NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务可以转换为图像分类任务,比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。

数据集:CIFAR-10数据集,
网络:ResNet18模型,
损失函数:交叉熵损失,
优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
评价指标:准确率。
5.5.1 数据处理
5.5.1.1数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×32像素。CIFAR-10数据集的示例如图所示。

5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
训练集:40 000条样本。
验证集:10 000条样本。
测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_'+str(batch_id))
#加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding = 'latin1')
imgs = batch['data'].reshape((len(batch['data']),3,32,32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path=r'C:\Users\74502\PycharmProjects\pythonProject\cifar-10-batches-py',
batch_id=1, mode='train')
#打印一下每个batch中X和y的维度
print ("batch of imgs shape: ",imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)

可视化观察其中的一张样本图像和对应的标签,代码如下所示:`
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1,2,0))
plt.savefig('cnn-car.pdf')

5.5.1.3 构造Dataset类
构造一个CIFAR10Dataset类,其将继承自paddle.io.DataSet类,可以逐个数据进行处理。代码实现如下:
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision.transforms as transforms
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path=r'C:\Users\74502\PycharmProjects\pythonProject\cifar-10-batches-py', mode='train'):
if mode == 'train':
#加载batch1-batch4作为训练集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate([self.labels, labels_batch])
elif mode == 'dev':
#加载batch5作为验证集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
#加载测试集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transforms = transforms.Compose([transforms.Resize(32),transforms.ToTensor(), transforms.Normalize(mean=[0.4914,0.4822,0.4465], std=[0.2023, 0.1994, 0.2010])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path=r'C:\Users\74502\PycharmProjects\pythonProject\cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path=r'C:\Users\74502\PycharmProjects\pythonProject\cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path=r'C:\Users\74502\PycharmProjects\pythonProject\cifar-10-batches-py', mode='test')
5.5.2 模型构建
使用PyTorch API中的Resnet18进行图像分类实验。
from torchvision.models import resnet18
resnet18_model = resnet18(pretrained=True)
5.5.3 模型训练
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.nn.functional as F
import torch.optim as opt
from nndl import RunnerV3, Accuracy
# 学习率大小
lr = 0.001
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 定义网络
model = resnet18_model.to(device)
# 定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍
optimizer = opt.Adam(lr=lr,params=model.parameters(), weight_decay=0.005)
# 定义损失函数
loss_fn = F.cross_entropy
loss_fn = loss_fn
# 定义评价指标
metric = Accuracy(is_logist=True)
# 实例化RunnerV3
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
[Train] epoch: 0/30, step: 0/18750, loss: 8.48361
[Evaluate] dev_score: 0.05810, dev_loss: 12.02462
best accuracy performence has been updated: 0.00000 --> 0.05143
[Train] epoch: 4/30, step: 3000/18750, loss: 0.76241
[Evaluate] dev_score: 0.62589, dev_loss: 1.02214
best accuracy performence has been updated: 0.05143 --> 0.64120
[Train] epoch: 9/30, step: 6000/18750, loss: 0.55245
[Evaluate] dev_score: 0.73120, dev_loss: 0.86646
best accuracy performence has been updated: 0.64120--> 0.73652
[Train] epoch: 14/30, step: 9000/18750, loss: 0.56214
[Evaluate] dev_score: 0.71552, dev_loss: 0.86452
[Train] epoch: 19/30, step: 12000/18750, loss: 0.76234
[Evaluate] dev_score: 0.72103, dev_loss: 0.90214
[Train] epoch: 24/30, step: 15000/18750, loss: 0.60124
[Evaluate] dev_score: 0.72440, dev_loss: 0.82145
best accuracy performence has been updated: 0.73652 --> 0.71544
[Train] epoch: 28/30, step: 18000/18750, loss: 0.65241
[Evaluate] dev_score: 0.73246, dev_loss: 0.82426
best accuracy performence has been updated: 0.71544 --> 0.73650
[Train] Training done!
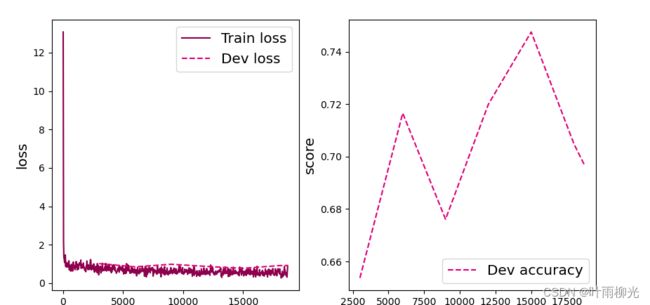
可视化观察训练集与验证集的准确率及损失变化情况。
from nndl import plot
plot(runner, fig_name='cnn-loss4.pdf')
5.5.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
[Test] accuracy/loss: 0.8360/0.6026
5.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
import matplotlib.pyplot as plt
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
logits = runner.predict(X,dim=1)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
# print(pred)
#获取概率最大的类别
pred_class = torch.argmax(pred[2][0]).cpu().numpy()
label = label[2].item()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='D:\project\DL\cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')

