综述类论文_Machine Learning for Encrypted Malicious Traffic Detection(重要)
文章目录
- Machine Learning for Encrypted Malicious Traffic Detection: Approaches, Datasets and Comparative Study
-
- 摘要
- 存在的问题
- 论文贡献
- 1. 基于机器学习的加密流量检测模型的总体框架
-
- 1.1 Research Target(研究目标)
- 1.2 Traffic Dataset Collection(流量数据集收集)
- 1.3 Traffic and Feature Extraction(流量和特征提取)
- 1.4 Feature Set Selection(特征选择)
- 1.5 Algorithms Selection(算法选择)
- 2. 比较实验
-
- 2.1 数据集的收集
- 2.2 特征提取与选择
- 2.3 实验
- 总结
-
- 学到的知识点
Machine Learning for Encrypted Malicious Traffic Detection: Approaches, Datasets and Comparative Study
中文题目:用于加密恶意流量检测的机器学习:方法、数据集和比较研究
发表期刊及年份:Computers & Security 2022/02
作者:Zihao Wang, Kar-Wai Fok, Vrizlynn L. L. Thing
latex引用:
@article{wang2022machine,
title={Machine learning for encrypted malicious traffic detection: Approaches, datasets and comparative study},
author={Wang, Zihao and Fok, Kar Wai and Thing, Vrizlynn LL},
journal={Computers \& Security},
volume={113},
pages={102542},
year={2022},
publisher={Elsevier}
}
摘要
随着人们对个人隐私和数据安全的需求日益突出,加密流量已成为网络世界的主流。然而,流量加密也可以防止对手引入的恶意和非法流量被检测到。特别是在新冠肺炎疫情后,恶意流量加密迅速增长的环境下。依赖普通负载内容分析(如深度包检查)的常见安全解决方案是无用的。因此,基于机器学习的方法已经成为加密恶意流量检测的一个重要方向。
本文提出了一种基于机器学习的加密恶意流量检测技术的通用框架,并对其进行了系统的综述。此外,由于缺乏公认的数据集和特征集,目前的研究采用不同的数据集来训练模型。因此,它们的模型性能无法进行可靠的比较和分析。
因此,在本文中,
- 我们分析、处理和组合了来自5个不同来源的数据集,以生成一个全面和公平的数据集,以帮助未来该领域的研究。
- 在此基础上,我们还实现并比较了10种加密恶意流量检测算法。然后讨论挑战并提出未来的研究方向。
存在的问题
- 虽然大多数个人和企业享受加密流量提供的流量隐私和数据保护,但攻击者也在利用加密来逃避其恶意活动的检测。
- 目前的基于机器学习的加密恶意流量检测方法研究采用不同的数据集来训练模型,因此它们的模型性能无法进行可靠的比较和分析。
- 流量加密目前有多种机制,如SSL、TLS (Transport Layer Security)、VPN (Virtual Private Network)、SSH (Secure Shell Protocol)和P2P。这些加密算法的工作原理不同;一些在传输层,而另一些在应用层,这使得加密流分类成为一项具有挑战性的任务。
- 即使使用相同的加密机制,由于原始流量的分布和利用率不同,加密后的流量也会呈现不同的数据分布特征。因此,大部分的研究都集中在加密流量的二分类上,即区分正常流量和恶意流量。
- 基于流的机器学习方法被认为是加密流分类最常用的方法。然而,值得注意的是,训练数据集的收集和加密流量检测特征的选择仍然是一个充满活力的研究领域。
论文贡献
- 对于我们提出的机器学习框架,回顾和讨论了它的优势、局限性,并且比较不同的技术。
- 对目前可用的流量数据集进行相对全面的整理和分析,分析其特点、局限性和适用性。这样的分析使数据集能够更好地服务于这种基于机器学习的方法。
