机器视觉自动数据标注方法
目录
一、背景阅读
个人总结:
(半)自动数据标注的方法基本都是采用类似的思路,即通过少量标注数据进行训练后得到一个预训练模型,然后再次基础上对该网络的输出结果进行人工核验,并进一步地进行训练得到第二轮优化模型,往复循环,增加更多数据提高模型精度。
(强化)主动学习的加入是将人工核验的过程的工作量再进一步地降低,使网络具有一定的自主决策能力,即网络具有理解自己在数据预测上偏差的能力,可为用户提供标注需求进一步改善网络的输出分布。
全自动的数据标注方法目前仍未实现,标注过程均需要人工核验,对数据进行修正、反馈给网络和loss。
二、自动标注方法介绍
2.1 PaddleSeg 团队开源的交互式分割工具——EISeg
2.2 Anno-Mage半自动标注工具
2.3 AI开发平台ModelArts-智能标注
2.4 基于labelImg与YOLOv5算法的半自动标注工具
2.5 实操链接基于yolov5的自动标注
一、背景阅读
机器视觉和人类一样,它需要学习,学习则需要教材,教材的好坏决定了学习效果,算法模型决定了学习效率。人类制造教材,是通过经验总结,再逻辑化编写。而机器的教材初期也只能靠人类编写,具体就是机器视觉里最基础的任务:目标检测——人在图像上一个一个打上标记,把需要识别的物体框起来,并标识其有哪些属性。
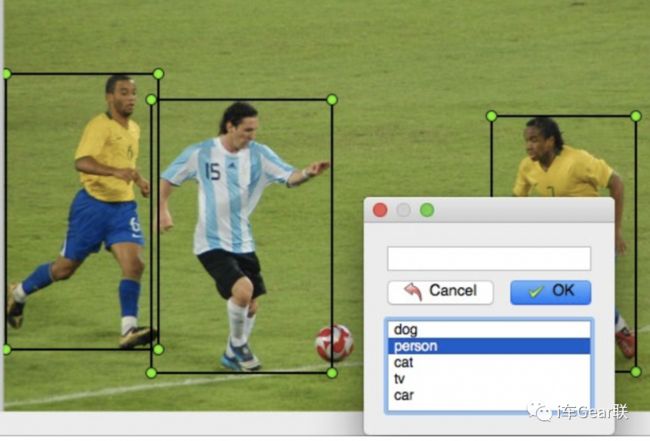 使用LabelImg标识一张图片里的球员
使用LabelImg标识一张图片里的球员
机器算法模型当前还不具备人类的高级认知和抽象能力,要求人类制作的数据教材全面且量大。一般来说机器要学出好的效果,需要数万张图片来进行训练。这只是一个特定类别的识别功能,而在一个大的场景里,如自动驾驶里的视觉感知,要实现多类物体的识别,其中每一类又有细分,所以需要制作的数据教材的量非常惊人。自然地,聪明的人类想出来用机器来生成这些数据教材(数据集)。不过,聪明如你,会发现这其实是先有鸡还是先有蛋的问题:如果机器已经能生成合乎要求的教材,那它不需要训练,直接就能使用,这只鸡可以下锅炖了吃了。所以我们从科学角度,是尽可能加速鸡生蛋,蛋变鸡的过程。再次一个自然的想法,机器是否能代替一部分甚至大部分人类标识数据的工作,人只要挑出认为质量不达标的结果进行修正,再给机器训练,就能减少很大部分标注工作量,同时不断提高机器模型质量。
在机器学习数据标注行业,会有一个重要的功能:(半)自动化标注。而由于多种场合的需要,这个(半)自动化标注会被反复提及并强调,俨然成了水平高低的龙门指标。但奇怪的是,近年来权威学术论文里居然没找到提及标注自动化率的量化指标和炫技展示,一般都是宣称自己在某个领域达到的识别效果:准确度、检测速度、训练速度等。按理说,国外人力资源昂贵,更应该着力提升机器自动化标注的效率,反而是国内一些商业公司一边雇佣大量劳动力来标注,一边宣称自己可以达到超过90%的自动化标注率。
常见过程中自动标注分两种情况:
- 目前开发者已经具有一个完备训练的相似场景模型,用户希望对实际应用场景进行进一步的细化与强化开发,并挖掘长尾部分的准确性。
- 目前开发者不具备良好训练的相似场景模型,整个模型开发从零开始迭代开发。
用于训练和预打标的数据集也分两种情况:
- 数据的是由若干相似场景的连续视频切分而来的(例如:对自动驾驶采集到的视频数据 进行秒频率的切分那么这些数据就是符合这样场景的)这样的数据噪声和训练的目标分布都是相似的。
- 数据是从不同场景,甚至是不同的设备,不同的感受野进行采集的。(例如:电商场景下的亿级图像关联出相似图像),这样的数据哪怕是预测同一个物体但是由于背景和噪声的不同。要找出这样的数据是需要一个额外的任务。
针对上述的两类情况,我们发现是两个维度构成了四象限,每个象限分别为:
A. 预标注模型不完备 + 数据场景不相似
B. 预标注模型完备 + 数据场景不相似
C. 预标注模型不完备 + 数据场景相似
D. 预标注模型完备 + 数据场景相似

【D】:预标注模型完备 + 数据场景相似
这类是看似最好解决的任务,一个训练良好的模型可以快速地进行模型预打标任务。如某自驾研发团队已经采集了100小时上海->北京的高速行使数据,该团队想要快速的训练出针对上海城市快速路适用的视觉感知模型。便可以通过已有的视觉感知模型(通过100小时训练所得)对上海快速路任务进行预打标并进行训练。不仅如此,在我们对公开数据集测试时发现一个良好的通过bdd/kitti训练的车道线模型在百度的自动驾驶数据集上的表现也较为良好。
但上述任务也是有一定局限的,例如对具有城市差异化的视觉感知场景(交通灯,路牌等)通过既有模型的预打标就有一定的局限性。因为国内很多省市的红绿灯/道路障碍物是不完全统一的,这一定程度上造成了通过模型预打标造成的数据集劣化。所以在感知场景(汽车和道路标线等)统一程度较高的各个城市,已有模型打标效果会更好。
 中国不同城市红绿灯对比(上海,南京)
中国不同城市红绿灯对比(上海,南京)
【A】:预标注模型不完备 + 数据场景不相似
这类数据往往出现在电商场景或是地图相似景观等,该类模型是非常难进行直接监督学习+迭代打标的闭环形式的。因为模型可能认不出不同角度的同一物体或者不同环境下的同一物体。所以在2019-20年,Google/阿里/华为等公司都举办了稀疏图像匹配的数据集/比赛。Google landmarks dataset 这 个数据集就是旨在建立这样的一个相似图片检索+召回的非监督学习体系。而不是通过监督学习对图像进行分类和目标检测然后落盘后通过标签的形式进行检索+召回。
 Google landmarks dataset 部分图片
Google landmarks dataset 部分图片
【C】: 预标注模型不完备 + 数据场景相似
具有代表性的是智能制造领域里的机器视觉质检,我们可以获取到与真实使用时相似的数据场景,但因为这些制造零件都是个性化甚至保密的,公开的预训练模型无法提供较好的预标注机制。此外,这类任务可能处理的是较为单一的某工业场景任务,算法开发人员往往没有该方面的算法经验以及模型沉淀,整个开发体系需要从零开始。
这样的任务其实更贴近于我们后面要详细展开说的主动学习节约打标的模式,由于我们不知道到底需要多少打标数据量才能满足模型训练要求。一开始一味的对数据进行大规模的打标是一种较大的浪费行为,这时候就可以用主动学习的方式,哪怕什么模型都没有,且只有很少的标注预算,也可以通过主动学习+auto-ML去实现低代码+低数据量的模型训练,在尽可能减少标注成本的同时提高模型最终效果。这其实类似于百度EasyDL的平台所提供的一些功能。
 法某工业零部件的质量检测
法某工业零部件的质量检测
好了,分析完会遭遇到的4种情况,我们发现D已经成熟,不用在数据准备和算法训练层面继续花大力气,应该转而到工程化、场景化去落地。而自动化标注算法最应该发力的是C——这类即没有成熟算法模型,但场景数据近似的情况。所以下面我们介绍一下我们在这个象限里的工作进展。
C象限里的大部分工作在学术界早有定义:主动学习(Active Learning)。主动学习指的是一种学习方法:大多数情况下,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵(如找医生来标注CT肺结核,找零部件质检工程师来标注缺陷等),这时候,学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给人类专家进行标注。这个筛选过程也就是主动学习主要研究的地方了。
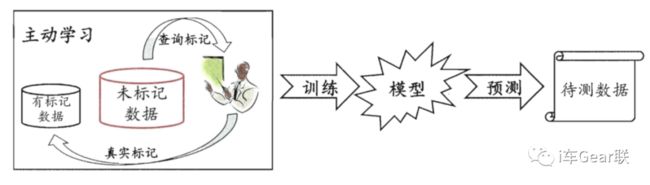 主动学习示意图
主动学习示意图
归纳一下我们的目标:
-
在优先的标注下提高训练精度
-
减少整体标注成本(费用与时间)
-
加快模型开发效率
具体路径

由此,我们发展出基于强化主动学习的自动标注服务:

简单地说,我们引入了一个『强化主动学习Agent』,用它先来判断是否需要人工标注专家来介入,同时它也同步接收人工标注专家的行为反馈,不断提高自己的判断准确性,从而实现在C象限场景下,不断提高模型精准度和减少数据人工标注比例的效果。也就是说,经过一定的标注训练爬坡,C象限可以转为D象限,达到模型成熟落地条件。

几点总结:
1.机器视觉AI训练依赖于大量的数据,数据可由现有模型进行标注,也需要人工参与。
2.制作训练数据集的过程可被一定程度自动化,但不同场景下自动化水平不适合相互比较。
3.通过强化主动学习,可以在场景数据类似的情况下,可以加速将模型由几乎零基础状态爬坡至成熟
====
个人总结:
-
(半)自动数据标注的方法基本都是采用类似的思路,即通过少量标注数据进行训练后得到一个预训练模型,然后再次基础上对该网络的输出结果进行人工核验,并进一步地进行训练得到第二轮优化模型,往复循环,增加更多数据提高模型精度。
-
(强化)主动学习的加入是将人工核验的过程的工作量再进一步地降低,使网络具有一定的自主决策能力,即网络具有理解自己在数据预测上偏差的能力,可为用户提供标注需求进一步改善网络的输出分布。
-
全自动的数据标注方法目前仍未实现,标注过程均需要人工核验,对数据进行修正、反馈给网络和loss。
参考链接:
1. 机器视觉AI模型的数据标注自动化
二、自动标注方法介绍
2.1 PaddleSeg 团队开源的交互式分割工具——EISeg
业界首个高性能的交互式分割工具——EISeg。那什么是交互式分割呢?它其实就是先用预训练模型对图像进行预标注,对于标注不精准、有误差的地方,再通过一系列绿色点(正点)和红色点(负点)对目标对象边缘进行精准的调整,从而实现精细化标注,高效而实用。


如果你需要特定领域的自动标注算法,还可以对 EISeg 的预训练模型进行精调,比如 EISeg 的开发团队就基于人像数据集对模型进行 Finetune(精调)得到预测速度快、精度高、交互点少的人像交互式分割模型。你还可以自己训练出像建筑物分割、飞机分割等等你需要的算法,提升相关任务的标注效率。
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.2/contrib/EISeg
EISeg 提供了超多人性化设计的快捷键:

传统方法使用的标注时间是1分07秒,EISeg 使用的只有 9 秒。使用的时间是传统方式的 1/7 还不到! EISeg 的交互式分割模型的标注效率是远远超过传统标注的!
支持多种图像及标注格式,满足多种视觉任务
EISeg 不仅仅支持输出 mask 掩膜输出,还支持多边形等多种标注生成。同时支持伪彩色图、灰度图,以及 json、coco 等数据格式,用户还可对角点进行增删和局部修正。这样标注出来的数据,不仅仅可以做语义分割,还可以用做实例分割任务,一举两得!!!


丰富的标注模型,适合多种场景
EISeg 开放了在 COCO+LVIS 和大规模人像数据上训练的四个标注模型,满足通用场景和人像场景的标注需求。其中模型结构对应 EISeg 交互工具中的网络选择模块,用户需要根据自己的场景需求选择不同的网络结构和加载参数。

另外,为了更好的满足用户分割场景的多样性,PaddleSeg 团队还在持续建设其他垂类领域的交互式模型,例如医疗和遥感图像标注。期待有相关需求的开发者们一起参与开源共建中来!

参考链接:
1. AI界的革命!终于可以自动标注了!
2. 这款图像自动标注软件,终于开源了 - 腾讯云开发者社区-腾讯云
2.2 Anno-Mage半自动标注工具
Anno-Mage是一个半自动标注工具,以RetinaNet作为建议算法,使用预训练的RetinaNet模型从MS COCO数据集建议80个类对象。 通过一个通用模型对数据集进行检测。但这个工具能标注的物品类型有限,也没有模型迭代逐步求精的过程,可以自行对其源码进行修改优化。
github代码地址: GitHub - virajmavani/semi-auto-image-annotation-tool: Anno-Mage: A Semi Automatic Image Annotation Tool which helps you in annotating images by suggesting you annotations for 80 object classes using a pre-trained model
参考链接:
1. 图像半自动标注「建议收藏」 - 腾讯云开发者社区-腾讯云
2. 深度学习图像数据自动标注
2.3 AI开发平台ModelArts-智能标注
智能标注_AI开发平台ModelArts_AI工程师用户指南_数据管理(旧版即将下线)_华为云
除了人工标注外,ModelArts还提供了智能标注功能,快速完成数据标注,为您节省70%以上的标注时间。智能标注是指基于当前标注阶段的标签及图片学习训练,选中系统中已有的模型进行智能标注,快速完成剩余图片的标注操作。
背景信息
- 目前只有“图像分类”和“物体检测”类型的数据集支持智能标注功能。
- 启动智能标注时,需数据集存在至少2种标签,且每种标签已标注的图片不少于5张。
- 启动智能标注时,必须存在未标注图片。
- 启动智能标注前,保证当前系统中不存在正在进行中的智能标注任务。
- 检查用于标注的图片数据,确保您的图片数据中,不存在RGBA四通道图片。如果存在四通道图片,智能标注任务将运行失败,因此,请从数据集中删除四通道图片后,再启动智能标注。
智能标注
- 登录ModelArts管理控制台,在左侧菜单栏中选择“数据管理 > 数据集”,进入“数据集”管理页面。
- 在数据集列表中,选择“物体检测”或“图像分类”类型的数据集,单击操作列的“智能标注”启动智能标注作业。
- 在弹出的“启动智能标注”对话框中,选择智能标注类型,可选“主动学习”或者“预标注”,详见表1和表2。
表1 主动学习 参数
说明
智能标注类型
“主动学习”。“主动学习”表示系统将自动使用半监督学习、难例筛选等多种手段进行智能标注,降低人工标注量,帮助用户找到难例。
算法类型
针对“图像分类”类型的数据集,您需要选择以下参数。
“快速型”:仅使用已标注的样本进行训练。
“精准型”:会额外使用未标注的样本做半监督训练,使得模型精度更高。
表2 预标注 参数
说明
智能标注类型
“预标注”。“预标注”表示选择用户AI应用管理里面的AI应用,选择模型时需要注意模型类型和数据集的标注类型相匹配。预标注结束后,如果标注结果符合平台定义的标准标注格式,系统将进行难例筛选,该步骤不影响预标注结果。
选择模型及版本
- “我的AI应用”。您可以根据实际需求选择您的AI应用。您需要在目标AI应用的左侧单击下拉三角标,选择合适的版本。您的AI应用导入参见创建AI应用。
- “我的订阅”。您可以根据实际需求选择AI Gallery中已订阅的AI应用。您需要在目标AI应用的左侧单击下拉三角标,选择合适的版本。查找AI应用参见我的订阅模型。
计算节点规格
在下拉框中,您可以选择目前ModelArts支持的节点规格选项。
计算节点个数
默认为1。您可以根据您的实际情况选择,最大为5。
2.4 基于labelImg与YOLOv5算法的半自动标注工具
labelGo
github: GitHub - cnyvfang/labelGo-Yolov5AutoLabelImg: YOLOV5 semi-automatic annotation tool (Based on labelImg)基于labelImg及YOLOV5的图形化半自动标注工具
一个基于labelImg与YOLOv5算法的半自动标注工具
通过现有的YOLOv5 Pytorch模型对数据集进行半自动标注
News
现已支持最新版本YOLOv5以及classes.txt的自动生成
YOLOv5半自动标注功能演示
一键将YOLO格式标签转换为VOC格式标签功能演示
2.5 实操链接基于yolov5的自动标注
基于yolov5的自动标注_Wyd_(ง •̀_•́)ง的博客-CSDN博客_yolov5自动标注