目标追踪与定位学习笔记3-多目标多摄像机跟踪的局部感知外观度量论文阅读
Locality Aware Appearance Metric for Multi-Target Multi-Camera Tracking
多目标多摄像机跟踪的局部感知外观度量
本文要介绍的是澳洲国立大学(Australian National University)郑良老师实验室和清华大学电子系计算机视觉实验室合作的工作《Locality Aware Appearance Metric for Multi-Target Multi-Camera Tracking》。
文章链接:arXiv;代码:re-id feature extraction,tracker & Locality Aware Appearance Metric
单摄像机跟踪中:局部邻域是指连续帧
多摄像机跟踪中:目标连续出现是指相邻摄像机
算法思路:设计了用于单摄像机跟踪的内摄像机度量,以及用于多摄像机跟踪的内摄像机度量。这两个指标都使用从相应的本地社区采样的数据对进行训练,而不是从重新识别的角度进行全局采样。我们证明了本地学习的指标可以成功地应用于几个全局学习的reID特性之上。

1. 问题概述
多目标多摄像机跟踪(MTMCT)的目的是对多摄像机系统中的所有目标进行实时识别和定位。在一个紧密相关的任务中,给定一个探测图像,再识别(re-ID)系统搜索图库以检索相同身份的图像。MTMCT系统由检测、相似度估计和数据关联等几个部分组成。在单摄像机跟踪(SCT)和多摄像机跟踪(MCT)中,基于相似度估计,对检测到的目标边界框进行关联。由于目标如行人、车辆等具有连续的轨迹,大多数跟踪系统只搜索局部邻域进行数据关联。
时间滑动窗口技术被应用于许多MTMCT系统[37,36,46]。在SCT中,时间滑动窗口将局部匹配邻域限制为摄像机内连续帧。在MCT中,这些窗口将局部匹配邻域限制为目标可能连续出现的相邻摄像机。
[36] Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara,and Carlo Tomasi. Performance measures and a data set formulti-target, multi-camera tracking. InEuropean Conferenceon Computer Vision, pages 17–35. Springer, 2016.
[37] Ergys Ristani and Carlo Tomasi. Features for multi-targetmulti-camera tracking and re-identification. arXiv preprintarXiv:1803.10859, 2018.[46] Y onatan Tariku Tesfaye, Eyasu Zemene, Andrea Prati, Mar-cello Pelillo, and Mubarak Shah. Multi-target tracking inmultiple non-overlapping cameras using constrained domi-nant sets. arXiv preprint arXiv:1706.06196, 2017.
The appearance feature is a driving force in MTMCT. Currently, the tracking community shares very similar appearance representations and deep learning architectures with the re-ID community. That is, the feature is learned globally from the entire train set, and then applied to both SCT and MCT [37, 54].
外观特征是MTMCT的驱动力。如今跟踪问题和重识别问题有非常相似的形式表示和深度学习架构,从训练集上获得整体的标识特征并同时运用到SCT和MCT问题上。
MTMCT问题和reID问题区别:reID问题通常无法获取轨迹、摄像机拓扑结构和其他时空线索,其次,SCT是MTMCT的重要组成部分。
In contrast, re-ID ignores candidates of the same camera as the probe in its evaluation.
