会相互关联。不同的模型会产生不同的错误。因此,这些错误的平均值为零!因此,如果我们取所有模型预测的平均值,我们应该得到一个越来越接近正确答案的预测,我们拥有的模型越多。这是一个非凡的结果——这意味着我们可以通过多次训练来提高几乎任何类型的机器学习算法的准确性,每次训练都在不同的随机数据子集上进行,并对预测进行平均。
2001 年,Breiman 继续证明这种构建模型的方法在应用于决策树构建算法时特别强大。他走得更远,不仅仅是为每个模型的训练随机选择行,而且在选择每个决策树中的每个拆分时,还从列的子集中随机选择。他将这种方法称为随机森林。今天,它可能是使用最广泛且实际上最重要的机器学习方法。
本质上,随机森林是一种对大量决策树的预测进行平均的模型,这些决策树是通过随机改变各种参数生成的,这些参数指定了使用什么数据来训练树和其他树参数。Bagging 是一种 特殊的集成方法 ,或将多个模型的结果组合在一起。为了看看它在实践中是如何工作的,让我们开始创建我们自己的随机森林吧!
创建随机森林
我们可以像创建决策树一样创建随机森林,除了现在我们还指定了指示有多少个参数 树木应该在森林中,我们应该如何对数据项(行)进行子集化,以及我们应该如何对字段(列)进行子集化。
在下面的函数定义中,n_estimators定义了我们想要的树的数量,max_samples定义了训练每棵树要采样多少行,max_features定义了在每个分割点采样多少列(这里0.5的意思是“取总列数的一半”)。我们还可以指定何时停止分裂树节点,通过包含min_samples_leaf我们在上一节中使用的相同参数来有效地限制树的深度。最后,我们通过n_jobs=-1参数告诉 sklearn 使用我们所有的 CPU 并行构建树。通过为此创建一个小函数,我们可以更快地尝试本章其余部分的变体:
def rf(xs, y, n_estimators=40, max_samples=200_000,
max_features=0.5, min_samples_leaf=5, **kwargs):
return RandomForestRegressor(n_jobs=-1, n_estimators=n_estimators,
max_samples=max_samples, max_features=max_features,
min_samples_leaf=min_samples_leaf, oob_score=True).fit(xs, y)m = rf(xs, y);我们的验证 RMSE 现在比我们上次生成的结果有了很大改进,DecisionTreeRegressor它只使用所有可用数据制作了一棵树:
m_rmse(m, xs, y), m_rmse(m, valid_xs, valid_y)(0.170896, 0.233502)
随机森林最重要的特性之一是它们 对超参数的选择不是很敏感,例如 max_features. 您可以设置n_estimators一个尽可能高的数字,因为您有时间进行训练——您拥有的树越多,模型就越准确。 max_samples通常可以保留其默认值,除非您有超过 200,000 个数据点,在这种情况下,将其设置为 200,000 将使它训练得更快,而对准确性的影响很小。尽管 sklearn 的默认设置也很好,但两者都运行良好max_features=0.5。 min_samples_leaf=4
sklearn 文档 举例说明不同max_features选择的影响,树的数量不断增加。在绘图中,蓝色绘图线使用的特征最少,而绿线使用的特征最多(它使用了所有特征)。正如您在图 9-7中所看到的,具有最低误差的模型是使用特征子集但具有更多树的结果。
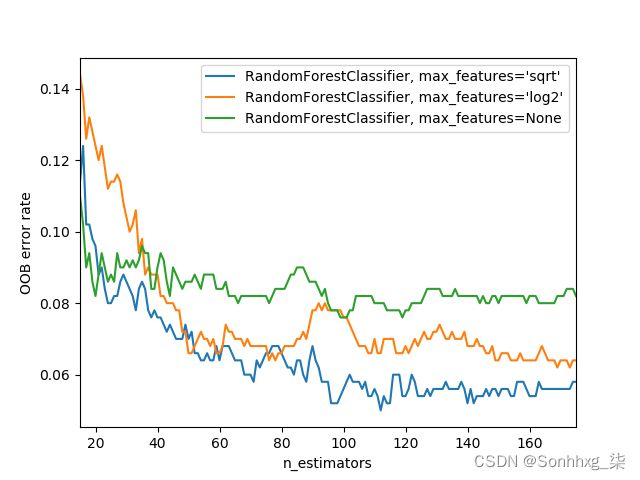
图 9-7。基于最大特征和树数的误差(来源:https ://oreil.ly/E0Och )
要查看 的影响n_estimators,让我们从森林中的每棵树中获取预测(这些在 estimators_属性中):
preds = np.stack([t.predict(valid_xs) for t in m.estimators_]) 如您所见,preds.mean(0)给出与我们的随机森林相同的结果:
plt.plot([r_mse(preds[:i+1].mean(0), valid_y) for i in range(40)]);0.233502
让我们看看当我们添加越来越多的树时 RMSE 会发生什么。作为 你可以看到,在大约 30 棵树之后,改进水平下降了很多:
plt.plot([r_mse(preds[:i+1].mean(0), valid_y) for i in range(40)]);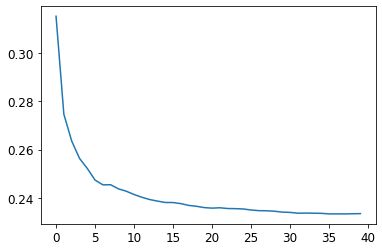
我们的验证集的性能比我们的训练集差。但那是因为 我们过度拟合了,还是因为验证集涵盖了不同的时间段,或者两者兼而有之?根据我们所看到的现有信息,我们无法判断。然而,随机森林有一个非常聪明的技巧,称为袋外(OOB) 错误,可以帮助我们解决这个问题(以及更多!)。
包外错误
回想一下,在随机森林中,每棵树都在训练数据的不同子集上进行训练。OOB 错误是一种测量训练数据集中预测错误的方法,方法是仅在该行未包含在训练中的情况下将其包含在行的错误树的计算中。这使我们能够查看模型是否过度拟合,而无需单独的验证集。
我对此的直觉是,由于每棵树都是用不同的随机选择的行子集训练的,袋外错误有点像想象每棵树因此也有自己的验证集。该验证集只是没有为该树的训练选择的行。
这在我们只有少量训练数据的情况下特别有用,因为它允许我们查看我们的模型是否在不删除项目以创建验证集的情况下进行概括。OOB 预测在oob_prediction_属性中可用。请注意,我们将它们与训练标签进行比较,因为这是使用训练集在树上计算的:
r_mse(m.oob_prediction_, y)0.210686
我们可以看到我们的 OOB 错误比我们的验证集错误低得多。这意味着 除了正常的泛化错误之外,还有其他原因导致了该错误。我们将在本章稍后部分讨论其原因。
这是解释我们模型预测的一种方式——让我们现在关注更多的预测。
模型解释
对于表格数据,模型解释尤为重要。对于给定的模型,我们最有可能感兴趣的是以下内容:
-
我们对使用特定数据行的预测有多大信心?
