Transformer源码理解(Tensorflow)
主要是留给自己以后回忆用的,写的不好,评论区不要开炮,Love&Peace。
源码:https://github.com/Kyubyong/transformer
本文参考博文内容:(细节参考在每一节)
NLP系列——Transformer源码解析(TensorFlow版)
论文解读:Attention is All you need
图解Transformer(完整版)
Transformer解析与tensorflow代码解读
Transformer源码解读
FlyAI小课堂:代码解读Transformer--Attention is All You Need
非常感谢以上大佬!
代码
hparams.py
import argparse class Hparams: parser = argparse.ArgumentParser() # prepro parser.add_argument('--vocab_size', default=32000, type=int) # train ## files parser.add_argument('--train1', default='iwslt2016/segmented/train.de.bpe', help="german training segmented data") parser.add_argument('--train2', default='iwslt2016/segmented/train.en.bpe', help="english training segmented data") parser.add_argument('--eval1', default='iwslt2016/segmented/eval.de.bpe', help="german evaluation segmented data") parser.add_argument('--eval2', default='iwslt2016/segmented/eval.en.bpe', help="english evaluation segmented data") parser.add_argument('--eval3', default='iwslt2016/prepro/eval.en', help="english evaluation unsegmented data") ## vocabulary parser.add_argument('--vocab', default='iwslt2016/segmented/bpe.vocab', help="vocabulary file path") # training scheme parser.add_argument('--batch_size', default=128, type=int) parser.add_argument('--eval_batch_size', default=128, type=int) parser.add_argument('--lr', default=0.0003, type=float, help="learning rate") parser.add_argument('--warmup_steps', default=4000, type=int) # 预热学习率 parser.add_argument('--logdir', default="log/1", help="log directory") # 日志存储路径 parser.add_argument('--num_epochs', default=20, type=int) parser.add_argument('--evaldir', default="eval/1", help="evaluation dir") # model parser.add_argument('--d_model', default=512, type=int, help="hidden dimension of encoder/decoder") # 词嵌入维度 parser.add_argument('--d_ff', default=2048, type=int, help="hidden dimension of feedforward layer") # 前向传播网络隐层单元数量 parser.add_argument('--num_blocks', default=6, type=int, help="number of encoder/decoder blocks") # blocks的数量 parser.add_argument('--num_heads', default=8, type=int, help="number of attention heads") # 多头注意力 “头”的数量 parser.add_argument('--maxlen1', default=100, type=int, help="maximum length of a source sequence") # 源句最大长度 parser.add_argument('--maxlen2', default=100, type=int, help="maximum length of a target sequence") # 目标句最大长度 parser.add_argument('--dropout_rate', default=0.3, type=float) # dropout丢弃概率 parser.add_argument('--smoothing', default=0.1, type=float, help="label smoothing rate") # 平滑率 # test parser.add_argument('--test1', default='iwslt2016/segmented/test.de.bpe', help="german test segmented data") parser.add_argument('--test2', default='iwslt2016/prepro/test.en', help="english test data") parser.add_argument('--ckpt', help="checkpoint file path") # 保存checkpoint的地址 parser.add_argument('--test_batch_size', default=128, type=int) parser.add_argument('--testdir', default="test/1", help="test result dir")
定义了一些与训练、词汇表、模型、测试相关的超参数。
argparse库
用于命令项选项与参数解析的模块。
一般为三个步骤:
- 创建 ArgumentParser() 对象
- 调用 add_argument() 方法添加参数
- 使用 parse_args() 解析添加的参数
参考:python学习笔记之argparse库的使用
train.py
import tensorflow as tf
from model import Transformer
from tqdm import tqdm
from data_load import get_batch
from utils import save_hparams, save_variable_specs, get_hypotheses, calc_bleu
import os
from hparams import Hparams
import math
import logging
logging.basicConfig(level=logging.INFO)
logging日志库
记录日志信息,见参考链接。
参考:logging的简单介绍
读取超参数
logging.info("# hparams")
hparams = Hparams()
parser = hparams.parser
hp = parser.parse_args()
save_hparams(hp, hp.logdir)利用Hparmas类实例化一个对象,获取其中参数,并将参数信息写为日志保存到logdir路径中。
准备训练/评估的批数据
logging.info("# Prepare train/eval batches")
train_batches, num_train_batches, num_train_samples = get_batch(hp.train1, hp.train2,
hp.maxlen1, hp.maxlen2,
hp.vocab, hp.batch_size,
