自动驾驶入门(八):YoloV3
YOLO definition
首先我们要了解什么是YOLO?
YOLO 是一种使用全卷积神经网络的实时目标检测算法,它是 You Only Look Once的缩写。与其他目标检测的算法相比,YOLO在一个网络模型中完成对图像中所有对象边界框和类别预测,避免了花费大量时间生成候选区域。它的强项是检测速度和识别能力,而不是完美地定位对象。
与目标识别算法不同,目标检测算法不仅需要预测目标的类标签,而且需要提供检测目标的位置。YOLO 算法对整个图像使用全卷积神经网络,将图像划分为多个网格区域,并预测每个区域目标的边界框和概率,而目标预测的概率则会随即用来对边界框的精确度加权,从而获得准确的边界框位置和尺寸。
现实生活中存在大量如封面街道图中的场景,无人驾驶汽车必须实时检测到周围所有对象的位置,才能让系统做出正确的决策和控制。YOLO 算法能够快速定位并分类不同的对象,并且让每个对象周围都有一个边界框和相应的分类标签。
在YOLO v3中存在一些重要概念,我会一一讲述。如果你一开始觉得疑惑,没有关系,我会在文章后半部分将这些知识串联并用代码展示,从而给你一个清晰的认识。
-
目标检测原理: 图像网格化(Grid cell),生成对象边界框(Bounding box),删除重叠边界框,交并比 IoU (Intersection over Union),非最大值抑制(non-maximum suppression),预测重叠对象(overlapping object),先验框(anchor box)
-
全卷积网络结构: 特征提取器Darknet-53,多尺度目标分类器,边界框回归(Regression),上采样(up-sampling),残差块(Resnet block),残差连接(skip connections)。
-
代码实现:载入预训练模型,执行目标检测
备注:YOLO v3是集v1,v2的大成之作,因此下文中会混合讲到YOLO v3/YOLO,这些技术在YOLO v3都会实现。
YOLO v3 Object detection principle
Sliding Windows vs Grid cell

在传统的目标检测技术如R-CNN中,普遍使用卷积滑动窗口来确定对象的类别和边界框的位置。这种方式可以将输入图像中的感兴趣区域,投射到卷积网络CNN 的更深层级的一组特征图中。
我们可以看看上图的例子。如在上图中,我们将16x16x3图像作为输入,通过多层卷积及池化网络(zero padding),获得深层网络的4x4x8特征图(features map)。我们只需将图像传入多个卷积和池化层一次,并使用生成的特征图分析输入图像的不同区域 ,便可以完成对全图中所有物体的检测与定位。这种技术使整个目标检测的过程更加有效。但是,此技术有一个缺点:边界框的位置不会非常准确。原因是给定大小的窗口和步幅不可能完全匹配图像中的对象,而且滑动窗口实施起来非常慢。
Joseph Redmon发现如果选择的步长使每个窗口都能覆盖图像的一个新区域并且没有重叠的话,速度会很快。因此作者在 YOLO中使用了网格化技术而不是传统的滑动窗口 。除此之外作者为了提高边界框的预测准确性,还使用了“交并比”和“非最大值抑制”两种技术,我会在下文对这些技术进行详细讲解。
Using a Grid

为了简化讨论,在上图中,我们使用 7x10 网格来讲解网格化技术。实际YOLO v3算法使用的网格更精细(对于416x416输入,最高使用52x52个网格),但是整体流程一样。
你可能会疑问,如何从网格中获得正确的边界框?
和滑动窗口的方法类似,我们可以向每个网格单元分配输出向量,使每个单元格都具有相关的向量,这个向量首先告诉我们该单元格中是否有对象,其次对象的类别是什么,最后是该对象的预测边界框。这样的话,边界框实际坐标不需要位于网格单元内,可以超出网格单元的范围。
Training on a Grid
作者将图像中某个对象的类别和边界框预测任务交与该对象中心位置所在的网格。这也可以被认为是一种很粗糙的区域推荐(region proposal)。在网格单元上训练需要一种非常特殊的训练数据,训练网络为每个单元格输出预测对象的类别得分和边界框向量,因此我们需要一个用于比较的正确标注。对于每个训练图像,我们需要将其划分为网格,并手动为每个网格单元分配一个正确标注。获得这些带网格单元标记的训练数据后,第二步是设计一个可以使用这些向量进行训练的 CNN 。在训练的时候,我们通过网格的方式告诉模型,图片中对象应该是由中心落在特定网格及其周围的某些像素组成,模型接收到这些信息后就会在网格周围尝试去寻找所有满足给定对象特征的像素,经过很多次带惩罚的尝试训练后,它就能找到这个准确的范围了。