-
对于特定行数据的预测,最重要的因素是什么,它们如何影响该预测?
-
哪些列是最强的预测变量,我们可以忽略哪些?
-
出于预测的目的,哪些列彼此有效冗余 ?
-
当我们改变这些列时,预测如何变化?
正如我们将看到的,随机森林特别适合回答这些问题。让我们从第一个开始吧!
预测置信度的树方差
我们看到了模型如何对单个树的预测进行平均以获得 总体预测——即价值的估计。但是我们如何知道估计的置信度呢?一种简单的方法是使用树间预测的标准差,而不仅仅是均值。这告诉我们预测的相对置信度。一般来说,与树给出非常不同的结果(更高的标准差)的行相比,与它们更一致(更低的标准差)的情况相比,我们希望更加谨慎地使用结果。
在“创建随机森林”中,我们了解了如何对验证集进行预测,使用 Python 列表理解对森林中的每棵树执行此操作:
preds = np.stack([t.predict(valid_xs) for t in m.estimators_])preds.shape(40, 7988)
现在我们对验证集中的每棵树和每次拍卖都有一个预测(40 棵树和 7,988 次拍卖)。
使用它,我们可以获得每次拍卖对所有树的预测的标准偏差:
preds_std = preds.std(0)以下是前五次拍卖预测的标准差——即验证集的前五行:
preds_std[:5]array([0.21529149, 0.10351274, 0.08901878, 0.28374773, 0.11977206])
如您所见,预测的置信度差异很大。对于某些拍卖,标准偏差较低,因为树木一致。对于其他人来说,它更高,因为树木不同意。这是在生产环境中有用的信息;例如,如果您使用此模型来决定在拍卖会上对哪些物品进行出价,则低置信度预测可能会导致您在出价之前更仔细地查看物品。
特征重要性
通常仅仅知道一个模型可以 做出准确的预测——我们还想知道它是如何做出预测的。特征重要性给了我们这种洞察力。feature_importances_我们可以通过查看属性直接从 sklearn 的随机森林中获取这些。这是一个简单的函数,我们可以使用它来将它们弹出到 DataFrame 中并对它们进行排序:
def rf_feat_importance(m, df):
return pd.DataFrame({'cols':df.columns, 'imp':m.feature_importances_}
).sort_values('imp', ascending=False)我们模型的特征重要性表明,前几个最重要的列的重要性分数比其余列高得多,并且(毫不奇怪)YearMade位于ProductSize列表的顶部:
fi = rf_feat_importance(m, xs)
fi[:10]| cols | imp | |
|---|---|---|
| 69 | YearMade | 0.182890 |
| 6 | ProductSize | 0.127268 |
| 30 | Coupler_System | 0.117698 |
| 7 | fiProductClassDesc | 0.069939 |
| 66 | ModelID | 0.057263 |
| 77 | saleElapsed | 0.050113 |
| 32 | Hydraulics_Flow | 0.047091 |
| 3 | fiSecondaryDesc | 0.041225 |
| 31 | Grouser_Tracks | 0.031988 |
| 1 | fiModelDesc | 0.031838 |
特征重要性图更清楚地显示了相对重要性:
def plot_fi(fi):
return fi.plot('cols', 'imp', 'barh', figsize=(12,7), legend=False)
plot_fi(fi[:30]);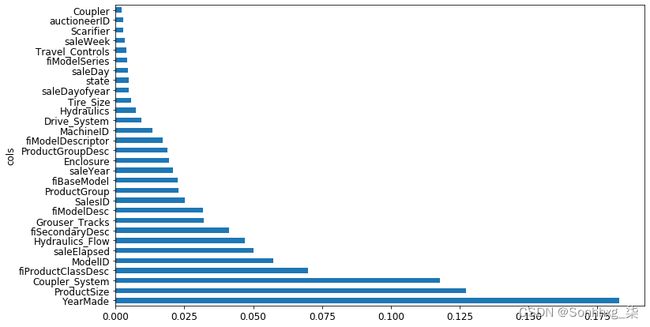
这些重要性的计算方式非常简单而优雅。特征重要性算法循环遍历每棵树,然后递归地探索每个分支。在每个分支,它会查看该拆分使用了哪些功能,以及该拆分后模型改进了多少。改进(由该组中的行数加权)被添加到该功能的重要性分数。这是所有树的所有分支的总和,最后将分数归一化,使它们加起来为 1。
删除低重要性变量
似乎我们可以通过以下方式使用列的子集 去除低重要性的变量,仍然可以得到很好的结果。让我们尝试只保留特征重要性大于 0.005 的那些:
to_keep = fi[fi.imp>0.005].cols
len(to_keep)21
我们可以仅使用列的这个子集来重新训练我们的模型:
xs_imp = xs[to_keep]
valid_xs_imp = valid_xs[to_keep]m = rf(xs_imp, y)结果如下:
m_rmse(m, xs_imp, y), m_rmse(m, valid_xs_imp, valid_y)(0.181208, 0.232323)
我们的准确性大致相同,但我们要研究的列要少得多:
len(xs.columns), len(xs_imp.columns)(78, 21)
我们发现,改进模型的第一步通常是简化它——78 列太多了,我们无法深入研究它们!此外,在实践中,通常更简单、更可解释的模型更容易推出和维护。
这也使我们的特征重要性图更易于解释。我们再来看一下:
plot_fi(rf_feat_importance(m, xs_imp));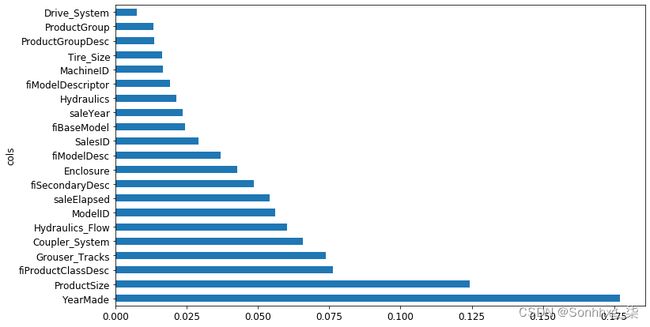
使这更难解释的一件事是似乎有一些变量具有非常相似的含义:例如,ProductGroup 和ProductGroupDesc。让我们尝试删除任何冗余功能。
删除冗余功能
让我们从这个开始:
cluster_columns(xs_imp)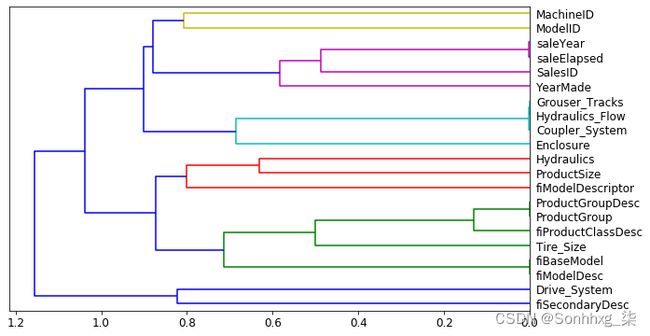
在此图表中,最相似的列对是早期合并在一起的列,远离左侧树的“根”。不出所料,字段 ProductGroup和ProductGroupDesc很早就被合并了,还有 saleYear和saleElapsed,fiModelDesc以及 fiBaseModel。这些可能是如此密切相关,以至于它们实际上是彼此的同义词。
最相似的对是通过计算等级相关性找到的,这意味着所有的值都被替换为它们的值。 排名(列内的第一、第二、第三等),然后计算相关性。(不过请随意跳过这个小细节,因为它不会在书中再次出现!)
让我们尝试删除其中一些密切相关的特征,看看是否可以在不影响准确性的情况下简化模型。首先,我们创建一个快速训练随机森林并返回 OOB 分数的函数,使用较低max_samples和较高的 min_samples_leaf. OOB 分数是 sklearn 返回的一个数字,范围介于完美模型的 1.0 和随机模型的 0.0 之间。(在统计中它被称为R 2,尽管细节对于这个解释并不重要。)我们不需要它非常准确——我们只是用它来比较不同的模型,基于删除一些可能是多余的列:
def get_oob(df):
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=15,
max_samples=50000, max_features=0.5, n_jobs=-1, oob_score=True)
m.fit(df, y)
return m.oob_score_这是我们的基准:
get_oob(xs_imp)0.8771039618198545
现在我们尝试删除每个潜在的冗余变量,一次一个:
{c:get_oob(xs_imp.drop(c, axis=1)) for c in (
'saleYear', 'saleElapsed', 'ProductGroupDesc','ProductGroup',
'fiModelDesc', 'fiBaseModel',
'Hydraulics_Flow','Grouser_Tracks', 'Coupler_System')}{'saleYear': 0.8759666979317242,
'saleElapsed': 0.8728423449081594,
'ProductGroupDesc': 0.877877012281002,
'ProductGroup': 0.8772503407182847,
'fiModelDesc': 0.8756415073829513,
'fiBaseModel': 0.8765165299438019,
'Hydraulics_Flow': 0.8778545895742573,
'Grouser_Tracks': 0.8773718142788077,
'Coupler_System': 0.8778016988955392}
现在让我们尝试删除多个变量。我们将从我们之前注意到的每个紧密对齐的对中删除一个。让我们看看它做了什么:
to_drop = ['saleYear', 'ProductGroupDesc', 'fiBaseModel', 'Grouser_Tracks']
get_oob(xs_imp.drop(to_drop, axis=1))0.8739605718147015
看起来不错!这真的不比所有领域的模型差多少。让我们创建没有这些列的数据帧,并保存它们:
xs_final = xs_imp.drop(to_drop, axis=1)
valid_xs_final = valid_xs_imp.drop(to_drop, axis=1)(path/'xs_final.pkl').save(xs_final)
(path/'valid_xs_final.pkl').save(valid_xs_final)我们可以稍后加载它们:
xs_final = (path/'xs_final.pkl').load()
valid_xs_final = (path/'valid_xs_final.pkl').load()现在我们可以再次检查我们的 RMSE,以确认准确性没有实质性改变:
m = rf(xs_final, y)
m_rmse(m, xs_final, y), m_rmse(m, valid_xs_final, valid_y)(0.183263, 0.233846)
通过关注最重要的变量并删除一些冗余变量,我们大大简化了模型。现在,让我们使用偏相关图看看这些变量如何影响我们的预测。
部分依赖
正如我们所见,两个最重要的预测变量是ProductSize和YearMade。 我们想了解这些预测变量与销售价格之间的关系。最好先检查每个类别的值计数(由 Pandasvalue_counts 方法提供),以查看每个类别的常见程度
p = valid_xs_final['ProductSize'].value_counts(sort=False).plot.barh()
c = to.classes['ProductSize']
plt.yticks(range(len(c)), c);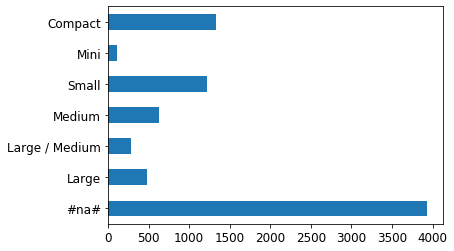
最大的组是#na#,这是 fastai 应用于缺失值的标签。
让我们为 做同样的事情YearMade。由于这是一个数字特征,我们需要绘制一个直方图,将年份值分组到几个离散的 bin 中:
ax = valid_xs_final['YearMade'].hist()
除了我们用于编码缺失年份值的特殊值 1950 之外,大部分数据来自 1990 年之后。
现在我们准备好查看部分依赖图。偏相关图试图回答这个问题:如果一行除了所讨论的特征之外没有任何变化,它将如何影响因变量?
