一文彻底搞清Linux中块设备驱动的深层次原理和编写方法
【摘要】本文主要讲述了在Linux环境下的块设备驱动的常见数据结构和内核接口,并以一个实际例子讲述了块设备驱动的编写方法。
1.前提知识
- 一个块驱动提供对块存储设备(比如 SD 卡、EMMC、NAND Flash、Nor Flash、SPI Flash、机械硬盘、固态硬盘等)以固定大小(块的大小由内核决定,常常是 4096 字节 )的块为基本单位,进行随机的存取。
- 一个扇区, 是一个小块, 它的大小常常由底层的硬件决定,但在内核中,扇区大小固定为512字节。如果你的设备使用不同的扇区大小,你必须相应地调整内核的扇区号。
2. 注册
1.块驱动的注册/注销
以下函数位于
- 注册函数
int register_blkdev(unsigned int major, const char *name);- major:被注册设备的主设备号,如果 major 传递为 0, 内核分配一个新的主编号并且返回它
给调用者。 - name:设备的名字,用于在/proc/devices/目录下显示。
- major:被注册设备的主设备号,如果 major 传递为 0, 内核分配一个新的主编号并且返回它
- 注销函数
int unregister_blkdev(unsigned int major, const char *name);- 参数必须和注册时的一样,否则返回-EINVAL错误。
- 操作函数
类似字符设备通过 file_operations操作,块设备通过struct block_device_operations 操作设备,其包含如下成员接口:
struct block_device_operations {
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
int (*ioctl) (struct inode *, struct file *, unsigned, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned, unsigned long);
long (*compat_ioctl) (struct file *, unsigned, unsigned long);
int (*direct_access) (struct block_device *, sector_t, unsigned long *);
int (*media_changed) (struct gendisk *); //检查介质是否改变
int (*revalidate_disk) (struct gendisk *); //响应一个介质的改变
int (*getgeo)(struct block_device *, struct hd_geometry *);
struct module *owner; //指向拥有这个结构的模块,常取值为THIS_MODULE
};
对比字符设备驱动的操作函数,它没有读写函数。这是因为在块 I/O 子系统中,读写操作由请求函数来处理。介绍他们之前,我们先了解一下代表磁盘的结构struck gendisk 及其注册方法。
2. gendisk
struct gendisk (定义于
-
定义
struct gendisk { int major; /* major number of driver */ int first_minor; int minors; /* 次设备个数,通常取16或者64,若取1代表该磁盘不可分区 */ char disk_name[32]; /* 磁盘名,出现在/proc/partitions 和 sysfs中 */ struct hd_struct **part; /* [indexed by minor] */ int part_uevent_suppress; struct block_device_operations *fops; //设备操作集合 struct request_queue *queue; //请求队列(用来管理这个设备的 I/O 请求的结构) void *private_data; sector_t capacity; //驱动器的容量, 以 512字节扇区来计。需通过set_capacity接口赋值 int flags; //描述驱动器的属性,可取GENHD_FL_REMOVABLE、GENHD_FL_CD、GENHD_FL_SUPPRESS_PARTITIONS_INFO等 struct device *driverfs_dev; struct kobject kobj; struct kobject *holder_dir; struct kobject *slave_dir; struct timer_rand_state *random; int policy; atomic_t sync_io; /* RAID */ unsigned long stamp; int in_flight; #ifdef CONFIG_SMP struct disk_stats *dkstats; #else struct disk_stats dkstats; #endif struct work_struct async_notify; }; -
分配/释放
-
驱动不能自己分配这个结构,而是需要通过接口进行动态分配:
struct gendisk *alloc_disk(int minors); //minor表示磁盘分区数,一经赋值,不可更改 -
当不再需要一个磁盘时, 它应当被释放
void del_gendisk(struct gendisk *gd);
-
-
初始化/添加
-
分配一个 gendisk 结构并不代表系统可使用这个磁盘了,我们还必须对其初始化,最后调用add_disk接口添加到内核:
void add_disk(struct gendisk *gd);需要注意的是,一旦调用了该接口,就代表该磁盘已经可用了,内核可随时利用block_device_operations中的操着函数对其进行操作,所以要务必确保在调用该函数前,驱动已经完全初始化好了所有内容。
-
-
举例:(实现一套内存中的虚拟磁盘驱动器. 对每个驱动器, sbull 分配(使用vmalloc, 为了简单)一个内存数组; 它接着使这个数组可通过块操作来使用。这个 sbull 驱动可通过分区这个驱动器, 在上面建立文件系统, 以及加载到系统层级中来测试 )
-
获取主设备号
sbull_major = 0; sbull_major = register_blkdev(sbull_major, "sbull"); if (sbull_major <= 0) { printk(KERN_WARNING "sbull: unable to get major number\n"); return -EBUSY; } -
自定义磁盘设备结构体
struct sbull_dev { int size; /* Device size in sectors */ u8 *data; /* The data array */ short users; /* How many users */ short media_change; /* Flag a media change? */ spinlock_t lock; /* For mutual exclusion */ struct request_queue *queue; /* The device request queue */ struct gendisk *gd; /* The gendisk structure */ struct timer_list timer; /* For simulated media changes */ }; -
初始化自定义设备结构体
struct sbull_dev sbulldev; struct sbull_dev *dev = &sbulldev; memset (dev, 0, sizeof (struct sbull_dev)); dev->size = nsectors * hardsect_size; //扇区数*硬件扇区大小 /* 1.分配磁盘空间 */ dev->data = vmalloc(dev->size); //用内存模拟的磁盘空间 if (dev->data == NULL) { printk (KERN_NOTICE "vmalloc failure.\n"); return; } /* 2.初始化请求队列 */ spin_lock_init(&dev->lock); dev->queue = blk_init_queue(sbull_request, &dev->lock); //sbull_request 是实际进行块读和写请求的函数 if (dev->queue == NULL) { printk (KERN_NOTICE "init_queue failure.\n"); return; } /* 3.分配、初始化、安装对应的 gendisk 结构 */ dev->gd = alloc_disk(SBULL_MINORS); if (!dev->gd) { printk (KERN_NOTICE "alloc_disk failure\n"); goto out_vfree; } dev->gd->major = sbull_major; dev->gd->first_minor = which*SBULL_MINORS; dev->gd->fops = &sbull_ops; dev->gd->queue = dev->queue; dev->gd->private_data = dev; snprintf (dev->gd->disk_name, 32, "sbull%c", which + 'a');//第一个设备是 sbulla, 第二个是 sbullb set_capacity(dev->gd, nsectors*(hardsect_size/KERNEL_SECTOR_SIZE)); add_disk(dev->gd);