shuffle=True)
eval_batches, num_eval_batches, num_eval_samples = get_batch(hp.eval1, hp.eval2,
100000, 100000,
hp.vocab, hp.batch_size,
shuffle=False)
# create a iterator of the correct shape and type
iter = tf.data.Iterator.from_structure(train_batches.output_types, train_batches.output_shapes)
xs, ys = iter.get_next()
train_init_op = iter.make_initializer(train_batches)
eval_init_op = iter.make_initializer(eval_batches)调用data_load中的get_batch函数,得到batch数据。
使用给定结构创建一个新的未初始化的迭代器Iterator,且未绑定到特定的数据集。
后续使用make_initializer()绑定特定数据集。
使用模型进行训练与评估
logging.info("# Load model")
m = Transformer(hp)
loss, train_op, global_step, train_summaries = m.train(xs, ys)
y_hat, eval_summaries = m.eval(xs, ys)向Transformer类中传递hp参数,实例化出模型对象。
用模型中的方法,根据数据集进行训练、评估。
训练
with tf.Session() as sess:
ckpt = tf.train.latest_checkpoint(hp.logdir) # 查找最新保存的checkpoint文件,读取模型保存好的参数
if ckpt is None: # 可能没有检查点
logging.info("Initializing from scratch") # 日志记录,从头开始初始化
sess.run(tf.global_variables_initializer()) # 初始化变量
save_variable_specs(os.path.join(hp.logdir, "specs")) # 存储变量相关的信息,如变量名、大小、参数数量等
else:
saver.restore(sess, ckpt) # 有检查点的话,恢复保存先前的变量,不必从头初始化
summary_writer = tf.summary.FileWriter(hp.logdir, sess.graph) # 保存训练过程数据的实例
sess.run(train_init_op) # 开始训练
total_steps = hp.num_epochs * num_train_batches # 训练需要的循环次数
_gs = sess.run(global_step)
for i in tqdm(range(_gs, total_steps+1)): # 训练
_, _gs, _summary = sess.run([train_op, global_step, train_summaries])
epoch = math.ceil(_gs / num_train_batches) # 向上取整,计算epoch
summary_writer.add_summary(_summary, _gs) # 保存训练过程数据
if _gs and _gs % num_train_batches == 0: # 根据当前进度,记录日志信息
logging.info("epoch {} is done".format(epoch)) # 代数
_loss = sess.run(loss) # train loss # 计算训练损失
logging.info("# test evaluation")
_, _eval_summaries = sess.run([eval_init_op, eval_summaries]) # 评估效果
summary_writer.add_summary(_eval_summaries, _gs)
logging.info("# get hypotheses")
hypotheses = get_hypotheses(num_eval_batches, num_eval_samples, sess, y_hat, m.idx2token) # 获取假设
logging.info("# write results") # 记录结果信息
model_output = "iwslt2016_E%02dL%.2f" % (epoch, _loss)
if not os.path.exists(hp.evaldir): os.makedirs(hp.evaldir)
translation = os.path.join(hp.evaldir, model_output)
with open(translation, 'w') as fout:
fout.write("\n".join(hypotheses))
logging.info("# calc bleu score and append it to translation") # 计算BLEU分数
calc_bleu(hp.eval3, translation)
logging.info("# save models") # 保存模型相关参数信息,
ckpt_name = os.path.join(hp.logdir, model_output)
saver.save(sess, ckpt_name, global_step=_gs)
logging.info("after training of {} epochs, {} has been saved.".format(epoch, ckpt_name))
logging.info("# fall back to train mode")
sess.run(train_init_op) # 继续训练
summary_writer.close()参考:
- tf.train.latest_checkpoint()
- Tensorflow模块:tf.train.Checkpoint
- tf.summary.FileWriter用法
data_load.py
与数据加载相关的一些函数。
load_vocab
get_batch→load_data→input_fn→generator_fn→encoder
注:变量名后缀为1表示为与源句相关,为2与目标句相关。如:fpath1源语句文件路径,fpath2目标语句文件路径
load_vocab(vocab_fpath)
import tensorflow as tf
from utils import calc_num_batches
def load_vocab(vocab_fpath): # 加载词汇表
'''Loads vocabulary file and returns idx<->token maps
vocab_fpath: string. vocabulary file path.
Note that these are reserved
0: , 1: , 2: , 3:
Returns
two dictionaries.
'''
vocab = [line.split()[0] for line in open(vocab_fpath, 'r').read().splitlines()] # list comprehension实现 每次读一行,去空格得单词
token2idx = {token: idx for idx, token in enumerate(vocab)} # 利用迭代器,返回索引与对应数据
idx2token = {idx: token for idx, token in enumerate(vocab)}
return token2idx, idx2token
生成词汇表字典,满足索引→单词,单词→索引两个需求。
get_batch(fpath1, fpath2, maxlen1, maxlen2, vocab_fpath, batch_size, shuffle=False)
def get_batch(fpath1, fpath2, maxlen1, maxlen2, vocab_fpath, batch_size, shuffle=False):
'''Gets training / evaluation mini-batches
fpath1: source file path. string.
fpath2: target file path. string.
