《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(第2版)》学习笔记
文章目录
-
-
- 书籍信息
- 技术和工具
-
- Scikit-Learn
- TensorFlow
- Keras
- Jupyter notebook
- 资源
-
- 书籍配套资料
- 流行的开放数据存储库
- 元门户站点(它们会列出开放的数据存储库)
- 其他一些列出许多流行的开放数据存储库的页面
- 其他
- 机器学习项目清单
-
- 主要有8个步骤
- 框出问题并看整体
- 获取数据
- 研究数据
- 准备数据
- 列出有前途的模型
- 微调系统
- 演示你的解决方案
- 启动
- 机器学习概览
-
- 什么是机器学习
- 为什么使用机器学习
- 机器学习的应用示例
- 机器学习系统的类型
- 机器学习的主要挑战
- 测试与验证
- 端到端的机器学习项目
-
- 观察大局
- 获取数据
- 从数据探索和可视化中获得洞见
- 机器学习算法的数据准备
- 选择和训练模型
- 微调模型
- 启动、监控和维护你的系统
- 分类
-
- 训练二元分类器
- 性能测量
- 多类分类器
- 误差分析
- 多标签分类
- 多输出分类
- 训练模型
-
- 线性回归
- 梯度下降
- 多项式回归
- 学习曲线
- 正则化线性模型
- 逻辑回归
- 支持向量机
-
- 线性SVM分类
- 非线性SVM分类
- SVM回归
- 工作原理
- 决策树
-
- 训练和可视化决策树
- 做出预测
- 估计类概率
- CART训练算法
- 计算复杂度
- 基尼不纯度或熵
- 正则化超参数
- 回归
- 不稳定性
- 集成学习和随机森林
-
- 投票分类器
- bagging和pasting
- 随机补丁和随机子空间
- 随机森林
- 提升法
- 堆叠法
- 降维
-
- 维度的诅咒
- 降维的主要方法
- 主成分分析 PCA
- 内核PCA
- 局部线性嵌入 LLE
- 其他降维技术
- 无监督学习技术
-
- 聚类
- 高斯混合模型
- Keras人工神经网络简介
-
- 从生物神经元到人工神经元
- 使用Keras实现MLP
- 微调神经网络超参数
- 训练深度神经网络
-
- 梯度消失与梯度爆炸问题
- 重用预训练层
- 更快的优化器
- 通过正则化避免过拟合
- 总结和实用指南
-
- 默认的DNN配置
- 用于自归一化网络的DNN配置
- 使用TensorFlow自定义模型和训练
-
- TensorFlow快速浏览
- 像NumPy一样使用TensorFlow
- 定制模型和训练算法
- TensorFlow函数和图
- 使用TensorFlow加载和预处理数据
-
- 数据API
- TFRecord格式
- 预处理输入特征
- TF Transform
- 使用卷积神经网络的深度计算机视觉
-
- 视觉皮层的架构
- 卷积层
- 池化层
- CNN架构
- 使用Keras实现ResNet-34 CNN
- 使用Keras的预训练模型
- 迁移学习的预训练模型
- 分类和定位
- 物体检测
- 语义分割
- 使用RNN和CNN处理序列
-
- 循环神经元和层
- 训练RNN
- 预测时间序列
- 处理长序列
- 使用RNN和注意力机制进行自然语言处理
-
- 使用字符RNN生成莎士比亚文本
- 情感分析
- 神经机器翻译的编码器-解码器网络
- 注意力机制
- 最近语言模型的创新
- 使用自动编码器和GAN的表征学习和生成 学习
-
- 有效的数据表征
- 使用不完整的线性自动编码器执行PCA
- 堆叠式自动编码器
- 卷积自动编码器
- 循环自动编码器
- 去噪自动编码器
- 稀疏自动编码器
- 变分自动编码器
- 生成式对抗网络
- 强化学习
-
- 学习优化奖励
- 策略搜索
- OpenAI Gym介绍
- 神经网络策略
- 评估动作:信用分配问题
- 策略梯度
- 马尔可夫决策过程
- 时序差分学习
- Q学习
- 实现深度Q学习
- 深度Q学习的变体
- TF-Agents库
- 一些流行的RL算法概述
- 大规模训练和部署TensorFlow模型
-
- 为TensorFlow模型提供服务
- 将模型部署到移动端或嵌入式设备
- 使用GPU加速计算
- 跨多个设备的训练模型