-
3、块设备操作
在讲解请求处理之前,我们先对 block_device_operations 下的部分操作函数进行介绍。本文块设备sbull 驱动的另一个特性: 它模拟一个可移出的设备。无论何时最后一个用户关闭设备, 一个 30 秒的定时器被设置; 如果设备在这个时间内不被打开, 设备的内容被清除, 并且内核被告知介质已被改变。下面围绕这个特性,对其操作函数进行介绍。
1.open和release
为实现模拟的介质移出, 驱动维护一个用户计数,当最后一个用户关闭设备时,用户计数为0,驱动也就知道是时候将介质移除了。
-
当一个节点引用一个块设备, i_bdev->bd_disk 包含一个指向关联 gendisk 结构的指针; 这个指针可用来获得一个驱动的给设备的内部数据结构:
static int sbull_open(struct inode *inode, struct file *filp) { struct sbull_dev *dev = inode->i_bdev->bd_disk->private_data; del_timer_sync(&dev->timer); //删除30秒的“移除介质定时器” filp->private_data = dev; spin_lock(&dev->lock); if (!dev->users) check_disk_change(inode->i_bdev); //检查介质是否改变 dev->users++; //递增用户计数 spin_unlock(&dev->lock); return 0; } -
释放方法的任务是递减用户计数, 以及 启动介质移出定时器
static int sbull_release(struct inode *inode, struct file *filp) { struct sbull_dev *dev = inode->i_bdev->bd_disk->private_data; spin_lock(&dev->lock); dev->users--; if (!dev->users) //如果用户数为0,则启动介质移除定时器 { dev->timer.expires = jiffies + INVALIDATE_DELAY; add_timer(&dev->timer); } spin_unlock(&dev->lock); return 0; } -
在一个处理真实的硬件设备的驱动中, open 和 release 方法应当相应地设置驱动和硬件的状态。包括起停磁盘、加锁一个可移出设备的门、分配 DMA 缓冲等等 。
2. media_changed和revalidate
如果你的磁盘是支持可移出的,则驱动中需要实现这两个接口函数。若不支持插拔,则可以忽略他们。
- 当用户调用check_disk_change 接口时,会触发media_changed 函数被调用。它主要用来查看介质是否已经被改变 :
int sbull_media_changed(struct gendisk *gd)
{
struct sbull_dev *dev = gd->private_data;
return dev->media_change;
}
-
revalidate 方法在介质改变后被调用,如果有新的介质被插入的话,它的工作是做任何需要的事情来准备驱动对新介质的操作。 在调用 revalidate 之后, 内核试图重新读分区表并且启动这个设备。本文仅仅复位 media_change 标志并且清零设备内存来模拟一个空盘插入 :
int sbull_revalidate(struct gendisk *gd) { struct sbull_dev *dev = gd->private_data; if (dev->media_change) { dev->media_change = 0; memset(dev->data, 0, dev->size); } return 0; }3. ioctl
实际上, 一个现代的块驱动根本不必实现许多的 ioctl 命令。我们在此实现ioctl就做一个任务,返回设备结构。为什么需要这个设备结构?因为我们的设备是纯粹虚拟的并且和磁道和柱面没任何关系,甚至大部分真正的块硬件都已很多年不再有很多更复杂的结构。
内核不关心一个块设备的结构,只把它看作一个扇区的线性数组。但是, 有某些用户工具仍然想能够查询一个磁盘的排列。如fdisk 工具,它编辑分区表, 依靠柱面信息并且如果这个信息没有则不能正确工作。
我们希望本文中的 sbull 设备是可分区的( 即便使用老的, 简单的工具)。 因此, 我们提供了一个 ioctl 方法,它提供一个可靠的能够匹配我们设备容量的结构假象。其实大部分现代磁盘驱动也做类似的事情。 需要注意的是,扇区计数要被转换成匹配内核使用的 512字节。
int sbull_ioctl (struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg) { long size; //设备容量(字节) struct hd_geometry geo; struct sbull_dev *dev = filp->private_data; switch(cmd) { case HDIO_GETGEO: /* * Get geometry: since we are a virtual device, we have to make * up something plausible. So we claim 16 sectors, four heads, * and calculate the corresponding number of cylinders. We set the * start of data at sector four. */ size = dev->size * (hardsect_size/KERNEL_SECTOR_SIZE); geo.cylinders = (size & ~0x3f) >> 6; geo.heads = 4; geo.sectors = 16; geo.start = 4; if (copy_to_user((void __user *) arg, &geo, sizeof(geo))) return -EFAULT; return 0; } return -ENOTTY; /* unknown command */ }
4、请求处理
一个磁盘驱动的性能可能是系统整个性能的关键部分. 因此, 内核的块子系统编写时在性能上帮我们考虑了很多,所以在编写驱动时得以简单,但是如果你的驱动要在一个更高层次上操作复杂的硬件,那就另当别论理论。
每个块驱动的核心是它的请求函数,下面我们分别予以讲述。
1.请求接口原型
当需要处理对设备的读, 写, 或者其他操作时,设备驱动的请求接口request被调用,每个请求接口都有一个请求队列作为其参数,队列里面链接的是一些具体的传输请求。这些传输请求被一些调度算法安排在某一时刻集中通过请求接口向系统进行申请执行。在此期间,请求接口持有一个自旋锁以保证其在原子上下文中运行。在请求函数持有锁时, 队列锁阻止内核去排队任何对设备的其他请求。另外,请求函数的启动(常常地)与任何用户空间进程之间是完全异步的,所以你不能假设内核运行在发起当前请求的进程上下文。
-
块驱动的请求方法的原型
void request(request_queue_t *queue); -
请求队列的创建函数
dev->queue = blk_init_queue(sbull_request, &dev->lock);- sbull_request:队列所属的请求接口(函数)
- dev->lock:请求队列的自旋锁
2.请求接口编程
一个最简单的实现请求的方法如下:
static void sbull_request(request_queue_t *q)
{
struct request *req; //表示一个块的I/O请求,后文详细介绍
while ((req = elv_next_request(q)) != NULL) {
struct sbull_dev *dev = req->rq_disk->private_data;
if (! blk_fs_request(req)) {
printk (KERN_NOTICE "Skip non-fs request\n");
end_request(req, 0);
continue;
}
sbull_transfer(dev, req->sector, req->current_nr_sectors,
req->buffer, rq_data_dir(req));
end_request(req, 1);
}
}
-
内核函数
elv_next_request获得请求队列中第一个未完成的请求,都完成了则返回NULL。注意,它返回后不会从请求队列里去除那个未完成的请求,即如果你连续调用它 2 次,它 2 次都返回同一个请求结构。 -
内核函数
blk_fs_request用来判断当前请求是否属于文件系统请求,如果不是,则将其通过end_request 函数结束该请求,并置参数succeeded为0,表示请求失败。void end_request(struct request *req, int succeeded); -
若属于文件系统请求,则调用传输函数进行数据传输,之后调用参数succeeded为1的end_request函数向系统报告请求成功完成。
static void sbull_transfer(struct sbull_dev *dev, unsigned long sector, unsigned long nsect, char *buffer, int write) { unsigned long offset = sector*KERNEL_SECTOR_SIZE; //数据传输的起始字节 unsigned long nbytes = nsect*KERNEL_SECTOR_SIZE; //数据传输的总的字节大小 if ((offset + nbytes) > dev->size) //判断是否超出设备大小范围 { printk (KERN_NOTICE "Beyond-end write (%ld %ld)\n", offset, nbytes); return; } if (write) memcpy(dev->data + offset, buffer, nbytes); //写数据到设备 else memcpy(buffer, dev->data + offset, nbytes); //从设备读数据 }- sector:设备上的起始扇区。所有这样的在内核和驱动之间传递的数目, 是以 512字节扇区来表示的 。
- nsect:要被传送的扇区(512-字节)数量。
- buffer:数据应当被传送到或者从的内核缓冲区指针。
- write:数据传输方向,0表示从设备读,1表示写到设备。可以用宏函数
rq_data_dir(struct request *req)计算出某请求的传输方向。
-
以上代码实现了一个简单的基于 RAM 的磁盘设备。但是,对于真实块设备,它不是一个实际可用的驱动。 原因如下:
- 以上代码实现了一次处理一个请求的功能,但对于高性能块设备来说,它需要可以同时处理多个请求。
- 磁盘操作的最高开销常常是读写头的定位,块驱动要具有优化请求队列,使之找到邻近的请求并且组合它们为更大的一个请求操作。
- 要想达到以上目的,需要对请求队列、请求结构和bio 结构 有更深入的理解。下文将继续阐述。
5、请求队列
内核中的一个块 I/O 请求的队列是一个相当复杂的数据结构,但驱动编写者不必全部了解。其中主要包含你当前设备可以处理的请求类型:它们的最大大小, 多少不同的段可进入一个请求, 硬件扇区大小, 对齐要求等等。
一个请求队列还保留了一个函数接口,用于选择对所有请求的调度算法,以最大化性能的方式向设备提交其中的IO请求。例如电梯调度算法表示调整不同的请求顺序,以确保每次可以让磁头按同一方向走。又如,2.6内核提供了一个“底线调度器”,确保每个请求在预设的最大时间内被满足;以及一个"预测调度器", 它实际上在一个预想中的读请求之后短暂停止设备,这样另一个邻近的读将几乎是马上到达。
I/O 调度器还负责合并邻近的请求. 当一个新 I/O 请求被提交给调度器, 它在队列里搜寻包含邻近扇区的请求; 如果找到一个, 并且如果结果的请求不是太大, 这 2 个请求被合并。
请求队列用struct request_queue 或者 request_queue_t 类型表示,他们在drivers/block/ll_rw_block.c 或者elevator.c 中找到。
1. 队列的创建和删除
如同之前说过的,请求队列是一个动态的数据结构,他只能通过特定的函数进行创建和初始化:
request_queue_t *blk_init_queue(request_fn_proc *request, spinlock_t *lock);
- 你需要检查其返回值以防失败,因为一个请求队列变量需要申请不少内存空间,因此可能会失败;
- 作为初始化的一部分,你可以将创建的请求队列指针赋值给queuedata,就如同其它结构中看到的private_data
void blk_cleanup_queue(request_queue_t *);
- 在模块卸载时,调用该函数销毁申请的请求队列,并释放其占据的内存资源。
2. 排队函数
在你调用这些函数之前,必须持有队列锁:
struct request *elv_next_request(request_queue_t *queue);
- 它返回指向下一个要处理的请求的指针(由 I/O 调度器所决定的),若没有请求要处理则返回 NULL 。
- elv_next_request 会保留这个请求在队列上, 但是会标识它为活动的; 这个标识阻止了 I/O 调度器试图将其与其它其他的请求进行合并。
void blkdev_dequeue_request(struct request *req);
- 该函数从一个队列中去除一个请求。
void elv_requeue_request(request_queue_t *queue, struct request *req);
- 向队列queue中放置一个出列请求req。
3. 控制函数
可被驱动用来控制一个请求队列如何操作的函数:
void blk_stop_queue(request_queue_t *queue);
void blk_start_queue(request_queue_t *queue);
- 如果你的设备目前不能处理等候的请求队列,你可调用blk_stop_queue 来告知块层 暂停响应。
- 当设备可处理更多请求时,可调用blk_start_queue来告知块层 重启队列。
- 无论是哪一个函数,队列锁必须被持有。
void blk_queue_bounce_limit(request_queue_t *queue, u64 dma_addr);
- 告知内核设备可进行 DMA 的最高物理地址。如果一个请求包含一个超出这个限制的内存引用, 一个反弹缓冲将被用来给这个操作,应当尽量避免。
- 可在这个参数中提供任何可能的值, 或者使用预先定义的符号:
- BLK_BOUNCE_HIGH :使用反弹缓冲给高内存页,此为默认值
- BLK_BOUNCE_ISA :驱动只可 DMA 到 16MB 的 ISA 区
- BLK_BOUCE_ANY:驱动可进行 DMA 到任何地址
void blk_queue_max_sectors(request_queue_t *queue, unsigned short max);
void blk_queue_max_phys_segments(request_queue_t *queue, unsigned short max);
void blk_queue_max_hw_segments(request_queue_t *queue, unsigned short max);
void blk_queue_max_segment_size(request_queue_t *queue, unsigned int max);
- …_sectors:以扇区为单位,设置请求的最大的大小,缺省是 255
- …_phys_segments:在一个请求中,驱动准备处理多少物理段(系统内存中不相邻的区) ,缺省是 128。
- …hw_segments:在一个请求中,设备可处理的最多的段数。缺省是 128。
- …_segment_size:任一个请求的段可能是多大字节,缺省是 65536 字节。
void blk_queue_segment_boundary(request_queue_t *queue, unsigned long mask);
- 一些设备无法处理跨越一个特殊大小内存边界的请求。如果你的设备是其中之一, 使用这个函数来告知内核这个边界。例如,如果你的设备处理跨 4MB 边界的请求有困难,则可传递一个 0x3fffff 掩码,缺省的掩码是 0xffffffff。
void blk_queue_dma_alignment(request_queue_t *queue, int mask);
- 告知内核关于你的设备施加于 DMA 传送的内存对齐限制的函数。
- 所有的请求被创建时,都有给定的对齐,并且请求的长度也必须匹配这个对齐。缺省的掩码是 0x1ff,即所有的请求被对齐到 512字节边界。
void blk_queue_hardsect_size(request_queue_t *queue, unsigned short max);
- 告知内核你的设备的硬件扇区大小。
- 所有由内核产生的请求,必须是这个扇区大小的倍数且是被正确对齐的。
6、请求结构的分析
每个请求结构代表一个块 I/O 请求,而且它也可能是由几个在更高层次上的独立的请求合并而成的。一个请求常常对应块设备中的多个连续的扇区,但这些扇区却有可能对应整个内存空间的任意一段。即一个请求被表示为多个段,每个对对应内存中的一段缓存。内核可能合并多个涉及磁盘上邻近扇区的请求, 但是它从不合并在单个请求结构中的读和写操作。
一个请求结构被实现为一个 bio 结构的链表及一些维护信息。
struct request {
...
request_queue_t *q;
...
struct bio *bio;
struct bio *biotail;
...
};
- 一个请求结构的内容是很多的,作为驱动编程者,最需要关注的就是其中的
bio结构体,它是一个块IO请求的底层描述。
1. bio结构体
当内核要传输一组块数据到一个块设备,或者相反,它就得装配一个bio结构来描述这个操作。而后该bio结构被合并到某个块IO请求,或为其创建一个新的请求。bio结构的定义位于
struct bio {
sector_t bi_sector; /* device address,即被传送的第一个(512 字节)扇区索引 */
struct bio *bi_next; /* request queue link,指向下一个bio结构 */
struct block_device *bi_bdev;
unsigned long bi_flags; /* 一组标志,如果是一个写请求,则最低有效位被置位 */
unsigned long bi_rw; /* bottom bits READ/WRITE, top bits priority */
unsigned short bi_vcnt; /* bio_vec结构体数组 包含的元素个数 */
unsigned short bi_idx; /* current index into bvl_vec */
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned short bi_phys_segments; //包含在这个 BIO 中的物理段的数目
/* Number of segments after physical and DMA remapping
* hardware coalescing is performed.
*/
unsigned short bi_hw_segments; //在 DMA 映射完成后被硬件看到的段数目
unsigned int bi_size; /* 被传送的数据大小, 以字节计 */
/*
* To keep track of the max hw size, we account for the
* sizes of the first and last virtually mergeable segments
* in this bio
*/
unsigned int bi_hw_front_size;
unsigned int bi_hw_back_size;
unsigned int bi_max_vecs; /* max bvl_vecs we can hold */
struct bio_vec *bi_io_vec; /* 指向bio_vec数组首元素, 是bio的核心 */
bio_end_io_t *bi_end_io;
atomic_t bi_cnt; /* pin count */
void *bi_private;
bio_destructor_t *bi_destructor; /* destructor */
};
-
一些针对bio的操作函数:
-
bio_sectors(bio):返回bio表示的被传送的总扇区数,与bi_size对应。 -
bio_data_dir(bio):bio的数据传输方向(写还是读?) -
bi_io_vec:它是bio结构的核心,指向一个bio_vec结构体的数组首元素,它的结构体定义如下struct bio_vec { struct page *bv_page; //指向物理页 unsigned int bv_len; //被传输的数据长度 unsigned int bv_offset; //被传输数据在页内的偏移量 }; -
bio结构示意图
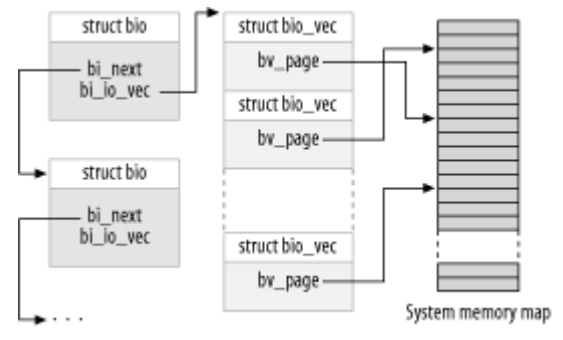
-
循环 bi_io_vec 数组中每个未被处理的项
int segno; //当前的段号 struct bio_vec *bvec; //指向当前的 bio_vec 项 bio_for_each_segment(bvec, bio, segno) { /* Do something with this segment * 这些值可被用来在blk_rq_map_sg中设置 DMA 发送器 */ } -
直接存取页,即直接映射在一个由索引i 所指定的在 bio_vec 中找到的缓冲,当然前提是要确保一个正确的内核虚拟地址存在。
char *__bio_kmap_atomic(struct bio *bio, int i, enum km_type type); void __bio_kunmap_atomic(char *buffer, enum km_type type); -
跟踪请求处理当前状态(还未被传送的第一个缓冲)的一组宏
struct page *bio_page(struct bio *bio); //返回一个指向页的指针, 表示下一个被传送的页. int bio_offset(struct bio *bio); //返回页内的被传送的数据的偏移. int bio_cur_sectors(struct bio *bio); //返回要被传送出当前页的总扇区数. char *bio_data(struct bio *bio); //返回一个内核逻辑地址, 指向被传送的数据.注意这个地址仅当请求的页不在高内存中时可用 char *bio_kmap_irq(struct bio *bio, unsigned long *flags); //给任何缓冲返回一个内核虚拟地址, 不管它是否在高或低内存。它是原子的,不能一次映射多于一个段,且驱动在此映射期间不可睡眠 void bio_kunmap_irq(char *buffer, unsigned long *flags); //去映射缓冲
-
2. 请求结构成员分析
有了 bio 结构如何工作的概念, 我们可以深入 struct request 并且看请求处理如何工作。其结构体的定义如下:
struct request {
struct list_head queuelist; //连接这个请求到请求队列的链表结构,去连接可用blkdev_dequeue_request函数
struct list_head donelist;
request_queue_t *q;
unsigned int cmd_flags;
enum rq_cmd_type_bits cmd_type;
/* Maintain bio traversal state for part by part I/O submission.
* hard_* are block layer internals, no driver should touch them!