我们来看下上图的例子。
上图中我们的示例中是 7x10 网格,每个网格单元具有相关的 8 维正确标注,因此我们的 CNN 输出层大小应该为 7x10x8。可以将其看做图像深度为 8 的7x10大小的标注数据。每个像素值的输出是一个 8 维向量(Pc,c1,c2,c3,x,y,w,h),而不是像 RGB 图像那样是长度为 3 的向量。这样的话,对于每个输入网格单元,在 CNN 的输出层中都有一个 8 维输出向量。
例如,当网络看到第一个网格单元时,它将在输出层左上角生成一个输出向量,接下来网络会依次看剩下的网格,并在输出层输出对应位置的向量。定义好这个输出形状后,我们可以使用图像和真实网格向量作为输入训练 CNN。训练 CNN 后,我们可以使用它检测并定位测试图像中的对象。接下来 我们将了解此方法如何生成准确的边界框。
Generate Bounding box
当 YOLO 看到一个用网格划分的图像时,如何查找正确的边界框?诀窍在于它将图像中一个对象的真实边界框,仅分配给训练图像中的一个网格单元,因此只有一个网格单元会定位图像。如何选择这个网格单元?对于每个训练图像,我们找到图像中每个对象的中点,然后将真实边界框分配给包含该中点的网格单元。

如在上图中,我们用黄色点表示的此人的中点,这个点包含在一个网格单元中。因此我们将真实边界框仅分配给这个网格单元,这个网格单元的正确标注如上图右侧所示。该标准向量将用于神经网络训练。请注意虽然另外两个网格单元也包含此人的一部分,但是它会被标注为不包含对象,即其 Pc 值为 0 。
其次值得注意的是在 YOLO v3/v2 算法中,x 和 y 确定的对象中心位置相对于当前网格单元的左上角的位置差。而边界框的w 和 h, 确定的是边界框相对于整个图像的宽和高。通常情况下,网格单元的左上角坐标是 (0,0) 或者右下角的坐标是 (1,1) ,因此在上图示例中 x= 0.5 y= 0.3 而预测边界框的宽度 w= 0.1(宽度大约是整个图像宽度的 10%), 高度 h =0.4 (高度大约是整个图像高度的 40%)。
注意,在这个体系中,所有边界框坐标值都在 0 和 1 之间,而边界框的宽度和高度可以大于网格单元的大小。这也被称为范围标准化,这使得算法变得更易于训练并收敛于更小的误差。在下文先验框(prior boxes)中我也会提到这一标准化过程。
Only one bounding box
基于网格的对象检测方法存在的一个问题是,当训练过的 CNN 遇到新的测试图像时,通常会生成多个网格单元向量。这些向量都尝试检测相同的对象,意味着有很多输出向量,全都包含同一对象的稍微不同的边界框。为了解决这一问题,我们使用一种叫做非最大值抑制的技巧,它会尝试查找一个最能匹配图像中对象的边界框。

接下来 我们将了解它是如何从一组边界框中查找最佳边界框的。
Intersection over Union (IoU)
交并比 (IOU) 用于在非最大值抑制中,比较给定对象的两个不同边界框的效果。
假设有这两个边界框 我们将这两个方框的交并比定义为:交集的面积除以并集的面积 。

在上图中这两个方框之间的交集用绿色方框表示,也就是这两个方框重叠的区域。并集区域用紫色区域表示。我们可以看到交集面积是 900 ,并集面积是 3000。方框的 IoU = 900/3000 即 0.3 。
IoU的上限为1,表示同一边界框,下限为0,表示两个边界框完全不相交。如下图所示:

Non-Maximal Suppression
对于拆分为网格的测试图像,网格 CNN 针对同一对象生成了多个网格单元向量和多个边界框,但其实我们只需要对应每个对象一个边界框。为此,我们将利用一种叫做非最大值抑制(Non-Maximal Suppression)的技巧,它会根据两个预测边界框之间的 IoU 选择最佳边界框。

在上图左边我们可以看到,位于对象上的三个网格有一个非零 Pc 值,表明它们都检测到对象和该对象的边界框。如果我们绘出每个网格单元预测的边界框以及 Pc 值,我们会看到右图同一对象有三个边界框,但是每个边界框的 Pc 值不同,第一个边界框的 Pc 值是 0.8, 第二个是 0.9, 最后一个是 0.7。Pc 是衡量检测到对象存在的置信指标,因此 Pc 值越高,对象检测的置信度越高,非最大值抑制仅选择 Pc 值最高的边界框。在此示例中 Pc 值最高的边界框是值为 0.9 的红色边界框,然后删除与刚刚所选的这个最佳边界框相比 IoU 值很高的所有边界框,这样的话就可以删除与红色边界框极为相似的边界框。最后剩下了一个边界框,对应的是最佳预测。所谓的非最大值抑制就是删除对象检测概率不是最大的重叠边界框。
值得注意的是,如果图像中有多个对象,则需要单独对每个类别应用非最大值抑制,比如有三个类别,则需要应用非最大值抑制三次。
非最大抑制步骤:
-
查看每个网格单元的输出向量。每个网格单元将具有一个带有Pc值和边界框坐标的输出矢量。
-
删除所有Pc值小于或等于某个阈值(例如0.5)的边界框。因此,如果有超过50%置信度,我们将保留这个边界框。
-
选择具有最高Pc值的边界框。
-
删除所有与当前编辑框具有高IoU 的边界框,并在最后一步中选中该框。
值得注意的是高IoU通常表示IoU大于或等于0.5。
我们已经成功预测了单一对象的唯一位置和边界框,但是如果我们需要预测多个重叠对象的边界框,我们该如何做?
Overlapping object
我们在上文中说过,图像中的每个对象都与一个网格单元相关联的情形,但是存在多个物体重叠呢?
一个网格单元实际上包含两个不同对象的中心点,这时候我们就需要先验框(prior boxes)。先验框可以帮助一个网格单元检测多个对象。
先验框从诞生开始一直被认为是高质量目标检测的关键,目前先进的目标检测系统可以做到为每个预测器创建数以千计的“锚框anchor boxes”或“先验框prior boxes” ,代表它专门预测对象的理想位置、形状和大小。
注意:锚框anchor boxes和先验框prior boxes都说的是同一类预先定义大小和宽高比,带有锚点的边界框。本文仅使用先验框prior boxes的说法,更更好理解它作为先验的含义。
先验框是一组预先准备的边界框,它是通过在COCO数据集上使用k均值聚类计算得到的。先验框固定在网格单元上,并且它们共享相同的质心。一旦我们定义了这些锚点,我们就可以确定真实值与先验框的重叠程度,并选择IOU最好的那一个。我们将预测边界框锚点距离当前网格单元左上角的的偏移量(此位置实际为网格的坐标值)以及边界框宽高相对整个图像的尺度。