在单摄像头追踪时,只搜索单个摄像机视频中的连续帧,在MCT中,当搜索范围被时间滑动窗口缩小时,我们在有限的相机池中进行匹配。
直接使用reID特征时追踪中的局部匹配与全局reID外观特征的不匹配可能会影响MTMCT的性能,造成这种情况的原因很可能是局部和整体特征的不匹配。
虽然重识别学会处理各种各样的环境差异,但是在SCT上,我们只需要相匹配具有相对较小(相对于跨摄像机)外观变化的连续帧,在MCT中我们仍然不需要考虑所有的环境变化。MCT的特征不需要同时对视点方差和低分辨率具有鲁棒性,因为目标不会连续出现在这些摄像机中。在这种情况下,较强的re-ID外观特征并不一定会导致较高的MTMCT结果。
为了适应跟踪中的局部匹配过程,提出了一种局部感知的外观度量(LAAM)。具体来说,对于SCT,我们从单个摄像机的连续帧中采样训练数据对。对于MCT,从相邻摄像机(目标可能连续出现)中选择训练数据对。
2. 相关工作
2.1 单摄像机中的多目标追踪
单摄像机问题是收到多目标跟踪(MOT)的启发。有线上和线下两种方法。在线追踪方法不应该使用来自未来时间段的数据,它们通常以贪婪的方式将检测与小轨迹关联起来。离线方法可以受益于未来的信息。他们通常将问题表述为批量优化,如最短路径,二部图,两两项。为了降低计算复杂度,一些方法采用了分层方法,或者采用了时间滑动窗口。
2.2 跨摄像头的多目标追踪
跨摄像头追踪是MTMCT的一个独特的特性,离线的方法经常为了高精确度使用和多目标追踪问题相似的批优化技术。
有方法使用多个线索来适应相似外观,重遮挡,场景转变的车辆跟踪问题。
2.3 MTMCT问题中REID的特性和使用
reID源自多摄像头追踪。近些年来,这一领域出现很多具有竞争力的CNN结构,
Loss functions and training techniques are studied, such as the contrastive loss, triplet loss and hard negative mining . Data augmentation methods are explored to enrich the database
还有一种方法使用全局特征学习来提高reID和MTMCT的性能。
2.4 多摄像头任务的度量学习
度量学习也被研究在跟踪计算观察之间的相似性。与预定义的距离度量不同,这些学习到的度量可以自动适应特定的场景,并产生更高的精度。
有一种方法训练一个Siamese网络来聚合像素值和光流,还有一种方法从reID数据集学习了一个Siamese网络,用于在线跟踪中的相似度估计。
本文研究局部感知外观度量LAAM来满足MTMCT数据关联中的局部匹配。
3. 系统的概览

给定边界框,**首先将边界框连接成短小可靠的轨迹,然后将这些轨迹合并成单相机的跟踪轨迹,最后单相机的轨迹合并成跨相机的移动轨迹。**本文提出的LAAM包括相机内度量和相机间度量。摄像机内/摄像机间度量分别用于生成单摄像机轨迹和交叉摄像机轨迹。
3.1 问题公式化
将观察到的(边界框,小轨迹、轨迹)作为图的节点,将节点之间的相似度作为节点之间的权重,这样就可以表示出G=(V,E),对每一对节点i,j, w i , j w_{i,j} wi,j代表他们之间的相似性, x i , j ∈ { − 1 , 1 } x_{i,j}\in \lbrace-1,1 \rbrace xi,j∈{−1,1}指的是是否有相同的特征。则优化问题的公式如下:
max x i , j ∑ ∀ i , j ∈ V x i , j w i , j 、 ( 1 ) s . t . x i , j + x j , k ≤ 1 + x i , k , ∀ i , j , k ∈ V . \max _{x_{i,j}} \sum _{∀ i,j∈V} x_{i,j}w_{i,j} 、\quad\quad\quad (1)\\ s.t. x_{i,j} +x_{j,k}\leq 1+x_{i,k}, ∀i,j,k∈V. xi,jmax∀i,j∈V∑xi,jwi,j、(1)s.t.xi,j+xj,k≤1+xi,k,∀i,j,k∈V.
类似于LDA降维的问题,要求在组内具有最大的相似度,组间具有最小的相似度,并且具有传递性,即如果两个数据都与第三个数据点共享相同的身份,这两个数据应该具有相同的身份。In fact,a better estimation w i , j w_{i,j} wi,j will make this optimization problem easier,and impove association accuracy.
对不同的数据集使用不同的策略,DukeMTMC,使用OpenPose检测器,CityFlow数据集,使用AI-City2019挑战的SSD检测器。
3.2 相似度估计
在基础算法中,给出CNN的一对特征 f i 和 f j f_i和f_j fi和fj,他们之间的相似度估计可表示为:
w i , j = t h r e s − d ( f ⃗ i , f ⃗ j ) n o r m ( 2 ) w_{i,j} = \frac {thres - d(\vec f_i,\vec f_j)} {norm} \quad\quad\quad (2) wi,j=normthres−d(fi,fj)(2)
其中 d ( f ⃗ i , f ⃗ j ) d(\vec f_i,\vec f_j) d(fi,fj)代表两个向量的距离,这里采用欧氏距离度量, t h r e s = μ n + μ p 2 thres = \frac {\mu_n + \mu_p} {2} thres=2μn+μp 和 n o r m = μ n − μ p 2 norm = \frac {\mu_n - \mu_p} {2} norm=2μn−μp,其中 μ p 和 μ n \mu_p 和 \mu_n μp和μn分别代表相同恒等式和不同恒等式的平均特征距离。
3.3 数据联合
对于SCT,我们使用短时间滑动窗口来关联小轨迹,对于MCT,由于目标在摄像机间的行走时间较长,在数据关联中使用了较长的时间滑动窗口。
4. 局部感知外观度量
一个好的相似度度量模型可以提高联合的效率,本文提出一种新的局部感知外观度量(LAAM),聚焦于局部临近样本。和全局搜索的reID问题不同,学习到的局域感知外观度量侧重于匹配局部临近候选图像,更适合MTMCT中的局部匹配任务。LAAM由一个度量网络和新的数据采样策略组成。
4.1 度量网络结构
The metric network is used to compute similarity scores between a pair of tracklets or trajectories, both of which are generated by global average pooling bounding box features.
