MySQL/Oracle字符串分割
字符串分割
在工程开发中,根据特定分割符进行字符串分割是常用的操作,本文将对MySQL及ORACLE中的字符串分割方法进行介绍。
一、MySQL
注意:本文的SQL 在 MySQL 8.0版本中测试通过
创建如下测试数据:

1、使用递归子查询
通过递归先计算出分隔符位置,再通过SUBSTRING函数将字符截取出来从而达到分割的目的。
WITH RECURSIVE TEMP(CLASS, NAME, START_POS, END_POS, LEVEL) AS(
SELECT CLASS,
NAME,
1, LOCATE(',', NAME, 1),
1
FROM POEM UNION ALL
SELECT CLASS, NAME,
END_POS+1, LOCATE(',', NAME, END_POS+1), LEVEL+1
FROM TEMP
WHERE END_POS > 1)
SELECT NAME, SUBSTRING(
NAME,
START_POS, CASE END_POS WHEN 0 THEN LENGTH(NAME)+1 ELSE
END_POS END - START_POS
) AS ITEM, LEVEL
FROM TEMP
ORDER BY CLASS, LEVEL;
查询结果:
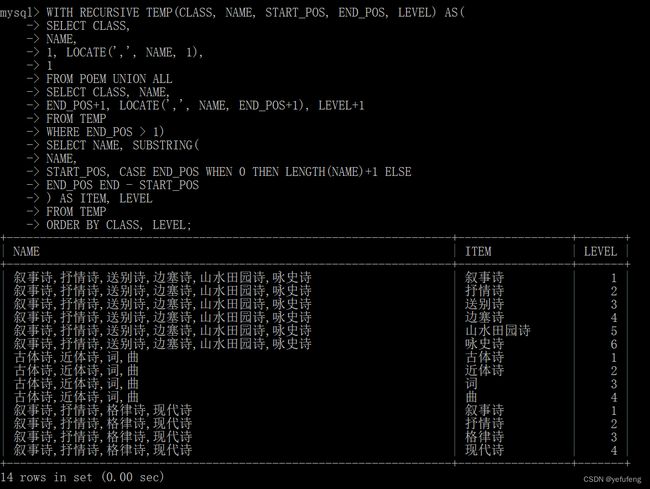
2、使用存储过程
DELIMITER //
CREATE PROCEDURE SPLITSTRING(
IN STR TEXT,
IN DELIMITER CHAR(128)
)
BEGIN
DROP TEMPORARY TABLE IF EXISTS RESULT;
CREATE TEMPORARY TABLE RESULT(VALS TEXT);
/*循环将分割出的字符串插入到结果表,并将取出的字符串去除*/
WHILE LOCATE(DELIMITER,STR) > 1 DO
INSERT INTO RESULT SELECT SUBSTRING_INDEX(STR,DELIMITER,1);
SET STR = REPLACE(STR, (SELECT LEFT(STR, LOCATE(DELIMITER, STR))),'');
END WHILE;
INSERT INTO RESULT(VALS) VALUES(STR);
SELECT TRIM(VALS) FROM RESULT;
END; //
DELIMITER ;
查询结果如下,但由于MySQL不支持将SELECT与存储过程配合使用,且存储函数不支持返回结果集,存储过程只能处理单次数据,较不方便。
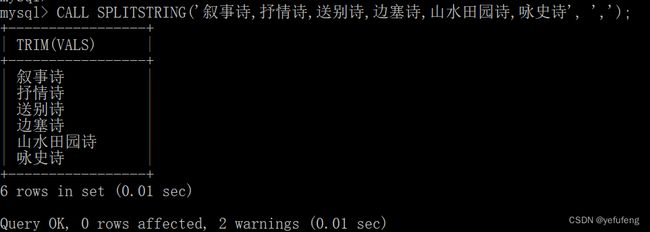
3、使用自增序列
思想与方式一类似,通过带有自增序列的表(这里选择MYSQL.HELP_TOPIC表,可根据情况换成其它表)与目标表进行关联,获取到分割符的位置,从而达到字符串分割的目的,但限制是只能查询一列。
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(t2.name,',',t1.help_topic_id+1),',',-1) AS name
FROM mysql.help_topic t1, poem t2
WHERE
t1.help_topic_id < LENGTH(t2.NAME)- LENGTH(REPLACE(t2.NAME,',',''))+1

二、Oracle
1、递归子查询
效率较快,且易扩展,推荐使用。
WITH BOUNDS ( CLASS, NAME, START_POS, END_POS, LVL ) AS (END_POS
SELECT CLASS, NAME, 1, INSTR( NAME, ',' ), 1 FROM POEM
UNION ALL
SELECT CLASS,
NAME,
END_POS + 1,
INSTR( NAME, ',', END_POS + 1 ),
LVL + 1
FROM BOUNDS
WHERE END_POS > 0
)
SELECT CLASS,
SUBSTR(
NAME,
START_POS,
CASE END_POS
WHEN 0
THEN LENGTH( NAME ) + 1
ELSE END_POS
END - START_POS
) AS ITEM,
LVL
FROM BOUNDS
ORDER BY CLASS, LVL;
2、存储函数
相对于MySQL而言,oracle存储函数支持返回结果集,更为友好。
CREATE OR REPLACE FUNCTION SPLIT_STRING(
I_STR IN VARCHAR2,
I_DELIM IN VARCHAR2 DEFAULT ','
) RETURN SYS.ODCIVARCHAR2LIST DETERMINISTIC
AS
P_RESULT SYS.ODCIVARCHAR2LIST := SYS.ODCIVARCHAR2LIST();
P_START NUMBER(5) := 1;
P_END NUMBER(5);
C_LEN CONSTANT NUMBER(5) := LENGTH( I_STR );
C_LD CONSTANT NUMBER(5) := LENGTH( I_DELIM );
BEGIN
IF C_LEN > 0 THEN
P_END := INSTR( I_STR, I_DELIM, P_START );
WHILE P_END > 0 LOOP
P_RESULT.EXTEND;
P_RESULT( P_RESULT.COUNT ) := SUBSTR( I_STR, P_START, P_END - P_START );
P_START := P_END + C_LD;
P_END := INSTR( I_STR, I_DELIM, P_START );
END LOOP;
IF P_START <= C_LEN + 1 THEN
P_RESULT.EXTEND;
P_RESULT( P_RESULT.COUNT ) := SUBSTR( I_STR, P_START, C_LEN - P_START + 1 );
END IF;
END IF;
RETURN P_RESULT;
END;
3、使用关联表
CONNECT BY在数据量较大时,处理效率较慢,一般不推荐使用。
SELECT T.CLASS,
V.COLUMN_VALUE AS VALUE,
ROW_NUMBER() OVER ( PARTITION BY CLASS ORDER BY ROWNUM ) AS LVL
FROM POEM T,
TABLE(
CAST(
MULTISET(
SELECT REGEXP_SUBSTR( T.NAME, '([^,]*)(,|$)', 1, LEVEL, NULL, 1 )
FROM DUAL
CONNECT BY LEVEL < REGEXP_COUNT( T.NAME, '[^,]*(,|$)' )
)
AS SYS.ODCIVARCHAR2LIST
)
) V;
4、使用分级查询
CONNECT BY在数据量较大时,处理效率较慢,一般不推荐使用。
SELECT T.CLASS,
REGEXP_SUBSTR( NAME, '([^,]*)(,|$)', 1, LEVEL, NULL, 1 ) AS VALUE,
LEVEL AS LVL
FROM POEM T
CONNECT BY
CLASS = PRIOR CLASS
AND PRIOR SYS_GUID() IS NOT NULL
AND LEVEL < REGEXP_COUNT( NAME, '([^,]*)(,|$)' )
5、使用XMLTable和FLWOR表达式
SELECT T.ID,
X.ITEM,
X.LVL
FROM POEM T,
XMLTABLE(
'LET $NAME := ORA:TOKENIZE(.,","),
$CNT := COUNT($NAME)
FOR $VAL AT $R IN $NAME
WHERE $R < $CNT
RETURN $VAL'
PASSING NAME||','
COLUMNS
ITEM VARCHAR2(100) PATH '.',
LVL FOR ORDINALITY
) (+) X;
6、使用CROSS APPLY
此方式只能在Oracle 12c及以上版本使用。
SELECT T.CLASS,
REGEXP_SUBSTR( T.NAME, '([^,]*)($|,)', 1, L.LVL, NULL, 1 ) AS ITEM,
L.LVL
FROM POEM T
CROSS APPLY
(
SELECT LEVEL AS LVL
FROM DUAL
CONNECT BY LEVEL <= REGEXP_COUNT( T.NAME, ',' ) + 1
) L;
7、使用XMLTable
下面语句中的#是为了提取NULL值,并通过SUBSTR( x.item.getStringVal(), 2 )将其删除。若查询表中不存在NULL值可简化查询。
SELECT t.class,
SUBSTR( x.item.getStringVal(), 2 ) AS item,
x.lvl
FROM poem t
CROSS JOIN
XMLTABLE(
( '"#' || REPLACE( t.name, ',', '","#' ) || '"' )
COLUMNS item XMLTYPE PATH '.',
lvl FOR ORDINALITY
) x;
【作者:墨叶扶风 http://blog.csdn.net/yefufeng】