01背包问题的三种求解方法——动态规划、回溯法、分支限界法的具体思路介绍及对比
多解法求解0-1背包问题
为了便于测试,选用acwing上的0-1背包问题作为测试平台:
2. 01背包问题 - AcWing题库
当然,在acwing上测试是看不到具体每个测试样例的规模的,在所有解法都介绍完毕后会专门使用自己生成的测试数据去测试每个解法的性能。
目录
解法一:动态规划
思路
代码
运行结果
复杂度分析
解法二:回溯法
思路
代码
运行结果
复杂度分析
解法三:分支限界法
思路
代码
运行结果
复杂度分析
三种方法对比:
适用性
使用难度
算法效率
具体测试
思考
附件
题目概述
有 N 件物品和一个容量是 V 的背包。每件物品只能使用一次。
第 i 件物品的体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。
输出最大价值。
输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品数量和背包容积。
接下来有 N 行,每行两个整数 vi,wi,用空格隔开,分别表示第 i件物品的体积和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N,V≤10000
0<vi,wi≤10000
输入样例
4 5
1 2
2 4
3 4
4 5
输出样例
8
注意:这里的w指物品的价值,而v指物品的体积,背包的限制条件是能装V体积的物品。而有些01背包问题描述里会用w指物品的重量,而v指物品的价值,背包的限制条件是能装W重量的物品。这两种描述里w和v的意义是不同的,需要注意!
解法一:动态规划
这是最经典的解法,也是多数oj平台上给出的官方解法。
思路:
我们用f[i][j]表示在仅考虑前i个物品,且要求容量为j时可以获得的物品最大价值。可以证明,如果f[i][j]最优,且最优选取策略里第i个物品被选取,那么f[i-1][j – v[i]]也是最优的。这是显然的,因为如果f[i-1][j-v[i]]的选择策略不是最优的,那么一定存在一个更优的选择策略使得从前i-1个物品中选取j-v[i]重量的物品获得的价值更高,我们用这个策略去替代f[i][j]中前i-1物品物品的选择策略,就能获得一个更大的f[i][j],这显然与f[i][j]最优矛盾。所以可以证明f[i-1][j-v[i]]最优。类似的我们可以证明如果第i个物品没有被选取,那么f[i-1][j]是最优的。所以该问题满足最优子结构。
我们不难写出对应的状态转移方程:
f[i][j] = max(f[i - 1][j], f[i - 1][j - v[i]] + w[j])
我们只需要输入数据后根据上面的状态转移方程更新f[i][j]直到f[N][V]被求出即可。
注意:因为我们只需要求解最大值而不需要保存最优解,我们可以考虑用滚动数组来优化空间,将f的i这一维省去,每次原地更新f[j]。但是需要注意更新顺序,我们需要将j从大到小进行更新,否则每次更新f[i][j]时右式中的f[i-1][j-v[i]]就变成f[i][j-v[i]]了,这就变成了完全背包问题的转移方程了。
据此可以写出对应的代码。用C++语言描述。
代码:
#include
#include
#include
using namespace std;
int main()
{
int N, V;
cin >> N >> V;
vector v(N + 1), w(N + 1), f(V + 1);
for(int i = 1; i <= N; ++i)
cin >> v[i] >> w[i];
for(int i = 1; i <= N; ++i)
for(int j = V; j >= v[i]; --j)
f[j] = max(f[j], f[j - v[i]] + w[i]);
cout << *max_element(f.begin(), f.end());
return 0;
}
运行结果:

复杂度分析:
时间复杂度O(NV),显然,两层循环,外循环O(N)次,内循环O(V)次,总时间复杂度为O(NV)。
空间复杂度O(V),因为使用了滚动数组,优化了空间,否则应为O(NV)。
解法二:回溯法
回溯法是一种通用求解法,效率与设置的约束函数和限界函数剪枝的能力密切相关。
思路:
我们寻找最大值,事实上就是寻找一个对物品的选择方案使得可以获得的价值最大。我们对于每个物品有 选和不选 这两种选择。为此,我们搜索所有可行的解,就可以求解出最大值。我们用一个子集树表示解空间。在第i层的每个结点都有两个孩子结点,对应选第i个物品和不选第i个物品。显然,该子集树是一个完全二叉树,且有n+1层,有2^(n+1) – 1个结点。
我们考虑回溯的剪枝:
- 约束函数:显然,当我们要选择一个物品时,如果当前已选物品的体积cv加上该物品的体积v[i],有cv+v[i] > V,那么就证明我们不能选择这个物品,因为背包装不下了,此时需要剪去这一边的树枝。这是从题目给出的条件可以看出的。
- 限界函数:我们期望到达一个结点后能够获得从当前已选方案出发如果继续进行选择所能获得的价值最大可能为多少。如果目前已知的最大价值bestw已经大于这个值,就证明继续拓展这个结点是毫无意义的,因为它不可能会带来更优的解。此时需要剪去这整个树枝。
如何评估这个价值上界?