在上图中,我们看到有一个人和一辆车重叠了,车的某些部分被遮挡了,更糟糕的是车辆和行人的边界框中心都位于相同的网格单元中 。之前我们说过每个网格单元的输出向量只能有一个类别,因此它必须选择车辆或行人。但是定义先验框后 我们可以创建一个更长的网格单元向量,使每个网格单元都可以与多个类别关联 。假设我们有两个具有初始宽高的先验框,先验框具有固定的宽高比,它们会尝试检测具有相近该宽高比并且可完美融入的对象。例如 因为我们要检测很宽的汽车和站着的行人,我们将定义一个形状大致是汽车形状的锚点框,这个方框的宽比高大,然后定义另一个能在里面填充站立行人的锚点框,高比宽大。现在修改每个网格单元的输出向量,以便包含这两个锚点框,其中包含坐标和类别得分。
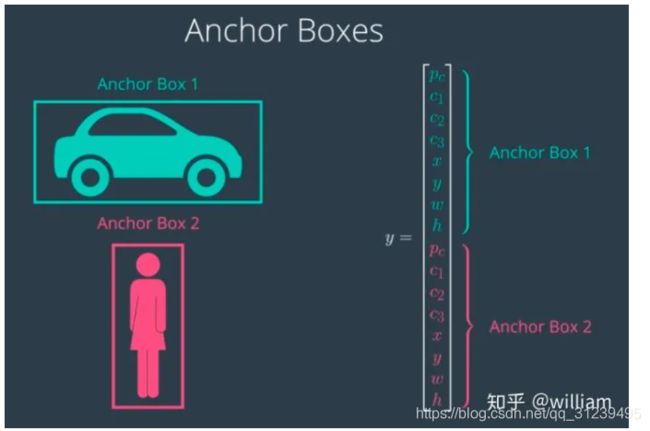
可以看到在上图右侧输出向量现在将包含 16 个元素,前 8 个元素对应先验框 1 ,后 8 个元素对应先验框 2 。因为汽车周围的边界框相对于先验框 1来说,IoU 更高,因此输出向量的先验框 1 元素将包含 汽车的类别和方框参数。同样,因为行人周围的边界框相对于先验框 2 来说 IoU 更高,先验框 2 将包含行人的类别和方框参数。
先验框能够算法识别人类都很难识别的场景中重叠的对象, 但是和很多对象检测方法一样,它也有局限性。假设有两个重叠的人 此算法将检查哪个人与先验框 1 相匹配,哪个人与先验框 2 相匹配,它只能将每种点框与一个对象相关联。如果两个重叠对象的形状大致一样,该算法效果就不太好。同样,如果你只定义了两个先验框,但是有三个重叠对象,那么此算法将失败, 因为它只能识别其中两个对象。好消息是这些情况很少见,其次YOLO v3具有三个尺度52x52,26x26,13x13下各三种形状的先验框,至少能在不同尺寸的网格中分别检测三个重叠的物体。

在下文讲完YOLO v3的网络结构后,我还会会详细介绍先验框的解码函数。
A Fully Convolution Neural Network
YOLO使用全卷积神经网络(FCN),所谓全卷积网络就是没有全连接层的CNN,优势在于支持不同大小的输入以及对全图进行端对端的训练,从而更好地学习上下文信息(context),非常适合于输出是图像的任务比如segmentation、edge detection、optical flow等。
YOLO v3的作者提出了一种新的、更深层次的特征提取器 Darknet-53架构。Darknet-53架构包含53个卷积层,每个卷积层之后是批标准化层和 Leaky ReLU 激活层。除此之外,Darknet-53借鉴了Resnet的思想,采用了大量残差块及残差连接,缓解了深层网络的梯度消散,打破了网络的对称性,从而提升了网络的表征能力。为了防止由于池化导致的低层级特征损失,作者并没有使用任何形式的池化层,而是使用步长为2的卷积层对特征图(feature maps)进行降采样。
Network Architecture
下图是Darknet-53的网络结构。备注: YOLO v3在使用时移除了全连接层。
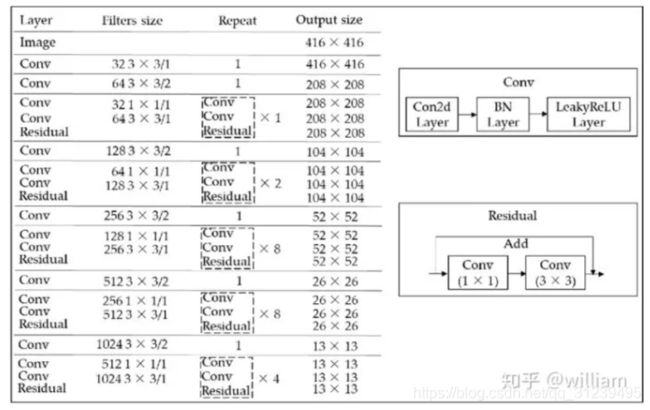
您也许会看到有些Darknet-53的网络结构图中使用256x256的输入层,这其实并不影响网络结构,但一般情况下大多数人都使用416x416的输入图像尺寸(coco dataset的图片尺寸),当然输入模型图像的尺寸在一定范围内越小越好,这样处理速度更快,但是必须注意它们都要是32的倍数。
YOLO v3将没有全连接层的特征提取器Darknet-53(0-74层)与多尺度检测器(75-106层)相结合,为了提高算法对小目标检测能力,YOLO v3中采用类似FPN的上采样和融合做法,从而实现了在多个尺度的特征图做目标检测。如在下图YOLO v3全网络结构中,YOLO v3有三条路径。
第一条路径:第74层网络经过多层卷积之后,对大尺寸物体进行检测(13x13conv)。
第二条路径:第83层连接了79层,第86层网络融合了第61层的特征图与第85层的上采样特征图,对中尺度物体进行检测(26x26conv)。
第三条路径:第95层连接了91层,第98层网络融合了第36层的特征图与第97层的上采样特征图,对小尺度物体进行检测(52x52conv)。
下图为YOLO的全部网络结构。