*/
sector_t sector; /* next sector to submit */
sector_t hard_sector; /* 第一个尚未被传送的扇区 */
unsigned long nr_sectors; /* no. of sectors left to submit */
unsigned long hard_nr_sectors; /* 在当前bio中已经传送的扇区总数 */
/* no. of sectors left to submit in the current segment */
unsigned int current_nr_sectors;
/* 在当前bio中剩余待传送的扇区数 */
unsigned int hard_cur_sectors;
struct bio *bio; //给这个请求的 bio 结构的链表,不应当直接存取它,而是使用 rq_for_each_bio代替
struct bio *biotail;
struct hlist_node hash; /* merge hash */
/*
* The rb_node is only used inside the io scheduler, requests
* are pruned when moved to the dispatch queue. So let the
* completion_data share space with the rb_node.
*/
union {
struct rb_node rb_node; /* sort/lookup */
void *completion_data;
};
/*
* two pointers are available for the IO schedulers, if they need
* more they have to dynamically allocate it.
*/
void *elevator_private;
void *elevator_private2;
struct gendisk *rq_disk;
unsigned long start_time;
/* Number of scatter-gather DMA addr+len pairs after
* physical address coalescing is performed.
*/
unsigned short nr_phys_segments; //这个请求在物理内存中占用的独特段的数目
/* Number of scatter-gather addr+len pairs after
* physical and DMA remapping hardware coalescing is performed.
* This is the number of scatter-gather entries the driver
* will actually have to deal with after DMA mapping is done.
*/
unsigned short nr_hw_segments;
unsigned short ioprio;
void *special;
char *buffer; //传送的缓冲地址,即在当前bio上调用bio_data 的结果
int tag;
int errors;
int ref_count;
/*
* when request is used as a packet command carrier
*/
unsigned int cmd_len;
unsigned char cmd[BLK_MAX_CDB];
unsigned int data_len;
unsigned int sense_len;
void *data;
void *sense;
unsigned int timeout;
int retries;
/*
* completion callback.
*/
rq_end_io_fn *end_io;
void *end_io_data;
};
- 为了便于大家理解,下面展示一个带有一个部分被处理的请求的请求队列示意图。在图中, cbio 和 buffer
指向尚未传送的第一个 bio 。
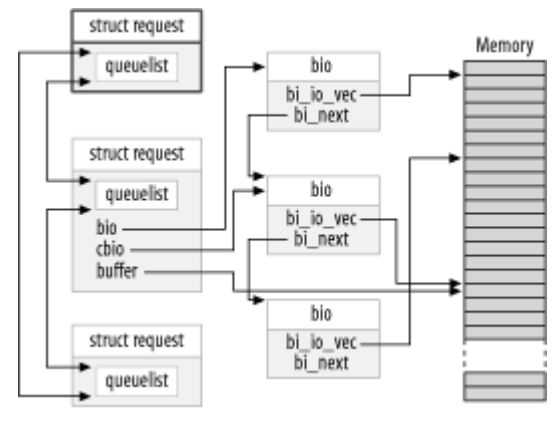
3. 屏障请求的处理
-
由来:当驱动处于某种目的(提高性能、同步要求或日志文件系统的要求等),需要对多个请求进行重新排序时,就需要用到屏障请求。
-
在内核2.6之后提出了屏障请求的概念,即如果一个请求被标记为REQ_HARDBARRER,那么在驱动响应任何后续的请求(初始化)之前,要确保该请求实际被写入驱动器。注意此处是实际写入,而非加入写缓冲!
-
实现:屏障处理是另一个专门的请求队列,它通过下面的接口进行设置
void blk_queue_ordered(request_queue_t *queue, int flag); //为指示你的驱动实现了屏障请求, flag 参数必须设置为一个非零值-
用来判断一个请求是否是屏障请求,可使用如下函数:
int blk_barrier_rq(struct request *req); //返回非零代表是屏障请求 -
当确认了一个屏障请求后,要根据硬件工作原理,停止从队列中继续获取请求,直到该屏障请求完成。
-
4. 不可重入请求
-
由来:块驱动常常试图重试第一次失败的请求. 这个做法可产生一个更加可靠的系统并且帮助来避免数据丢失。
-
但如果某个请求已经明确被标记为不可重入的,此时如果你再试图重试该请求,将会引起错误,所以在考虑重试一个请求前要通过如下函数进行判断:
int blk_noretry_request(struct request *req); -
如果这个宏返回非零值, 你的驱动应当放弃这个请求, 使用一个错误码来代替重试它。
7、请求完成函数
在一个 I/O 请求中,当设备已经完成传送一些或者全部扇区,必须通知块子系统,使用的函数有俩个,且它们都是原子的。
int end_that_request_first(struct request *req, int success, int count);
- 这个函数告知块代码,驱动已经完成 count 个扇区传送, 如果 I/O 是成功的, 传递 success 为 1; 否则传递 0 。函数的返回值指示请求中的所有的扇区是否已经被传送完成(0表示完成)
void end_that_request_last(struct request *req);
-
从队列中解除一个请求,并通知任何在等待这个请求的人,这个请求已经完成并且回收这个请求结构。注意,它必须在持有队列锁时被调用。
在前文4.2节中提到的end_request就是利用上述两个函数定义的
void end_request(struct request *req, int uptodate) { if (!end_that_request_first(req, uptodate, req->hard_cur_sectors)) { add_disk_randomness(req->rq_disk); blkdev_dequeue_request(req); end_that_request_last(req); } }- add_disk_randomness接口使用块 I/O 请求的定时,来贡献熵给系统的随机数池。对于真实的磁盘设备是必须的,但对于本文所说的利用内存虚拟出来的磁盘,调用该函数就没有意义了。
1. 直接使用bio编写请求函数
在学习了以上函数接口后,现在我们来重新编写4.2节所讲的请求函数,先来看代码:
static void sbull_full_request(request_queue_t *q)
{
struct request *req;
int sectors_xferred;
struct sbull_dev *dev = q->queuedata;
while ((req = elv_next_request(q)) != NULL) {
if (!blk_fs_request(req)) {
printk (KERN_NOTICE "Skip non-fs request\n");
end_request(req, 0);
continue;
}
sectors_xferred = sbull_xfer_request(dev, req);
if (! end_that_request_first(req, 1, sectors_xferred))
{
blkdev_dequeue_request(req);
end_that_request_last(req);
}
}
}
-
这个函数简单地获取每个请求,并将其传递到 sbull_xfer_request,接着使用end_that_request_first 和 end_that_request_last (如果需要) 来完成请求任务。所以,真正处理该请求的工作是由sbull_xfer_request完成的,下面先该函数的实现代码:
static int sbull_xfer_request(struct sbull_dev *dev, struct request *req) { struct bio *bio; int nsect = 0; rq_for_each_bio(bio, req) //遍历请求中的每个bio结构 { sbull_xfer_bio(dev, bio); nsect += bio->bi_size/KERNEL_SECTOR_SIZE; } return nsect; } -
该函数简单遍历一个请求中的bio结构,并传递给sbull_xfer_bio处理:
static int sbull_xfer_bio(struct sbull_dev *dev, struct bio *bio) { int i; struct bio_vec *bvec; sector_t sector = bio->bi_sector; //待传输的起始扇区 /* Do each segment independently. */ bio_for_each_segment(bvec, bio, i) { char *buffer = __bio_kmap_atomic(bio, i, KM_USER0); sbull_transfer(dev, sector, bio_cur_sectors(bio), buffer, bio_data_dir(bio) == WRITE); sector += bio_cur_sectors(bio); __bio_kunmap_atomic(bio, KM_USER0); } return 0; /* Always "succeed" */ } //bio_cur_sectors宏,返回要被传送出当前页的总扇区数.- 这个函数简单地遍历每个 bio 结构中的段, 获得一个内核虚拟地址来存取缓冲,接着调用之前4.2节同样的 sbull_transfer 函数来完成拷贝数据。