YearMade例如,在所有其他条件相同的情况下,如何影响销售价格?要回答这个问题,我们不能只取每个的平均销售价格YearMade。这种方法的问题在于许多其他事情每年都在变化,例如销售哪些产品、有多少产品装有空调、通货膨胀等。因此,仅对所有具有相同特征的拍卖进行平均,YearMade 也可以捕捉到其他所有领域如何随之变化以及YearMade整体变化如何影响价格的影响。
相反,我们所做的是用 1950 替换列中的每个值YearMade ,然后计算每次拍卖的预测售价,并取所有拍卖的平均值。然后我们对 1951 年、1952 年等做同样的事情,直到 2011 年的最后一年。这隔离了 only 的影响YearMade(即使它是通过对一些想象的记录进行平均来实现的,在这些记录中我们分配了一个YearMade可能永远不会与某些记录一起实际存在的值其他值)。
如果你有哲学头脑,那么考虑我们所处的不同类型的假设会有点令人眼花缭乱杂耍来做这个计算。首先,每个预测都是假设性的,因为我们没有注意到经验数据。其次,有一点是我们不仅有兴趣询问如果我们改变
YearMade以及其他一切随之改变,销售价格会如何变化。相反,我们非常具体地询问在一个只发生变化的假设世界中销售价格将如何YearMade变化。呸!令人印象深刻的是,我们可以提出这样的问题。如果您有兴趣更深入地探索用于分析这些微妙之处的形式主义,我推荐 Judea Pearl 和 Dana Mackenzie 最近关于因果关系的书 The Book of Why (基础书籍)。
有了这些平均值,我们就可以在 x 轴上绘制每年,在 y 轴上绘制每个预测。最后,这是一个部分依赖图。让我们来看看:
from sklearn.inspection import plot_partial_dependence
fig,ax = plt.subplots(figsize=(12, 4))
plot_partial_dependence(m, valid_xs_final, ['YearMade','ProductSize'],
grid_resolution=20, ax=ax);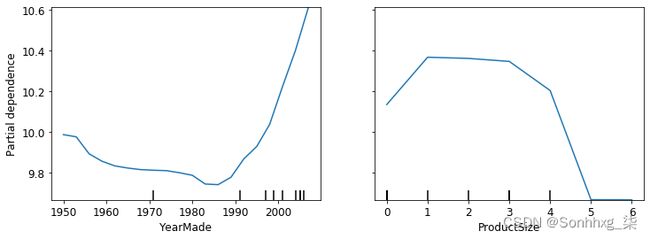
首先查看YearMade图表,特别是涵盖 1990 年之后年份的部分(因为正如我们指出的那样,这是我们拥有最多数据的地方),我们可以看到年份和价格之间几乎呈线性关系。请记住,我们的因变量是在取对数之后得出的,所以这意味着实际上价格呈指数增长。这正是我们所期望的:折旧通常被认为是随时间推移的乘数因子,因此对于给定的销售日期,改变制造年份应该与销售价格呈指数关系。
ProductSize部分情节有点令人担忧。它表明我们看到的最后一组是缺失值,具有最低的 价格。要在实践中使用这种洞察力,我们需要找出它为何 经常缺失以及这意味着什么。缺失值有时可能是有用的预测因子——这完全取决于导致它们缺失的原因。但是,有时它们可能表示数据泄漏。
数据泄露
在论文“数据挖掘中的泄漏:制定、检测和避免”中,Shachar Kaufman 等人。泄漏描述如下:
引入有关数据挖掘问题目标的信息,不应合法地从中进行挖掘。泄漏的一个简单示例是使用目标本身作为输入的模型,因此得出例如“下雨天下雨”的结论。在实践中,这种非法信息的引入是无意的,数据收集、汇总和准备过程助长了这一 过程。
他们举了一个例子:
IBM 的一个真实商业智能项目,其中根据在其网站上找到的关键字,识别某些产品的潜在客户等。事实证明这是泄漏,因为用于培训的网站内容是在潜在客户已经成为客户的时间点进行采样的,并且该网站包含购买 IBM 产品的痕迹,例如“Websphere”一词(例如,在有关购买或客户使用的特定产品功能的新闻稿中)。
数据泄漏是微妙的,可以有多种形式。特别是,失踪 值通常表示数据泄漏。
例如,Jeremy 参加了 Kaggle 竞赛,该竞赛旨在预测哪些研究人员最终会获得研究资助。这些信息是由一所大学提供的,包括数千个研究项目的例子,以及有关研究人员的信息和每笔资助最终是否被接受的数据。该大学希望能够使用在本次竞赛中开发的模型来对最有可能成功的拨款申请进行排名,以便确定其处理的优先顺序。
Jeremy 使用随机森林对数据建模,然后使用特征重要性找出哪些特征最具预测性。他注意到三件令人惊讶的事情:
-
该模型能够在 95% 以上的时间内正确预测谁将获得拨款。
-
显然无意义的标识符列是最重要的预测因素。
-
星期几和一年中的某一天列也具有很高的预测性;例如,绝大多数日期为星期日的拨款申请都被接受,许多被接受的拨款申请日期为 1 月 1 日。
对于标识符列,部分依赖图显示当信息缺失时,申请几乎总是被拒绝。事实证明,在实践中,大学仅在拨款申请被接受后才填写大部分此类信息。通常,对于未被接受的申请,它只是留空。因此,此信息在收到申请时不可用,并且不可用于预测模型——这是数据泄漏。
同样,成功申请的最终处理通常在周末或年底自动批量完成。正是这个最终处理日期最终出现在数据中,所以同样,这些信息虽然是预测性的,但在收到申请时实际上并不可用。
这个例子展示了最实用和最简单的识别数据泄漏的方法,即建立模型然后执行以下操作:
-
检查模型的准确性是否好得令人难以置信。
-
寻找在实践中没有意义的重要预测变量。
-
寻找在实践中没有意义的部分依赖图结果。
回想一下我们的熊检测器,这反映了我们在第 2 章中提供的建议——先构建模型然后进行数据清理通常是个好主意,而不是相反。该模型可以帮助您识别可能存在问题的数据问题。
它还可以帮助您使用树解释器确定哪些因素会影响特定的预测。
树解释器
在本节开始时,我们说过我们希望能够回答五个问题:
-
我们对使用特定数据行的预测有多大信心?