看懂这个图片需要较长的时间,在我的代码库中,在载入YOLO v3的权重文件后,可以打印网络结构,m.print_network()。结合上图,可以更清晰的了解YOLO v3的网络结构。备注:shortcut 对应残差连接。
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64
4 shortcut 1
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
8 shortcut 5
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
11 shortcut 8
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
15 shortcut 12
16 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
17 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
18 shortcut 15
19 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
20 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
21 shortcut 18
22 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
23 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
24 shortcut 21
25 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
26 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
27 shortcut 24
28 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
29 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
30 shortcut 27
31 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
32 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
33 shortcut 30
34 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
35 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
36 shortcut 33
37 conv 512 3 x 3 / 2 52 x 52 x 256 -> 26 x 26 x 512
38 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
39 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
40 shortcut 37
41 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
42 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
43 shortcut 40
44 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
45 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
46 shortcut 43
47 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
48 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
49 shortcut 46
50 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
51 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
52 shortcut 49
53 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
54 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
55 shortcut 52
56 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
57 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
58 shortcut 55
59 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
60 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
61 shortcut 58
62 conv 1024 3 x 3 / 2 26 x 26 x 512 -> 13 x 13 x1024
63 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
64 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
65 shortcut 62
66 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
67 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
68 shortcut 65
69 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
70 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
71 shortcut 68
72 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
73 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
74 shortcut 71
75 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
76 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
77 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
78 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
79 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
80 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
81 conv 255 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 255
82 detection
83 route 79
84 conv 256 1 x 1 / 1 13 x 13 x 512 -> 13 x 13 x 256
85 upsample * 2 13 x 13 x 256 -> 26 x 26 x 256
86 route 85 61
87 conv 256 1 x 1 / 1 26 x 26 x 768 -> 26 x 26 x 256
88 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
89 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
90 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
91 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
92 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
93 conv 255 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 255
94 detection
95 route 91
96 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128
97 upsample * 2 26 x 26 x 128 -> 52 x 52 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255
106 detection在这里我们需要对几个点进行研究:
output and anchor box
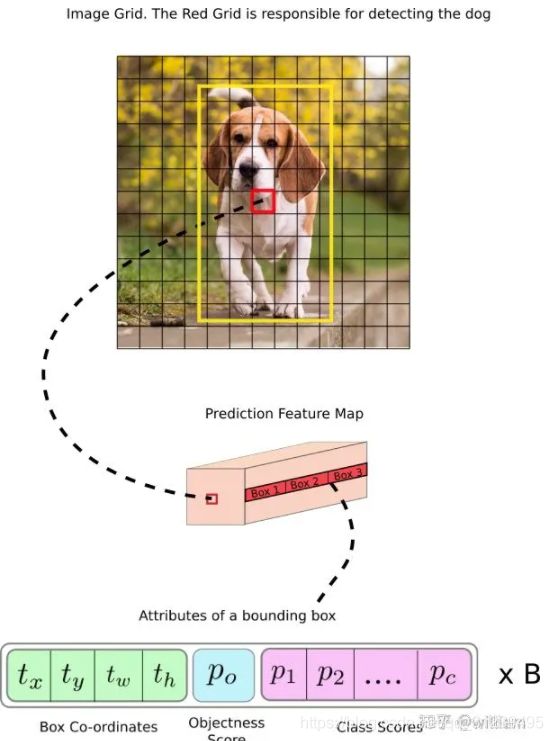
我们可以看到3条预测路径都是使用全卷积的结构,根据不同的输入尺寸,会得到3个不同大小的输出特征图,以YOLO v3的标准输入416x416x3为例,输出的特征图为13x13x255, 26x26x255, 52x52x255。你可能对这个感到疑惑,为什么输出的维度都是255。
原因在与YOLO v3特征图的每个网格,都配备了3个不同宽高比的先验框。对每个网格预测的输出结果是网络对3个先验框分别回归之后得到的3个边界框的信息的集合,每个边界框包括边界框位置(4维)、检测置信度(1维)、类别概率(80维)一共85维信息,因此一共有3×85 = 255个参数。
三个特征图一共可以解码出(52 x 52) + (26 x 26) + (13 x 13)) x 3= 10647个检测盒以及相应的类别、置信度。
再说YOLO v3的先验框。相对于YOLO v1直接回归边界框的实际宽、高,YOLO v2回归基于给定先验框的变化值,YOLO v3在YOLO v2的基础上,增加先验框的数量(5->9),并使用k-means对COCO数据集中的标签框进行聚类,得到类别中心点的9个框,宽高尺寸分别是 (10×13),(16×30),(33×23),(30×61),(62×45),(59× 119), (116 × 90), (156 × 198),(373 × 326) ,它们就是先验框的由来。值得注意的是,如果你想在自己独有的数据集上训练YOLO v3模型,你需要根据目标的大小,宽高比,以及图像的输入尺寸修改自己的先验框参数,实际操作中一般先使用k-means对标签框进行聚类,计算先验框的大小。
Bounding Box regression
YOLO v3网络预测对象的边界框是通过对先验框进行线性回归(微调)实现。

