机器学习(四)--- 朴素贝叶斯
目录
概述
朴素贝叶斯算法原理
代码练习
1、留言分类
2、垃圾邮件分类
3、My Data
Reference
概述
朴素贝叶斯法(Naive Bayes Classifier)是基于贝叶斯定理与特征条件独立性假设的分类方法。对于给定的训练集,首先基于特征条件独立假设学习输入输出的联合概率分布(朴素贝叶斯法这种通过学习得到模型的机制,显然属于生成模型);然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y。
首先 我们先来了解一下部分概念
比如我们已经知道袋子里面有 10 个球,不是黑球就是白球,其中 6个是黑球,那么把手伸进去摸一个球,就能知道摸出黑球的概率是多少。但这种情况往往是上帝视角,即了解了事情的全貌再做判断。
但是 我们事先不知道袋子里黑球和白球的比例 通过我们后面摸出来球的颜色能判断袋子里黑白球的比例吗
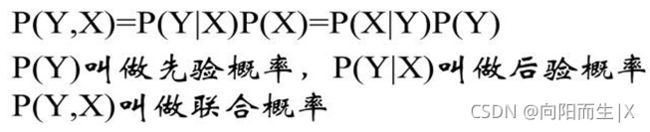
先验概率:
通过经验来判断事情发生的概率,比如说“贝叶死”的发病率是万分之一,就是先验概率。
后验概率:
后验概率就是发生结果之后,推测原因的概率。比如说某人查出来了患有“贝叶死”,那么患病的原因可能是 A、B 或 C。**患有“贝叶死”是因为原因 A 的概率就是后验概率。它是属于条件概率的一种。
条件概率:
事件 A 在另外一个事件 B 已经发生条件下的发生概率,表示为 P(A|B)。比如原因 A 的条件下,患有“贝叶死”的概率,就是条件概率。
接下来了解一下机器学习中的判别式模型和生成式模型
在机器学习中,对于有监督学习可以将其分为两类模型:判别式模型和生成式模型。简单地说,判别式模型是针对条件分布建模,而生成式模型则针对联合分布进行建模。
简单来说就是
- 对于判别式模型,只需要学习二者差异即可。比如说好瓜和坏瓜 比如好瓜的藤比坏瓜更绿一些。
- 而生成式模型则不一样,需要学习好瓜的特征是什么样,坏瓜的特征是么样。有了二者的特征以后,再根据各自的特征去区分。
生成式模型:由数据学习联合概率分布P(X,Y), 然后由P(Y|X)=P(X,Y)/P(X)求出概率分布P(Y|X)作为预测的模型。该方法表示了给定输入X与产生输出Y的生成关系
判别式模型:由数据直接学习决策函数Y=f(X)或条件概率分布P(Y|X)作为预测模型,即判别模型。判别方法关心的是对于给定的输入X,应该预测什么样的输出Y。
而这次实验所学的贝叶斯就是生成式模型
对每一个类建立一个模型,有多少个类别,就建立多少个模型。比如说类别标签有{好瓜,坏瓜},那首先根据好瓜的特征学习出一个好瓜的模型,再根据坏瓜的特征学习出坏瓜的模型,之后分别计算新样本 跟两个类别的联合概率 ![]() ,然后根据贝叶斯公式:
,然后根据贝叶斯公式:

分别计算,选择最大的![]() 作为样本的分类
作为样本的分类

朴素贝叶斯算法原理
贝叶斯公式
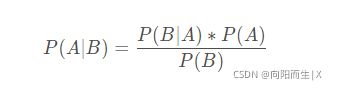
在贝叶斯公式中,P(A)称为"先验概率"(Prior probability),即在B事件发生之前,对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:后验概率=先验概率 x 调整因子
换个表达形式就会更容易理解一些

P(“属于某类”|“具有某特征”)=P(“具有某特征”|“属于某类”)P(“属于某类”)/P(“具有某特征”)
贝叶斯方法把计算“具有某特征条件下属于某类(就是分类)”的概率转化为需要计算“属于某类条件下具有某特征(分别训练模型)”的概率,属于有监督学习
就用老师上课的例子来理解一下朴素贝叶斯公式

