Hive——入门介绍
目录
- 1.Hive概述
- 2.Hive架构
- 3.Hive启动
- 4.Hive数据库操作
-
- 4.1.创建数据库--默认方式
- 4.2.创建数据库--指定存储路径
- 4.3.查看数据库的详细信息
- 4.4.删除数据库
- 5.Hive数据库表操作
-
- 5.1.创建数据库表的语法
- 5.2.内部表操作
- 5.3.外部表操作
- 5.4.分区表操作
- 6.Hive查询操作
-
- 6.1.基本语法
- 6.2.基本查询
- 6.3.聚合函数
- 6.4.where语句
- 6.5.比较运算符
- 6.6逻辑运算符
- 6.7.分组查询
- 6.8.Having语句
- 6.9.排序order by
- 6.10.limit语句
- 6.11.多表查询
- 6.12.子查询
- 7.Hive内置函数
-
- 7.1.数学函数
- 7.2.字符串函数
- 7.3.日期函数
- 7.4.条件判断函数
- 7.5.行转列操作
- 7.6.开窗函数
1.Hive概述
Hive是一个构建在Hadoop上的数据仓库框架。最初,Hive是由Facebook开发,后来移交由Apache软件基金会开发,并作为一个Apache开源项目。Hive具有以下特点:
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类sQL查询功能。
- Hive它能够存储很大的数据集,可以直接访问存储在Apache HDFS或其他数据存储系统(如Apache HBase)中的文件。
- Hive支持MapReduce、Spark、Tez这三种分布式计算引擎。
2.Hive架构
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以存储、查询和分析存储在分布式存储系统中的大规模数据集。Hive定义了简单的类sQL查询语言,通过底层的计算引擎,将SQL转为具体的计算任务进行执行。Hive架构图如下图所示:
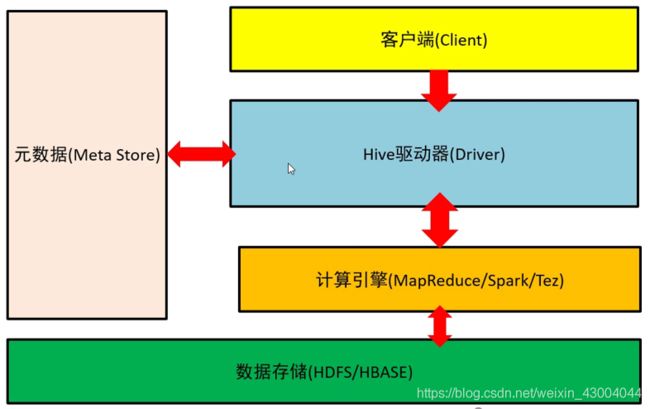
| 组件 | 功能 |
|---|---|
| 客户端 | 编写类SQL语句 |
| Hive驱动器 | 解析、优化SQL |
| 计算引擎 | 执行SQL |
| 数据存储 | 存储源数据和结果数据 |
| 元数据 | 记录数据库和表的特征信息 |
3.Hive启动
(1)启动集群中的所有组件(具体操作以自己的实际配置为准)
cd /export/onekey
./start-all.sh
(2)使用终端连接Hive(具体操作以自己的实际配置为准)
- 进入到/export/server/spark-2.3.0-bin-hadoop2.7/bin目录中
- 执行以下命令:./beeline
- 输入:!connect jdbc:hive2://node1:10000,回车
- 输入用户名:root
- 直接回车,即可使用命令行连接到Hive,然后就可以执行HQL了。
4.Hive数据库操作
4.1.创建数据库–默认方式
create database if not exists myhive; #创建数据库
show databases; #查看所有数据库
特别说明:
(1)if not exists:该参数可选,表示如果数据存在则不创建(不加该参数则报错),不存在则创建。
(2)hive的数据库置默认存放在/user/hive/warehouse目录下
4.2.创建数据库–指定存储路径
create database myhive2 location '/myhive2’; #在myhive2目录下创建数据库myhive2
show databases; #查看所有数据库
特别说明:location用来指定数据库的存放目录
4.3.查看数据库的详细信息
desc database myhive; #查看数据库myhive的详细信息
4.4.删除数据库
drop database myhive; #删除数据库myhive,如果数据库myhive下面有数据表,那么就会报错
drop database myhive cascade; #强制删除数据库myhive,包含数据库下面的表一起删除
5.Hive数据库表操作
5.1.创建数据库表的语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[LOCATION hdfs_path]
……
表字段类型

