用HTML绘制三线表,R语言-临床三线表
自动生成临床三线表
按照流行病学和相关领域的标准做法是,期刊文章的第一张表格,我们通常称为“表1”,是一份表,列出按暴露程度分层的研究人群基线特征的描述性统计数据。这个包使得使用R生成这样一个表相当简单。输出格式是html(它的优点是很容易复制到Word文档中;Chrome浏览器工作得很好)。
实际上这个包还能够对表格有更多定制的功能,但这样用起来爽是需要代价的,更多的代码与CSS知识
官方文档参考资料(https://benjaminrich.github.io/table1/vignettes/table1-examples.html)
R包table1
if(!require(table1)) install.packages("table1",ask=F,update=F)
## Loading required package: table1
## Warning: package 'table1' was built under R version 3.6.1
##
## Attaching package: 'table1'
## The following objects are masked from 'package:base':
##
## units, units
require(table1)
Example1
使用boot包中的自带数据
melanoma数据集
library(boot)
## Warning: package 'boot' was built under R version 3.6.1
melanoma2
head(melanoma)
## time status sex age year thickness ulcer
## 1 10 3 1 76 1972 6.76 1
## 2 30 3 1 56 1968 0.65 0
## 3 35 2 1 41 1977 1.34 0
## 4 99 3 0 71 1968 2.90 0
## 5 185 1 1 52 1965 12.08 1
## 6 204 1 1 28 1971 4.84 1
dim(melanoma)
## [1] 205 7
## input melanoma是一个数据框
## 对我们感兴趣的变量因子化
melanoma2$status
factor(melanoma2$status,
levels=c(2,1,3),
labels=c("Alive", # 第一个作为参考组
"Melanoma death",
"Non-melanoma death"))
可以来绘制一个表格试试,意思就是以感兴趣的因子作为分类status,同理这个status可以是任意大家感兴趣的变量。
格式为~感兴趣的基线变量|感兴趣的分类变量,data
table1(~ factor(sex) + age + factor(ulcer) + thickness | status, data=melanoma2)
image.png
这样的表格已经可以了,但仍然可以改进
基线分类变量sex,ulcer没有很好的label,基线的连续型变量可以指定单位units,下面来improve
## 给分类变量sex指定标签
melanoma2$sex
factor(melanoma2$sex, levels=c(1,0),
labels=c("Male",
"Female"))
## 给分类变量ulcer指定标签
melanoma2$ulcer
factor(melanoma2$ulcer, levels=c(0,1),
labels=c("Absent",
"Present"))
## 给变量名指定标签
label(melanoma2$sex)
label(melanoma2$age)
label(melanoma2$ulcer)
label(melanoma2$thickness)
## 给连续型变量指定单位
units(melanoma2$age)
units(melanoma2$thickness)
## 再增加overall统计量
table1(~ sex + age + ulcer + thickness | status, data=melanoma2, overall="Total")
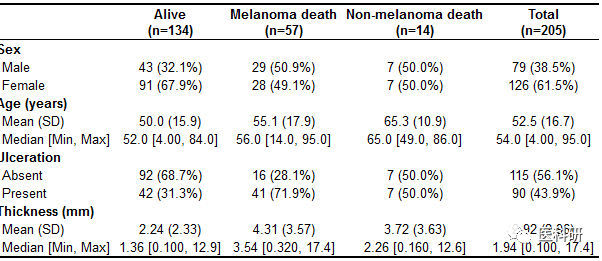
image.png
细节控制
labels
variables=list(sex="Sex",
age="Age (years)",
ulcer="Ulceration",
thickness="Thickness (mm)"),
groups=list("", "", "Death"))##表格上的第一级Death
# 重新给status命名标签,death放到上面去
levels(melanoma2$status)
#按想要的顺序顺序设置分组或列,
#Total放第一列,split分开status
strata
# 添加渲染风格-连续型变量与分类变量展示不同
# 连续型渲染风格函数
my.render.cont
with(stats.apply.rounding(stats.default(x), digits=2), c("",
"Mean (SD)"=sprintf("%s (± %s)", MEAN, SD)))
}
# 分类变量渲染风格
my.render.cat
c("", sapply(stats.default(x), function(y) with(y,
sprintf("%d (%0.0f %%)", FREQ, PCT))))
}
## 结果
## groupsapn为分组的个数,1为Total, 1为Alive,以及2为Death
## 增加了Death的亚组
table1(strata, labels, groupspan=c(1, 1, 2),
render.continuous=my.render.cont, render.categorical=my.render.cat)
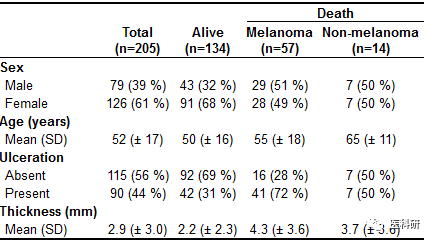
image.png
Example2
自己模拟一个数据
函数式编程
…把其余参数全部传递,…的参数传递到了sample函数
f
set.seed(427)
## 构造数据框
n
dat
dat$treat
dat$age
dat$sex
dat$wt
dat$wt[sample.int(n, 5)]
head(dat)
## id treat age sex wt
## 1 1 Treated 18 Female 62.6
## 2 2 Treated 50 Male 57.4
## 3 3 Treated 37 Male 104.6
## 4 4 Treated 25 Female 55.5
## 5 5 Placebo 60 Female 58.4
## 6 6 Treated 44 Female 41.9
标签命名