maxlen1: source sent maximum length. scalar.
maxlen2: target sent maximum length. scalar.
vocab_fpath: string. vocabulary file path.
batch_size: scalar
shuffle: boolean
Returns
batches
num_batches: number of mini-batches
num_samples
'''
sents1, sents2 = load_data(fpath1, fpath2, maxlen1, maxlen2) # 读取数据
batches = input_fn(sents1, sents2, vocab_fpath, batch_size, shuffle=shuffle)
num_batches = calc_num_batches(len(sents1), batch_size)
return batches, num_batches, len(sents1)生成批数据。
load_data(fpath1, fpath2, maxlen1, maxlen2)
def load_data(fpath1, fpath2, maxlen1, maxlen2):
'''Loads source and target data and filters out too lengthy samples.
fpath1: source file path. string.
fpath2: target file path. string.
maxlen1: source sent maximum length. scalar.
maxlen2: target sent maximum length. scalar.
Returns
sents1: list of source sents
sents2: list of target sents
'''
sents1, sents2 = [], []
with open(fpath1, 'r') as f1, open(fpath2, 'r') as f2:
for sent1, sent2 in zip(f1, f2): # zip将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
# 换句话说,每一次循环,sent1和sent2读取一对源语句+目标语句
if len(sent1.split()) + 1 > maxlen1: continue # 1:
if len(sent2.split()) + 1 > maxlen2: continue # 1:
# 如果源语句/目标语句大于设定的长度,直接过滤掉不加入到列表中。
# 这里+1是因为也占一位。
sents1.append(sent1.strip()) # 删除字符串前后空格,加入列表
sents2.append(sent2.strip())
return sents1, sents2将所有满足要求的句子加入到列表中,返回,相当于过滤出可以使用的数据,返回到get_batch中给Input_fn用。
语句由结尾,因此需要+1。
结尾的必要性(和代码没关系,只是复习一下之前学过的知识,可以不看这句):在n-gram中,需要用到使其成为真正的概率分布。如果没有结束符号,所有给定句子长度的句子概率之和需要为1,则模型将定义一个无限的概率分布集合,每个句子都有一个分布。
参考:《Speech and Language Processing》Chapter3 P4
input_fn(sents1, sents2, vocab_fpath, batch_size, shuffle=False)
def input_fn(sents1, sents2, vocab_fpath, batch_size, shuffle=False):
'''Batchify data
sents1: list of source sents
sents2: list of target sents
vocab_fpath: string. vocabulary file path.
batch_size: scalar
shuffle: boolean
'''
shapes = (([None], (), ()),
([None], [None], (), ()))
types = ((tf.int32, tf.int32, tf.string),
(tf.int32, tf.int32, tf.int32, tf.string))
paddings = ((0, 0, ''),
(0, 0, 0, ''))
dataset = tf.data.Dataset.from_generator(
generator_fn,
output_shapes=shapes,
output_types=types,
args=(sents1, sents2, vocab_fpath)) # <- arguments for generator_fn. converted to np string arrays
if shuffle: # for training
dataset = dataset.shuffle(128*batch_size)
dataset = dataset.repeat() # 无限次重复
dataset = dataset.padded_batch(batch_size, shapes, paddings).prefetch(1)
return dataset载入数据一般使用numpy、tensors或者是placeholder,但当一个数组中元素的长度不相同时,使用generator更有效。
tensorflow tf.data.Dataset.from_generator:
利用generator_fn函数,生成数据。
- output_shapes 可选参数,但也建议填写,设置为None说明可变或未知。
- output_types 必选参数。
<未解决>为什么是128*batch_size (猜测:mini-batch的个数硬编码为128,每个batch的大小为bach_size,总数据128*128,但感觉不太靠谱,姑且这么认为)
数据训练时需要先经过shuffle,评估时不需要。
shuffle
shuffle(
buffer_size, seed=None, reshuffle_each_iteration=None
)随机重新排列数据集元素,用buffrer_size个元素来填充缓冲区,从缓冲区中随机采样元素(达到shuffle效果),采样后缓冲区中元素大小会不足buffer_size个,从数据集中顺序选择下一个元素进行空位的补充。
repeat
repeat(
count=None
)如果指定了count,dataset重复count次,没指定就是无限重复。 repeat的次数相当于epoch的个数。
batch
batch(
batch_size, drop_remainder=False, num_parallel_calls=None, deterministic=None
)padded_batch
padded_batch(
batch_size, padded_shapes=None, padding_values=None, drop_remainder=False
)参考:
- 如何使用TensorFlow中的Dataset API
- from_generator() 官方文档
- TensorFlow dataset.shuffle、batch、repeat用法
- tf.data.Dataset.shuffle(buffer_size)中buffer_size的理解
- tf.data: Build TensorFlow input pipelines
- tensorflow dataset.shuffle dataset.batch dataset.repeat 理解 注意点
- 【进阶Python】第五讲:迭代器与生成器
- TensorFlow的Dataset的padded_batch使用
generator_fn(sents1, sents2, vocab_fpath)
def generator_fn(sents1, sents2, vocab_fpath):
'''Generates training / evaluation data
生成训练/评估集数据
sents1: list of source sents
sents2: list of target sents
vocab_fpath: string. vocabulary file path.
