高斯混合模型GMM及EM迭代求解算法(含代码实现)
高斯混合模型GMM及EM迭代求解算法(含代码实现)
高斯分布与高斯混合模型
高斯分布
高斯分布大家都很熟悉了,下面是一元高斯分布的概率密度函数(Probability Density Function,PDF):
P ( x ) = N ( μ , σ 2 ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) P(x)=N(\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x-\mu)^2}{2\sigma^2}) P(x)=N(μ,σ2)=2πσ1exp(−2σ2(x−μ)2)
其中 μ \mu μ 和 σ 2 \sigma^2 σ2 分别是该高斯分布的均值和方差,而如果是多元高斯分布,则为:
P ( x ) = 1 ( 2 π ) D 2 ∣ Σ ∣ 1 2 exp ( − ( x − μ ) T Σ − 1 ( x − μ ) 2 ) P(x)=\frac{1}{(2\pi)^{\frac{D}{2}}|\Sigma|^{\frac{1}{2}}}\exp(-\frac{(x-\mu)^T\Sigma^{-1}(x-\mu)}{2}) P(x)=(2π)2D∣Σ∣211exp(−2(x−μ)TΣ−1(x−μ))
其中 μ \mu μ 、 Σ \Sigma Σ 和 D D D 分别是均值、协方差矩阵和数据维度。
高斯混合模型
高斯混合模型,顾名思义,就是由多个单高斯模型组合而成的模型。具体来说,它是具有如下形式的概率分布模型:
P ( x ∣ θ ) = ∑ k = 1 K α k ϕ ( x ∣ θ k ) P(x|\theta)=\sum_{k=1}^K\alpha_k\phi(x|\theta_k) P(x∣θ)=k=1∑Kαkϕ(x∣θk)
其中:
- K K K 是该混合模型中单高斯模型的个数
- α k \alpha_k αk 是各个单高斯模型的权重系数,它满足: α k ≥ 0 \alpha_k\ge0 αk≥0 且 ∑ k = 1 K α k = 1 \sum_{k=1}^K\alpha_k=1 ∑k=1Kαk=1
- ϕ ( x ∣ θ k ) \phi(x|\theta_k) ϕ(x∣θk) 是第 k k k 个单高斯模型的概率密度,也称为 k k k 个分模型
- θ k \theta_k θk 表示第 k k k 个单高斯模型的参数(均值和方差),即 θ k = ( μ k , σ k 2 ) \theta_k=(\mu_k,\sigma_k^2) θk=(μk,σk2)
为什么是高斯?
对于一般地混合模型,我们可以选用任何自己认为合适的单概率分布模型。这
里使用高斯混合模型是因为由中心极限定理可以得知,将现实世界中的数据分布假设为高斯分布是比较合理的,并且高斯分布具备很好的数学性质以及良好的计算性能。
为什么要混合?
现实世界中,我们的样本通常都是会有多个特征来描述,此时如果使用单个高斯模型来对问题进行建模,显然表达能力是不足的。而如果我们使用多个高斯模型,按照一定的权重参数将它们组合,将大大提高整个模型的表达能力。
具体来说,我们知道单个高斯模型是单峰的(如图所示),即只有某一个区间的概率特别高,两端都是逐渐降低的。而如果我们使用两个高斯模型混合,得到的模型表达能力更强,可以处理现实世界中的复杂分布。
理论上,混合高斯模型的概率密度函数曲线可以是任意形状的非线性函数。
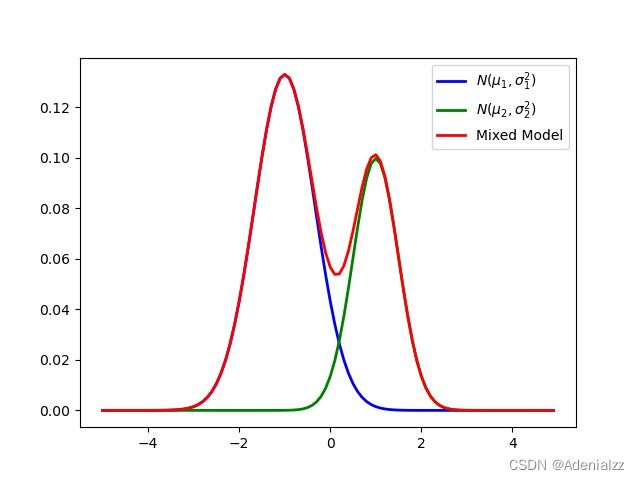
高斯混合模型的三种理解角度
几何角度
从几何的角度来看高斯混合模型,在图像上(如图1所示),它由多个高斯分布叠加而成,是多个高斯分布的加权平均值。
P ( x ∣ θ ) = ∑ k = 1 K α k ϕ ( x ∣ θ k ) P(x|\theta)=\sum_{k=1}^K\alpha_k\phi(x|\theta_k) P(x∣θ)=k=1∑Kαkϕ(x∣θk)
在这个角度下,这里的 α k \alpha_k αk 就是每个单高斯模型的权重。
混合模型的角度
高斯混合模型中有两个变量:
- X = ( x 1 , x 2 , … , x N ) X=(x_1,x_2,\dots,x_N) X=(x1,x2,…,xN):观测数据
- Z = ( z 1 , z 2 , … , z N ) Z=(z_1,z_2,\dots,z_N) Z=(z1,z2,…,zN):隐变量
这两个变量合称为完全数据。