上文中我们提到,图像中边界框的bx 和b y参数代表对象中心位置距离当前网格单元的左上角的偏差量。而边界框的bw 和b h, 确定的是边界框相对于整个图像的宽和高比例。值得注意的是YOLO v3网络训练以及输出的前四项参数不是边界框的位置和尺寸bx,by, bw, bh,而是标准化的tx, ty, tw, th,需要经过下面的解码函数转换。
回归函数:

在上图中σ(tx), σ(ty)是基于矩形框中心点距离左上角网格点坐标的偏移量, sigma是激活函数,论文中作者使用sigmoid。pw, ph 是先验框的宽、高,通过上述公式,计算出实际预测框的宽高 bw, bh。
举个例子,假设在输入尺寸为416x416x3的情况下,我们在第二个特征图26x26x3x255中检测到一个对象的边界框为[4,3,2], 第二个特征图对应先验框为(30×61),(62×45),(59× 119),先验框中Cx=3,Cy=4, index=1,则取第二个先验框62x45的宽高作为pw,ph求出bw,bh。对于计算出来的bx,by需要乘以第二个特征图的降采样率16(416/26),就可以得到在416x416尺寸原图中真实的边界框x,y了。
也许有读者会疑问,为什么需要这个额外的解码转换函数?直接将真实的偏移量以及宽高的尺度比例输出不行吗?我们分两块解释。
-
偏移量
首先讨论为什么不用绝对坐标:边界框属性由彼此堆叠的单元格预测得出。绝对坐标对于目标置信度的阈值计算,添加对中心的网格偏移,应用锚点等都不方便。因此YOLO v3/v2不会预测边界框中心的绝对坐标,而是预测的偏移量。(备注:YOLO v1使用绝对坐标和尺寸,后续版本已经改进成偏移量和尺寸比例)
那为什么要对使用边界框使用解码函数?
YOLO v3神经网络通过学习偏移量,就可以通过预设的先验框去回归真实边界框。
但是偏移量并不是直接累加到当前网格的左上角上,而是首先需要根据特征图中的网格的尺寸进行 sigma标准化。这是为了防止预测得到的对象中心位置位于当前网格外,将位置值归一化到[0,1]区间。