The true category is 8 and the predicted category is 8
什么是“预训练模型”?什么是“迁移学习”?(必做)
迁移学习,顾名思义,就是要进行迁移。放到人工智能和机器学习的学科里,迁移学习是一种学习的思想和模式。
首先机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可顺利地实现知识的迁移。
迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
预训练模型可以把迁移学习很好地用起来。这和小孩读书一样,一开始语文、数学、化学都学,读书、网上游戏等,在脑子里积攒了很多。当他学习计算机时,实际上把他以前学到的所有知识都带进去了。如果他以前没上过中学,没上过小学,突然学计算机就不懂这里有什么道理。这和我们预训练模型一样,预训练模型就意味着把人类的语言知识,先学了一个东西,然后再代入到某个具体任务,就顺手了,就是这么一个简单的道理。
参考:https://blog.csdn.net/weixin_43570155/article/details/118030824
比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
resnet18_model = resnet18(pretrained=False)
[Train] epoch: 24/30, step: 15000/18750, loss: 0.30124
[Evaluate] dev_score: 0.72440, dev_loss: 0.89145
[Evaluate] best accuracy performence has been updated: 0.73652 --> 0.72440
[Train] epoch: 28/30, step: 18000/18750, loss: 0.47557
[Evaluate] dev_score: 0.68210, dev_loss: 0.99598
[Evaluate] dev_score: 0.69590, dev_loss: 0.92128
[Train] Training done!
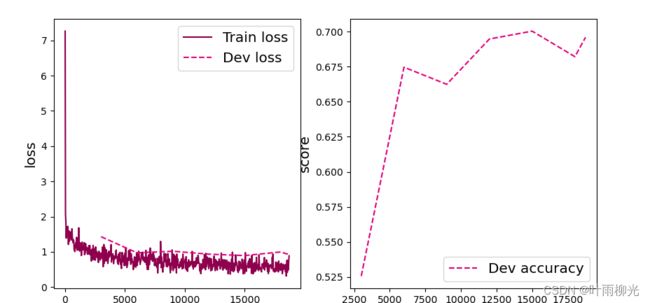
1.使用预训练模型收敛速度更快,更稳定
2.使用预训练模型的准确率更高
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
LeNet
LeNet是最早的卷积神经网络之一。1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如所图示,这里展示的是作者论文中的LeNet-5模型:
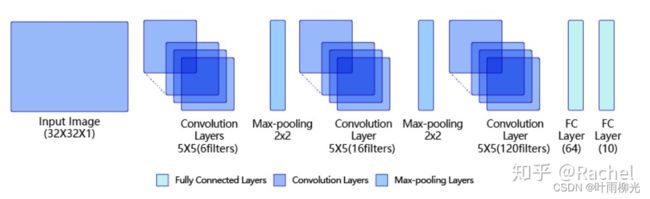
上图就是LeNet网络的结构模型,其中包含:
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用sigmoid),图像尺寸从32减小到28。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到14。
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到10,经过池化后变成5。
第三模块:包含5×5的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别其大小是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
虽然LeNet网络模型对手写数字的识别取得的效果很明显,因为手写数字的输入图片尺寸仅为28x28但是当输入图片的尺寸过大时(224x224),它的效果就不尽人意了。
AlexNet
在2012年,Alex Krizhevsky等人提出的AlexNet以很大优势获得了ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
使用Dropout抑制过拟合
使用ReLU激活函数减少梯度消失现象
AlexNet的具体结构如图:
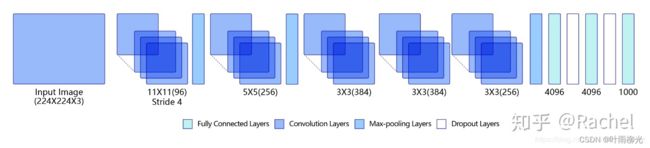
其中有四个模块:
第一模块:包含了11 x 11步长为4的96通道卷积以及一个最大池化
第二模块:包含了5 x 5步的256通道卷积以及一个最大池化