-
书籍信息
书名:机器学习实战:基于Scikit-Learn、Keras和TensorFlow(第2版)
作者:奥雷利安·杰龙
资料:https://download.csdn.net/download/zhiyuan411/87008603,密码:book
技术和工具
Scikit-Learn
Scikit-Learn 非常易于使用,它有效地实现了许多机器学习算法,因此成为学习机器学习的重要切入点。Scikit-Learn由David Cournapeau于2007年创建,现在由法国计算机科学和自动化研究所的一个研究小组领导。
TensorFlow
TensorFlow 是用于分布式数值计算的更复杂的库。通过将计算分布在数百个GPU(图形处理单元)服务器上,它可以有效地训练和运行大型神经网络。TensorFlow(TF)是由Google创建的,并支持许多大型机器学习应用程序。它于2015年11月开源,2.0版本于2019年11月发布。
Keras
Keras 是高层深度学习API,使训练和运行神经网络变得非常简单。它可以在TensorFlow、Theano或微软Cognitive Toolkit(以前称为CNTK)之上运行。TensorFlow附带了该API自己的实现,称为 tf.keras,支持某些高级TensorFlow功能(例如有效加载数据的能力)。
Jupyter notebook
Jupyter Notebook 是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
安装和使用参考:https://zhuanlan.zhihu.com/p/33105153
资源
书籍配套资料
- 在 https://github.com/ageron/handson-ml2 上在线获得的代码示例。
- O’Reilly的在线学习平台允许你按需访问现场培训课程、深入的学习路径、交互式编程环境,以及O’Reilly和200多家其他出版商提供的大量文本和视频资源。访问: http://oreilly.com
流行的开放数据存储库
- UC Irvine Machine Learning Repository(http://archive.ics.uci.edu/ml/)
- Kaggle datasets(https://www.kaggle.com/datasets)
- Amazon’s AWS datasets(http://aws.amazon.com/fr/datasets/)
元门户站点(它们会列出开放的数据存储库)
- Data Portals(http://dataportals.org/)
- OpenDataMonitor(http://opendatamonitor.eu/)
- Quandl(http://quandl.com/)
其他一些列出许多流行的开放数据存储库的页面
- Wikipedia’s list of Machine Learning datasets(https://goo.gl/SJHN2k)
- Quora.com(http://goo.gl/zDR78y)
- The datasets subreddit(https://www.reddit.com/r/datasets)
其他
- http://kaggle.com/ 的竞赛网站
- TensorFlow数据集项目:https://homl.info/tfds
机器学习项目清单
主要有8个步骤
- 框出问题并看整体。
- 获取数据。
- 研究数据以获得深刻见解。
- 准备数据以便更好地将潜在的数据模式提供给机器学习算法。
- 探索许多不同的模型,并列出最佳模型。
- 微调你的模型,并将它们组合成一个很好的解决方案。
- 演示你的解决方案。
- 启动、监视和维护你的系统。
框出问题并看整体
- 用业务术语定义目标。
- 你的解决方案将如何使用?
- 当前有什么解决方案/解决方法(如果有)?
- 你应该如何阐述这个问题(有监督/无监督,在线/离线等)?
- 应该如何衡量性能?
- 性能指标是否符合业务目标?
- 达到业务目标所需的最低性能是多少?
- 有没有一些相似的问题?你可以重用经验或工具吗?
- 有没有相关有经验的人?
- 你会如何手动解决问题?