2. 使用DMA编写块请求
如果你在为一块高性能块设备编写驱动,那不得不考虑使用DMA来进行真正的数据传输。即通过遍历bio结构,为每一个创建一个DMA映射。可以通过发散/汇聚I/O函数完成。
int blk_rq_map_sg(request_queue_t *queue, struct request *req, struct scatterlist *list);
- 该函数使用来自给定请求req的全部段填充给定的列表。内存中邻近的段默认在插入散布表之前被接合(如果不想接合,可调用
clear_bit(QUEUE_FLAG_CLUSTER, &queue->queue_flags);,特别是一些SCSI磁盘不需要结合 ), 因此你不需要自己探测它们。函数返回值是列表中的项数。这个函数还通过它的第 3 个参数list回传一个适合传递给 dma_map_sg 的散布表。 - 你的驱动必须在调用 blk_rq_map_sg 之前给散布表list分配足够的存储,即列表必须至少能够持有这个请求所有的物理段。而struct request 成员
nr_phys_segments持有那个数量(它不能超过由blk_queue_max_phys_segments 指定的物理段的最大数目)。
3. 不用请求队列
前面我们已经讨论了内核在队列中优化请求顺序的工作,包括排列请求、延迟队列来允许一个预期的请求到达等)。这些技术在处理一个真正的旋转的磁盘驱动器时有助于系统的性能,但是, 使用一个虚拟的软件磁盘(例如软件 RAID 阵列或者被逻辑卷管理者创建的虚拟磁盘)的设备它们是完全没必要的。对于这类设备,最好直接从块层接收请求,根本不用使用请求队列。
块层支持"无队列"的操作模式。为了使用这个模式,你的驱动必须提供一个"制作请求"的函数, 而不是一个请求函数。其函数原型如下:
typedef int (make_request_fn) (request_queue_t *q, struct bio *bio);
-
q:注意一个请求队列仍然存在, 即便它从不会真正有任何请求
-
bio :该结构表示一个或多个要传送的缓冲
-
该函数做 2 个事情之一,要么直接进行传输,要么重定向这个请求到另一个设备。如果是直接传输,则使用我们之前讲的存取方法完成这个bio,并负责通过bio_endio函数,通知bio的创建者完成情况:
void bio_endio(struct bio *bio, unsigned int bytes, int error);-
bytes :是至今已经传送的字节数,可小于bio所需求传送字节数。
-
在这个方式中, 你可指示部分完成, 并且更新在 bio 中的内部的"当前缓冲"指针。在你的设备进行进一步处理时,你应当再次调用 bio_endio。
-
当你不能完成这个请求时,应该通过error参数指示一个错误(类似-EIO的负值错误码)
-
不管这个 I/O 是否成功,函数应当返回 0。
-
注意:在通常的请求函数中,应避免使用该函数,而是使用end_that_request_first 代替。
-
一个不用请求队列的请求函数的例子如下:
static int sbull_make_request(request_queue_t *q, struct bio *bio) { struct sbull_dev *dev = q->queuedata; int status; status = sbull_xfer_bio(dev, bio); bio_endio(bio, bio->bi_size, status); return 0; }
-
-
一些实现卷管理者和软件 RAID 阵列的,一般真正需要重定向请求到另一个设备来处理真正的 I/O。本文不准备讲关于这方面的内容,但基本思路是:
- 如果 make_request 函数返回一个非零值,则 bio 被再次提交,进而引发一个堆叠
- 因此,一个"堆叠"驱动修改 bi_bdev 成员来指向一个不同的设备、改变起始扇区值后返回。
- 块系统接着传递 bio 到新设备。如果需要的话,还有一个 bio_split调用,可用来划分一个 bio 到多个块,以提交给多个设备。
-
不管是任何一个方式,你都必须告知块子系统,你的驱动在使用一个自定义的make_request 函数。为此必须分配一个请求队列:
request_queue_t *blk_alloc_queue(int flags);- 这个函数不同于 blk_init_queue, 它不真正建立队列并持有某个请求。
- flags 参数是一组分配标志被用来为队列分配内存,常常取 GFP_KERNEL
-
一旦分配好了请求队列和定义好了请求函数后,就需要讲它们作为参数来调用以下函数:
void blk_queue_make_request(request_queue_t *queue, make_request_fn *func); -
所以,本文代码最后可实现为:
dev->queue = blk_alloc_queue(GFP_KERNEL); if (dev->queue == NULL) goto out_vfree; blk_queue_make_request(dev->queue, sbull_make_request);
8、完整的驱动代码
-
sbull.c
/* * Sample disk driver, from the beginning. */ #include#include #include #include #include #include /* printk() */ #include /* kmalloc() */ #include /* everything... */ #include /* error codes */ #include #include /* size_t */ #include /* O_ACCMODE */ #include /* HDIO_GETGEO */ #include #include #include #include #include /* invalidate_bdev */ #include MODULE_LICENSE("Dual BSD/GPL"); static int sbull_major = 0; module_param(sbull_major, int, 0); static int hardsect_size = 512; module_param(hardsect_size, int, 0); static int nsectors = 1024; /* How big the drive is */ module_param(nsectors, int, 0); static int ndevices = 4; module_param(ndevices, int, 0); /* * The different "request modes" we can use. */ enum { RM_SIMPLE = 0, /* The extra-simple request function */ RM_FULL = 1, /* The full-blown version */ RM_NOQUEUE = 2, /* Use make_request */ }; static int request_mode = RM_SIMPLE; module_param(request_mode, int, 0); /* * Minor number and partition management. */ #define SBULL_MINORS 16 #define MINOR_SHIFT 4 #define DEVNUM(kdevnum) (MINOR(kdev_t_to_nr(kdevnum)) >> MINOR_SHIFT /* * We can tweak our hardware sector size, but the kernel talks to us * in terms of small sectors, always. */ #define KERNEL_SECTOR_SIZE 512 /* * After this much idle time, the driver will simulate a media change. */ #define INVALIDATE_DELAY 30*HZ /* * The internal representation of our device. */ struct sbull_dev { int size; /* Device size in sectors */ u8 *data; /* The data array */ short users; /* How many users */ short media_change; /* Flag a media change? */ spinlock_t lock; /* For mutual exclusion */ struct request_queue *queue; /* The device request queue */ struct gendisk *gd; /* The gendisk structure */ struct timer_list timer; /* For simulated media changes */ }; static struct sbull_dev *Devices = NULL; /* * Handle an I/O request. */ static void sbull_transfer(struct sbull_dev *dev, unsigned long sector, unsigned long nsect, char *buffer, int write) { unsigned long offset = sector*KERNEL_SECTOR_SIZE; unsigned long nbytes = nsect*KERNEL_SECTOR_SIZE; if ((offset + nbytes) > dev->size) { printk (KERN_NOTICE "Beyond-end write (%ld %ld)\n", offset, nbytes); return; } if (write) memcpy(dev->data + offset, buffer, nbytes); else memcpy(buffer, dev->data + offset, nbytes); } /* * The simple form of the request function. */ static void sbull_request(request_queue_t *q) { struct request *req; while ((req = elv_next_request(q)) != NULL) { struct sbull_dev *dev = req->rq_disk->private_data; if (! blk_fs_request(req)) { printk (KERN_NOTICE "Skip non-fs request\n"); end_request(req, 0); continue; } // printk (KERN_NOTICE "Req dev %d dir %ld sec %ld, nr %d f %lx\n", // dev - Devices, rq_data_dir(req), // req->sector, req->current_nr_sectors, // req->flags); sbull_transfer(dev, req->sector, req->current_nr_sectors, req->buffer, rq_data_dir(req)); end_request(req, 1); } } /* * Transfer a single BIO. */ static int sbull_xfer_bio(struct sbull_dev *dev, struct bio *bio) { int i; struct bio_vec *bvec; sector_t sector = bio->bi_sector; /* Do each segment independently. */ bio_for_each_segment(bvec, bio, i) { char *buffer = __bio_kmap_atomic(bio, i, KM_USER0); sbull_transfer(dev, sector, bio_cur_sectors(bio), buffer, bio_data_dir(bio) == WRITE); sector += bio_cur_sectors(bio); __bio_kunmap_atomic(bio, KM_USER0); } return 0; /* Always "succeed" */ } /* * Transfer a full request. */ static int sbull_xfer_request(struct sbull_dev *dev, struct request *req) { struct bio *bio; int nsect = 0; rq_for_each_bio(bio, req) { sbull_xfer_bio(dev, bio); nsect += bio->bi_size/KERNEL_SECTOR_SIZE; } return nsect; } /* * Smarter request function that "handles clustering". */ static void sbull_full_request(request_queue_t *q) { struct request *req; int sectors_xferred; struct sbull_dev *dev = q->queuedata; while ((req = elv_next_request(q)) != NULL) { if (! blk_fs_request(req)) { printk (KERN_NOTICE "Skip non-fs request\n"); end_request(req, 0); continue; } sectors_xferred = sbull_xfer_request(dev, req); if (! end_that_request_first(req, 1, sectors_xferred)) { blkdev_dequeue_request(req); end_that_request_last(req); } } } /* * The direct make request version. */ static int sbull_make_request(request_queue_t *q, struct bio *bio) { struct sbull_dev *dev = q->queuedata; int status; status = sbull_xfer_bio(dev, bio); bio_endio(bio, bio->bi_size, status); return 0; } /* * Open and close. */ static int sbull_open(struct inode *inode, struct file *filp) { struct sbull_dev *dev = inode->i_bdev->bd_disk->private_data; del_timer_sync(&dev->timer); filp->private_data = dev; spin_lock(&dev->lock); if (! dev->users) check_disk_change(inode->i_bdev); dev->users++; spin_unlock(&dev->lock); return 0; } static int sbull_release(struct inode *inode, struct file *filp) { struct sbull_dev *dev = inode->i_bdev->bd_disk->private_data; spin_lock(&dev->lock); dev->users--; if (!dev->users) { dev->timer.expires = jiffies + INVALIDATE_DELAY; add_timer(&dev->timer); } spin_unlock(&dev->lock); return 0; } /* * Look for a (simulated) media change. */ int sbull_media_changed(struct gendisk *gd) { struct sbull_dev *dev = gd->private_data; return dev->media_change; } /* * Revalidate. WE DO NOT TAKE THE LOCK HERE, for fear of deadlocking * with open. That needs to be reevaluated. */ int sbull_revalidate(struct gendisk *gd) { struct sbull_dev *dev = gd->private_data; if (dev->media_change) { dev->media_change = 0; memset (dev->data, 0, dev->size); } return 0; } /* * The "invalidate" function runs out of the device timer; it sets * a flag to simulate the removal of the media. */ void sbull_invalidate(unsigned long ldev) { struct sbull_dev *dev = (struct sbull_dev *) ldev; spin_lock(&dev->lock); if (dev->users || !dev->data) printk (KERN_WARNING "sbull: timer sanity check failed\n"); else dev->media_change = 1; spin_unlock(&dev->lock); } /* * The ioctl() implementation */ int sbull_ioctl (struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg) { long size; struct hd_geometry geo; struct sbull_dev *dev = filp->private_data; switch(cmd) { case HDIO_GETGEO: /* * Get geometry: since we are a virtual device, we have to make * up something plausible. So we claim 16 sectors, four heads, * and calculate the corresponding number of cylinders. We set the * start of data at sector four. */ size = dev->size*(hardsect_size/KERNEL_SECTOR_SIZE); geo.cylinders = (size & ~0x3f) >> 6; geo.heads = 4; geo.sectors = 16; geo.start = 4; if (copy_to_user((void __user *) arg, &geo, sizeof(geo))) return -EFAULT; return 0; } return -ENOTTY; /* unknown command */ } /* * The device operations structure. */ static struct block_device_operations sbull_ops = { .owner = THIS_MODULE, .open = sbull_open, .release = sbull_release, .media_changed = sbull_media_changed, .revalidate_disk = sbull_revalidate, .ioctl = sbull_ioctl }; /* * Set up our internal device. */ static void setup_device(struct sbull_dev *dev, int which) { /* * Get some memory. */ memset (dev, 0, sizeof (struct sbull_dev)); dev->size = nsectors*hardsect_size; dev->data = vmalloc(dev->size); if (dev->data == NULL) { printk (KERN_NOTICE "vmalloc failure.