关于什么是隐变量,这是笔者从网络上找到的一个例子,感觉这个例子和 GMM 中的引入的隐变量意思非常接近(可结合下面样本生成的角度来理解),并且比较直观:
举个例子吧
一个人拿着n个袋子,里面有m种颜色不同的球。现在这个人随机地抓球,规则如下:
先随机挑一个袋子
从这个袋子中随机挑一个球
如果你站在这个人旁边,你目睹了整个过程:这个人选了哪个袋子、抓出来的球是什么颜色的。然后你把每次选择的袋子和抓出来的球的颜色都记录下来(样本观察值),那个人不停地抓,你不停地记。最终你就可以通过你的记录,推测出每个袋子里每种球颜色的大致比例。并且你记录的越多,推测的就越准(中心极限定理)。
然而,抓球的人觉得这样很不爽,于是决定不告诉你他从哪个袋子里抓的球,只告诉你抓出来的球的颜色是什么。这时候,“选袋子”的过程由于你看不见,其实就相当于是一个隐变量。
隐变量在很多地方都是能够出现的。现在我们经常说的隐变量主要强调它的“latent”。所以广义上的隐变量主要就是指“不能被直接观察到,但是对系统的状态和能观察到的输出存在影响的一种东西”。
在 GMM 中, Z Z Z 就是我们引入一个隐变量: z i , i = [ 1 , 2 , … , N ] z_i,i=[1,2,\dots,N] zi,i=[1,2,…,N] ,用它来表示对应的观测样本 x i x_i xi 是属于哪一个高斯分布,具体来说,是样本 x i x_i xi 属于每一个高斯分布的概率(类似软分类的思想)。
这样,很自然地, Z Z Z 应当是一个离散随机变量,并服从多项分布。其分布律为:
| Z Z Z | C 1 C_1 C1 | C 2 C_2 C2 | … \dots … | C K C_K CK |
|---|---|---|---|---|
| P ( z ) P(z) P(z) | p 1 p_1 p1 | p 2 p_2 p2 | … \dots … | p K p_K pK |
其中 C k C_k Ck 表示第 k k k 个单高斯模型, ∑ k = 1 K p k = 1 \sum_{k=1}^Kp_k=1 ∑k=1Kpk=1 。
现在我们推导在混合模型的角度下,高斯混合模型的概率分布:
P ( X ) = ∫ z P ( X , Z ) d z = ∑ Z P ( X , Z = C k ) = ∑ k = 1 K P ( Z = C k ) P ( X ∣ Z = C k ) = ∑ k = 1 K p k N ( X ∣ μ k , σ k 2 ) = ∑ k = 1 K p k ϕ ( x ∣ θ k ) \begin{align} P(X)&=\int_zP(X,Z)dz\\ &=\sum_ZP(X,Z=C_k)\\ &=\sum_{k=1}^KP(Z=C_k)P(X|Z=C_k)\\ &=\sum_{k=1}^Kp_kN(X|\mu_k,\sigma_k^2)\\ &=\sum_{k=1}^Kp_k\phi(x|\theta_k) \end{align} P(X)=∫zP(X,Z)dz=Z∑P(X,Z=Ck)=k=1∑KP(Z=Ck)P(X∣Z=Ck)=k=1∑KpkN(X∣μk,σk2)=k=1∑Kpkϕ(x∣θk)
推导过程解释:由联合概率密度函数 P ( X , Z ) P(X,Z) P(X,Z) 求边缘概率密度函数 P ( X ) P(X) P(X),最直接的想法就是将另一个随机变量 Z Z Z 直接积掉,又由于这里的 Z Z Z 是一个离散的随机变量,因此应该是积分应该写为求和,然后由公式 P ( X , Y ) = P ( Y ) P ( X ∣ Y ) P(X,Y)=P(Y)P(X|Y) P(X,Y)=P(Y)P(X∣Y) 进行分解,此时前一项 P ( Z = C k ) P(Z=C_k) P(Z=Ck) 由分布律知就是 p k p_k pk ,而后一项条件概率 P ( X ∣ Z = C k ) P(X|Z=C_k) P(X∣Z=Ck) 表示的是在选定第 k k k 个高斯分布之后的概率密度函数,那自然就是其本身的概率密度函数 N ( X ∣ μ k , σ k 2 ) N(X|\mu_k,\sigma_k^2) N(X∣μk,σk2)。
这里的 p k p_k pk 表示的是多项分布 Z Z Z 的概率取值,这里的 p k p_k pk 其实对应的就是上一种角度中的权重系数 α k \alpha_k αk ,但是在两种不同的理解角度中有不同的物理含义。
从混合模型的角度来看,GMM是由离散的多项分布+连续的高斯分布组成。
样本生成的角度
GMM 是一个生成模型,从样本生成的角度来说:
对于每一个样本点 x i x_i xi ,我们可以认为它是通过这样的过程得到的 :先通过一个多项( K K K 项)分布选择一个单高斯模型(相当于掷一个有 K K K 个面的骰子),然后从对应的高斯分布中进行采样得到 x i x_i xi。
为什么MLE无法求出高斯混合模型的解析解
高斯混合模型的参数
高斯混合模型中的参数,就是我们公式中的 θ \theta θ ,是哪些呢?很明显的,参数包括每个单高斯模型对应的权重系数 α k \alpha_k αk 和每个单高斯模型自身的均值方差 θ k = ( μ k , σ k 2 ) \theta_k=(\mu_k,\sigma_k^2) θk=(μk,σk2) 。
即混合高斯模型中的参数:
θ = ( α 1 , α 2 , … , α K ; θ 1 , θ 2 , … , θ K ) = ( α 1 , α 2 , … , α K ; μ 1 , μ 2 , … , μ K ; σ 1 , σ 2 , … , σ K ) \theta=(\alpha_1,\alpha_2,\dots,\alpha_K;\theta_1,\theta_2,\dots,\theta_K)=(\alpha_1,\alpha_2,\dots,\alpha_K;\mu_1,\mu_2,\dots,\mu_K;\sigma_1,\sigma_2,\dots,\sigma_K) θ=(α1,α2,…,αK;θ1,θ2,…,θK)=(α1,α2,…,αK;μ1,μ2,…,μK;σ1,σ2,…,σK)
观测数据 x 1 , x 2 , … , x n x_1,x_2,\dots,x_n x1,x2,…,xn 由参数为 θ \theta θ 的高斯混合模型生成,
高斯混合模型的MLE尝试
对于单高斯模型,我们可以直接用极大似然估计 MLE 来求解。下面我们对混合高斯模型也进行类似的尝试,看能不能行得通:
θ ^ M L E = arg max θ P ( X ) = arg max θ log P ( X ) = arg max θ log P ( x 1 ) P ( x 2 ) … P ( X N ) = arg max θ log ∏ i = 1 N P ( x i ) = arg max θ ∑ i = 1 N log P ( x i ) = arg max θ ∑ i = 1 N log ∑ k = 1 K p k ϕ ( x ∣ θ k ) \begin{align} \hat{\theta}_{MLE}&=\arg\max_\theta P(X)\\ &=\arg\max_\theta \log P(X)\\ &=\arg\max_\theta\log P(x_1)P(x_2)\dots P(X_N)=\arg\max_\theta\log \prod_{i=1}^NP(x_i)\\ &=\arg\max_\theta\sum_{i=1}^N\log P(x_i)\\ &=\arg\max_\theta\sum_{i=1}^N\log \sum_{k=1}^Kp_k\phi(x|\theta_k) \end{align} θ^MLE=argθmaxP(X)=argθmaxlogP(X)=argθmaxlogP(x1)P(x2)…P(XN)=argθmaxlogi=1∏NP(xi)=argθmaxi=1∑NlogP(xi)=argθmaxi=1∑Nlogk=1∑Kpkϕ(x∣θk)
至此,下一步应该是对 θ k \theta_k θk 各个值进行求偏导,然后令导数为 0。
但是我们发现,在对数 log \log log 里面还有一个连加符号。对于对数里的连乘,我们可以利用对数的性质,直接拿出来,变为连加,但是对于对数里本身的连加符号,是非常难处理的。因此,到这一步之后,无法直接求出混合高斯模型的解析解。
接下来,我们将介绍如何利用 EM 算法来迭代求解高斯混合模型的参数 θ \theta θ 。
EM算法迭代求解高斯混合模型
EM算法的一般步骤
EM 算法是一种非监督期望最大化算法。其结合了极大似然和迭代求解的方法去预估数据的分布。EM 算法主要用来解决含有隐变量的混合模型的参数估计,非常适合求解高斯混合模型。
这里直接给出一般的算法步骤,详情见:[TODO]
EM 算法通过迭代求 L ( θ ) = log P ( X ∣ θ ) L(\theta)=\log P(X|\theta) L(θ)=logP(X∣θ) 的极大似然估计,每次迭代包含两部:E步,求期望;M步,求极大化。
算法流程:
-
输入:观测变量数据 X X X,隐变量数据 Z Z Z,联合分布 P ( X , Z ∣ θ ) P(X,Z|\theta) P(X,Z∣θ) ,条件分布: P ( Z ∣ X , θ ) P(Z|X,\theta) P(Z∣X,θ) ;