-
对于特定行数据的预测,最重要的因素是什么,它们如何影响该预测?
-
哪些列是最强的预测因子?
-
为了预测的目的,哪些列彼此有效冗余 ?
-
当我们改变这些列时,预测如何变化?
我们已经处理了其中的四个;只剩下第二个问题。要回答这个问题,我们需要用到树解释器库。我们还将使用waterfallcharts库来绘制结果图表。您可以通过在笔记本单元中运行这些命令来安装它们:
!pip install treeinterpreter
!pip install waterfallcharts我们已经了解了如何计算整个随机森林中的特征重要性。基本思想是在每棵树的每个分支上查看每个变量对改进模型的贡献,然后将每个变量的所有这些贡献相加。
我们可以做完全相同的事情,但只针对一行数据。例如,假设我们正在拍卖中查看一件特定物品。我们的模型可能会预测这个项目会非常昂贵,我们想知道为什么。因此,我们将那一行数据放入第一棵决策树中,看看在整个树的每个点上使用了什么拆分。对于每个拆分,我们发现与树的父节点相比,增加或减少。我们对每棵树都这样做,并通过拆分变量将重要性的总变化相加。
例如,让我们选择验证集的前几行:
row = valid_xs_final.iloc[:5]然后我们可以将这些传递给treeinterpreter:
prediction,bias,contributions = treeinterpreter.predict(m, row.values)prediction只是随机森林做出的预测。 bias是基于对因变量(即每棵树的根 模型)取平均值的预测。contributions是最有趣的一点——它告诉我们每个自变量导致的预测总变化。因此,对于每一行, contributionsplus的总和bias必须等于, 。prediction让我们只看第一行:
prediction[0], bias[0], contributions[0].sum()(array([9.98234598]), 10.104309759725059, -0.12196378442186026)
显示贡献的最清晰方法是使用瀑布图。这显示了所有自变量的正负贡献如何加起来创建最终预测,即此处标记为“净”的右侧列:
waterfall(valid_xs_final.columns, contributions[0], threshold=0.08,
rotation_value=45,formatting='{:,.3f}');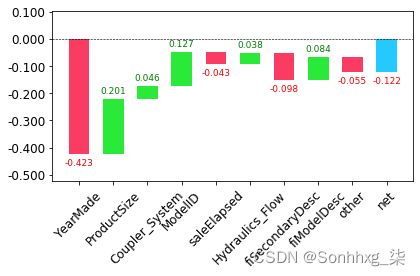
这种信息在生产中最有用,而不是在模型开发期间。您可以使用它向数据产品的用户提供有关预测背后的潜在推理的有用信息。
既然我们介绍了一些经典的机器学习技术来解决这个问题,让我们看看深度学习如何提供帮助!
外推和神经网络
随机森林的问题,就像所有机器学习或深度学习一样 学习算法,是它们并不总能很好地泛化到新数据。我们将了解神经网络在哪些情况下泛化效果更好,但首先,让我们看看随机森林存在的外推问题,以及它们如何帮助识别域外数据。
外推问题
让我们考虑从 40 个数据点进行预测的简单任务,这些数据点显示出轻微的线性关系:
x_lin = torch.linspace(0,20, steps=40)
y_lin = x_lin + torch.randn_like(x_lin)
plt.scatter(x_lin, y_lin);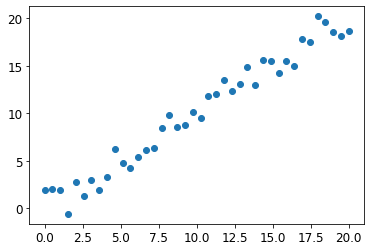
虽然我们只有一个自变量,但 sklearn 需要一个自变量矩阵,而不是一个向量。所以我们必须把我们的向量变成一个只有一列的矩阵。换句话说,我们必须将形状从更改[40]为[40,1]。一种方法是使用unsqueeze方法,它在请求的维度上向张量添加一个新的单位轴:
xs_lin = x_lin.unsqueeze(1)
x_lin.shape,xs_lin.shape(torch.Size([40]), torch.Size([40, 1]))
一种更灵活的方法是使用特殊值对数组或张量进行切片None,这会在该位置引入一个额外的单位轴:
x_lin[:,None].shapetorch.Size([40, 1])
我们现在可以为这些数据创建一个随机森林。我们将仅使用前 30 行来训练模型:
m_lin = RandomForestRegressor().fit(xs_lin[:30],y_lin[:30])然后我们将在完整数据集上测试模型。蓝点是训练数据,红点是预测:
plt.scatter(x_lin, y_lin, 20)
plt.scatter(x_lin, m_lin.predict(xs_lin), color='red', alpha=0.5);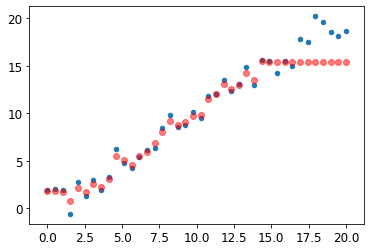
我们有大问题了!我们在训练数据涵盖的领域之外的预测都太低了。你认为这是为什么?
请记住,随机森林只是对许多树的预测进行平均。而一棵树只是简单地预测叶子中行的平均值。因此,树和随机森林永远无法预测训练数据范围之外的值。这对于指示随时间变化趋势的数据(例如通货膨胀)尤其成问题,并且您希望对未来时间进行预测。您的预测在系统上会过低。
但问题超出了时间变量。 在更一般的意义上,随机森林无法推断出它们所看到的数据类型之外的数据。这就是为什么我们需要确保我们的验证集不包含域外数据。
查找域外数据
有时很难知道您的测试集是否以与训练数据相同的方式分布,或者,如果不同,哪些列反映了这种差异。有一种简单的方法可以解决这个问题,那就是使用随机森林!
但在这种情况下,我们不使用随机森林来预测我们实际的因变量。相反,我们尝试预测一行是在验证集中还是在训练集中。为了实际看到这一点,让我们结合训练集和验证集,创建一个因变量来表示每一行来自哪个数据集,使用该数据构建随机森林,并获取其特征重要性:
df_dom = pd.concat([xs_final, valid_xs_final])
is_valid = np.array([0]*len(xs_final) + [1]*len(valid_xs_final))
m = rf(df_dom, is_valid)
rf_feat_importance(m, df_dom)[:6]| cols | imp | |
|---|---|---|
| 5 | saleElapsed | 0.859446 |
| 9 | SalesID | 0.119325 |
| 13 | MachineID | 0.014259 |
| 0 | YearMade | 0.001793 |
| 8 | fiModelDesc | 0.001740 |
| 11 | Enclosure | 0.000657 |
这表明训练集和验证集之间的三列存在显着差异:saleElapsed、SalesID和MachineID。很明显为什么会出现这种情况saleElapsed:它是数据集开始和每一行之间的天数,因此它直接对日期进行编码。的差异SalesID表明拍卖销售的标识符可能会随着时间的推移而增加。MachineID表明在这些拍卖中出售的个别物品可能会发生类似的事情。
让我们得到原始随机森林模型的 RMSE 的基线,然后确定依次删除每一列的效果:
m = rf(xs_final, y)
print('orig', m_rmse(m, valid_xs_final, valid_y))
for c in ('SalesID','saleElapsed','MachineID'):
m = rf(xs_final.drop(c,axis=1), y)
print(c, m_rmse(m, valid_xs_final.drop(c,axis=1), valid_y))orig 0.232795 SalesID 0.23109 saleElapsed 0.236221 MachineID 0.233492
看起来我们应该能够在 不损失任何准确性的情况下删除SalesID和。MachineID让我们检查:
time_vars = ['SalesID','MachineID']
xs_final_time = xs_final.drop(time_vars, axis=1)
valid_xs_time = valid_xs_final.drop(time_vars, axis=1)
m = rf(xs_final_time, y)
m_rmse(m, valid_xs_time, valid_y)0.231307
删除这些变量略微提高了模型的准确性;但更重要的是,随着时间的推移,它应该会变得更有弹性,并且更容易维护和理解。我们建议对于所有数据集,您尝试构建一个模型,其中您的因变量是 is_valid,就像我们在这里所做的那样。它通常可以发现您可能会错过的细微域转移 问题。
在我们的案例中可能有帮助的一件事是简单地避免使用旧数据。通常,旧数据显示的关系不再有效。让我们尝试只使用最近几年的数据:
xs['saleYear'].hist();
下面是这个子集的训练结果:
filt = xs['saleYear']>2004
xs_filt = xs_final_time[filt]
y_filt = y[filt]m = rf(xs_filt, y_filt)
m_rmse(m, xs_filt, y_filt), m_rmse(m, valid_xs_time, valid_y)(0.17768, 0.230631)
它稍微好一点,这表明您不应该总是使用整个数据集;有时一个子集会更好。
让我们看看使用神经网络是否有帮助。
使用神经网络
我们可以使用相同的方法来构建神经网络模型。 让我们首先复制我们设置 TabularPandas对象所采取的步骤:
df_nn = pd.read_csv(path/'TrainAndValid.csv', low_memory=False)
df_nn['ProductSize'] = df_nn['ProductSize'].astype('category')
df_nn['ProductSize'].cat.set_categories(sizes, ordered=True, inplace=True)
df_nn[dep_var] = np.log(df_nn[dep_var])
df_nn = add_datepart(df_nn, 'saledate')我们可以利用我们所做的工作,通过为我们的神经网络使用相同的列集来修剪随机森林中不需要的列:
df_nn_final = df_nn[list(xs_final_time.columns) + [dep_var]]分类列在神经网络中的处理方式非常不同, 与决策树方法相比。正如我们在 第 8 章中看到的,在中性网络中,处理分类变量的一种好方法是使用嵌入。为了创建嵌入,fastai 需要确定哪些列应该被视为分类变量。它通过将变量中不同级别的数量与max_card参数值进行比较来实现这一点。如果它较低,fastai 会将变量视为分类变量。大于 10,000 的嵌入大小通常只应在您测试是否有更好的方法对变量进行分组后使用,因此我们将使用 9,000 作为我们的max_card值:
cont_nn,cat_nn = cont_cat_split(df_nn_final, max_card=9000, dep_var=dep_var)然而,在这种情况下,我们绝对不想将一个变量视为分类变量:saleElapsed。根据定义,分类变量不能推断出它所见的值范围之外,但我们希望能够预测未来的拍卖价格。让我们验证是否cont_cat_split做了正确的事情:
cont_nn.append('saleElapsed')
cat_nn.remove('saleElapsed')让我们看一下到目前为止我们选择的每个分类变量的基数:
df_nn_final[cat_nn].nunique()YearMade 73 ProductSize 6 Coupler_System 2 fiProductClassDesc 74 ModelID 5281 Hydraulics_Flow 3 fiSecondaryDesc 177 fiModelDesc 5059 ProductGroup 6 Enclosure 6 fiModelDescriptor 140 Drive_System 4 Hydraulics 12 Tire_Size 17 dtype: int64
事实上,有两个变量与设备的“模型”有关,都具有相似的非常高的基数,这表明它们可能包含相似的冗余信息。请注意,我们在分析冗余特征时不一定会发现这一点,因为这依赖于以相同顺序排序的相似变量(即,它们需要具有相似命名的级别)。具有 5,000 个级别的列意味着在我们的嵌入矩阵中需要 5,000 列,如果可能的话最好避免。让我们看看删除这些模型列之一对随机森林的影响:
xs_filt2 = xs_filt.drop('fiModelDescriptor', axis=1)
valid_xs_time2 = valid_xs_time.drop('fiModelDescriptor', axis=1)
m2 = rf(xs_filt2, y_filt)
m_rmse(m2, xs_filt2, y_filt), m_rmse(m2, valid_xs_time2, valid_y)(0.176706, 0.230642)
影响很小,所以我们将删除它作为我们神经网络的预测器:
cat_nn.remove('fiModelDescriptor')我们可以使用TabularPandas与创建随机森林时相同的方式创建我们的对象,并添加一个非常重要的功能:归一化。随机森林不需要任何规范化——树构建过程只关心变量中值的顺序,根本不关心它们是如何缩放的。但正如我们所见,神经网络肯定会关心这一点。因此,我们在 Normalize构建TabularPandas对象时添加处理器:
procs_nn = [Categorify, FillMissing, Normalize]
to_nn = TabularPandas(df_nn_final, procs_nn, cat_nn, cont_nn,
splits=splits, y_names=dep_var)表格模型和数据通常不需要太多 GPU RAM,因此我们可以使用更大的批处理大小:
dls = to_nn.dataloaders(1024)正如我们所讨论的, y_range为回归模型设置是个好主意,所以让我们找到因变量的最小值和最大值:
y = to_nn.train.y
y.min(),y.max()(8.465899897028686, 11.863582336583399)
我们现在可以创建Learner来创建此表格模型。像往常一样,我们使用特定于应用程序的学习者功能,以利用其应用程序自定义的默认值。我们将损失函数设置为 MSE,因为这是本次比赛使用的。
默认情况下,对于表格数据,fastai 创建一个具有两个隐藏层的神经网络,分别具有 200 和 100 个激活。这对于小型数据集非常有效,但这里我们有一个相当大的数据集,所以我们将图层大小增加到 500 和 250:
from fastai.tabular.all import *learn = tabular_learner(dls, y_range=(8,12), layers=[500,250],
n_out=1, loss_func=F.mse_loss)learn.lr_find()(0.005754399299621582, 0.0002754228771664202)
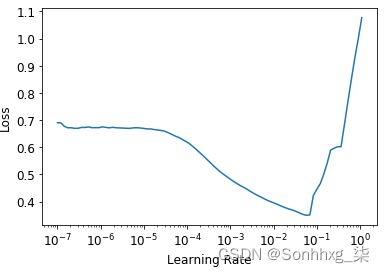
没有必要使用fine_tune,所以我们将使用 训练fit_one_cycle几个时期,看看它看起来如何:
learn.fit_one_cycle(5, 1e-2)| epoch | train_loss | vaild_loss | time |
|---|---|---|---|
| 0 | 0.069705 | 0.062389 | 00:11 |
| 1 | 0.056253 | 0.058489 | 00:11 |
| 2 | 0.048385 | 0.052256 | 00:11 |
| 3 | 0.043400 | 0.050743 | 00:11 |
| 4 | 0.040358 | 0.050986 | 00:11 |
我们可以使用我们的r_mse函数将结果与我们之前得到的随机森林结果进行比较:
preds,targs = learn.get_preds()
r_mse(preds,targs)
0.22580.2258
它比随机森林好很多(尽管训练时间更长,而且对超参数调整更挑剔)。
在我们继续之前,让我们保存我们的模型,以防我们以后想再次回到它:
learn.save('nn')FASTAI 的 TABULAR CLASSES
在 fastai 中,表格模型只是一个采用连续或分类数据列并预测类别(a 分类模型)或连续值(回归模型)。分类自变量通过嵌入传递并连接,正如我们在用于协同过滤的神经网络中看到的那样,然后连续变量也被连接起来。
创建的模型tabular_learner是类的对象 TabularModel。现在看看源代码tabular_learner(记住,那是tabular_learner??在 Jupyter 中)。您会看到collab_learner,它首先会调用 get_emb_sz以计算适当的嵌入大小(您可以使用emb_szs参数覆盖这些大小,该参数是一个字典,其中包含您想要手动设置大小的任何列名),并且它设置了一些其他默认值。除此之外,它创建 TabularModel并将其传递给TabularLearner(请注意 ,除自定义 方法外,TabularLearner它与 相同)。Learnerpredict
这意味着实际上所有工作都在 中进行TabularModel,所以现在请查看源代码。除了 层BatchNorm1d和Dropout层(我们将在稍后学习)之外,您现在已经掌握了理解整个课程所需的知识。看看EmbeddingNN上一章末尾的讨论。回想一下,它传递n_cont=0给TabularModel. 我们现在可以明白为什么会这样了:因为有零个连续变量(在 fastai 中,n_前缀的意思是“数量”,cont是“连续”的缩写)。
另一件有助于泛化的事情是使用多个模型并对它们的预测进行平均——一种技术,如前所述,称为集成。
Ensembling(合奏)
回想一下为什么随机森林如此有效背后的最初推理 嗯:每棵树都有错误,但这些错误彼此不相关,所以一旦有足够多的树,这些错误的平均值应该趋于零。类似的推理可用于考虑对使用不同算法训练的模型的预测进行平均。
在我们的例子中,我们有两个非常不同的模型,使用非常不同的算法训练:随机森林和神经网络。可以合理地预期每个人所犯的错误类型会大不相同。因此,我们可能会期望他们预测的平均值会优于任何一个人的个人预测。
正如我们之前看到的,随机森林本身就是一个集成。但是我们可以在另一个集成中包含一个随机森林——一个随机森林和神经网络的集成!虽然集成不会在成功和不成功的建模过程之间产生差异,但它肯定可以为您构建的任何模型增加一点小小的推动力。
我们必须注意的一个小问题是我们的 PyTorch 模型和我们的 sklearn 模型创建不同类型的数据:PyTorch 给我们一个 rank-2 张量(一个列矩阵),而 NumPy 给我们一个 rank-1 数组(一个向量). squeeze从张量中删除任何单位轴,to_np 并将其转换为 NumPy 数组:
rf_preds = m.predict(valid_xs_time)
ens_preds = (to_np(preds.squeeze()) + rf_preds) /2这给了我们比任何一个模型单独获得的结果更好的结果:
r_mse(ens_preds,valid_y)0.22291
事实上,这个结果比 Kaggle 上显示的任何分数都要好 排行榜。然而,它不能直接比较,因为 Kaggle 排行榜使用我们无法访问的单独数据集。Kaggle 不允许我们提交给这个旧竞赛以了解我们会怎么做,但我们的结果确实令人鼓舞!