我们考虑下面的情况:
我们假设在剩下的未被考虑是否选择的物品里,每次优先选择那些价值与体积比最大的物品,并且在背包剩余体积小于想选物品的时候,我们认为物品可分,并选取剩余体积那么多的物品。
事实上,这是一种小数背包的处理方式,通过增加背包物品可分的条件,我们能够更简单地评估出上界。
为了便于能够更快地去选择价值与体积比最大的物品,我们事先将N个物品按 价值/体积 从大到小排序,这样我们只需要顺序遍历去选择物品即可。
根据上面的讨论我们可以写出代码。
代码:
#include
#include
#include
using namespace std;
struct item
{
double v, w;
};
int bestw = 0, N, V;
vector- items;
bool cmp(const item &a, const item &b)
{
return a.w / a.v > b.w / b.v;
}
double evalue(int i, double cv)
{
double upperbound = 0, vleft = V - cv;
for(int k = i; k <= N; ++k)
{
if(vleft >= items[k].v)
{
upperbound += items[k].w;
vleft -= items[k].v;
}
else
{
upperbound += items[k].w / items[k].v * vleft;
return upperbound;
}
}
return upperbound;
}
void backtrack(int i, double cv, double cw)
{
if(i > N)
{
bestw = bestw > cw ? bestw : cw;
return;
}
if(cv + items[i].v <= V)
backtrack(i + 1, cv + items[i].v, cw + items[i].w);
if(cw + evalue(i + 1, cv) > bestw)
backtrack(i + 1, cv, cw);
}
int main()
{
scanf("%d%d", &N, &V);
items.resize(N + 1);
for(int i = 1; i <= N; ++i)
scanf("%lf%lf", &items[i].v, &items[i].w);
sort(items.begin() + 1, items.end(), cmp);
backtrack(1, 0, 0);
cout << bestw << endl;
system("pause");
return 0;
}
其中evalue函数用于评估如果当前使用体积为cv时,选取第i~n物品最多可以获得多少价值。
注意到我们不需要在进入左子树的时候使用限界函数进行剪枝,因为如果可以进入左子树的话,限界函数的值是不会变的,因为我们进入左子树就是要选择加入第i个物品,通过限界函数评估出的上界是不会变的,因为其实无非就是把w[i]从r(i)这一部分移到了cw这一部分,整体的值是不会变的。所以我们只在要进入右子树的时候通过限界函数剪枝。
简而言之,左子树只用约束函数剪枝,右子树只用限界函数剪枝。
运行结果:

复杂度分析:
首先子集树结点为2^(N+1)-1个,即O(2^N)个。在每个结点处都需要求解限界函数,时间复杂度显然为O(N)。所以回溯的时间复杂度为O(N*2^N)。而排序需要花费O(NlogN)时间,在渐进意义下,总时间复杂度为O(N*2^N)。
搜索深度最多为n+1,即O(N),而排序的栈空间开销为O(logN),渐进意义下的空间复杂度为O(N)
解法三:分支限界法
分支限界法也是一种在解空间上进行搜索的算法,与回溯不同的是,它常常用于求解最优解,而回溯则是求解全部可行解。在进行结点扩展时,它是一次性将一个结点的所有子节点进行扩展。通过FIFO队列或者优先队列每次优先选取在某种约束下最优的结点进行拓展以期更快地获得最优解。
思路:
分支限界法因为也是对解空间进行搜索,所有为了优化速度,我们使用它的时候也是需要进行“剪枝”的,只不过在这里不叫剪枝,而是叫做“杀死”活结点。我们每次对一个活结点进行拓展,对它拓展出的子节点,我们需要用约束函数和限界函数进行判断,判断这个结点是否可以作为活结点,如果不能,就将它杀死。事实上,这里的约束函数和限界函数与回溯法里的是一样的。