度量网络用于计算一对轨迹或轨迹之间的相似性得分,这两种相似性得分都是由全局平均池化边界盒特征生成的,上述 d ( f ⃗ i , f ⃗ j ) d(\vec f_i,\vec f_j) d(fi,fj)表示欧几里得距离,此处将使用度量网络结构代替,用来优化相似度判别。

度量网络有三层的感知器组成,隐藏的全连接层的输出是128维的向量,然后接ReLU激活函数。给定一对向量 f ⃗ i , f ⃗ j \vec f_i,\vec f_j fi,fj,它们的绝对差 f ⃗ = ∣ f ⃗ i − f ⃗ j ∣ \vec f = |\vec f_i-\vec f_j| f=∣fi−fj∣,将此向量作为网络的输入,输出为2维的softmax向量,表示为 x = ( x 0 , x 1 ) x = (x_0,x_1) x=(x0,x1),两个分量代表输入对具有不同单位或相同单位的可能性进行编码。
在训练过程中,re-ID的部分保持不动,只更新度量网络的部分。利用交叉熵损失函数将度量问题转化为分类问题。
During testing, we exert a scaling factor of 0.1 onto the softmax layer, to prevent the appearance similarity score from overshadowing other cues, e.g., spatialtemporal cues.
在测试的过程中,在softmax施加0.1的比例因子,以防止外观相似度评分掩盖例如时空线索的其他线索。此时所提出度量的相似度得分的计算方法为: w = x 1 − x 0 w = x_1-x_0 w=x1−x0
若数据对属于同一种身份,则相似度的值为正,否则为负。
4.2 摄像头内度量和摄像头间度量
局部感知外观度量(LAAM)Locality Aware Appearance Metric对于单摄像头跟踪和多摄像头跟踪有摄像头内度量和摄像头间度量,两种度量指标都是用本地邻近数据对进行训练的。
类似于数据关联,我们发现时间窗可以有效地找到相机内或相机间对应的局部邻域。因此在本文提出的LAAM中使用时间窗对训练数据进行采样。
**相机内度量:**在SCT中的数据关联,训练一个摄像头内的度量来提供小轨迹之间的相似性估计,该度量网络以轨迹特征作为输入进行训练和测试。训练时,在图片的真实值上计算小轨迹特征。在测试时,从行人检测中计算小轨迹特征。
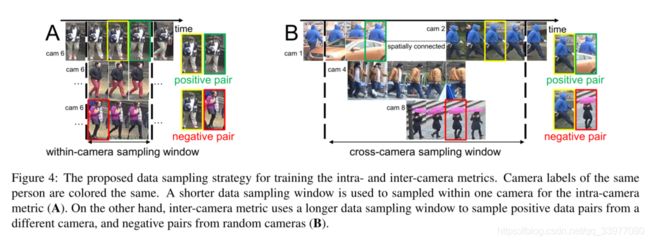
In training, we sample local neighboring data pairs within a small temporal duration of τSfrom the target camera. As shown in Fig. 4, for every tracklet (yellow box) and the corresponding feature fi, we first randomly select data pair being of the same identity or not. These same identity data pairs and different identity data pairs are denoted as positive pairs and negative pairs, respectively. Note that the positive/negative pairs are generated with a 1 : 1 ratio for data balance. We then choose the corresponding tracklet feature fjfor the positive/negative pair. For positive pairs, we sample a tracklet (green box) that belongs to the same identity n as the first tracklet, within the τS-sized window. For negative pairs, we sample a tracklet (red box) that belongs to a different identity, within the same data sampling window. Either way, we end up with a tracklet feature pair f i a n d f j f_i and f_j fiandfj fi and fj. At last, we feed the absolute difference vector f = ∣ f i − f j ∣ f = | f_i - f_j | f=∣fi−fj∣into the metric network as input.