- 对机器学习模型的特点进行分类,并讨论它们的优势、限制、适用场景和可能的优化方向。
- 基于相同的训练数据集,使用不同的算法和特征集进行对比实验,以找到更可靠和一致的结果。据我们所知,我们构建的数据集是最全面的训练数据集,完全由开放的公共数据源组成。
1. 基于机器学习的加密流量检测模型的总体框架

框架流程介绍:
- Research Target:确定研究目标。
- Traffic Dataset Collection:交通数据集的采集。可通过两种方式采集:
真实的流量采集和模拟流量生成。
- Feature Selection/Feature extraction:特征选择/特征提取。
特征选择:首先从流量中提取所有可能的特征,然后自动选择特征,以获得最理想的特征集。
特征提取:首先进行特征选择,然后根据所选特征进行流量和特征提取。
- Algorithms Selection:算法选择。
- Experiment Evaluation:实验评估。
1.1 Research Target(研究目标)
加密流量分类一般可分为两大类:
- 加密和非加密流量分类。
- 加密恶意流量检测:
目前还没有覆盖所有类型的流量和恶意软件家族的工作。多分类的性能也普遍比二分类方法差。
目前研究概况:
-
不考虑加密协议的二分类问题(该二分类包含两种:加密与不加密、恶意加密和正常加密)。
-
明确加密协议下的二分类问题(该二分类包含两种:加密与不加密、恶意加密和正常加密)。
-
不考虑加密协议的恶意软件族的多分类。
-
明确加密协议下恶意软件族的多分类。
最后,在设定研究目标的过程中,我们还需要考虑检测模型的运行环境。也就是说,检测模型是在线运行还是离线运行,因为不同的操作环境对效率、鲁棒性和准确性有不同的要求。有时,我们需要妥协一个要求,以更好地满足其他要求。
总结:
- 要确定要做哪方面的研究
- 要确定检测模型的运行环境
1.2 Traffic Dataset Collection(流量数据集收集)
数据采集方法一般可分为两种:
- 真实流量采集:在实际运行的网络环境中,通过常用的流量采集软件(如Wireshark)采集流量数据。然后对收集到的数据进行分析和标记以供使用。
优点:真实流量采集方法保证了数据集中网络流量的真实性
缺点:由于与正常的网络交互相比,真实网络攻击的频率较低,收集到的数据集往往不平衡,存在大量冗余数据,需要大量的时间进行筛选和标记。 - 模拟流量生成:通常通过构建模拟网络或使用脚本模拟器生成目标流量数据集。
优点:它们也比来自真实流量收集的数据集更加平衡,更适合于机器学习。
缺点:模拟流量生成的数据集可能与真实的网络数据存在差异,并不能真正代表真实的网络流量状况。
一个优秀的加密恶意流量数据集需要具有以下特征:
-
足够多的加密流量。
-
多种加密恶意攻击。
-
类平衡。
-
基本事实得到证实。
-
无冗余数据。
不幸的是,目前还没有针对这个特定域问题的成熟数据集。因此,研究工作经常使用自己的私有数据集或从少数可用的公共数据集中选择。这就提出了在这些现有作品之间进行公平性能比较的挑战。
因此,我们的目标是解决这一问题,为今后这一课题的研究奠定良好的基础。我们收集可公开获得的适用于加密流量分析的数据集,并分析其目标和适用领域、特征、局限性,以及是否包含加密恶意流量。
数据集:
下表中显示了编译后的数据集列表。通过分析,发现大多数公共数据集要么包含少量加密流量,要么根本不包含加密流量。包含加密恶意流量的数据集更加罕见。

总结:
可用于加密流量检测的公开数据集有以下几个:UNSW_NS2019、CIC-AndMal2017、CICIDS2017、UNSW_NS2015、Malware Capture Facility Project、Malware traffic analysis net
1.3 Traffic and Feature Extraction(流量和特征提取)
流程主要分2步:
-
Traffic data pre-processing(流量数据预处理):
一般公开数据集有以下两种:pcap和csv文件数据清洗:
(1)清洗原始pcap包(大多数):1)需要清理不适用于加密恶意流量检测研究的无关网络报文,如ARP或ICMP报文
2)需要删除重复的,损坏的,不必要的,不完全捕获的流量流或信息
3)使用数据截断和填充来保持输入数据的长度一致