我们可以看下面的例子,假设我们正在对红色网格进行预测,模型的预测输出值为(1.2,0.7),狗的中心点是(6.0,6.0),通过累加偏移量到原点的坐标,得到边界框中心位置位于13 x 13特征图上的(7.2,6.7),这不符合YOLO v3的设定。因此我们需要使用 sigma函数将输出压缩到0到1的范围内,从而有效的将对象中心保存在所预测的网格中。

-
对数尺度空间
在实际预测中, 由于图像中边界框的尺寸和长宽比变化很大,如果我们用卷积网络强行预测边界框的绝对尺寸,那么网络将很难收敛。因此我们使用相对原图宽高的比例来描述边界框的宽高。
那为什么我们还需要对数尺度空间呢?
原因在与将边界框的尺度缩放到对数空间,有助于降低训练的不稳定梯度。比如,原本我们可以通过对先验框的tw,th进行缩放微调得到bw,bh,由于bw,bh>0,那么必然要求卷积神经模型的输出tw, th>0,这就意味着给卷积神经模型加上了不等式约束。一个不等式约束的优化问题是无法用SGD,Adam解决的。

加上指数函数之后,我们可以看到不管预测的tw, th大于或者小于0,bw, bh永远大于0,这就可以有效的降低训练的不稳定梯度。
通过对输出应用对数空间转换,然后与先验框的宽高相乘就可以得到边界框的预测尺寸。
YOLO v3网络对于边界框的回归其实就是找到映射f使得先验框能够通过回归(平移和缩放)逼近真实值G。

Objectness Score and Class Confidences
Objectness Score 代表这个边界框中存在对象的概率。Class Confidences是指被检测的对象属于特定类别(如猫狗,汽车,行人等)的概率。在老的YOLO版本中,作者使用softmax来预测类别分数。然而在YOLO v3中作者使用了sigmoid激活函数,使得网络更加灵活。
这是由于softmax具有类别互斥性,即假设一个对象属于某一类,那必然不属于其他类。比如说如果数据集中同一网格预测对象有人和女人时,softmax就会失败,而sigmoid使用逻辑回归来预测,凡是高于给定阈值的任意类别的标签都可以被加入到边界框的属性中。换句话说,softmax所有类别的预测概率和为1,sigmoid可以不为1。
convolution 1x1 + 3x3
在 YOLO v3中,检测是通过在网络结构中三个不同位置的三种不同大小的特征图上应用1 × 1卷积内核来完成的。
除了此处之外模型中,存在大量的1x1卷积内核。其实这是为了实现跨通道的交互和信息整合,其次1x1卷积内核可以方便进行卷积核通道数的降维和升维,比如YOLO v3中先使用1x1 的卷积核将通道拉低,然后再用3x3的卷积核将通道拉回来,最后是1x1卷积内核可以在保持特征图尺寸不变(即不损失分辨率)的前提下大幅增加非线性特性。这种方式可以把网络做得很深。深层网络的特征提取和检测的效果相对浅层网络更好。而3x3卷积可以减少参数量,提高实时性。
Downsampling
三次检测分别都在原图进行32倍降采样(52x52x256),16倍降采样(26x26x512),8倍降采样(13x13x1024)后进行检测。降采样有助于防止由于池化导致的低层级特征损失。
Upsampling
众所周知,深层网络的特征表达效果很好。然而在32倍降采样后,特征图尺度变得很小,在这种情况下对于中小尺寸对象的识别上效果不好。因此我们在86层,97层分别使用了步长为2的上采样,逐步将特征图的尺寸拉回到了第61层,第36层的尺寸大小,随后融合了深层网络与浅层网络的信息,从而保留了一些原图中细小的特征,实现了对中小尺度物体的精确检测。如在第三条路径中,第36层的特征图(52x52x256)拼接第97层的特征图(52x52x128),最后得到第98层的特征图(52x52x128)。
YOLO v3 Algorithm steps
在这里我用封面街景图的例子来讲解YOLO v3目标检测的流程。
我们来看看 YOLO 如何接受输入图像并检测多个对象,假设有个 CNN 被训练成识别多个类别,包括交通信号灯 汽车,行人和卡车。我们为其提供多种不同类型的锚点框,如一个高的锚点框和一个宽的锚点框,使其能够处理形状不同的重叠对象。CNN 被训练后 我们可以向其提供新的测试图像并检测图像中的对象,测试图像首先被划分为网格,然后网络生成输出向量。每个网格单元对应一个向量,这些向量告诉我们某个单元中是否有对象,对象的类别是什么以及对象的边界框是什么。我们在每个尺度使用三个先验框,因此每个尺度下的各个网格单元都将有三个预测边界框,某些预测边界框的 Pc 值将很低,生成这些输出向量后 我们使用非最大值抑制删除不太有用的边界框。对于每个类别,非最大值抑制都会删除 Pc 值低于某个给定阈值的边界框,然后选择 Pc 值最高的边界框,并删除与该边界框非常相似的边界框。它将重复这一流程,直到删除所有类别的非最大值抑制边界框。
最终结果将如下图所示,可以看出 YOLO v3 有效地检测出图像中包括汽车和行人在内的很多对象。