如果想要粗浅地去理解回溯和分支限界法的区别。可以将回溯法理解为改造过的深度优先搜索,之所以说是改造过的,是因为回溯法会涉及到大量的剪枝,否则单纯的对解空间进行深度优先搜索所消耗的时间是不可接受的。同理,分支限界法则可以认为是改造过的广度优先搜索,在广度优先搜索的基础上增加了约束函数和限界函数“杀死”活结点。至少在使用FIFO队列时可以这样认为。其中提到的活结点表往往使用FIFO队列或者优先队列。如果使用的优先队列作为活结点表,就不能单纯的认为是一种改造过的广度优先搜索了。此时是一种权值优先搜索,权值的构成和我们要求的最优解有关。
因为分支限界法的约束函数和限界函数与回溯法相同,我在此就略去了。我们只讨论对于使用优先队列作为活结点表时结点优先级的设定。
在上面我们提到了用限界函数B(i)来计算从当前结点继续搜索可以达到的价值上界。我们期望能够尽快地搜索到最优解,也就是最大价值,一种直观的想法是我们每次选取B(i)最大的结点进行扩展,因为它“最有潜力”成为最优解。可以证明,上述的策略确实能够大大提升搜索到最优解的速度,而且可以断言第一个搜索到的可行解一定就是最优解,因为搜索到可行解时B(i)事实上就是当前这个解的值,又因为这个结点的B(i)比其余结点都大,那么这个解的值就一定比其余结点的B(i)高。既然比价值上界都高,那么当前这个搜索到的解就一定是最优解了。因此,我们在存储结点时不仅要存储cw,cv,i,也要存储B(i),并将它作为从大到小的优先队列的权值。每次取队头结点进行拓展。同样的,为了能够快速地计算出B(i),我们依然需要先对物品进行排序。
据此,我们可以写出代码。
代码:
#include
#include
#include
#include
using namespace std;
struct item
{
double v, w;
};
struct node
{
int cw, cv, i;
double B;
node(int cv, int cw, int i, double B) : cv(cv), cw(cw), i(i), B(B) {}
bool operator<(const node &b) const
{
return this -> B < b.B;
}
};
int bestw = 0, N, V;
vector- items;
bool cmp(const item &a, const item &b)
{
return a.w / a.v > b.w / b.v;
}
double evalue(int i, double cv)
{
double upperbound = 0, vleft = V - cv;
for(int k = i; k <= N; ++k)
{
if(vleft >= items[k].v)
{
upperbound += items[k].w;
vleft -= items[k].v;
}
else
{
upperbound += items[k].w / items[k].v * vleft;
return upperbound;
}
}
return upperbound;
}
void Knapsacks()
{
priority_queue
Q;
Q.push(node(0, 0, 1, evalue(1, 0)));
node temp(0, 0, 0, 0);
while(!Q.empty())
{
temp = Q.top();
Q.pop();
if(temp.i > N)
{
bestw = temp.cw;
return;
}
double &vi = items[temp.i].v;
double &wi = items[temp.i].w;
double nextB = temp.cw + evalue(temp.i + 1, temp.cv);
if(temp.cv + vi <= V)
{
Q.push(node(temp.cv + vi, temp.cw + wi, temp.i + 1, temp.B));
bestw = bestw > temp.cw + wi ? bestw : temp.cw + wi;
}
if(nextB > bestw)
Q.push(node(temp.cv, temp.cw, temp.i + 1, nextB));
}
}
int main()
{
scanf("%d%d", &N, &V);
items.resize(N + 1);
for(int i = 1; i <= N; ++i)
scanf("%lf%lf", &items[i].v, &items[i].w);
sort(items.begin() + 1, items.end(), cmp);
Knapsacks();
cout << bestw << endl;