4)过滤掉非加密流量,最终的数据集只包含加密流量(2)事先进行清理、过滤和特征提取的csv格式的数据集
- 如果csv特征数据集中没有标识这些特征是从加密流量还是非加密流量中提取的,且数据集的来源不提供原始流量文件(即PCAP文件),这样的数据集很难进行加密流量检测模型的训练。
- 如果训练模型所需的特征不包含在这类数据集中,则数据集也不能使用。
数据编码:
此外,我们还需要将数据集中的离散特征(如网络协议信息、加密协议证书、服务器指示名称等)转换或编码为数字特征。数据平衡:
两种解决方案:
(1)组合不同数据集,或者使用自生成数据集来增加流量的类型和数量。
(2)可以采用数据增强、过采样、过采样、过采样后过采样等方法来解决数据不平衡问题。数据归一化:
数据归一化可以将流量数据或特征值归一化为0到1或负1到正1的范围,从而减少数据冗余,增强模型训练的完整性和效率。 -
Feature extraction(特征提取):
本文将流量特征分为两类:协议无关的数值特征 和 协议特定的特征。
(1)协议无关的数值特征:两种粒度
1)基于包的特征:在流量包级别提取的特征。如会话流中报文的时间差、每个报文的包大小(或包长度)、每个报文的负载大小(或负载长度)、每个会话的TCP窗口长度的值变化等。
2)基于会话的特征:在会话流级别提取的特征。例如会话流持续时间、每个会话中来自客户机/服务器的总字节数、每个会话中来自客户机/服务器的总数据包数、每个会话的IP包头的总长度。
统计特征:统计特征是通过对上述这些特征进行统计计算得到的。常用的计算方法包括基于包和基于会话的特征的平均值、中位数、最大值、最小值、方差和标准偏差(STD)。
特征子集:基于特征的独特属性,从不确定协议的数值特征中选取其独特子集作为模型训练特征集。例如Stergiopoulos等定义了TCP侧通道特征(如与前一个数据包的比值)。简单来说就是根据自己的研究方法选择上述特征集合的子集来做研究,大部分高质量的工作都是使用特征子集的方法。(2)协议特定的特征:从加密协议信息中提取特征,目前HTTPs作为加密流量类型占主导地位。
HTTPs使用的加密协议为TLS/SSL。相关特征通常从三个不同的日志文件中提取:
1)conn.log文件:从conn.log文件中提取的特征与协议无关的数值特征有一定的重叠。例如,它的特性还包括来自客户机和服务器的流和有效负载字节数。
2)SSL.log文件:包括TLS版本类型和同一发行者的比例。
3)X509.log(证书日志)文件:包括公共证书密钥平均值、证书有效性平均值和SAN中的域名的平均数。从捕获的原始网络流量(即pcap包)生成日志的最常用应用程序之一是Zeek IDS (Bro IDS)。Zeek IDS通过处理原始网络流量,根据流量和协议生成此类日志文件。这些日志文件通过uid(唯一id)列和cert chain fuid(证书标识符)列相互连接。

-
对于协议特定的特征,一个重要的限制是这些特性只适用于它们相关的加密协议。因此,如果数据集包含其他加密协议,特定于协议的特性将不再适用。
-
另一方面,协议无关的数值特征的提取不依赖于流量通信和协议的任何具体内容或信息。因此,无论使用何种加密机制,都可以提取出与协议无关的数值特征。然而,由于有大量的协议无关的数值特征和不同的提取逻辑,提取过程是复杂的,耗时的,并需要先验知识。
-
1.4 Feature Set Selection(特征选择)
常用的特征选择方法可分为两类
-
基于领域专家的选择:
领域专家根据他们的经验和知识选择一组他们认为最合适的特征。之后,这些建议的特征将直接从数据集中提取,并用作模型输入。有一些常用的自动提取特征的工具(如CICFlowMeter)
然而,手动选择最重要的特性并不总是可靠的。可能存在人为错误,可能无法发现非直观的特征,这将极大地影响检测模型的性能。
注意,对于基于领域专家的选择,首先将选择特征,然后从流量中提取这组特征。 -
基于机器学习和一些算法的自选择:
它需要人类提取所有可能的特征,选择的算法将排名和选择最合适的特征作为最终的特征集,或者直接处理原始数据,自己学习和提取所需的特征。
然而,由于AI的黑箱特性,尤其是涉及到深度学习算法时,解释特征选择过程和提供特征被选择为最优的原因的可解释性是非常具有挑战性的。要解决上述问题还需要进一步的研究(XAI技术)。
1.5 Algorithms Selection(算法选择)
许多成熟的传统流量检测方法,如DPI,已不再适用于加密流量。目前,传统的机器学习方法和深度学习方法是该领域的两个主流研究方向。
- 传统机器学习方法:对于传统的机器学习,算法和特征集优化是主要关注的焦点。
- 深度学习方法:基于深度学习的加密流量检测有很多明显的优势,比如能够通过自身的特征学习自动提取所需的数据特征。它也更容易发现交通特征之间的非直观联系,这是人类无法做到的。然而,将深度学习应用于加密恶意流量检测和分类的研究有限。
2. 比较实验
在本节中,我们执行两个实验来评估我们的实验目标。
实验一:用不同的算法和特征集进行一系列的对比实验,为每个提出的现有工作找到一个更可靠、一致和公平的结果。通过筛选和分析公开数据集。作者策划了一个完全由公共数据集组成的数据集,这个数据集适用于加密恶意流量检测。
实验二:为了验证上述组合数据集比现有工作使用的数据集更加全面和客观,进行了跨数据集验证。此外,在加密恶意流量检测和分类方面,使用了该组合数据集对文中提到的相关工作之间进行公平的比较。实验二旨在提供一些关于协议无关的数值特征和协议特定的特征的性能哪个更好的见解,以及两者之间的优劣。
2.1 数据集的收集
组合的数据集基于三个标准组成:
1)结合广泛的公共数据集。这些数据集包含现有工作中加密的恶意和合法流量,如恶意软件捕获设施项目数据集和CICIDS2017数据集。
2)保证数据平衡。即恶意和合法网络流量的平衡,以及每个独立的公开数据集之间流量规模的平衡。
3)数据集包括传统设备和物联网设备的加密恶意和合法流量。因为这些设备越来越多地部署在相同的环境中,如办公室、家庭和其他智能城市设置。

2.2 特征提取与选择
(1)协议无关的数值特征:
1)FOS特征集包含14个特征(FOS Feature Set):由于不同的研究选择了不同的特征集,我们对这些研究中出现的协议无关的数值特征进行了统计分析,列出了高频出现的特征。在比较实验中,将列出的特征构造为一个特征集,称为进一步优化统计特征集(FOS)
2)前向序贯选择特征集(Top10 Ranked Features Feature Set):来自“A Distance-Based Method for Building an Encrypted Malware Traffic Identification Framework”的前10个排名特征特征集,这是使用增强的SFS算法在其检测框架中使用的前10个排名特征
3)侧信道特征集(Side Channel Feature Set):基于“Automatic Detection of V arious Malicious Traffic Using Side Channel Features on TCP Packets”的思想,其中包含五个基于包的特征。在我们的实验中,为了使用这个基于包的特征集与其他基于会话的特征集进行比较,我们选择在每个会话中只使用前15个包。这确保数据集包含尽可能多的数据变化,同时适用于基于包的特征集和基于会话的特征集。
4)抗篡改特性集(Tamper resistant Feature Set):基于“Malware traffic detection using tamper resistant features”思想,其中所选的特性不依赖于TCP有效负载信息或不包含端口和标志。
5)基于时间的特征集(Time Based Feature Set):基于“Detection of Tor Traffic using Deep Learning”的思想,这些时间序列相关的特征在研究中出现的频率很高。
(2)协议特定的特征
与数值特征选择类似,我们也对TLS/SSL特征进行了统计分析。创建了在许多作品中出现频率很高的TLS/SSL特性列表。该列表包含了SAN的DNS中的Server Name Indication (SNI) 、公共证书密钥的平均值、SAN中的平均域、公共证书密钥的STD等22个特性。我们将此TLS/SSL特性列表命名为进一步优化的TLS/SSL (FOTS)特性集。
由于这些特定于协议的特性只适用于与之相关的加密协议,因此在加密恶意流量检测和分类领域受到限制。因此,我们使用这个FOTS特征集与实验2中协议无关的数值特征集进行对比实验,以提供一些关于哪个特征集的性能更好的见解,以及两者之间的优劣。
我们将分析用与协议无关的数值特性替换TLS/SSL特性(特定于协议的特性)的潜力。

2.3 实验
实验设置:选取了10个常见的机器学习方法,参数除个别外均使用sklearn中默认参数