YOLO v3 code implementation
我们来看下YOLO v3的目标预测函数(基于pytorch):
def detect_objects(model, img, iou_thresh, nms_thresh):
start = time.time()
# Set the model to evaluation mode.
model.eval()
# Convert the image from a NumPy ndarray to a PyTorch Tensor of the correct shape.
# The image is transposed, then converted to a FloatTensor of dtype float32, then
# Normalized to values between 0 and 1, and finally unsqueezed to have the correct
# shape of 1 x 3 x 416 x 416
img = torch.from_numpy(img.transpose(2,0,1)).float().div(255.0).unsqueeze(0)
# Feed the image to the neural network with the corresponding NMS threshold.
# The first step in NMS is to remove all bounding boxes that have a very low
# probability of detection. All predicted bounding boxes with a value less than
# the given NMS threshold will be removed.
list_boxes = model(img, nms_thresh)
# Make a new list with all the bounding boxes returned by the neural network
boxes = list_boxes[0][0] + list_boxes[1][0] + list_boxes[2][0]
# Perform the second step of NMS on the bounding boxes returned by the neural network.
# In this step, we only keep the best bounding boxes by eliminating all the bounding
# boxes whose IOU value is higher than the given IOU threshold
boxes = nms(boxes, iou_thresh)
# Stop the time.
finish = time.time()
# Print the time it took to detect objects
print('\n\nIt took {:.3f}'.format(finish - start), 'seconds to detect the objects in the image.\n')
# Print the number of objects detected
print('Number of Objects Detected:', len(boxes), '\n')
return boxes再让我们看下NMS非最大值抑制的实现:
def nms(boxes, iou_thresh):
# If there are no bounding boxes do nothing
if len(boxes) == 0:
return boxes
# Create a PyTorch Tensor to keep track of the detection confidence
# of each predicted bounding box
det_confs = torch.zeros(len(boxes))
# Get the detection confidence of each predicted bounding box
for i in range(len(boxes)):
det_confs[i] = boxes[i][4]
# Sort the indices of the bounding boxes by detection confidence value in descending # order.
# We ignore the first returned element since we are only interested in the sorted # indices
_,sortIds = torch.sort(det_confs, descending = True)
# Create an empty list to hold the best bounding boxes after
# Non-Maximal Suppression (NMS) is performed
best_boxes = []
# Perform Non-Maximal Suppression
for i in range(len(boxes)):
# Get the bounding box with the highest detection confidence first
box_i = boxes[sortIds[i]]
# Check that the detection confidence is not zero
if box_i[4] > 0:
# Save the bounding box
best_boxes.append(box_i)
# Go through the rest of the bounding boxes in the list and calculate their
# IOU with respect to the previous selected box_i.
for j in range(i + 1, len(boxes)):
box_j = boxes[sortIds[j]]
# If the IOU of box_i and box_j is higher than the given IOU threshold set
# box_j's detection confidence to zero.
if boxes_iou(box_i, box_j) > iou_thresh:
box_j[4] = 0
return best_boxesConclusion
YOLO v3 具有极强的速度优势,改进的Darknet-53模型大幅提升了模型精度,同时在多个尺度上对目标进行检测,增强了对小目标及重叠遮挡目标的识别,在速度和精度上的表现都很均衡,因此被广泛应用在工业界。
原文链接:
yolo详解原文