yields
xs: tuple of
x: int32 tensor. (N, T1) N个句子,每个句子长度都是T1(被补全)
x_seqlens: int32 tensor. (N,) N个句子的长度
sents1: str tensor. (N,) N个句子
ys: tuple of
decoder_input: int32 tensor. (N, T2) N个句子,每个句子长度都是T2
y: int32 tensor. (N, T2) N个句子,每个长度都是T2
y_seqlen: int32 tensor. (N, ) N个句子,每个句子的长度
sents2: str tensor. (N,) N个句子
'''
token2idx, _ = load_vocab(vocab_fpath)
for sent1, sent2 in zip(sents1, sents2):
x = encode(sent1, "x", token2idx)
y = encode(sent2, "y", token2idx)
decoder_input, y = y[:-1], y[1:] # decoder_input舍去 y舍去
x_seqlen, y_seqlen = len(x), len(y) # 获取源句目标句序列长度
yield (x, x_seqlen, sent1), (decoder_input, y, y_seqlen, sent2)将输入的列表(列表里装的都是一个个str),用encode函数编码成对应的数字序列。
<未解决>x的T1是什么时候被补全的,又或者说什么时候变成T1的。
联想RNN:
- decoder_input,输入到解码器中。去掉,解码前N-1个词。
- y,期望输出第2个到第N个。
yield:见参考链接
参考:python中yield的用法详解——最简单,最清晰的解释
encode(inp, type, dict)
def encode(inp, type, dict):
'''Converts string to number. Used for `generator_fn`.
inp: 1d byte array. 由token(str)组成的句子
type: "x" (source side) or "y" (target side) 源/目标
dict: token2idx dictionary
Returns
list of numbers
'''
inp_str = inp.decode("utf-8")
# 以 encoding 指定的编码格式解码字符串。默认编码为字符串编码
if type=="x": tokens = inp_str.split() + [""]
else: tokens = [""] + inp_str.split() + [""]
# 目标句需要在开头加一个,标识句子的开头
x = [dict.get(t, dict[""]) for t in tokens]
# 未找到则标记代表的索引
return x 利用token2index,将string转换成数字序列。
注意:这里在处理的时候如果是目标句,需要在开始和结尾处加上和,传回generator_fn的时候会根据需要舍弃开头或结尾符。
model.py
模型的主体部分。
import tensorflow as tf
from data_load import load_vocab
from modules import get_token_embeddings, ff, positional_encoding, multihead_attention, label_smoothing, noam_scheme
from utils import convert_idx_to_token_tensor
from tqdm import tqdm
import logging
logging.basicConfig(level=logging.INFO)用到的库,及日志的设置。
__init__(self, hp)
class Transformer:
'''
xs: tuple of
x: int32 tensor. (N, T1)
x_seqlens: int32 tensor. (N,)
sents1: str tensor. (N,)
ys: tuple of
decoder_input: int32 tensor. (N, T2)
y: int32 tensor. (N, T2)
y_seqlen: int32 tensor. (N, )
sents2: str tensor. (N,)
training: boolean.
'''
def __init__(self, hp):
self.hp = hp
self.token2idx, self.idx2token = load_vocab(hp.vocab)
self.embeddings = get_token_embeddings(self.hp.vocab_size, self.hp.d_model, zero_pad=True) # (V,E)
获取超参数、两个字典、构建词嵌入矩阵。
encode(self, xs, training=True)
def encode(self, xs, training=True):
'''
Returns
memory: encoder outputs. (N, T1, d_model)
'''
with tf.variable_scope("encoder", reuse=tf.AUTO_REUSE):
x, seqlens, sents1 = xs # 被补全的句子,句子长度,原句
# src_masks 源句掩码
src_masks = tf.math.equal(x, 0) # (N, T1) 掩码,标记补全位置
# embedding 嵌入
enc = tf.nn.embedding_lookup(self.embeddings, x) # (N, T1, d_model) # 词嵌入 Input Embedding
enc *= self.hp.d_model**0.5 # scale 对enc缩放,但是原论文中没有发现相关内容
enc += positional_encoding(enc, self.hp.maxlen1) # 位置嵌入
enc = tf.layers.dropout(enc, self.hp.dropout_rate, training=training) #Dropout 防止过拟合
# 截止现在输入已被嵌入完毕
## Blocks Encoder 块
for i in range(self.hp.num_blocks): # 设定的Encoder块
with tf.variable_scope("num_blocks_{}".format(i), reuse=tf.AUTO_REUSE): #当前是第几个Encoder块
# self-attention 多头注意力机制
enc = multihead_attention(queries=enc,
keys=enc,
values=enc,
key_masks=src_masks,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=False) # 多头注意力机制
# feed forward 前向传播
enc = ff(enc, num_units=[self.hp.d_ff, self.hp.d_model])
memory = enc # 记住当前进度
return memory, sents1, src_masksmask作用:
在positional_encoding函数中也有体现
这里的mask是Padding mask,比较短的句子后面会直接补0。由 于在Attention机制中,补充的位置不需要被关注,将位置值加上一个非常大的负数(-2^32+1),经过softmax的时候概率较小。
参考:tf.AUTO_REUSE作用
decode(self, ys, memory, src_masks, training=True)
def decode(self, ys, memory, src_masks, training=True):
'''
memory: encoder outputs. (N, T1, d_model)
src_masks: (N, T1)
Returns
logits: (N, T2, V). float32.