单位
## 分类变量
label(dat$age)
label(dat$sex)
label(dat$wt)
label(dat$treat)
## 连续型变量
units(dat$age)
units(dat$wt)
## 绘制默认表格
table1(~ age + sex + wt | treat, data=dat)

image.png
删除overall
table1(~ age + sex + wt | treat, data=dat, overall=F)
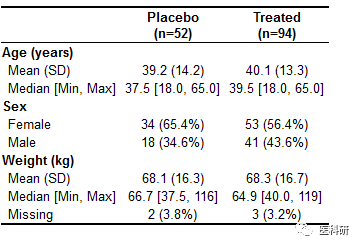
image.png
轻松进行多个变量分类,一键定制
table1(~ age + wt | treat*sex, data=dat)
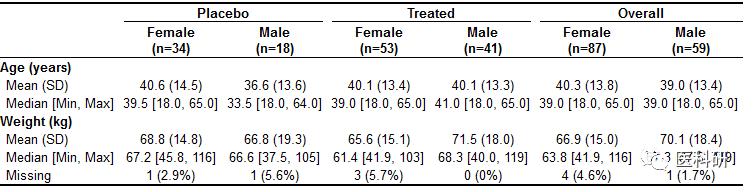
image.png
改变顺序
table1(~ age + wt | treat*sex, data=dat)
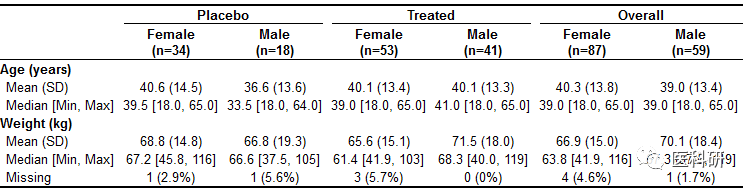
image.png
无感兴趣变量统计表格
table1(~ treat + age + sex + wt, data=dat)
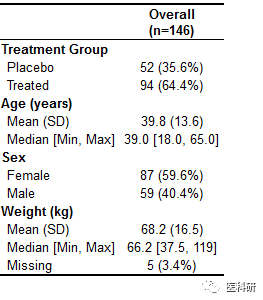
image.png
更复杂的定制
## 给原数据增加一个dose列
dat$dose
## 给dose加标签
dat$dose
## strata定制
## split指定按dose分亚组
strata
list("All treated"=subset(dat, treat=="Treated")), ## all treated组
list(Overall=dat))## overall
labels
variables=list(age=render.varlabel(dat$age),
sex=render.varlabel(dat$sex),
wt=render.varlabel(dat$wt)),
groups=list("", "Treated", ""))## 一级分组标签
## groupspan二级分组告诉你标题栏的线包括几个变量
## 对应groups
table1(strata, labels, groupspan=c(1, 3, 1))
image.png
显示不同变量的不同统计数据
例如下面的渲染风格
age展示Median
wt展示mean
rndr
if (!is.numeric(x)) return(render.categorical.default(x))
what
age = "Median [Min, Max]",
wt = "Mean (SD)")
parse.abbrev.render.code(c("", what))(x)
}
table1(~ age + sex + wt | treat, data=dat,
render=rndr)
改变表格的样式
内置了多个渲染风格
zebra: alternating shaded and unshaded rows (zebra stripes)
grid: show all grid lines
shade: shade the header row(s) in gray
times: use a serif font
center: center all columns, including the first which contains the row labels
## 更换表格风格,用topclass参数设置
## zebra似乎不错
table1(~ age + sex + wt | treat, data=dat, topclass="Rtable1-zebra")
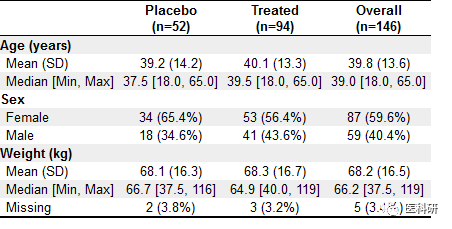
image.png
增加一列pvalue
实际上这个功能本身是没有的,但是可以通过添加一个渲染来实现
library(MatchIt)
## Warning: package 'MatchIt' was built under R version 3.6.1
data(lalonde)
head(lalonde)
## treat age educ black hispan married nodegree re74 re75 re78
## NSW1 1 37 11 1 0 1 1 0 0 9930.0460
## NSW2 1 22 9 0 1 0 1 0 0 3595.8940
## NSW3 1 30 12 1 0 0 0 0 0 24909.4500
## NSW4 1 27 11 1 0 0 1 0 0 7506.1460
## NSW5 1 33 8 1 0 0 1 0 0 289.7899
## NSW6 1 22 9 1 0 0 1 0 0 4056.4940
## 分类变量
lalonde$treat
lalonde$black
lalonde$hispan
lalonde$married
lalonde$nodegree
lalonde$black
lalonde$hispan
lalonde$married
lalonde$nodegree
##连续变量
label(lalonde$black)
label(lalonde$hispan)
label(lalonde$married)
label(lalonde$nodegree)
label(lalonde$age)
label(lalonde$re74)
label(lalonde$re75)
label(lalonde$re78)
units(lalonde$age)
rndr
if (length(x) == 0) {
y
s
if (is.numeric(y)) {
p
} else {
p
}
s[2]
s
} else {
render.default(x=x, name=name, ...)
}
}
rndr.strat
ifelse(n==0, label, render.strat.default(label, n, ...))
}
## 绘图
table1(~ age + black + hispan + married + nodegree + re74 + re75 + re78 | treat,
data=lalonde, droplevels=F, render=rndr, render.strat=rndr.strat, overall=F)

image.png
本期内容就到这里,我是白介素2,下期再见。
相关阅读: