目标检测评价指标合集
目标检测评价指标
混淆矩阵(confusion matrix)可谓是贯穿了整个目标检测评价体系,衍生了一系列的目标检测评价指标,如精确率(precision),准确率(accuracy),召回率(recall),F1-score,ROC-AUC指标,Ap(平均正确率),MAp(mean average precisioon),IOU(intersect over union)等一系列常见评价指标。下面将会针对这些评价指标展开一一介绍。
混淆矩阵(Confusion matrix)

TP:真实为正样本,预测也为正样本。又称(真阳性)
FN:真实为正样本,预测为负样本。又称(假阴性)
FP:真实为负样本,预测为正样本。又称(假阳性)
TN:真实为负样本,预测为负样本。又称(真阴性)
通常情况下,我们希望TP+TN越大越好(预测正确的概率),FP+FN越小越好(预测错误的概率)
精确率(Precision)召回率(Recall)
Precision:预测为正的样本(TP+FP)中,真实为正(TP)的比例 == T P T P + F P \dfrac{TP}{TP+FP} TP+FPTP
Recall:真实为正(TP+FN)的样本中,预测为正(TP)的比例== T P T P + F N \dfrac{TP}{TP+FN} TP+FNTP
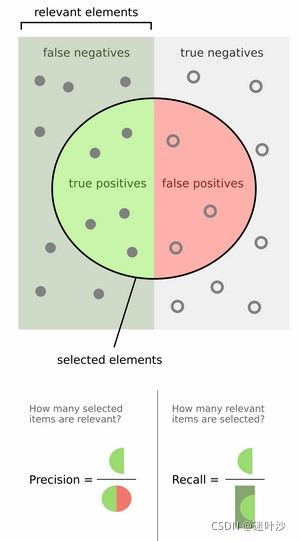
true positives:TP(真实为正,预测为正)
false positives:FP(真实为负,预测为正)
false negatives:FN(真实为正,预测为负)
true negatives:TN(真实为负,预测为负)
Recall=100%,表示真实为正的样本中,全部被检测出来了。举个栗子:现在有100个人,经过检测我们完美的检测出100个人,这样我们的召回率就为100%,表示任一目标都没有漏检。
Precision=100%,表示预测为正的样本同时也真实为正。现在我们预测出100个人,后来经过与真实样本对比,发现真实数据中也恰好100个人。表示我们成功识别出所有目标,没有发生虚警。
这两个指标我们都希望越大越好,都处于【0,1】之间。
准确率(Accuracy)
Accuracy:将正、负样本(TP+TN)分别检测出来与总体样本(TP+FP+FN+TN)的比例== T P + T N T P + F P + F N + T N \dfrac{TP+TN}{TP+FP+FN+TN} TP+FP+FN+TNTP+TN
F1–score
F 1 − s c o r e = 2 1 P + 1 R = 2 P R P + R F1-score=\dfrac{2}{\frac{1}{P}+\frac{1}{R}}=2\dfrac{PR}{P+R} F1−score=P1+R12=2P+RPR
通常我们采取精确率与召回率两个指标来衡量一个模型的好坏,因为有两个指标的参与,我们需要对其分配权重,通常我们采取0.5/0.5的权重方式。但在实际情况中两个指标呈现相互冲突的情况。在增大样本的情况下,recall往往呈现越来越高的趋势,而precision往往却呈现出逐渐降低的趋势
ROC-AUC
在目标检测任务中,ROC曲线使用尤为广泛。ROC曲线横纵坐标系由FPR(假阳性率)与TPR(真阳性率)构成。
F P R = F P F P + T N , T P R = T P T P + F N FPR=\dfrac{FP}{FP+TN},TPR=\dfrac{TP}{TP+FN} FPR=FP+TNFP,TPR=TP+FNTP
这里就引入了一个问题,前面我们已经引入了多几种评价指标,为何还要使用ROC曲线呢,其横纵坐标系其实与上述指标极为相近。这里ROC不易受样本波动的优越性能便表现出来了。
实际问题中,我们往往受到样本不均衡带来的干扰。很多曲线由于正负样本的分布情况不同而产生了诸多的变动,但ROC
曲线却能很好的抵消掉这一干扰。假设我们现在增大负样本,来造成一种样本不均衡的情况。TPR只考虑预测为正样本
的目标,因此不受影响,FPR中,FP与TN随着负样本的增加总体呈现出等比例增加的情况,因此大体上FPR也呈现出不变
的情形。因此ROC曲线即使在样本出现不均衡的情况依旧具有较好的鲁棒性。
AUC指标指ROC曲线与横纵坐标所围成的面积,是一个0-1的概率值。面积大小反映了模型的分类能力,面积越大分类效果越好。
AUC=1:理想分类器
AUC∈[0.7,1]:较好分类器
AUC=0.5:乱猜
AUC<0.5:还不如乱猜
平均正确率(AP)
image cites from https://blog.csdn.net/Gentleman_Qin/article/details/84519388

AP:average precision,平均正确率,就是P(Precision)-R(Recall)曲线所包围的面积。0-1区间,面积越大,分类器模型效果越好。Ap计算的是单个类别的平均正确率。
MAP:mean average precision,如上图所示,A,B,C三个类别,有三个Ap, M A P = A P a + A P b + A P c 3 MAP=\dfrac{AP_a+AP_b+AP_c}{3} MAP=3APa+APb+APc
在Pascal VOC 挑战中,还采取了另外一种Ap计算方式。就是我们论文上常见的top-N评估方式。通过事先设定N个Recall阈值,通过绘制P-R曲线。在每一个召回阈值下都对应着一个最高的Precision,这样我们就可以得到N个Precision。最终将Precision求和再与样本数N取均值得到该类别的AP值。(VOC2007中使用,VOC2012采取计算面积的方式)
补充
在COCO数据中,还有 A P s m a l l 、 A P m e d i u m 、 A P l a r g e AP^{small}、AP^{medium}、AP^{large} APsmall、APmedium、APlarge,针对于样本中不同大小的目标分别计算其AP值。
small:< 3 2 2 32^2 322
medium: 3 2 2 < 9 6 2 32^2<96^2 322<962
large: 9 6 2 > 96^2> 962>
IOU(Intersect over union)
在进行目标检测任务中,我们预测出的目标边界框几乎不可能与真实边界框完全一致。通常情况下我们只需要让我们预测的边界框与真实的边界框有较大的的重合度即可。

IOU:0处于0-1之间, I O U = A ⊓ B A ⊔ B IOU=\dfrac{A\sqcap{B}}{A\sqcup{B}} IOU=A⊔BA⊓B,与杰卡德系数有异曲同工之处。
def calculate_iou(pre_bbox,groud_bbox):
"""
calculate intersection over union between pre_bbox and ground_bbox
params:
pre_bbox:{'xmin':xxx,'ymin':xxx,'xmax':xxx,'ymax':xxx}
groud_bbox:{'xmin':xxx,'ymin':xxx,'xmax':xxx,'ymax':xxx}
return :iou
"""
# 检测xmin,ymin,xmax,ymax是否符合实际情况
assert pre_bbox['xmin']<pre_bbox['xmax'] and groud_bbox['xmin']<groud_bbox['xmax']
assert pre_bbox['ymin']>pre_bbox['ymax'] and groud_bbox['ymin']<groud_bbox['ymax']
# 获取intersection area coordinates
x_min = max(pre_bbox['xmin'],groud_bbox['xmin'])
y_min = max(pre_bbox['ymin'],groud_bbox['ymin'])
x_max = min(pre_bbox['xmax'],groud_bbox['xamx'])
y_max = min(pre_bbox['ymax'],groud_bbox['ymax'])
# calculate areas
intersection_area = (x_max-x_min)*(y_max-y_min)
pre_bbox_area = (pre_bbox['max']-pre_bbox['xmin']+1)*(pre_bbox['ymax']-pre_bbox['ymin']+1)
groud_bbox_area = (groud_bbox['max']-groud_bbox['xmin']+1)*(groud_bbox['ymax']-groud_bbox['ymin']+1)
# calculate iou
iou = intersection_area/(pre_bbox_area+groud_bbox_area-intersection_area)
assert iou>=0.0 and iou<=1.0
return iou
上述function简单计算了两个bbox之间的IOU,有一个细节需要注意一下,我们计算pre_bbox与groud_bbox时
需要坐标之间有+1的操作。这里的+1操作其实就是和python索引有关,比如1080P像素度为1920*1080,索引从
(0-1919,0-1079)因此我们在计算覆盖的像素面积时需要+1.
如计算(0,0)与(1919,1079)整张1080P面积时,应为(1919-0+1)*(1079-0+1) = 1920*1080