- 列出你(或其他人)到目前为止所做的假设。
- 如果可能,请验证假设。
获取数据
- 列出所需的数据以及你需要多少数据。
- 查找并记录可从何处获取该数据。
- 检查将占用多少空间。
- 检查法律义务,并在必要时获得授权。
- 获取访问授权。
- 创建一个工作空间(具有足够的存储空间)。
- 获取数据。
- 将数据转换为可以轻松操作的格式(无须更改数据本身)。
- 确保敏感信息被删除或受保护(例如匿名)。
- 检查数据的大小和类型(时间序列、样本、地理等)。
- 抽样一个测试集,将其放在一边,再也不要看它(无数据监听!)。
- 注意:尽可能地自动化,以便你可以轻松地获取新数据。
研究数据
- 创建数据副本来进行研究(必要时将其采样到可以管理的大小)。
- 创建 Jupyter notebook 以记录你的数据研究。
- 研究每个属性及其特征:名称、类型(分类、整数/浮点型、有界/无界、文本、结构化等)、缺失值的百分比、噪声和噪声类型(随机、异常值、舍入误差等)、任务的实用性、分布类型(高斯分布、均匀分布、对数分布等)
- 对于有监督学习任务,请确定目标属性。
- 可视化数据。
- 研究属性之间的相关性。
- 研究如何手动解决问题。
- 确定你可能希望使用的转变。
- 确定有用的额外数据。
- 记录所学的知识。
- 注意:请尝试从现场专家那里获取有关这些步骤的见解。
准备数据
- 数据清理:修复或删除异常值(可选)、填写缺失值(例如,零、均值、中位数)或删除其行(或列)。
- 特征选择(可选):删除没有为任务提供有用信息的属性。
- 特征工程(如果适用):离散化连续特征、分解特征(例如分类、日期/时间等)、添加有希望的特征转换(例如log(x)、sqrt(x)、x2等)、将特征聚合为有希望的新特征。
- 特征缩放:标准化或归一化特征。
- 注意:在数据副本上工作(保持原始数据集完整);为你应用的所有数据转换编写函数(原因有5个:下次获取新的数据集时,你可以轻松准备数据;可以在未来的项目中应用这些转换;清理并准备测试集;解决方案上线后清理并准备新的数据实例;使你可以轻松地将准备选择视为超参数)
列出有前途的模型
- 使用标准参数训练来自不同类别(例如线性、朴素贝叶斯、SVM、随机森林、神经网络等)的许多快速和粗糙的模型。
- 衡量并比较其性能。对于每个模型,使用N折交叉验证,在N折上计算性能度量的均值和标准差。
- 分析每种算法的最重要的变量。
- 分析模型所犯错误的类型。人类将使用什么数据来避免这些错误?
- 快速进行特征选择和特征工程。
- 在前面5个步骤中执行一两个以上的快速迭代。
- 筛选出前三到五个最有希望的模型,优先选择会产生不同类型错误的模型。
- 注意:如果数据量巨大,则可能需要采样为较小的训练集,以便可以在合理的时间内训练许多不同的模型(请注意,这会对诸如大型神经网络或随机森林之类的复杂模型造成不利影响);尽可能自动化地执行这些步骤。
微调系统
- 使用交叉验证微调超参数:将你的数据转换选择视为超参数,尤其是当你对它们不确定时(例如,如果不确定是否用零或中位数替换缺失值,或者只是删除行);除非要研究的超参数值很少,否则应优先选择随机搜索而不是网格搜索,如果训练时间很长,你可能更喜欢贝叶斯优化方法(如Jasper Snoek等人所述使用高斯过程先验)。
- 尝试使用集成方法。组合最好的模型通常会比单独运行有更好的性能。
- 一旦对最终模型有信心,就可以在测试集中测量其性能,以估计泛化误差。
- 注意:你将需要在此步骤中使用尽可能多的数据,尤其是在微调结束时;与往常一样,尽可能做到自动化;在测量了泛化误差之后,请不要对模型进行调整,否则你会开始过拟合测试集。
演示你的解决方案
- 记录你所做的事情。
- 创建一个不错的演示文稿。确保先突出大的蓝图。
- 说明你的解决方案为何可以实现业务目标。
- 别忘了介绍你一路上注意到的有趣观点。描述什么有效,什么无效;列出你的假设和系统的局限性。
- 确保通过精美的可视化效果或易于记忆的陈述来传达你的主要发现(例如,“中等收入是房价的第一大预测指标”)。
启动
- 使你的解决方案准备投入生产环境(插入生产数据输入、编写单元测试等)。