-
输出:模型参数 θ \theta θ ;
-
步骤
-
选择参数的初值 θ 0 \theta^{0} θ0 ,开始迭代;
-
E 步:记 θ t \theta^{t} θt 为第 t t t 次迭代参数 θ \theta θ 的估计值,在第 i + 1 i+1 i+1 次迭代的 E 步,计算:
Q ( θ , θ t ) = E Z [ log P ( X , Z ∣ θ ) ∣ X , θ ( t ) ] = ∑ Z log P ( X , Z ∣ θ ) P ( Z ∣ X , θ ( t ) ) \begin{align} Q(\theta,\theta^{t})&=\mathbb{E}_Z[\log P(X,Z|\theta)|X,\theta^{(t)}]\\ &=\sum_{Z}\log P(X,Z|\theta)P(Z|X,\theta^{(t)}) \end{align} Q(θ,θt)=EZ[logP(X,Z∣θ)∣X,θ(t)]=Z∑logP(X,Z∣θ)P(Z∣X,θ(t))
这里 P ( Z ∣ X , θ ( t ) ) P(Z|X,\theta^{(t)}) P(Z∣X,θ(t)) 为给定观测数据 X X X 和当前参数估计 θ ( t ) \theta^{(t)} θ(t) 下隐变量数据 Z Z Z 的条件概率分布; -
M 步:求使 Q ( θ , θ ( t ) ) Q(\theta,\theta^{(t)}) Q(θ,θ(t)) 极大化的 θ \theta θ ,确定第 t + 1 t+1 t+1 次迭代的参数估计值 θ t + 1 \theta^{t+1} θt+1 :
θ ( t + 1 ) = arg max θ Q ( θ , θ t ) \theta^{(t+1)}=\arg\max_{\theta}Q(\theta,\theta^{t}) θ(t+1)=argθmaxQ(θ,θt) -
重复 2、3 两步,直到收敛。
-
函数 Q ( θ , θ ( t ) ) Q(\theta,\theta^{(t)}) Q(θ,θ(t)) 是 EM 算法的核心,称为 Q Q Q 函数。
使用EM算法求解GMM推导
1 写出完全数据的对数似然函数
这里隐变量的定义与之前不同,是因为
回忆我们之前介绍的生成模型的角度,观测数据 x i , i = 1 , 2 , … , N x_i,i=1,2,\dots,N xi,i=1,2,…,N 是这样产生的:首先根据概率 α k \alpha_k αk 选择第 k k k 个单高斯分布模型 ϕ ( x ∣ θ k ) \phi(x|\theta_k) ϕ(x∣θk) ,然后根据 ϕ ( x ∣ θ k ) \phi(x|\theta_k) ϕ(x∣θk) 生成观测数据 x i x_i xi 。注意,观测数据 x i x_i xi 是已知的;反映观测数据 x i x_i xi 来自第 k k k 个单高斯模型的的数据是未知的,用隐变量 z i k z_{ik} zik 表示,其定义如下:
z i k = { 1 , 第 i 个观测来自第 k 个分模型 0 , 否则 i = 1 , 2 , … , N ; k = 1 , 2 , … , K z_{ik}=\begin{cases}1,\ \ \ 第i个观测来自第k个分模型 \\ 0,\ \ \ 否则\end{cases}\\ i=1,2,\dots,N;\ \ \ k=1,2,\dots,K zik={1, 第i个观测来自第k个分模型0, 否则i=1,2,…,N; k=1,2,…,K
隐变量 z i k z_{ik} zik 与观测数据 X X X 共同组成了完全数据,记为 ( x i , z i 1 , z i 2 , … , z i K ) , i = 1 , 2 , … , N (x_i,z_{i1},z_{i2},\dots,z_{iK}),\ \ \ i=1,2,\dots,N (xi,zi1,zi2,…,ziK), i=1,2,…,N 。
记 GMM 模型:
P ( x ∣ θ ) = ∑ k = 1 K α k ϕ ( x ∣ θ k ) P(x|\theta)=\sum_{k=1}^K\alpha_k\phi(x|\theta_k) P(x∣θ)=k=1∑Kαkϕ(x∣θk)
则有完全数据的似然函数:
P ( x , z ∣ θ ) = ∏ i = 1 N P ( x i , z i 1 , z i 2 , … , z i K ∣ θ ) = ∏ k = 1 K ∏ i = 1 N [ α k ϕ ( x i ∣ θ k ) ] z i k = ∏ k = 1 K α k n k ∏ i = 1 N [ ϕ ( x i ∣ θ k ) ] z i k = ∏ k = 1 K α k n k ∏ i = 1 N [ 1 2 π σ k exp ( − ( x i − μ k ) 2 2 σ k 2 ) ] z i k \begin{align} P(x,z|\theta)&=\prod_{i=1}^NP(x_i,z_{i1},z_{i2},\dots,z_{iK}|\theta)\\ &=\prod_{k=1}^K\prod_{i=1}^N[\alpha_k\phi(x_i|\theta_k)]^{z_{ik}}\\ &=\prod_{k=1}^K\alpha_k^{n_k}\prod_{i=1}^N[\phi(x_i|\theta_k)]^{z_{ik}}\\ &=\prod_{k=1}^K\alpha_k^{n_k}\prod_{i=1}^N[\frac{1}{\sqrt{2\pi}\sigma_k}\exp(-\frac{(x_i-\mu_k)^2}{2\sigma_k^2})]^{z_{ik}} \end{align} P(x,z∣θ)=i=1∏NP(xi,zi1,zi2,…,ziK∣θ)=k=1∏Ki=1∏N[αkϕ(xi∣θk)]zik=k=1∏Kαknki=1∏N[ϕ(xi∣θk)]zik=k=1∏Kαknki=1∏N[2πσk1exp(−2σk2(xi−μk)2)]zik
其中, n l = ∑ i = 1 N z i k n_l=\sum_{i=1}^Nz_{ik} nl=∑i=1Nzik , ∑ k = 1 K n k = N \sum_{k=1}^Kn_k=N ∑k=1Knk=N。
那么,完全数据的对输入似然函数为:
log P ( x , z ∣ θ ) = ∑ k = 1 K { ( n k log α k + ∑ j = 1 N z i k [ log ( 1 2 π ) − log σ k − 1 2 σ l 2 ( x i − μ k ) 2 ] } \log P(x,z|\theta)=\sum_{k=1}^K\{(n_k\log\alpha_k+\sum_{j=1}^Nz_{ik}[\log(\frac{1}{\sqrt{2\pi}})-\log \sigma_k-\frac{1}{2\sigma_l^2}(x_i-\mu_k)^2]\} logP(x,z∣θ)=k=1∑K{(nklogαk+j=1∑Nzik[log(2π1)−logσk−2σl21(xi−μk)2]}
2 E步,求期望,写出 Q Q Q 函数
Q ( θ , θ ( t ) = E ( log P ( x , z ∣ θ ) ∣ x , θ ( t ) ) = E { ∑ k = 1 K { ( n k log α k + ∑ j = 1 N z i k [ log ( 1 2 π ) − log σ k − 1 2 σ l 2 ( x i − μ k ) 2 ] } } = ∑ k = 1 K { ∑ i = 1 N ( E z i k ) log α k + ∑ i = 1 N ( E z i k [ log 1 2 π − log σ k − 1 2 σ k 2 ) ( x i − μ k ) 2 ] } \begin{align} Q(\theta,\theta^{(t)}&=\mathbb{E}(\log P(x,z|\theta)|x,\theta^{(t)})\\ &=\mathbb{E}\{\sum_{k=1}^K\{(n_k\log\alpha_k+\sum_{j=1}^Nz_{ik}[\log(\frac{1}{\sqrt{2\pi}})-\log \sigma_k-\frac{1}{2\sigma_l^2}(x_i-\mu_k)^2]\}\}\\ &=\sum_{k=1}^K\{\sum_{i=1}^N(\mathbb{E}z_{ik})\log \alpha_k+\sum_{i=1}^N(\mathbb{E}z_{ik}[\log \frac{1}{\sqrt{2\pi}}-\log\sigma_k-\frac{1}{2\sigma_k^2})(x_i-\mu_k)^2]\} \end{align} Q(θ,θ(t)=E(logP(x,z∣θ)∣x,θ(t))=E{k=1∑K{(nklogαk+j=1∑Nzik[log(2π1)−logσk−2σl21(xi−μk)2]}}=k=1∑K{i=1∑N(Ezik)logαk+i=1∑N(Ezik[log2π1−logσk−2σk21)(xi−μk)2]}