\n"); return; } spin_lock_init(&dev->lock); /* * The timer which "invalidates" the device. */ init_timer(&dev->timer); dev->timer.data = (unsigned long) dev; dev->timer.function = sbull_invalidate; /* * The I/O queue, depending on whether we are using our own * make_request function or not. */ switch (request_mode) { case RM_NOQUEUE: dev->queue = blk_alloc_queue(GFP_KERNEL); if (dev->queue == NULL) goto out_vfree; blk_queue_make_request(dev->queue, sbull_make_request); break; case RM_FULL: dev->queue = blk_init_queue(sbull_full_request, &dev->lock); if (dev->queue == NULL) goto out_vfree; break; default: printk(KERN_NOTICE "Bad request mode %d, using simple\n", request_mode); /* fall into.. */ case RM_SIMPLE: dev->queue = blk_init_queue(sbull_request, &dev->lock); if (dev->queue == NULL) goto out_vfree; break; } blk_queue_hardsect_size(dev->queue, hardsect_size); dev->queue->queuedata = dev; /* * And the gendisk structure. */ dev->gd = alloc_disk(SBULL_MINORS); if (! dev->gd) { printk (KERN_NOTICE "alloc_disk failure\n"); goto out_vfree; } dev->gd->major = sbull_major; dev->gd->first_minor = which*SBULL_MINORS; dev->gd->fops = &sbull_ops; dev->gd->queue = dev->queue; dev->gd->private_data = dev; snprintf (dev->gd->disk_name, 32, "sbull%c", which + 'a'); set_capacity(dev->gd, nsectors*(hardsect_size/KERNEL_SECTOR_SIZE)); add_disk(dev->gd); return; out_vfree: if (dev->data) vfree(dev->data); } static int __init sbull_init(void) { int i; /* * Get registered. */ sbull_major = register_blkdev(sbull_major, "sbull"); if (sbull_major <= 0) { printk(KERN_WARNING "sbull: unable to get major number\n"); return -EBUSY; } /* * Allocate the device array, and initialize each one. */ Devices = kmalloc(ndevices*sizeof (struct sbull_dev), GFP_KERNEL); if (Devices == NULL) goto out_unregister; for (i = 0; i < ndevices; i++) setup_device(Devices + i, i); return 0; out_unregister: unregister_blkdev(sbull_major, "sbd"); return -ENOMEM; } static void sbull_exit(void) { int i; for (i = 0; i < ndevices; i++) { struct sbull_dev *dev = Devices + i; del_timer_sync(&dev->timer); if (dev->gd) { del_gendisk(dev->gd); put_disk(dev->gd); } if (dev->queue) { if (request_mode == RM_NOQUEUE) blk_put_queue(dev->queue); else blk_cleanup_queue(dev->queue); } if (dev->data) vfree(dev->data); } unregister_blkdev(sbull_major, "sbull"); kfree(Devices); } module_init(sbull_init); module_exit(sbull_exit); -
sbull.h
/* * sbull.h -- definitions for the char module * * Copyright (C) 2001 Alessandro Rubini and Jonathan Corbet * Copyright (C) 2001 O'Reilly & Associates * * The source code in this file can be freely used, adapted, * and redistributed in source or binary form, so long as an * acknowledgment appears in derived source files. The citation * should list that the code comes from the book "Linux Device * Drivers" by Alessandro Rubini and Jonathan Corbet, published * by O'Reilly & Associates. No warranty is attached; * we cannot take responsibility for errors or fitness for use. * */ #include/* Multiqueue only works on 2.4 */ #ifdef SBULL_MULTIQUEUE # warning "Multiqueue only works on 2.4 kernels" #endif /* * Macros to help debugging */ #undef PDEBUG /* undef it, just in case */ #ifdef SBULL_DEBUG # ifdef __KERNEL__ /* This one if debugging is on, and kernel space */ # define PDEBUG(fmt, args...) printk( KERN_DEBUG "sbull: " fmt, ## args) # else /* This one for user space */ # define PDEBUG(fmt, args...) fprintf(stderr, fmt, ## args) # endif #else # define PDEBUG(fmt, args...) /* not debugging: nothing */ #endif #undef PDEBUGG #define PDEBUGG(fmt, args...) /* nothing: it's a placeholder */ #define SBULL_MAJOR 0 /* dynamic major by default */ #define SBULL_DEVS 2 /* two disks */ #define SBULL_RAHEAD 2 /* two sectors */ #define SBULL_SIZE 2048 /* two megs each */ #define SBULL_BLKSIZE 1024 /* 1k blocks */ #define SBULL_HARDSECT 512 /* 2.2 and 2.4 can used different values */ #define SBULLR_MAJOR 0 /* Dynamic major for raw device */ /* * The sbull device is removable: if it is left closed for more than * half a minute, it is removed. Thus use a usage count and a * kernel timer */ typedef struct Sbull_Dev { int size; int usage; struct timer_list timer; spinlock_t lock; u8 *data; #ifdef SBULL_MULTIQUEUE request_queue_t *queue; int busy; #endif }Sbull_Dev; -
Makefile
# Comment/uncomment the following line to disable/enable debugging #DEBUG = y # Add your debugging flag (or not) to CFLAGS ifeq ($(DEBUG),y) DEBFLAGS = -O -g -DSBULL_DEBUG # "-O" is needed to expand inlines else DEBFLAGS = -O2 endif CFLAGS += $(DEBFLAGS) CFLAGS += -I.. ifneq ($(KERNELRELEASE),) # call from kernel build system obj-m := sbull.o else KERNELDIR ?= /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) default: $(MAKE) -C $(KERNELDIR) M=$(PWD) modules endif clean: rm -rf *.o *~ core .depend .*.cmd *.ko *.mod.c .tmp_versions depend .depend dep: $(CC) $(CFLAGS) -M *.c > .depend ifeq (.depend,$(wildcard .depend)) include .depend endif
【参考资料】LDD3