y_hat: (N, T2). int32
y: (N, T2). int32
sents2: (N,). string.
'''
with tf.variable_scope("decoder", reuse=tf.AUTO_REUSE):
decoder_inputs, y, seqlens, sents2 = ys
# tgt_masks
tgt_masks = tf.math.equal(decoder_inputs, 0) # (N, T2)
# embedding
dec = tf.nn.embedding_lookup(self.embeddings, decoder_inputs) # (N, T2, d_model)
dec *= self.hp.d_model ** 0.5 # scale
dec += positional_encoding(dec, self.hp.maxlen2)
dec = tf.layers.dropout(dec, self.hp.dropout_rate, training=training)
# Blocks
for i in range(self.hp.num_blocks):
with tf.variable_scope("num_blocks_{}".format(i), reuse=tf.AUTO_REUSE):
# Masked self-attention (Note that causality is True at this time)
dec = multihead_attention(queries=dec,
keys=dec,
values=dec,
key_masks=tgt_masks,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=True,
scope="self_attention")
# Vanilla attention
dec = multihead_attention(queries=dec,
keys=memory,
values=memory,
key_masks=src_masks,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=False,
scope="vanilla_attention")
### Feed Forward
dec = ff(dec, num_units=[self.hp.d_ff, self.hp.d_model])
# Final linear projection (embedding weights are shared)
weights = tf.transpose(self.embeddings) # (d_model, vocab_size)
logits = tf.einsum('ntd,dk->ntk', dec, weights) # (N, T2, vocab_size)
y_hat = tf.to_int32(tf.argmax(logits, axis=-1))
return logits, y_hat, y, sents2train(self, xs, ys)
def train(self, xs, ys):
'''
Returns
loss: scalar.
train_op: training operation
global_step: scalar.
summaries: training summary node
'''
# forward 前向
memory, sents1, src_masks = self.encode(xs) # 编码
logits, preds, y, sents2 = self.decode(ys, memory, src_masks) # 解码
# train scheme
y_ = label_smoothing(tf.one_hot(y, depth=self.hp.vocab_size)) # 平滑标签
ce = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=y_) # softmax分类
nonpadding = tf.to_float(tf.not_equal(y, self.token2idx[""])) # 0:
loss = tf.reduce_sum(ce * nonpadding) / (tf.reduce_sum(nonpadding) + 1e-7)
global_step = tf.train.get_or_create_global_step()
lr = noam_scheme(self.hp.lr, global_step, self.hp.warmup_steps)
optimizer = tf.train.AdamOptimizer(lr)
train_op = optimizer.minimize(loss, global_step=global_step)
tf.summary.scalar('lr', lr)
tf.summary.scalar("loss", loss)
tf.summary.scalar("global_step", global_step)
summaries = tf.summary.merge_all()
return loss, train_op, global_step, summaries eval(self, xs, ys)
def eval(self, xs, ys):
'''Predicts autoregressively
At inference, input ys is ignored.
Returns
y_hat: (N, T2)
'''
decoder_inputs, y, y_seqlen, sents2 = ys
decoder_inputs = tf.ones((tf.shape(xs[0])[0], 1), tf.int32) * self.token2idx[""]
ys = (decoder_inputs, y, y_seqlen, sents2)
memory, sents1, src_masks = self.encode(xs, False)
logging.info("Inference graph is being built. Please be patient.")