这里需要计算 E ( z i k ∣ x , θ ) \mathbb{E}(z_{ik}|x,\theta) E(zik∣x,θ),记为 z ^ i k \hat{z}_{ik} z^ik:
z ^ i k = E ( z i k ∣ x , θ ) = P ( z i k = 1 ∣ x , θ ) = P ( z i k = 1 , x i ∣ θ ) ∑ k = 1 K P ( z i k = 1 , x i ∣ θ ) = P ( x i ∣ z i k = 1 , θ ) P ( z i k = 1 ∣ θ ) ∑ k = 1 K P ( x i ∣ z i k = 1 , θ ) P ( z i k = 1 , θ ) = α k ϕ ( x i ∣ θ k ) ∑ k = 1 K α k ϕ ( x i ∣ θ k ) , i = 1 , 2 , … , N ; k = 1 , 2 , … , K \begin{align} \hat{z}_{ik}&=\mathbb{E}(z_{ik}|x,\theta)=P(z_{ik}=1|x,\theta)\\ &=\frac{P(z_{ik}=1,x_i|\theta)}{\sum_{k=1}^KP(z_{ik}=1,x_i|\theta)}\\ &=\frac{P(x_i|z_{ik}=1,\theta)P(z_{ik}=1|\theta)}{\sum_{k=1}^KP(x_i|z_{ik}=1,\theta)P(z_{ik}=1,\theta)}\\ &=\frac{\alpha_k\phi(x_i|\theta_k)}{\sum_{k=1}^K\alpha_k\phi(x_i|\theta_k)},\ \ i=1,2,\dots,N;\ k=1,2,\dots,K \end{align} z^ik=E(zik∣x,θ)=P(zik=1∣x,θ)=∑k=1KP(zik=1,xi∣θ)P(zik=1,xi∣θ)=∑k=1KP(xi∣zik=1,θ)P(zik=1,θ)P(xi∣zik=1,θ)P(zik=1∣θ)=∑k=1Kαkϕ(xi∣θk)αkϕ(xi∣θk), i=1,2,…,N; k=1,2,…,K
z ^ i k \hat{z}_{ik} z^ik 是当前模型参数下第 i i i 个观测数据来自第 k k k 个模型的概率,称为分模型 k k k 对观测数据 x i x_i xi 的响应程度。
将 z ^ i k = E z i k \hat{z}_{ik}=\mathbb{E}z_{ik} z^ik=Ezik 和 n k = ∑ i = 1 N E z i k n_k=\sum_{i=1}^N\mathbb{E}z_{ik} nk=∑i=1NEzik 代入得:
Q ( θ , θ ( t ) ) = ∑ k = 1 K { ∑ i = 1 N ( n k log α k + ∑ i = 1 N ( z ^ i k [ log 1 2 π − log σ k − 1 2 σ k 2 ) ( x i − μ k ) 2 ] } Q(\theta,\theta^{(t)})=\sum_{k=1}^K\{\sum_{i=1}^N(n_k\log \alpha_k+\sum_{i=1}^N(\hat{z}_{ik}[\log \frac{1}{\sqrt{2\pi}}-\log\sigma_k-\frac{1}{2\sigma_k^2})(x_i-\mu_k)^2]\} Q(θ,θ(t))=k=1∑K{i=1∑N(nklogαk+i=1∑N(z^ik[log2π1−logσk−2σk21)(xi−μk)2]}
3 M步,求极大
M 步是求函数 Q ( θ , θ ( t ) ) Q(\theta,\theta^{(t)}) Q(θ,θ(t)) 取得极大值时的 θ \theta θ ,作为 θ ( t + 1 ) \theta^{(t+1)} θ(t+1) :
θ ( t + 1 ) = arg max θ Q ( θ , θ ( t ) ) \theta^{(t+1)}=\arg\max_{\theta}Q(\theta,\theta^{(t)}) θ(t+1)=argθmaxQ(θ,θ(t))
我们之前介绍过,GMM 模型要估计的参数为:
θ = ( α 1 , α 2 , … , α K ; θ 1 , θ 2 , … , θ K ) = ( α 1 , α 2 , … , α K ; μ 1 , μ 2 , … , μ K ; σ 1 , σ 2 , … , σ K ) \theta=(\alpha_1,\alpha_2,\dots,\alpha_K;\theta_1,\theta_2,\dots,\theta_K)=(\alpha_1,\alpha_2,\dots,\alpha_K;\mu_1,\mu_2,\dots,\mu_K;\sigma_1,\sigma_2,\dots,\sigma_K) θ=(α1,α2,…,αK;θ1,θ2,…,θK)=(α1,α2,…,αK;μ1,μ2,…,μK;σ1,σ2,…,σK)
对于 μ k \mu_k μk 和 σ k 2 \sigma_k^2 σk2 ,我们只需根据上式分别对他们求偏导并令其为 0 即可;
而对于 α ^ k \hat{\alpha}_k α^k ,还需要注意约束条件 ∑ k = 1 K α k = 1 \sum_{k=1}^K\alpha_k=1 ∑k=1Kαk=1 。
结果如下:
μ ^ k = ∑ i = 1 N z ^ i k x i ∑ i = 1 N z ^ i k σ ^ k 2 = ∑ i = 1 N z ^ i k ( x i − μ k ) 2 ∑ i = 1 N z ^ i k α ^ k = n k N = ∑ i = 1 N z ^ i k N \hat{\mu}_k=\frac{\sum_{i=1}^N\hat{z}_{ik}x_i}{\sum_{i=1}^N\hat{z}_{ik}}\\ \hat{\sigma}_{k}^2=\frac{\sum_{i=1}^N\hat{z}_{ik}(x_i-\mu_k)^2}{\sum_{i=1}^N\hat{z}_{ik}}\\ \hat{\alpha}_k=\frac{n_k}{N}=\frac{\sum_{i=1}^N\hat{z}_{ik}}{N} μ^k=∑i=1Nz^ik∑i=1Nz^ikxiσ^k2=∑i=1Nz^ik∑i=1Nz^ik(xi−μk)2α^k=Nnk=N∑i=1Nz^ik
重复上述 2、3 步,直到收敛。
GMM模型的EM算法步骤
至此,可以给出GMM模型的EM算法步骤:
-
选择参数的初值 θ 0 \theta^{0} θ0 ,开始迭代;
-
E 步:记 θ t \theta^{t} θt 为第 t t t 次迭代参数 θ \theta θ 的估计值,在第 i + 1 i+1 i+1 次迭代的 E 步,计算:
Q ( θ , θ ( t ) ) = ∑ k = 1 K { ∑ i = 1 N ( n k log α k + ∑ i = 1 N ( z ^ i k [ log 1 2 π − log σ k − 1 2 σ k 2 ) ( x i − μ k ) 2 ] } Q(\theta,\theta^{(t)})=\sum_{k=1}^K\{\sum_{i=1}^N(n_k\log \alpha_k+\sum_{i=1}^N(\hat{z}_{ik}[\log \frac{1}{\sqrt{2\pi}}-\log\sigma_k-\frac{1}{2\sigma_k^2})(x_i-\mu_k)^2]\} Q(θ,θ(t))=k=1∑K{i=1∑N(nklogαk+i=1∑N(z^ik[log2π1−logσk−2σk21)(xi−μk)2]}
这里 P ( Z ∣ X , θ ( t ) ) P(Z|X,\theta^{(t)}) P(Z∣X,θ(t)) 为给定观测数据 X X X 和当前参数估计 θ ( t ) \theta^{(t)} θ(t) 下隐变量数据 Z Z Z 的条件概率分布; -
M 步:求使 Q ( θ , θ ( t ) ) Q(\theta,\theta^{(t)}) Q(θ,θ(t)) 极大化的 θ \theta θ ,确定第 t + 1 t+1 t+1 次迭代的参数估计值 θ t + 1 \theta^{t+1} θt+1 :
μ ^ k = ∑ i = 1 N z ^ i k x i ∑ i = 1 N z ^ i k σ ^ k 2 = ∑ i = 1 N z ^ i k ( x i − μ k ) 2 ∑ i = 1 N z ^ i k α ^ k = n k N = ∑ i = 1 N z ^ i k N \hat{\mu}_k=\frac{\sum_{i=1}^N\hat{z}_{ik}x_i}{\sum_{i=1}^N\hat{z}_{ik}}\\ \hat{\sigma}_{k}^2=\frac{\sum_{i=1}^N\hat{z}_{ik}(x_i-\mu_k)^2}{\sum_{i=1}^N\hat{z}_{ik}}\\ \hat{\alpha}_k=\frac{n_k}{N}=\frac{\sum_{i=1}^N\hat{z}_{ik}}{N} μ^k=∑i=1Nz^ik∑i=1Nz^ikxiσ^k2=∑i=1Nz^ik∑i=1Nz^ik(xi−μk)2α^k=Nnk=N∑i=1Nz^ik -