system("pause");
return 0;
}
注意到与回溯法不同,我们在分支限界法里每到一个结点都会尝试更新bestw,因为这样才能使得bestw较早地变为较大的数值,以便限界函数发挥作用。当然,我们在回溯法里也可以每到一个结点就尝试更新bestw,但是这是没有什么意义的,因为在搜索一个可行解时我们搜索过程中随着层数的增加获得的cw一定是会逐渐增加的(至少是不减的),此时每次到达一个结点就对bestw进行更新没有意义,因为此时限界函数无法帮助剪枝。打个比方,假如我们现在搜索到第i层结点,并且获得了比bestw还大的cw,那么我们此时更新bestw有什么意义?还是得继续往第i+1层结点搜索,而且我们还能保证继续搜索获得的cw肯定只增不减,那么这个时候更新bestw是不能帮助我们通过限界函数剪枝的,只有在搜索到一个可行解后,我们可以用这个可行解的值去帮助搜索之后的可行解,在搜索某个可行解的过程中更新bestw对继续搜索这个可行解是没有意义的。所以在回溯里我们在找到一个可行解的时候才会尝试更新bestw。
运行结果:

复杂度分析:
时间复杂度O(N*2^N),与回溯法相同,当然了,事实上不可能这么高,这是一个非常松的上界,相信不难发现回溯法和分支限界法都比号称O(N^2)时间复杂度的动态规划快,这证明剪枝剪去了非常多的枝条。
空间复杂度O(2^N),这是个非常松的上界,因为我们剪去了很多树枝,事实上从运行空间大小来看,与回溯法相差无几,我们有理由相信经过剪枝后的分支限界法的运行空间在大多数情况下是接近O(N)的。
三种方法对比:
适用性:
动态规划可以解决的题目相对较少,需要题目满足最优子结构和重叠子问题两个条件。
回溯法和分支限界法都是通用求解方法,适用范围更广,可以用来求解NP问题。但是一般分支限界法会倾向于去求解最优解问题,当然也可以用来求解所有可行解,但是此时我们会更倾向于使用回溯法。
使用难度:
动态规划涉及到最优子结构和重叠子问题的证明,状态的定义,状态转移方程的构造等。想要设计一个正确的动态规划算法难度较大。
回溯法和分支限界法的编写难度较低,只需对解空间树进行搜索即可。但是约束函数和限界函数的编写的好坏对算法的效率影响非常大,如果不进行优化,这两个算法的时间和空间花费是不可接受的。剪枝是一个技巧性很强的操作,想要写出一个高效的回溯法或者分支限界法难度也较高。回溯法和分支限界法应该属于易学难精的算法,但是如果真的写出了优秀的回溯法或者分支限界法,它们的效率会非常高。
算法效率:
动态规划的时间复杂度和空间复杂度一般都是多项式级别的,相对于一般的暴力解法会高效很多。
回溯法和分支限界法的时间复杂度上界虽然很大,但是经过剪枝可以达到非常高效。但是到底效率能达到多高与剪枝的方法息息相关,一个好的剪枝方案可以带来优越的算法,而一个差的剪枝方案会带来一个没有实用性的算法。也就是说回溯法和分支限界法的效率的上限很高,但是下限也很低。
具体测试:
我准备了7组测试数据用于比较这三种算法在01背包方法上的运行时间,我会在后面附上这七组测试数据与测试代码。它们的N的规模分别为100,500,1000,1500,2000,2500,3000。
下面是实验结果:
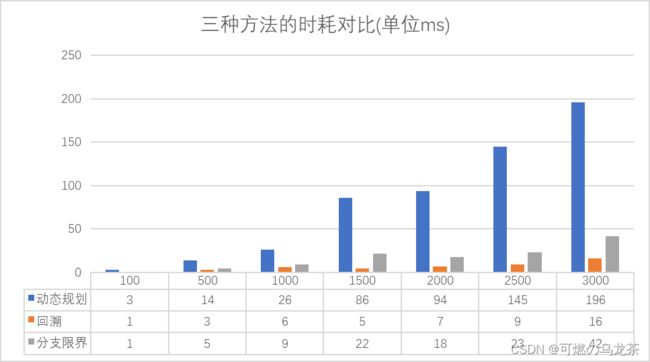
可见动态规划算法随着数据规模的增大,时耗会明显增高,而回溯法和分支限界法则增长缓慢。当然,回溯法和分支限界法的时耗与测试样例关系较大,在我的这七组数据里回溯法表现得比分支限界法好,在其他的数据里可能分支限界法就会更好。
总而言之,经过较好剪枝处理的回溯法和分支限界法在时耗上是可能比动态规划这类所谓时间复杂度更低的算法还少的。
思考:
经过上述分析,并且结合个人在写这三个算法中途的感受,我认为在求解类似的这些既可以用动态规划也可以用回溯或者分支限界法的问题,如果对于动态规划有思路,还是优先选用动态规划吧。毕竟动态规划虽然不太好想,但是代码量一般会少很多。而回溯或者分支限界法虽然在优化的情况下可以有很高的效率,但是一般的题目的剪枝难度是很高的,想要找到一个优良的剪枝方案难度较高。而动态规划方法所提供的时间消耗也是我们可以接受的。
当然了,如果没有动态规划的思路的话,回溯或者分支限界法就可以考虑了,在写出主体后再考虑剪枝方案,虽然可能效率不尽人意,但是总比什么都不做强。如果能想出一个优秀的剪枝方案那更是再好不过了。
附件:
之前提到的七组测试样例,分别以数据规模来命名。
以及对应的测试用代码,分别是动态规划、回溯、分支限界。
链接: https://pan.baidu.com/s/12t3EN89IFK7WE6b9ehfDDw?pwd=b6mk
提取码: b6mk