for _ in tqdm(range(self.hp.maxlen2)):
logits, y_hat, y, sents2 = self.decode(ys, memory, src_masks, False)
if tf.reduce_sum(y_hat, 1) == self.token2idx[""]: break
_decoder_inputs = tf.concat((decoder_inputs, y_hat), 1)
ys = (_decoder_inputs, y, y_seqlen, sents2)
# monitor a random sample
n = tf.random_uniform((), 0, tf.shape(y_hat)[0]-1, tf.int32)
sent1 = sents1[n]
pred = convert_idx_to_token_tensor(y_hat[n], self.idx2token)
sent2 = sents2[n]
tf.summary.text("sent1", sent1)
tf.summary.text("pred", pred)
tf.summary.text("sent2", sent2)
summaries = tf.summary.merge_all()
return y_hat, summaries
modules.py
构建Transformer模型需要的函数。
import numpy as np
import tensorflow as tfln(inputs, epsilon = 1e-8, scope="ln")
Layer Normalization
epsilon防止分母过小
def ln(inputs, epsilon = 1e-8, scope="ln"):
'''Applies layer normalization. See https://arxiv.org/abs/1607.06450.
inputs: A tensor with 2 or more dimensions, where the first dimension has `batch_size`.
epsilon: A floating number. A very small number for preventing ZeroDivision Error.
scope: Optional scope for `variable_scope`.
Returns:
A tensor with the same shape and data dtype as `inputs`.
'''
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
inputs_shape = inputs.get_shape() # 输入形状
params_shape = inputs_shape[-1:] #
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True) # 求均值和方差
beta= tf.get_variable("beta", params_shape, initializer=tf.zeros_initializer())
gamma = tf.get_variable("gamma", params_shape, initializer=tf.ones_initializer())
normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) )
outputs = gamma * normalized + beta
return outputs
参考:tf.nn.moments( ) 的用法
get_token_embeddings(vocab_size, num_units, zero_pad=True)
def get_token_embeddings(vocab_size, num_units, zero_pad=True):
'''Constructs token embedding matrix.000000.
Note that the column of index 0's are set to zeros.
vocab_size: scalar. V. 词汇表词汇量V
num_units: embedding dimensionalty. E. 嵌入维度E
zero_pad: Boolean. If True, all the values of the first row (id = 0) should be constant zero
To apply query/key masks easily, zero pad is turned on.
设置后嵌入矩阵第一行皆为0
Returns
weight variable: (V, E)
'''
with tf.variable_scope("shared_weight_matrix"):
embeddings = tf.get_variable('weight_mat',
dtype=tf.float32,
shape=(vocab_size, num_units),
initializer=tf.contrib.layers.xavier_initializer())
# 利用xavier初始化方法,初始化嵌入矩阵
if zero_pad: # 便于创建常量掩码
embeddings = tf.concat((tf.zeros(shape=[1, num_units]),
embeddings[1:, :]), 0)
# 生成一行全0向量,与去掉第一行的embeddings矩阵进行拼接。
return embeddingsscaled_dot_product_attention(Q, K, V, key_masks, causality=False, dropout_rate=0., training=True, scope="scaled_dot_product_attention")
大意如下图所示
def scaled_dot_product_attention(Q, K, V, key_masks,
causality=False, dropout_rate=0.,
training=True,
scope="scaled_dot_product_attention"):
'''See 3.2.1.
Q: Packed queries. 3d tensor. [N, T_q, d_k].
K: Packed keys. 3d tensor. [N, T_k, d_k].
V: Packed values. 3d tensor. [N, T_k, d_v].
key_masks: A 2d tensor with shape of [N, key_seqlen]
causality: If True, applies masking for future blinding
dropout_rate: A floating point number of [0, 1].
training: boolean for controlling droput
scope: Optional scope for `variable_scope`.
'''
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
d_k = Q.get_shape().as_list()[-1]
# dot product
outputs = tf.matmul(Q, tf.transpose(K, [0, 2, 1])) # (N, T_q, T_k)
# scale
outputs /= d_k ** 0.5
# key masking
outputs = mask(outputs, key_masks=key_masks, type="key")
# causality or future blinding masking
if causality:
outputs = mask(outputs, type="future")
# softmax
outputs = tf.nn.softmax(outputs)
attention = tf.transpose(outputs, [0, 2, 1])
tf.summary.image("attention", tf.expand_dims(attention[:1], -1))
# # query masking
# outputs = mask(outputs, Q, K, type="query")
# dropout
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=training)
# weighted sum (context vectors)
outputs = tf.matmul(outputs, V) # (N, T_q, d_v)
return outputs 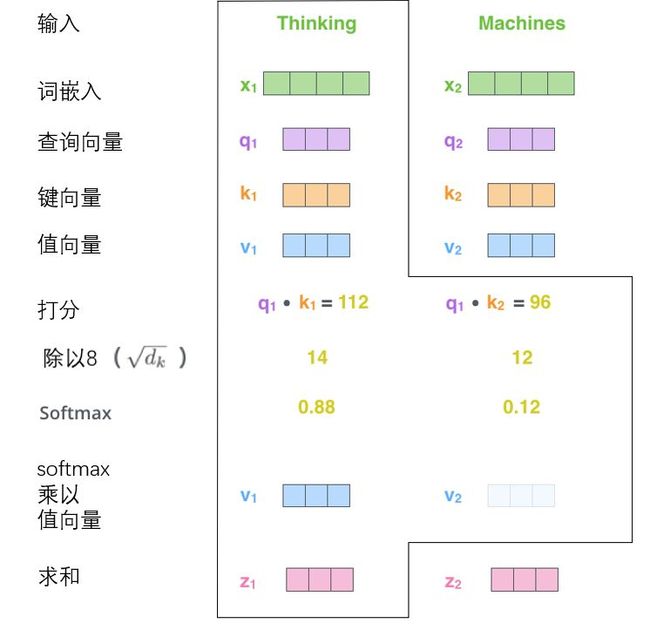
mask(inputs, key_masks=None, type=None):
def mask(inputs, key_masks=None, type=None):
"""Masks paddings on keys or queries to inputs
inputs: 3d tensor. (h*N, T_q, T_k)
key_masks: 3d tensor. (N, 1, T_k)
type: string. "key" | "future"
e.g.,
>> inputs = tf.zeros([2, 2, 3], dtype=tf.float32)
>> key_masks = tf.constant([[0., 0., 1.],
[0., 1., 1.]])
>> mask(inputs, key_masks=key_masks, type="key")
array([[[ 0.0000000e+00, 0.0000000e+00, -4.2949673e+09],
[ 0.0000000e+00, 0.0000000e+00, -4.2949673e+09]],
[[ 0.0000000e+00, -4.2949673e+09, -4.2949673e+09],
[ 0.0000000e+00, -4.2949673e+09, -4.2949673e+09]],
[[ 0.0000000e+00, 0.0000000e+00, -4.2949673e+09],
[ 0.0000000e+00, 0.0000000e+00, -4.2949673e+09]],
[[ 0.0000000e+00, -4.2949673e+09, -4.2949673e+09],
[ 0.0000000e+00, -4.2949673e+09, -4.2949673e+09]]], dtype=float32)
"""
padding_num = -2 ** 32 + 1 #足够小的负数,保证被填充的位置进入softmax之后概率接近0
if type in ("k", "key", "keys"): # padding mask
key_masks = tf.to_float(key_masks)
key_masks = tf.tile(key_masks, [tf.shape(inputs)[0] // tf.shape(key_masks)[0], 1]) # (h*N, seqlen)
key_masks = tf.expand_dims(key_masks, 1) # (h*N, 1, seqlen)
outputs = inputs + key_masks * padding_num
# elif type in ("q", "query", "queries"):
# # Generate masks
# masks = tf.sign(tf.reduce_sum(tf.abs(queries), axis=-1)) # (N, T_q)
# masks = tf.expand_dims(masks, -1) # (N, T_q, 1)
# masks = tf.tile(masks, [1, 1, tf.shape(keys)[1]]) # (N, T_q, T_k)
#
# # Apply masks to inputs
# outputs = inputs*masks
elif type in ("f", "future", "right"): # future mask
diag_vals = tf.ones_like(inputs[0, :, :]) # (T_q, T_k)
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k) # 上三角皆为0
future_masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(inputs)[0], 1, 1]) # (N, T_q, T_k) # N batch size
paddings = tf.ones_like(future_masks) * padding_num
outputs = tf.where(tf.equal(future_masks, 0), paddings, inputs) # 上三角中用padding值代替
else:
print("Check if you entered type correctly!")
return outputs
multihead_attention(queries, keys, values, key_masks, num_heads=8, dropout_rate=0, training=True, causality=False, scope="multihead_attention")
多头注意力机制,注意causality参数,
def multihead_attention(queries, keys, values, key_masks,
num_heads=8,
dropout_rate=0,
training=True,
causality=False,
scope="multihead_attention"):
'''Applies multihead attention. See 3.2.2
queries: A 3d tensor with shape of [N, T_q, d_model].
keys: A 3d tensor with shape of [N, T_k, d_model].
values: A 3d tensor with shape of [N, T_k, d_model].
key_masks: A 2d tensor with shape of [N, key_seqlen]
num_heads: An int. Number of heads.
dropout_rate: A floating point number.
training: Boolean. Controller of mechanism for dropout.
causality: Boolean. If true, units that reference the future are masked.
scope: Optional scope for `variable_scope`.
Returns
A 3d tensor with shape of (N, T_q, C)
'''
d_model = queries.get_shape().as_list()[-1] # 获取词向量长度
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
# Linear projections # 通过权重矩阵得出Q,K,V矩阵
Q = tf.layers.dense(queries, d_model, use_bias=True) # (N, T_q, d_model)
K = tf.layers.dense(keys, d_model, use_bias=True) # (N, T_k, d_model)
V = tf.layers.dense(values, d_model, use_bias=True) # (N, T_k, d_model)
# Split and concat 针对最后一个维度划分为多头,词向量长度512 → 每个头64
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, d_model/h)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, d_model/h)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, d_model/h)
# Attention 计算自注意力
outputs = scaled_dot_product_attention(Q_, K_, V_, key_masks, causality, dropout_rate, training)
# Restore shape 合并多头
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, d_model)
# Residual connection 残差链接
outputs += queries
# Layer Normalize
outputs = ln(outputs)
return outputs 
ff(inputs, num_units, scope="positionwise_feedforward")
def ff(inputs, num_units, scope="positionwise_feedforward"):
'''position-wise feed forward net. See 3.3
inputs: A 3d tensor with shape of [N, T, C].
num_units: A list of two integers.
num_units[0]=d_ff: 隐藏层大小(2048)
num_units[1]=d_model: 词向量长度(512)
scope: Optional scope for `variable_scope`.
Returns:
A 3d tensor with the same shape and dtype as inputs
'''
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
# Inner layer
outputs = tf.layers.dense(inputs, num_units[0], activation=tf.nn.relu)
# Outer layer
outputs = tf.layers.dense(outputs, num_units[1])
# Residual connection
outputs += inputs
# Layer Normalize
outputs = ln(outputs)
return outputslabel_smoothing(inputs, epsilon=0.1):
def label_smoothing(inputs, epsilon=0.1):
'''Applies label smoothing. See 5.4 and https://arxiv.org/abs/1512.00567.
inputs: 3d tensor. [N, T, V], where V is the number of vocabulary.
epsilon: Smoothing rate.
For example,
```
import tensorflow as tf
inputs = tf.convert_to_tensor([[[0, 0, 1],
[0, 1, 0],
[1, 0, 0]],
[[1, 0, 0],
[1, 0, 0],
[0, 1, 0]]], tf.float32)
outputs = label_smoothing(inputs)
with tf.Session() as sess:
print(sess.run([outputs]))
>>
[array([[[ 0.03333334, 0.03333334, 0.93333334],
[ 0.03333334, 0.93333334, 0.03333334],
[ 0.93333334, 0.03333334, 0.03333334]],
[[ 0.93333334, 0.03333334, 0.03333334],
[ 0.93333334, 0.03333334, 0.03333334],
[ 0.03333334, 0.93333334, 0.03333334]]], dtype=float32)]
```
'''
V = inputs.get_shape().as_list()[-1] # number of channels
return ((1-epsilon) * inputs) + (epsilon / V)positional_encoding(inputs, maxlen, masking=True, scope="positional_encoding"):
位置编码
def positional_encoding(inputs,
maxlen,
masking=True,
scope="positional_encoding"):
'''Sinusoidal Positional_Encoding. See 3.5
inputs: 3d tensor. (N, T, E)
maxlen: scalar. Must be >= T
masking: Boolean. If True, padding positions are set to zeros.
scope: Optional scope for `variable_scope`.
returns
3d tensor that has the same shape as inputs.
'''
E = inputs.get_shape().as_list()[-1] # static 获取此向量维度 d_model
N, T = tf.shape(inputs)[0], tf.shape(inputs)[1] # dynamic N为batch_size,T为最长句子长度
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
# position indices 位置索引
position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1]) # (N, T) 对张量进行扩展 1,T → N,T
# First part of the PE function: sin and cos argument 位置嵌入方法
position_enc = np.array([
[pos / np.power(10000, (i-i%2)/E) for i in range(E)]
for pos in range(maxlen)])
# Second part, apply the cosine to even columns and sin to odds. 不同位置 使用sin和cos方法
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1
position_enc = tf.convert_to_tensor(position_enc, tf.float32) # (maxlen, E)
# lookup
outputs = tf.nn.embedding_lookup(position_enc, position_ind)
# masks
if masking: # 是否需要掩码
outputs = tf.where(tf.equal(inputs, 0), inputs, outputs)
# inputs中值为0的地方(为True的地方)保持值不变,其余元素替换为outputs结果。因为0的地方就是掩码的地方,不需要有所谓的位置嵌入。
return tf.to_float(outputs)参考:
- 直观的理解tensorflow中的tf.tile()函数
- tf.expand_dims用法详解
- TensorFlow函数:tf.where
noam_scheme(init_lr, global_step, warmup_steps=4000.)
def noam_scheme(init_lr, global_step, warmup_steps=4000.):
'''Noam scheme learning rate decay
init_lr: initial learning rate. scalar.
global_step: scalar.
warmup_steps: scalar. During warmup_steps, learning rate increases
until it reaches init_lr.
'''
step = tf.cast(global_step + 1, dtype=tf.float32)
return init_lr * warmup_steps ** 0.5 * tf.minimum(step * warmup_steps ** -1.5, step ** -0.5)