第三模块:包含了两个3 x 3的384通道以及一个3 x 3的256通道的卷积,后面加一个最大池化
第四模块:包含了两个4096通道输入的全连接层,每个全连接层后面加一个Dropout层来抑制过拟合,以及还有最后一个1000通道的全连接层
VGG
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和pooling层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
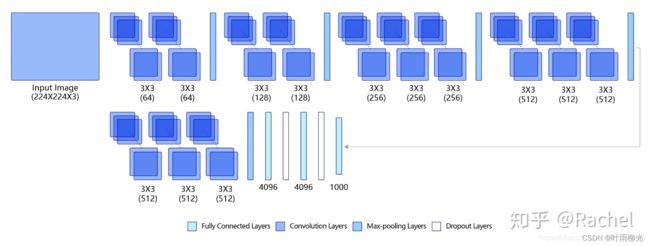
下图是VGG-16的网络结构示意图,有13层卷积和3层全连接层。VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。
使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层3×3卷积层,可以得到感受野为5的特征图,而比使用5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。
GoogLeNet
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核大小来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。如 下图 所示:
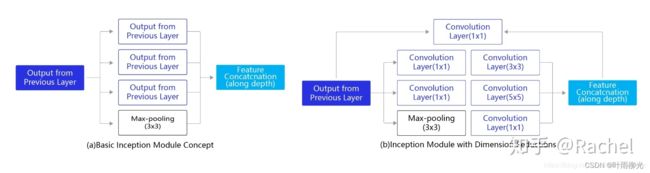
其中(a)是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。
为了减小参数量,Inception模块使用了图(b)中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图(b)中所示的结构。
GoogLeNet的架构如 下图 所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
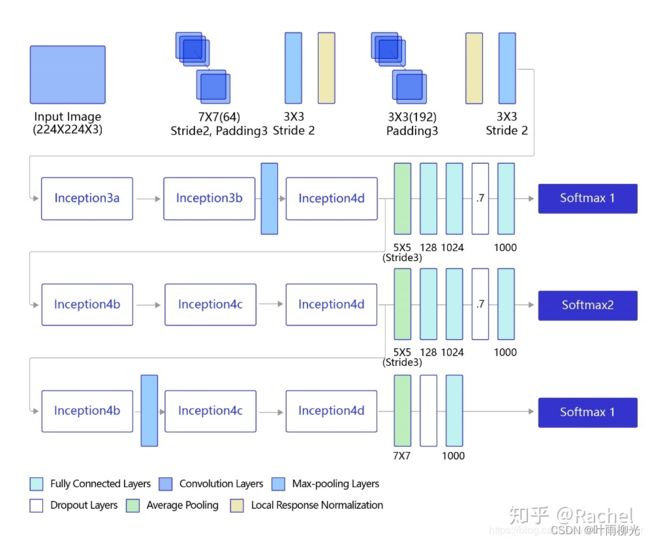
其中:
第一模块使用一个64通道的7 × 7卷积层
第二模块使用2个卷积层:首先是64通道的1 × 1卷积层,然后是将通道增大3倍的3 × 3卷积层。
第三模块串联2个完整的Inception块。
第四模块串联了5个Inception块。
第五模块串联了2 个Inception块。
第五模块的后面紧跟输出层,使用全局平均池化 层来将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。
并且:在原作者的论文中添加了图中所示的softmax1和softmax2两个辅助分类器,如下图所示,训练时将三个分类器的损失函数进行加权求和,以缓解梯度消失现象。这里的程序作了简化,没有加入辅助分类器。
ResNet
ResNet是2015年ImageNet比赛的冠军,将图像分类识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
通过前面几个经典模型学习,我们可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
Kaiming He等人提出了残差网络ResNet来解决上述问题,其基本思想如 下图 所示。
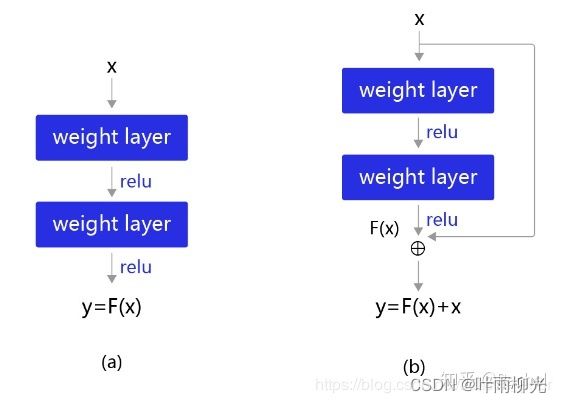
(a):表示增加网络的时候,将x映射成输出。
(b):对(a)作了改进,输出这时不是直接学习输出特征y的表示,而是学习
如果想学习出原模型的表示,只需将F(x)的参数全部设置为0,则y=x是恒等映射。 F(x)=y−x也叫做残差项,如果x→y的映射接近恒等映射,(b)中通过学习残差项也比(a)学习完整映射形式更加容易。
(b)的结构是残差网络的基础,这种结构也叫做残差块(residual block)。输入x通过跨层连接,能更快的向前传播数据,或者向后传播梯度。
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。

来源:https://zhuanlan.zhihu.com/p/162881214
总结
下面是网上我觉得较好的一张图
转载:https://www.cnblogs.com/sophiaecho/p/16595537.html