现在给我们的问题是,如果一堆西瓜,我们去挑瓜,比如我们挑中的某个西瓜的特点分别是青绿,蜷缩,浊响,凹陷,硬滑,密度和含糖率是特定的值 然后我们判断一下这个瓜是好瓜还是坏瓜
这是一个典型的分类问题,转为数学问题就是比较好瓜和坏瓜,谁的概率大,就能得出结果
P(好瓜|青绿,蜷缩,浊响,凹陷,硬滑,密度,含糖率)=p(青绿,蜷缩,浊响,凹陷,硬滑,密度,含糖率|好瓜)*p(好瓜)/p(青绿,蜷缩,浊响,凹陷,硬滑,密度,含糖率)
通过贝叶斯公式 我们就可以把求的内容转化成右边的3个量
p(青绿,蜷缩,蜷缩,凹陷,硬滑,密度,含糖率|好瓜)*p(好瓜)=p(青绿|好瓜)*p(蜷缩|好瓜)*p(凹陷|好瓜)*p(密度|好瓜)*p(密度|好瓜)*p(含糖率|好瓜)


代码练习
1、留言分类
在这个demo中 我们需要理解一下这两段文字的意思


import numpy as np
from functools import reduce
import math
#创建实验样本
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
# 类别标签向量,1代表侮辱性词汇,0代表非侮辱性词汇
classVec = [0,1,0,1,0,1]
print(sum(classVec))
return postingList,classVec
#将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
def createVocabList(dataSet):
vocabSet=set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet =vocabSet|set(document)
return list(vocabSet)
#根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0"
"""Parameters:
vocabList - createVocabList返回的列表
inputSet - 切分的词条列表
Returns:
returnVec - 文档向量,词集模型"""
def setOfWords2Vec(vocabList, inputSet):
# 创建一个其中所含元素都为0的向量
returnVec = [0] * len(vocabList)
# 遍历每个词条
for word in inputSet:
if word in vocabList:
# 如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
print("returnVec ",returnVec)
return returnVec
#朴素贝叶斯分类器训练函数
"""
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainMat
trainCategory - 训练类别标签向量,即loadDataSet返回的 classVec
Returns:
p0Vect - 非侮辱类的条件概率数组
p1Vect - 侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
"""
def trainNB0(trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix) #6
numWords = len(trainMatrix[0]) #32
pAbusive = sum(trainCategory) / float(numTrainDocs) #3/6
p0Num = np.ones(numWords)
p1Num = np.ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1: # 统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
print("p1Num p1Denom",p1Num,p1Denom)
else: # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
print("p0Num poDenom",p0Num,p0Denom)
p1Vect = p1Num/p1Denom #侮辱类的条件概率数组
p0Vect = p0Num/p0Denom #非侮辱类的条件概率数组
return p0Vect,p1Vect,pAbusive
"""
函数说明:朴素贝叶斯分类器分类函数
Parameters:
vec2Classify - 待分类的词条数组
p0Vec - 非侮辱类的条件概率数组
p1Vec -侮辱类的条件概率数组
pClass1 - 文档属于侮辱类的概率
Returns:
0 - 属于非侮辱类
1 - 属于侮辱类
"""
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + math.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + math.log(1.0 - pClass1)
print('p0:',p0)
print('p1:',p1)
if p1 > p0:
return 1
else:
return 0
if __name__ == '__main__':
listOPosts, listClasses = loadDataSet() # 创建实验样本
myVocabList = createVocabList(listOPosts) # 创建词汇表
trainMat = []
for postinDoc in listOPosts:
print(postinDoc)
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
print("trainMat ",trainMat)
print("len(trainMat)",len(trainMat))
print("len(trainMat[0])",len(trainMat[0]))
p0V, p1V, pAb = trainNB0(np.array(trainMat), np.array(listClasses))
print("p0V ",p0V)
print("p1V ",p1V)
print("pAb ",pAb)
testEntry = ['love', 'my', 'dalmation'] # 测试样本1
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) # 测试样本向量化
if classifyNB(thisDoc, p0V, p1V, pAb):
print(testEntry, '属于侮辱类') # 执行分类并打印分类结果
else:
print(testEntry, '属于非侮辱类') # 执行分类并打印分类结果
testEntry = ['stupid', 'garbage'] # 测试样本2
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) # 测试样本向量化
if classifyNB(thisDoc, p0V, p1V, pAb):
print(testEntry, '属于侮辱类') # 执行分类并打印分类结果
else:
print(testEntry, '属于非侮辱类') 
2、垃圾邮件分类
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26):
# 读取每个垃圾邮件,并字符串转换成字符串列表
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read())
print(i," ",wordList)
docList.append(wordList)
fullText.append(wordList)
# 标记垃圾邮件,1表示垃圾文件
classList.append(1)
print(i," ",classList)
# 读取每个非垃圾邮件,并字符串转换成字符串列表
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read())
print(i, " ", wordList)
docList.append(wordList)
fullText.append(wordList)
# 标记非垃圾邮件,0表示非垃圾文件
classList.append(0)
# 创建词汇表,不重复
vocabList = createVocabList(docList)
trainingSet = list(range(50)); testSet = []
print("trainingSet",trainingSet)
for i in range(10):
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat = []; trainClasses = []
# 遍历训练集
for docIndex in trainingSet:
# 将生成的词集模型添加到训练矩阵中
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
# 将类别添加到训练集类别标签系向量中
trainClasses.append(classList[docIndex])
# 训练朴素贝叶斯模型
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))
errorCount = 0
# 遍历测试集
for docIndex in testSet:
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print("分类错误的测试集:",docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))3、My Data
该数据集根据数据中的评论,采用朴素贝叶斯算法来分析用户情感,将用户评论划分为“好评”,“差评”
数据集:外卖评价数据集
1代表好评 0代表差评