5.2.内部表操作
(1)创建表
未被external修饰的是内部表(managed table),内部表又称管理表,内部表不适合用于共享数据。
create database test; #创建数据库test
use mytest; #选择数据库test
create table stu(id int,name string); #在数据库test中创建表stu,stu有id和name两个字段
show tables; #查询表数据
创建表之后,Hive会在对应的数据库文件夹下创建对应的表目录
(2)查看表结构
desc stu; #查看stu表结构的基本信息
desc formatted stu; #查看stu表结构的详细信息
(3)删除表
drop table stu; #删除表stu
(4)插入数据
(4.1)直接插入数据
#对于Hive中的表,可以通过insert into 指令向表中插入数据
use mytest; #选择数据库
create table stu(id int,name string); #创建表
insert into stu values(1,'zhangsan’);
insert into stu values(2,'lisi');
select * from stu; #查询数据
缺点:该方式每次插入都会在表目录中生成对应的数据文件,不推荐使用。

(4.2)load数据加载
Load命令用于将外部数据加载到Hive表中。
#语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)]
#说明:LOCAL 表示从本地文件系统加载,否则是从HDFS加载
#应用1:本地加载
#创建表,同时指定文件的分隔符
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t’ ;
#向表加载数据
load data local inpath '/export/data/hivedatas/stu.txt' into table stu2;
#应用2:HDFS加载
#创建表,同时指定文件的分隔符
create table if not exists stu3(id int ,name string)
row format delimited fields terminated by '\t’ ;
#提前准备好HDFS中的数据
hadoop fs -mkdir -p /hivedatas
cd /export/data/hivedatas
hadoop fs –put stu.txt /hivedatas/
#向表加载数据(加载完成后,/hivedatas目录下的stu.txt会被剪切到/user/hive/warehouse/mytest.db/stu3/目录下)
load data inpath '/hivedatas/stu.txt' into table stu3;
(5)元数据以及内部表的特点
(5.1)元数据
| Hive是建立在hadoop之上的数据仓库,存在hive里的数据实际上就是存在HDFS上,都是以文件的形式存在 |
|---|
| Hive元数据用用来记录数据库和表的特征信息,比如数据库的名字、存储路径、表的名字、字段信息,表文件存储路径等等。 |
| 在学习过程中Hive的元数据是保存在Mysql数据库中的。 |
(5.2)内部表的特点
| hive内部表信息存储默认的文件路径是在/user/hive/warehouse/databasename.db/tablename/目录 |
|---|
| hive内部表在进行drop操作时,其表中的数据以及表的元数据信息均会被删除 |
| 内部表一般可以用来做中间表或者临时表 |
5.3.外部表操作
(1)创建表
创建表时,使用external关键字修饰则为外部表,外部表数据可用于共享。
#创建学生表
create external table student (sid string,sname string,sbirth string , ssex string) row format delimited fields terminated by '\t' location '/hive_table/student';
#创建老师表
create external table teacher (tid string,tname string) row format delimited fields terminated by '\t' location '/hive_table/teacher';
创建表之后,Hive会在Location指定目录下创建对应的表目录:

(2)加载数据
外部表加载数据也是通过load命令来完成。
#给学生表添加数据
load data local inpath '/export/data/hivedatas/student.txt' into table student;
#给老师表添加数据,并覆盖已有数据
load data local inpath '/export/data/hivedatas/teacher.txt' overwrite into table teacher;
#查询数据
select * from student;
select * from teacher;
(3)外部表的特点
(3.1)外部表在进行drop操作的时,仅会删除元数据,而不删除HDFS上的文件。例如当删除掉某一个表后,它所对应的元数据文件依然存在,并且当重新创建该表时,其原本的数据会根据存在的元数据文件进行恢复。
(3.2)外部表一般用于数据共享表,比较安全
5.4.分区表操作
(1)介绍
大数据中,最常用的一种思想就是分治,分区表实际就是对应HDFS文件系统上的的独立的文件夹,该文件夹下是该分区所有数据文件。分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。Hive中可以创建一级分区表和多级分区表。
(2)创建一级分区表
# 创建一级分区表
create table score(sid string,cid string, sscore int) partitioned by (month string) row format delimited fields terminated by '\t';
# 加载数据
load data local inpath '/export/data/hivedatas/score.txt' into table score partition (month='202107');
(3)创建多级分区表
# 创建多级分区表
create table score2(sid string,cid string, sscore int) partitioned by (year string,month string, day string) row format delimited fields terminated by '\t';
# 加载数据
load data local inpath '/export/data/hivedatas/score.txt' into table score2 partition(year='2021',month='07',day='01');
(4)查看分区
show partitions score;
结果如图所示:

(5)添加分区
# 添加一个分区
alter table score add partition(month='202108’);
# 添加多个分区
alter table score add partition(month='202109') partition(month = '202110');
(6)删除分区
alter table score drop partition(month = '202110');
6.Hive查询操作
6.1.基本语法
select [distinct]select_expr, select_expr, ...
from table_reference
[where where_condition]
[group by col_list]
[having where_condition]
[order by col_list] ...
[limit number]
说明:
| select | 查询关键字 |
|---|---|
| distinct | 去重 |
| from | 指定要查询的表 |
| where | 指定查询条件 |
| group by | 分组查询 |
| having | 对分组后的结果进行条件筛选 |
| order by | 排序 |
| limit | 查询指定的记录数 |
6.2.基本查询
# 全表查询
select * from score;
# 选择特定列查询
select sid ,cid from score;
# 使用别名查询
select sid as stu_id,cid course_id from score;
6.3.聚合函数
SparkSQL中提供的聚合函数可以用来统计、求和、求最值等等。
| COUNT | 统计行数量 |
|---|---|
| SUM | 获取单个列的合计值 |
| AVG | 计算某个列的平均值 |
| MAX | 计算列的最大值 |
| MIN | 计算列的最小值 |
应用:
# 1.求总行数(count)
select count(1) from score;
select count(*) from score;
# 2.求分数的最大值(max)
select max(sscore) from score;
# 3.求分数的最小值(min)
select min(sscore) from score;
# 4.求分数的总和(sum)
select sum(sscore) from score;
# 5.求分数的平均值(avg)
select avg(sscore) from score;
6.4.where语句
Where条件语句的写法非常丰富,使用where语句可以查询满足条件的数据,where语句紧随from关键字。
#查询出分数大于60的数据
select * from score where sscore > 60;
6.5.比较运算符

6.6逻辑运算符
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
6.7.分组查询
分组关键字是GROUP BY,该语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。注意使用group by分组之后,select后面的字段只能是分组字段和聚合函数。
# 1.计算每个学生的平均分数
select sid ,avg(sscore) from score group by sid;
# 2.计算每个学生最高成绩
select sid ,max(sscore) from score group by sid;
6.8.Having语句
Having语句通常与order by 语句联合使用,用来过滤由order by 语句返回的记录集。Having语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。
# 求每个学生平均分数大于80的人
select sid,avg(sscore) avgscore from score group by sid having avgscore > 80;
6.9.排序order by
排序关键字是order by ,用于根据指定的列对结果集进行排序。在排序时,可以指定排序顺序,asc为升序(默认),desc为降序。
# 1.查询学生的成绩,并按照分数升序排列
select * from score order by sscore asc;
# 2.按照分数的平均值降序排序
select sid ,avg(sscore) avg from score group by sid order by avg desc;
6.10.limit语句
limit子句用于限制查询结果返回的数量。
# 查询5条数据
select * from student limit 5;
6.11.多表查询
(1)内连接查询,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来
# 隐式内连接:
select * from A,B where 条件;
# 显示内连接:
select * from A inner join B on 条件;
应用:
#查询每个老师对应的课程信息
#隐式内连接
select * from teacher t, course c where t.tid = c.tid;
#显式内连接
select * from teacher t inner join course c on t.tid = c.tid;
select * from teacher t join course c on t.tid = c.tid;
(2)外连接查询
# 左外连接:left outer join,JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
select * from A left outer join B on 条件;
# 右外连接:right outer join,JOIN操作符右边表中符合WHERE子句的所有记录将会被返回
select * from A right outer join B on 条件;
# 满外连接:full outer join,将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代
select * from A full outer join B on 条件;
6.12.子查询
子查询即查询允许把一个查询嵌套在另一个查询当中,本质上就是select的嵌套。
# 查询成绩最高的学生的sid
select sid from score a,(select max(sscore) max_score from score) b where a.sscore = b.max_score;
7.Hive内置函数
在SparkSQL中提供了很多的内置函数,或者叫内嵌函数,包括聚合函数、数学函数,字符串函数、转换函数,日期函数,条件函数,表生成函数等等。
7.1.数学函数
指定精度取整函数:round
语法:round(double a, int d)
说明:返回指定精度d的double类型
举例:
hive> select round(3.1415926,4);
3.1416
取随机数函数: rand
语法:rand(),rand(int seed)
说明:返回一个0到1范围内的随机数。如果指定种子seed,则会返回固定的随机数
举例:
hive> select rand();
0.5577432776034763
hive> select rand(100);
0.7220096548596434
7.2.字符串函数
字符串连接函数-带分隔符:concat_ws
语法: concat_ws(string SEP, string A, string B…)
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
举例:
hive> select concat_ws(',','abc','def','gh’);
abc,def,gh
字符串截取函数:substr,substring
语法:
substr(string A, int start, int len),
substring(string A, intstart, int len)
返回值:
string 说明:返回字符串A从start位置开始,长度为len的字符串
举例:
hive> select substr('abcde',3,2);
cd
hive>select substring('abcde',-2,2);
de
7.3.日期函数
日期转年函数:year
语法:year(string date)
说明:返回日期中的年。
举例:
hive> select year('2012-12-08’);
2012
日期增加函数:date_add
语法:date_add(string startdate, int days)
说明:返回开始日期startdate增加days天后的日期。
举例:
hive> select date_add('2012-12-08',10);
2012-12-18
日期减少函数:date_sub
语法:date_sub (string startdate, int days)
返回值:string 说明:返回开始日期startdate减少days天后的日期。
举例:
hive> select date_sub('2012-12-08',10);
2012-11-28
7.4.条件判断函数
语法: CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
返回值: T
说明:如果a为TRUE,则返回b;如果c为TRUE,则返回d;否则返回
应用:
select
sid,
cid,
case
when sscore >= 60
then '及格'
when sscore < 60
then '不及格'
else
'其它'
end as flag
from
score
order by sid;
结果如下:

7.5.行转列操作
# 创建表
create table emp(
deptno int,
ename string
)row format delimited fields terminated by '\t'
# 加载数据
load data local inpath '/export/data/hivedatas/emp.txt'into table emp
# 行转列
# collect_set(ename):根据字段ename分组后,把分在一组的数据合并在一起,默认分隔符’,’ ,并且会自动进行去重操作
select deptno,concat_ws(" | ",collect_set(ename)) as ems from emp group by deptno;
转后之前:

转换之后:

7.6.开窗函数
(1)rank(),dense_rank(),row_number()
# 创建表
create table user_ access (
user_id string,
createtime string, --day
pv int
)
row format DELIMITED FIELDS TERMINATED BY ',';
# 加载数据:
load data local inpath '/export/data/hivedatas/user_access.txt' into table user_log;
# 实现分组排名
# RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
# DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
# ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列
select
user_id,createtime,pv,
rank() over(partition by user_id order by pv desc) as rn1,
dense_rank() over(partition by user_id order by pv desc) as rn2,
row_number() over(partition by user_id order by pv desc) as rn3
from
user_access
结果如下:

(2)sum()
# 从第一行累加到当前行
select
user_id,createtime,pv,
sum(pv) over(partition by user_id order by createtime rows between unbounded preceding and current row) as pv2
from
user_access
结果如下:
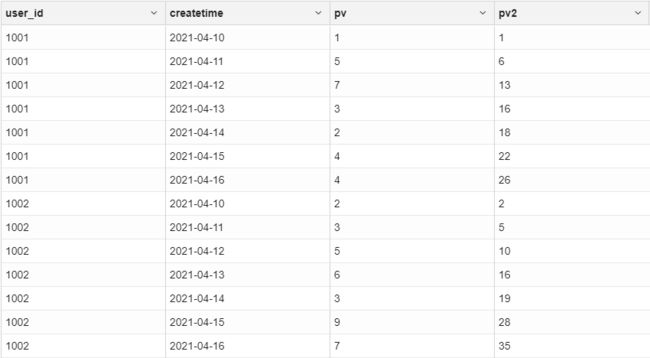
# 从前3行累加到当前行
select
user_id,createtime,pv,
sum(pv) over(partition by user_id order by createtime rows between 3 preceding and current row) as pv2
from
user_access
结果如下:

# 从前3行累加到后一行
select
user_id,createtime,pv,
sum(pv) over(partition by user_id order by createtime rows between 3 preceding and 1 following) as pv2
from
user_access
结果如下:

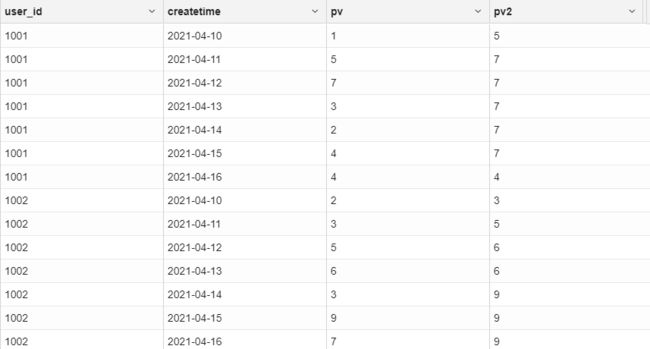
(3)max()
# 选出从第一行到当前行元素值最大的
select
user_id,createtime,pv,
max(pv) over(partition by user_id order by createtime rows between unbounded preceding and current row) as pv2
from
user_access
结果如下:

# 选出前3行到后1行元素值最大的
select
user_id,createtime,pv,
max(pv) over(partition by user_id order by createtime rows between 3 preceding and 1 following) as pv2
from
user_access
结果如下:
还有例如avg(),min()等函数的用法与上述函数类似,此处不再赘述。