- 编写监控代码,以定期检查系统的实时性能,并在系统故障时触发警报。当心缓慢的退化:随着数据的发展,模型往往会“腐烂”;评估性能可能需要人工流水线(例如通过众包服务);监视你的输入的质量(例如,传感器出现故障,发送了随机
值,或者另一个团队的输出变得过时),这对于在线学习系统尤其重要。 - 定期根据新数据重新训练模型(尽可能自动进行)。
机器学习概览
什么是机器学习
机器学习是一个研究领域,让计算机无须进行明确编程就具备学习能力。(亚瑟·萨缪尔(Arthur Samuel),1959)
一个计算机程序利用经验E来学习任务T,性能是P,如果针对任务T的性能P随着经验E不断增长,则称为机器学习。(汤姆·米切尔(Tom Mitchell),1997)
为什么使用机器学习
- 有解决方案,但解决方案需要进行大量人工微调或需要遵循大量规则;
- 传统方法难以解决的复杂问题;
- 环境有波动;
- 洞察复杂问题和大量数据。
机器学习的应用示例
- 分析生产线上的产品图像来对产品进行自动分类:这是图像分类问题。
- 通过脑部扫描发现肿瘤:这是语义分割,图像中的每个像素都需要被分类。
- 自动分类新闻:这是自然语言处理,更具体地是文本分类。
- 论坛中自动标记恶评:这也是文本分类,使用自然语言处理工具。
- 自动对长文章做总结:这是自然语言处理的一个分支,叫作文本总结。
- 创建一个聊天机器人或者个人助理:这涉及自然语言处理的很多分支,包括自然语言理解和问答模块。
- 基于很多性能指标来预测公司下一年的收入:这是一个回归问题(如预测值),需要使用回归模型进行处理。
- 让应用对语音命令做出反应:这是语音识别,要求能处理音频采样。
- 检测信用卡欺诈:这是异常检测。
- 基于客户的购买记录来对客户进行分类,对每一类客户设计不同的市场策略:这是聚类问题。
- 用清晰而有洞察力的图表来表示复杂的高维数据集:这是数据可视化,经常涉及降维技术。
- 基于以前的购买记录给客户推荐可能感兴趣的产品:这是推荐系统,一个办法是将以前的购买记录(和客户的其他信息)输入人工神经网络,从而输出客户最可能购买的产品。
- 为游戏建造智能机器人:这通常通过强化学习来解决。
机器学习系统的类型
- 有监督学习:k-近邻算法、线性回归、逻辑回归、支持向量机(SVM)、决策树和随机森林、神经网络。
- 无监督学习:聚类算法、k-均值算法、DBSCAN、分层聚类分析(HCA)、异常检测和新颖性检测、单类SVM、孤立森林、可视化和降维、主成分分析(PCA)、核主成分分析、局部线性嵌入(LLE)、t-分布随机近邻嵌入(t-SNE)、关联规则学习、Apriori、Eclat。
- 半监督学习
- 强化学习
- 批量学习和在线学习
- 基于实例的学习与基于模型的学习
机器学习的主要挑战
- 训练数据的数量不足
- 训练数据不具代表性
- 低质量数据
- 无关特征
- 过拟合训练数据
- 欠拟合训练数据
测试与验证
- 超参数调整和模型选择
- 数据不匹配
端到端的机器学习项目
观察大局
- 框架问题
- 选择性能指标
- 检查假设
获取数据
- 创建工作区
- 下载数据
- 快速查看数据结构
- 创建测试集
从数据探索和可视化中获得洞见
- 将数据可视化
- 寻找相关性
- 试验不同属性的组合
机器学习算法的数据准备
- 数据清理
- 处理文本和分类属性
- 自定义转换器
- 特征缩放
- 转换流水线
选择和训练模型
- 训练和评估训练集
- 使用交叉验证来更好地进行评估
微调模型
- 网格搜索
- 随机搜索
- 集成方法
- 分析最佳模型及其误差
- 通过测试集评估系统
启动、监控和维护你的系统
分类
训练二元分类器
性能测量
- 使用交叉验证测量准确率
- 混淆矩阵
- 精度和召回率
- 精度/召回率权衡
- ROC曲线(受试者工作特征曲线)
多类分类器
误差分析
多标签分类
多输出分类
训练模型
线性回归
- 标准方程
- 计算复杂度
梯度下降
- 批量梯度下降
- 随机梯度下降
- 小批量梯度下降
多项式回归
学习曲线
正则化线性模型
- 岭回归
- Lasso回归
- 弹性网络
- 提前停止
逻辑回归
- 估计概率
- 训练和成本函数
- 决策边界