训练过程中我们从目标摄像机中的一小段时间 τ S \tau_S τS范围内采样局部邻域数据对。在图中,每一个边界框和对应的特征 f ⃗ i \vec f_i fi。首先我们随机选择是否具有相同特征的数据对。这些相同特征的数据对和不同特征的数据对分别表示正对和副对。并且保证类别之间的数据平衡。然后选择对应的小轨特征fj作为正/负对。对于正对,我们在 τ s \tau_s τs大小窗口内采样一个与第一个小轨迹同一性n的小轨迹(绿框)。对于负对,我们在同一个数据采样窗口中采样属于不同身份的小轨迹(红框)。无论哪种方式,我们最终得到一个小轨迹特征对 f i 和 f j f_i 和f_j fi和fj。最后,我们将绝对差向量 f = ∣ f i − f j ∣ f = | f_i - f_j | f=∣fi−fj∣输入到度量网络中。
**相机间度量:**相机间度量以轨迹/轨迹特征作为输入,分别进行训练和测试。在训练过程中,由于缺少单摄像机轨迹,使用tracklet特征而不是轨迹特征。与相机内度量相同,训练的轨迹特征是在真实图像上计算的。在测试过程中通过行人检测计算轨迹特征。
跨相机数据对构造和单摄像机数据对构造不同之处:
- 在跨摄像机的 τ M \tau_M τM帧长的数据样本中选择数据对。这种跨摄像机的采样窗口长度 τ M \tau_M τM通常比单摄像头采样的窗口长度 τ S \tau_S τS长。
- 正负样本对的采样机制不一样。正样本数据对采样了属于相同特征的n的轨迹(绿边框)作为大小为 τ M \tau_M τM窗口的第一个轨迹,并要求从不同的摄像机进行采样。负样本数据对从一个随机的摄像机内的时间采样窗口 τ M \tau_M τMsample出了一个属于不同个体的轨迹(红框).
4.3 讨论
**数据采样窗口和时间滑动窗口:**二者有很多相似之处,都用于将数据池限制为其本地邻域。但是时间滑动窗口用于数据关联,在数据采样中使用数据采样窗口来训练局部感知的外观度量(LAAM)
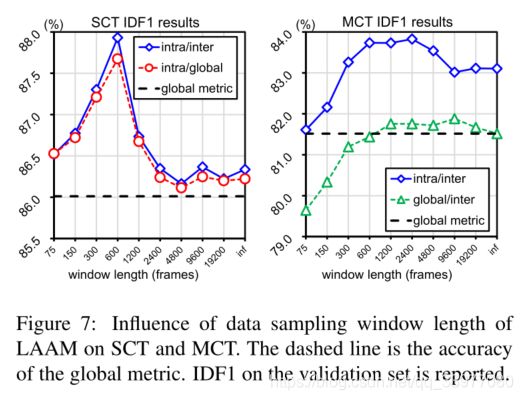
**数据采样窗口的长度:**相机内度量和相机间度量的数据采样窗口是不一样的。相机内数据采样窗口的长度 τ S \tau_S τS与平均轨迹持续时间相似。跨摄像机数据采样窗口 τ M \tau_M τM应足够长,以覆盖不同摄像机中相同身份的局部邻近轨迹。效果如图7所示。

**全局度量和局部感知外观度量:**我们通过统计数据比较来验证LAAM。SCT和MCT过程中的匹配误差如图6所示。我们对SCT使用相机内度量,对MCT使用相机间度量。使用该方法,假正例率明显低于全局度量,而假反例率保持非常相似。
**极限情况下:**首先,当视频帧率非常低时,除非它们返回,否则每个目标只会在一个摄像机中出现一次。在这种情况下,SCT将失去作用,因此摄像机内的度量将被淘汰。但是,由于轨迹连续性仍然保持,拓扑没有改变,MCT中的局域性不会受到影响。因此,摄像机间的度量仍然是有用的。其次,在开放拓扑中,目标以相同的概率到达所有摄像机。这一次,摄像机间的度量将回落到全局度量。然而,SCT数据关联仍然是局部的,因此摄像机内度量是有用的。
5. 实验分析
5.1 数据集
本实验采用DukeMTMC数据集和CityFlow数据集评估本文提出的方法。
DukeMTMC行人跟踪数据集,包含学校校园的8个摄像头拍摄的1080p,60fps的视频。
CityFlow是车辆跟踪数据集,具有较低的帧率10fps和严重的遮挡,以及从40个摄像头快速移动的车辆,跨越超过2公里。
**DukeMTMC的训练和验证集:**使用前40分钟视频作为训练集,使用剩下的10分钟作为验证集,对于验证和在线测试,我们只是用训练集来训练。
**评估指标:**对于多摄像头多目标跟踪问题使用IDF1,IDP,IDR作为评估指标。CityFlow只使用MCT,对上述两个标黄的数据集,我们使用在线的测试集进行评估模型性能。reID评估,使用rank-1和mAP进行评估。
5.2 实现细节
**reID特征:**在DukeMTMC中,使用三个全局学习的重识别特征:IDE(ID-discriminative embedded), triplet(三重特征), partial-based convolutional baseline(PCB).