重复 2、3 两步,直到收敛。
代码
给出参考实现[代码][[https://github.com/wl-lei/upload/blob/master/homework/GMM.py]
import numpy as np
import random
def calc_prob(X, K, pMu, pSigma):
N = X.shape[0]
D = X.shape[1]
Px = np.zeros((N, K))
for i in range(K):
Xshift = X-np.tile(pMu[i], (N, 1))
lambda_flag = np.e**(-5)
conv = pSigma[i]+lambda_flag*np.eye(D)
inv_pSigma = np.linalg.inv(conv)
tmp = np.sum(np.dot(Xshift, inv_pSigma)*Xshift, axis=1)
coef = (2*np.pi)**(-D/2)*np.sqrt(np.linalg.det(inv_pSigma))
Px[:, i] = coef*np.e**(-1/2*tmp)
return Px
def gmm(X, K): #用array来处理
threshold = np.e**(-15)
N = X.shape[0]
D = X.shape[1]
rndp = random.sample(np.arange(N).tolist(),K)
centroids = X[rndp,:]
pMu = centroids
pPi = np.zeros((1, K))
pSigma = np.zeros((K, D, D))
dist = np.tile(np.sum(X*X, axis=1).reshape(N,1), (1, K))+np.tile(np.sum(pMu*pMu, axis=1), (N, 1))-2*np.dot(X, pMu.T)
labels = np.argmin(dist,axis=1)
for i in range(K):
index = labels == i
Xk = X[index,:]
pPi[:,i] = (Xk.shape[0])/N
pSigma[i] = np.cov(Xk.T)
Loss = -float("inf")
while True:
Px = calc_prob(X, K, pMu, pSigma)
pGamma = Px*np.tile(pPi, (N, 1))
pGamma = pGamma/np.tile(np.sum(pGamma, axis=1).reshape(N,1), (1, K))
Nk = np.sum(pGamma, axis=0)
pMu = np.dot(np.dot(np.diag(1/Nk), pGamma.T), X)
pPi = Nk/N
for i in range(K):
Xshift = X-np.tile(pMu[i], (N, 1))
pSigma[i] = np.dot(Xshift.T, np.dot(np.diag(pGamma[:, i]), Xshift))/Nk[i]
L = np.sum(np.log(np.dot(Px, pPi.T)), axis=0)
if L-Loss < threshold:
break
Loss = L
return Px,pMu,pSigma,pPi
if __name__ == "__main__":
Data_list = []
with open("data.txt", 'r') as file:
for line in file.readlines():
point = []
point.append(float(line.split()[0]))
point.append(float(line.split()[1]))
Data_list.append(point)
Data = np.array(Data_list)
Px,pMu,pSigma,pPi = gmm(Data, 2)
print(Px,pMu,pSigma,pPi)
Ref
- 高斯混合模型(GMM)
- 高斯混合模型白板推导
- 隐变量是什么
- 详解EM算法与混合高斯模型(Gaussian mixture model, GMM)
- 高斯混合模型(GMM)的两种详解及简化