- Softmax回归
支持向量机
线性SVM分类
非线性SVM分类
- 多项式内核
- 相似特征
- 高斯RBF内核
- 计算复杂度
SVM回归
工作原理
- 决策函数和预测
- 训练目标
- 二次规划
- 对偶问题
- 内核化SVM
- 在线SVM
决策树
训练和可视化决策树
做出预测
估计类概率
CART训练算法
计算复杂度
基尼不纯度或熵
正则化超参数
回归
不稳定性
集成学习和随机森林
投票分类器
bagging和pasting
- Scikit-Learn中的bagging和pasting
- 包外评估
随机补丁和随机子空间
随机森林
- 极端随机树
- 特征重要性
提升法
- AdaBoost
- 梯度提升
堆叠法
降维
维度的诅咒
降维的主要方法
- 投影
- 流形学习
主成分分析 PCA
- 保留差异性
- 主要成分
- 向下投影到d维度
- 使用Scikit-Learn
- 可解释方差比
- 选择正确的维度
- PCA压缩
- 随机PCA
- 增量PCA
内核PCA
选择内核并调整超参数
局部线性嵌入 LLE
其他降维技术
- 随机投影
- 多维缩放(MDS)
- Isomap
- t分布随机近邻嵌入(t-SNE)
- 线性判别分析(LDA)
无监督学习技术
聚类
- K-Means
- 中心点初始化方法
- 加速的K-Means和小批量K-Means
- 寻找最佳聚类数
- K-Means的局限
- 使用聚类进行图像分割
- 使用聚类进行预处理
- 使用聚类进行半监督学习
- 其他聚类算法:聚集聚类、BIRCH、均值漂移、相似性传播、谱聚类
高斯混合模型
- 使用高斯混合进行异常检测
- 选择聚类数
- 贝叶斯高斯混合模型
- 其他用于异常检测和新颖性检测的算法:Scikit-Learn、PCA、Fast-MCD、隔离森林、局部离群因子 LOF、单类SVM。
Keras人工神经网络简介
从生物神经元到人工神经元
- 生物神经元
- 神经元的逻辑计算
- 感知器
- 多层感知器和反向传播
- 回归MLP
- 分类MLP
使用Keras实现MLP
- 安装TensorFlow 2
- 使用顺序API构建图像分类器:使用Keras加载数据集、使用顺序API创建模型、编译模型、训练和评估模型、使用模型进行预测
- 使用顺序API构建回归MLP
- 使用函数式API构建复杂模型
- 使用子类API构建动态模型
- 保存和还原模型
- 使用回调函数
- 使用TensorBoard进行可视化
微调神经网络超参数
- 隐藏层数量
- 每个隐藏层的神经元数量
- 学习率、批量大小和其他超参数:学习率、优化器、批量大小、激活函数、迭代次数
训练深度神经网络
梯度消失与梯度爆炸问题
- Glorot和He初始化
- 非饱和激活函数
- 批量归一化
- 梯度裁剪
重用预训练层
- 用Keras进行迁移学习
- 无监督预训练
- 辅助任务的预训练
更快的优化器
- 动量优化
- Nesterov加速梯度
- AdaGrad
- RMSProp
- Adam和Nadam优化
- 学习率调度
通过正则化避免过拟合
- l1和l2正则化
- dropout
- 蒙特卡罗(MC)Dropout
- 最大范数正则化
总结和实用指南
默认的DNN配置

用于自归一化网络的DNN配置

使用TensorFlow自定义模型和训练
TensorFlow快速浏览
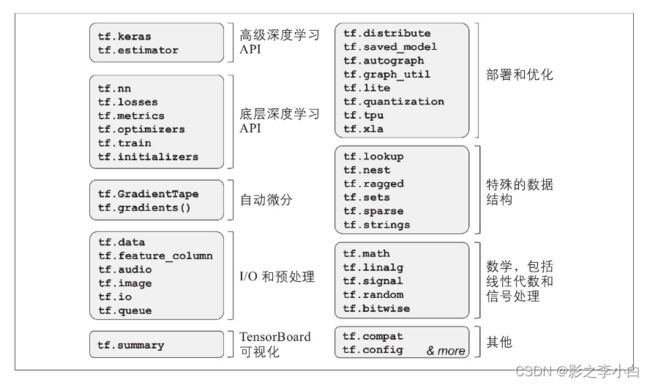
像NumPy一样使用TensorFlow
- 张量和操作
- 张量和NumPy
- 类型转换
- 变量
- 其他数据结构:稀疏张量、张量数组、不规则张量、字符串张量、集合、队列
定制模型和训练算法
- 自定义损失函数
- 保存和加载包含自定义组件的模型
- 自定义激活函数、初始化、正则化和约束
- 自定义指标
- 自定义层
- 自定义模型
- 基于模型内部的损失和指标
- 使用自动微分计算梯度
- 自定义训练循环
TensorFlow函数和图
- 自动图和跟踪
- TF函数规则
使用TensorFlow加载和预处理数据
数据API
- 链式转换
- 乱序数据
- 预处理数据