Boosting
到目前为止,我们的集成方法一直是使用bagging,它涉及通过对它们进行平均来组合许多模型(每个模型在不同的数据子集上训练)。正如我们所见,将其应用于决策树时,称为随机森林。
在另一个重要的集成方法中,称为boosting, 我们添加模型而不是平均它们的地方。以下是提升的工作原理:
-
训练一个不适合您的数据集的小型模型。
-
计算该模型训练集中的预测。
-
从目标中减去预测;这些称为残差,代表训练集中每个点的误差。
-
回到步骤 1,但不使用原始目标,而是使用残差作为训练目标。
-
继续这样做,直到达到停止标准,例如最大树数,或者您观察到验证集错误变得更糟。
使用这种方法,每棵新树都将尝试适应所有先前树组合的错误。因为我们通过从前一棵树的残差中 减去每棵新树的预测来不断创建新的残差,所以残差会越来越小。
为了用一组增强树进行预测,我们计算 来自每棵树的预测,然后将它们全部加在一起。有许多模型遵循这种基本方法,并且相同模型有许多名称。梯度提升机(GBM) 和梯度提升决策树(GBDT) 是您最有可能遇到的术语,或者您可能会看到实现这些的特定库的名称;在撰写本文时,XGBoost是最受欢迎的。
请注意,与随机森林不同,使用这种方法,没有什么可以阻止我们过度拟合。在随机森林中使用更多树不会导致过度拟合,因为每棵树都独立于其他树。但是在提升的集成中,你拥有的树越多,训练误差就越大,最终你会看到验证集上的过度拟合。
我们不打算在这里详细介绍如何训练梯度提升树集成,因为该领域正在快速发展,我们提供的任何指导在您阅读本文时几乎肯定已经过时。在我们撰写本文时,sklearn 刚刚添加了一个 HistGradientBoostingRegressor提供出色性能的类。有许多超参数需要针对此类进行调整,对于我们见过的所有梯度提升树方法。与随机森林不同,梯度提升树对这些超参数的选择极其敏感;在实践中,大多数人使用一个循环来尝试一系列超参数来找到最有效的超参数。
另一种取得了巨大成果的技术是在机器学习模型中使用神经网络学习的嵌入。
将嵌入与其他方法相结合
我们开头提到的entity embedding论文摘要 本章指出:“当用作输入特征时,从经过训练的神经网络获得的嵌入显着提高了所有经过测试的机器学习方法的性能。” 它包括非常有趣的表,如图 9-8所示。
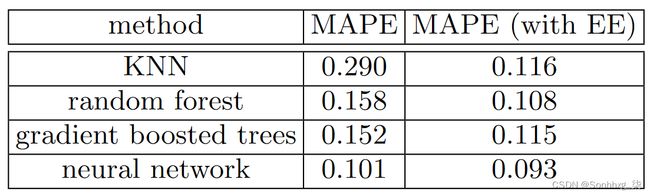
图 9-8。使用神经网络嵌入作为其他机器学习方法输入的效果(由 Cheng Guo 和 Felix Berkhahn 提供)
这显示了之间比较的平均平均百分比误差 (MAPE) 四种建模技术,其中三种我们已经见过,还有k最近邻 (KNN),这是一种非常简单的基线方法。第一个数字列包含对竞赛提供的数据使用方法的结果;第二列显示如果您首先使用分类嵌入训练神经网络,然后使用这些分类嵌入而不是模型中的原始分类列,会发生什么情况。如您所见,在每种情况下,通过使用嵌入而不是原始类别,模型都得到了显着改进。
这是一个非常重要的结果,因为它表明您无需在推理时使用神经网络即可获得神经网络的大部分性能改进。你可以只使用一个嵌入,它实际上只是一个数组查找,以及一个小的决策树集合。
这些嵌入甚至不需要为组织中的每个模型或任务单独学习。相反,一旦为特定任务的列学习了一组嵌入,它们就可以存储在一个中心位置并在多个模型中重复使用。事实上,我们从与大公司其他从业者的私下交流中了解到,这种情况已经在很多地方发生了。
结论
我们已经讨论了两种表格建模方法:决策树 集成和神经网络。我们还提到了两个决策树集成:随机森林和梯度提升机。每个都是有效的,但也需要妥协:
-
随机森林是最容易训练的,因为它们对超参数的选择具有极强的弹性,并且几乎不需要预处理。它们训练起来很快,如果你有足够多的树,它们就不会过度拟合。但它们可能不太准确,尤其是在需要外推的情况下,例如预测未来的时间段。
-
理论上梯度提升机的训练速度与随机森林一样快,但在实践中你将不得不尝试大量的超参数。它们可能会过度拟合,但它们通常比随机森林更准确。
-
神经网络的训练时间最长,需要额外的预处理,例如归一化;这种规范化也需要在推理时使用。它们可以提供很好的结果并且可以很好地推断,但前提是你要小心你的超参数并注意避免过度拟合。
我们建议您从随机森林开始分析。这将为您提供强大的基线,您可以确信这是一个合理的起点。然后,您可以使用该模型进行特征选择和部分依赖分析,以更好地了解您的数据。
在此基础上,您可以尝试神经网络和 GBM,如果它们在合理的时间内为您的验证集提供明显更好的结果,您就可以使用它们。如果决策树集成对您来说效果很好,请尝试将分类变量的嵌入添加到数据中,看看这是否有助于您的决策树更好地学习。