实验一:使用组合数据集的不同统计数值特征集和算法的性能分析
4个实验目标:
(1)分析使用相同特征集的不同算法的性能。
(2)分析使用相同算法的不同特征集的性能。
(3)使用此数据集识别最佳算法和特征集。
(4)用跨数据集验证来表明相比于单独使用数据集使用组合数据集进行模型训练的重要性。

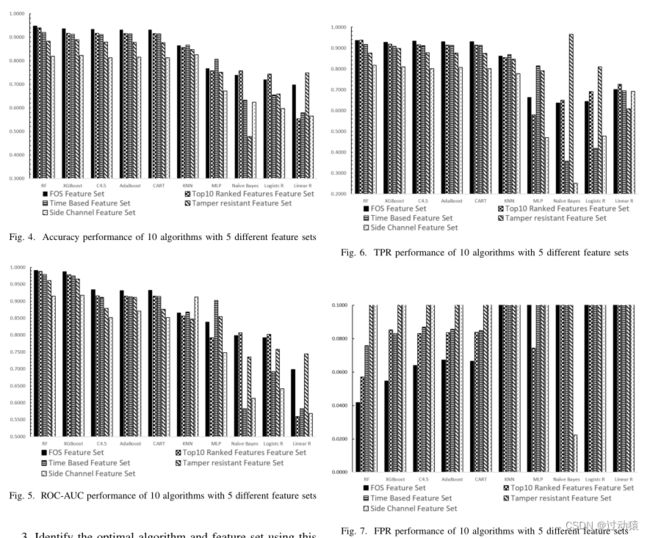
针对上述四个目标得到的结论:
(1)从图中可以看出,RF和XGBoost的ROC-AUC值都优于其他算法,且相对稳定。其中RF的效果最好最稳定。
(2)RF和XGBoost模型在图中一直表现良好。使用RF或XGBoost的FOS特征集可以同时实现TPR高于92%和FPR低于6%。在所有特征集中,使用RF、XGBoost、C4.5、AdaBoost和CART的FOS特征集能够获得最高的ROC-AUC和精度值。在KNN、MLP、Naive Bayes、Logistic R和Linear R模型中,其他四种特征集的ROC-AUC和精度最高,但性能均低于FOS特征集的前五种算法。
(3)RF的FOS特征集在TPR和FPR之间提供了更好的权衡。从实验第一和第二目标的分析结果可以看出,RF算法与FOS特征集的结合可以获得最佳的性能。
实验结果表明,将基于时间的特征和流量数值特征相结合的特征集相比单独使用两者可以提高模型的检出率。基于会话的特性或基于会话的特性与基于包的特性的组合很可能优于仅考虑基于包的特性的特性。
例如:FOS特征集和Top 10排名特征集都包含基于时间的特征和流量数值特征,但基于时间的特征集只包含基于时间的特征。
例如:在实验中,在五个特征集中,侧信道特征集的性能最差。我们认为这是因为侧信道特征集中的特征都是基于包的特征,例如有效载荷大小、包大小和有效载荷比。这些特征在值上可能无法明确区分恶意流量和合法流量,可能影响检测模型的性能。其他四种特征集的特征都是基于会话的特征,它们考虑的是多个报文序列,而不是单个报文。
(4)通过跨数据集的训练和测试实验,可以得出仅使用单一的公共数据集将缺乏对加密流量的多样性的检测能力的结论。因此使用组合数据集将非常有必要。
例如:当我们使用常规设备数据训练带有FOS特征集的射频模型,并使用物联网数据集作为测试集时,我们同时得到0个FPR和0个TPR。这说明在实验中,由常规设备数据训练的RF模型对物联网测试集几乎没有检测能力。

实验二:比较不确定协议的数值特征集和TLS/SSL特征集的性能
在第二个实验中,目的是评估和比较协议无关的数值特性和TLS/SSL特性的性能。由于TLS/SSL特性仅局限于通过这些协议加密的流量,因此我们使用的数据集仅包含TLS/SSL加密的流量。
我们应用FOTS特征集和FOS特征集,用十种不同的算法训练模型。

在RF、XGBoost等顶级性能算法中,无论使用ROC-AUC还是准确性,FOS特征集都比TLS/SSL特性具有更好的性能。因此,考虑用与协议无关的数值特征替换特定于协议的特征是可行的。那么,大多数关于加密恶意流量检测的研究将不再局限于HTTPs或任何特定协议,而是可以进行更全面的加密恶意流量分析。未来在不确定协议的数值特征上进行特征选择和优化的研究可能比协议特定的特征更有意义。
总结
学到的知识点
- 加密流量检测整体流程:
- Research Target:确定研究目标。
- Traffic Dataset Collection:交通数据集的采集。可通过两种方式采集:
真实的流量采集和模拟流量生成。
- Feature Selection/Feature extraction:特征选择/特征提取。
特征选择:首先从流量中提取所有可能的特征,然后自动选择特征,以获得最理想的特征集。
特征提取:首先进行特征选择,然后根据所选特征进行流量和特征提取。
- Algorithms Selection:算法选择。
- Experiment Evaluation:实验评估。
-
数据集:文中提到的组合数据集的下载链接
-
提取特征:
(1)不确定协议的数值特征:两种粒度(包粒度和会话粒度)+统计特征+特征子集。包粒度:在每个会话中选择前5到15个包可以获得更好的性能指标。
(2)协议特定的特征:zeek提取三个日志文件:conn.log文件、SSL.log文件、X509.log(证书日志)文件 -
机器学习方法中,RF和XGBoost的性能比较好。RF性能最好。
-
未来在不确定协议的数值特征上进行特征选择和优化的研究可能比协议特定的特征更有意义。