- 合并在一起
- 预取
- 和tf.keras一起使用数据集
TFRecord格式
- 压缩的TFRecord文件
- 协议缓冲区简介
- TensorFlow协议
- 加载和解析Example
- 使用SequenceExample Protobuf处理列表的列表
预处理输入特征
- 使用独热向量编码分类特征
- 使用嵌入编码分类特征
- Keras预处理层
TF Transform
使用卷积神经网络的深度计算机视觉
视觉皮层的架构
卷积层
- 滤波器
- 堆叠多个特征图
- TensorFlow实现
- 内存需求
池化层
CNN架构
- LeNet-5
- AlexNet
- GoogLeNet
- VGGNet
- ResNet
- Xception
- SENet
使用Keras实现ResNet-34 CNN
使用Keras的预训练模型
迁移学习的预训练模型
分类和定位
物体检测
- 全卷积网络1
- YOLO
语义分割
使用RNN和CNN处理序列
循环神经元和层
训练RNN
预测时间序列
- 基准指标
- 实现一个简单的RNN
- 深度RNN
- 预测未来几个时间步长
处理长序列
- 应对不稳定梯度问题
- 解决短期记忆问题
使用RNN和注意力机制进行自然语言处理
使用字符RNN生成莎士比亚文本
- 创建训练数据集
- 如何拆分顺序数据集
- 将顺序数据集切成多个窗口
- 创建和训练Char-RNN模型
- 使用Char-RNN模型
- 生成假莎士比亚文本
- 有状态RNN
情感分析
- 掩码屏蔽
- 重用预训练的嵌入
神经机器翻译的编码器-解码器网络
- 双向RNN
- 集束搜索
注意力机制
- 视觉注意力
- Transformer架构:位置嵌入、多头注意力
最近语言模型的创新
使用自动编码器和GAN的表征学习和生成 学习
有效的数据表征
使用不完整的线性自动编码器执行PCA
堆叠式自动编码器
- 使用Keras实现堆叠式自动编码器
- 可视化重构
- 可视化数据集
- 使用堆叠式自动编码器的无监督预训练
- 绑定权重
- 一次训练一个自动编码器
卷积自动编码器
循环自动编码器
去噪自动编码器
稀疏自动编码器
变分自动编码器
生成式对抗网络
- GAN的训练难点
- 深度卷积GAN
- GAN的逐步增长
- StyleGAN
强化学习
学习优化奖励
策略搜索
OpenAI Gym介绍
神经网络策略
评估动作:信用分配问题
策略梯度
马尔可夫决策过程
时序差分学习
Q学习
- 探索策略
- 近似Q学习和深度Q学习
实现深度Q学习
深度Q学习的变体
- 固定的Q值目标
- 双DQN
- 优先经验重播
- 竞争DQN
TF-Agents库
- 安装TF-Agents
- TF-Agents环境
- 环境规范
- 环境包装器和Atari预处理
- 训练架构
- 创建深度Q网络
- 创建DQN智能体
- 创建重播缓冲区和相应的观察者
- 创建训练指标
- 创建收集驱动者
- 创建数据集
- 创建训练循环
一些流行的RL算法概述
- Actor-Critic算法
- Asynchronous Advantage Actor-Critic(A3C)
- Advantage Actor-Critic(A2C)
- Soft Actor-Critic(SAC)
- Proximal Policy Optimization(PPO)
- Curiosity-based exploration
大规模训练和部署TensorFlow模型
为TensorFlow模型提供服务
- 使用TensorFlow Serving
- 在GCP AI平台上创建预测服务
- 使用预测服务
将模型部署到移动端或嵌入式设备
使用GPU加速计算
- 拥有你自己的GPU
- 使用配备GPU的虚拟机
- Colaboratory
- 管理GPU内存
- 在设备上放置操作和变量
- 跨多个设备并行执行
跨多个设备的训练模型
- 模型并行
- 数据并行
- 使用分布式策略API进行大规模训练
- 在TensorFlow集群上训练模型
- 在Google Cloud AI平台上运行大型训练作业
- AI平台上的黑箱超参数调整