深度学习实战 2 YOLOv5 添加CBAM、CA注意力机制
YOLOv5结合注意力机制有两种策略:
- 注意力机制结合Bottleneck,替换backbone中的所有C3模块
- 在backbone单独加入注意力模块
1. CBAM
论文《CBAM: Convolutional Block Attention Module》:https://arxiv.org/pdf/1807.06521.pdf
核心算法是:通道注意力模块(Channel Attention Module,CAM) +空间注意力模块(Spartial Attention Module,SAM) ,分别进行通道与空间上的 Attention。

1.1 替换C3,C3CBAM
1.1.1在Common.py中添加定义模块
# ---------------------------- CBAM start ---------------------------------
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 全局平均池化—>MLP两层卷积
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
# 全局最大池化—>MLP两层卷积
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 基于channel的全局平均池化(channel=1)
avg_out = torch.mean(x, dim=1, keepdim=True)
# 基于channel的全局最大池化(channel=1)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# channel拼接(channel=2)
x = torch.cat([avg_out, max_out], dim=1)
# channel=1
x = self.conv(x)
return self.sigmoid(x)
class CBAMBottleneck(nn.Module):
# ch_in, ch_out, shortcut, groups, expansion, ratio, kernel_size
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, kernel_size=7):
super(CBAMBottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
# 加入CBAM模块
self.channel_attention = ChannelAttention(c2, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 考虑加入CBAM模块的位置:bottleneck模块刚开始时、bottleneck模块中shortcut之前,这里选择在shortcut之前
x2 = self.cv2(self.cv1(x)) # x和x2的channel数相同
# 在bottleneck模块中shortcut之前加入CBAM模块
out = self.channel_attention(x2) * x2
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return x + out if self.add else out
class C3CBAM(C3):
# C3 module with CBAMBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e) # 引入C3(父类)的属性
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(CBAMBottleneck(c_, c_, shortcut) for _ in range(n)))
# ----------------------------- CBAM end ----------------------------------
1.1.2 修改yolo.py
在yolo.py的parse_model函数中加入CBAMBottleneck, C3CBAM两个模块 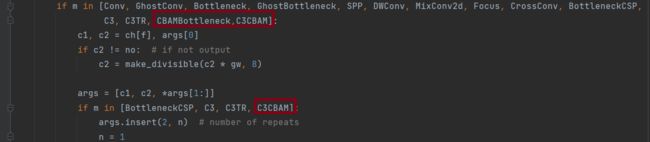
1.1.3 修改配置文件,yolov5s.yaml
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3CBAM, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3CBAM, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3CBAM, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3CBAM, [1024, False]], # 9
]1.2 在backbone最后单独加入CBAM
1.2.1 在Common.py中添加定义模块
# ---------------------------- CBAM start ---------------------------------
class ChannelAttentionModule(nn.Module):
def __init__(self, c1, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = c1 // reduction
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=c1, out_features=mid_channel),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(in_features=mid_channel, out_features=c1)
)
self.act = nn.Sigmoid()
#self.act=nn.SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
return self.act(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.act = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.act(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, c1,c2):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(c1)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
# ---------------------------- CBAM end ---------------------------------1.2.2 修改yolo.py
在models/yolo.py中的parse_model函数中添加CBAM模块
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']),对应位置 下方只需要新增以下代码
elif m is CBAM:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2]
1.2.3 修改配置文件,yolov5s.yaml
注意head层数的变化
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CBAM, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2. Coordinate Attention(CA)注意力机制
论文《Coordinate Attention for Efficient Mobile Network Design》地址:https://arxiv.org/abs/2103.02907
核心算法:将通道注意力分解为两个并行(x和y方向)的1D特征编码过程,这两个嵌入特定方向信息的特征图分别被编码为两个注意力图,每个注意力图都捕获了输入特征图沿着一个空间方向的长程依赖。
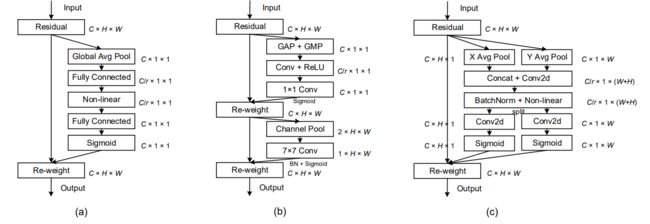
2.1 在Common.py中添加定义模块
# ----------------------------- CABlock start ----------------------------------
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
# height方向上的均值池化
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
# width方向上的均值池化
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
# ----------------------------- CoordAtt end ----------------------------------2.2 修改yolo.py
在models/yolo.py中的parse_model函数中添加CA模块,并新增以下代码 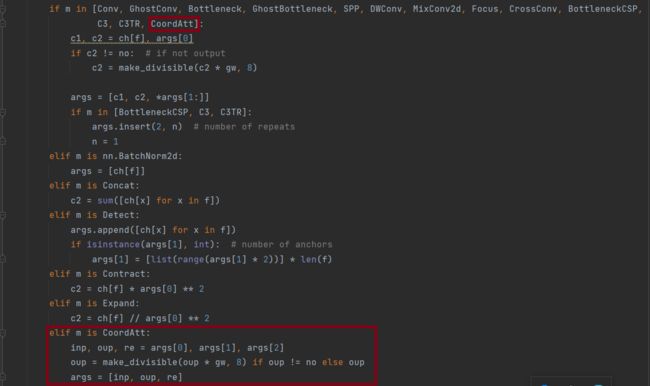
elif m is CoordAtt:
inp, oup, re = args[0], args[1], args[2]
oup = make_divisible(oup * gw, 8) if oup != no else oup
args = [inp, oup, re]2.3 修改配置文件,yolov5s.yaml
注意backbone层数的变化
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, CoordAtt, [512]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]