1.9 朴素贝叶斯-scikit-learn中文社区 https://scikit-learn.org.cn/view/88.html
https://scikit-learn.org.cn/view/88.html
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
#获取数据集
#data为我们所采用的的数据,review为用户评论数据,label为标签,label=1表示好评,label=0表示差评
print("loading train dataset ...")
data = pd.read_csv(r"C:/Users/xxd52/Desktop/pinglun.csv")
review=data['review'].values
label=data['label'].values
# 把数据分成训练数据集和测试数据集,80%作为训练集,20%作为测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(review, label, test_size=0.20, random_state=2);
t1=Xtrain.tolist() #把数组转换为列表
t2=Ytrain.tolist()
news_train = {'review':t1, 'label': np.array(t2)}
#把这些评论全部转换为由TF-IDF表达的权重信息构成的向量
#TfidfVectorizer类是用来把所有评论转化为矩阵,该矩阵每行都代表一条评论
# 一行中的每个元素代表一个对应的词语的重要性,词语的重要性由TF-IDF来表示。
print("vectorizing train dataset ...")
vectorizer = TfidfVectorizer(encoding='latin-1')
X_train = vectorizer.fit_transform((d for d in news_train["review"]))
#直接使用MultinomialNB对数据集进行训练
y_train = news_train["label"]
#alphaα表示平滑系数,其值越小,越容易造成过拟合,值太大,容易造成欠拟合
clf = MultinomialNB(alpha=0.01)
clf.fit(X_train, y_train)
train_score = clf.score(X_train, y_train)
print("loading test dataset ...")
t1_test=Xtest.tolist()
t2_test=Ytest.tolist()
news_test = {'review':t1_test, 'label': np.array(t2_test)}
print("vectorizing test dataset ...")
X_test = vectorizer.transform((d for d in news_test['review']))
y_test = news_test["label"]
pred = clf.predict(X_test[0])
print("predicting test dataset ...")
pred = clf.predict(X_test)
print(pred)
test_score = clf.score(X_test, y_test)
print("test score: {0}".format(test_score))运行结果

Reference
基于朴素贝叶斯算法实现情感分类https://www.heywhale.com/mw/project/60521d5e5316950016efa577https://www.heywhale.com/mw/project/60521d5e5316950016efa577
带你搞懂朴素贝叶斯分类算法_人工智能-CSDN博客_朴素贝叶斯算法https://blog.csdn.net/AMDS123/article/details/70173402?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163810726716780261950626%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163810726716780261950626&biz_id=0&spm=1018.2226.3001.4187