训练中,将输入图像的大小调整至384*128,使用随机擦除进行数据增强,类似于神经网络中的dropout,随机去掉网络中的连接,能够很好的防止模型过拟合。使用真实值的 1 60 \frac 1 {60} 601(每秒一帧作为训练数据),以期更快的收敛,并且不会导致准确率的下降。使用ImageNet上预训练的ResNet50作为三个模型的骨干。在CityFlow中,使用带有softmax和tripleloss的基于reID特征的DenseNet121网络。对CityFlow提供的车辆重新识别数据集进行训练。
**MTMCT跟踪器的基础:**基于DeepCC研究,只有一处修改。允许目标返回同一个摄像机,这既有助于在长时间遮挡后识别目标但对短时间滑动窗口的SCT是非常困难的。
[37] Ergys Ristani and Carlo Tomasi. Features for multi-target multi-camera tracking and re-identification. arXiv preprint arXiv:1803.10859, 2018.
在DukeMTMC上,每个轨迹有40帧。SCT和MCT的时间滑动窗口长度分别为150帧和6000帧。在CityFlow中,我们将tracklet的长度设置为10帧。SCT和MCT的时间滑动窗口分别设置为500帧长和2400帧长。
μ p 和 μ n \mu_p 和 \mu_n μp和μn是从两个数据集的训练集中计算。
**度量学习设置:**The proposed locality aware appearance metric is trained with tracklet features, average pooled from ground truth image re-ID features.
LAAM使用小轨迹特征,从reID真实值的平均池化进行训练,学习率在前30个epoch设置为0.0001,在最后10个epoxh下降到0.1,batchsize设置为64,在度量网络中使用交叉熵损失函数。
| Dataset | τ S \tau_S τS | τ M \tau_M τM |
|---|---|---|
| DukeMTMC | 600 frames | 2400 frames |
| CityFlow | 30 frames | 500 frames |
5.3 ReID特征的评估
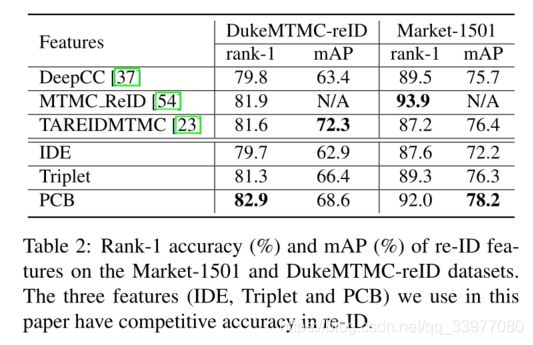
在ReID中的性能评估有PCB,IDE和Triplet,在现有的MTMCT工作上使用reID特征的性能和本文所总结的分析来看,IDE和Triplet性能相当,低于PCB。本文所提出的特征提取器在DuckMTMC-reID和Market1501上具有较强的竞争力,PCB的准确率能够达到92%(Market1501)。
In the following experiment, if not specified, we use IDE as the default pedestrian descriptor due to its good accuracy and easy implementation.
5.4 在提出的方法中评估
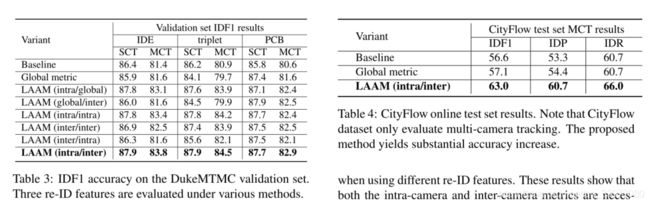
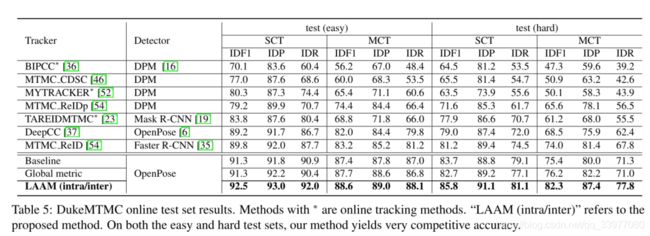
在基础跟踪器上的改进和全局度量学习:
- 全局度量学习并没有在基础算法中得到改善,因为基础算法和全局度量都是在全局训练集上进行的,它们的辨别能力非常相近。
figure4 shows the situation - 完整的LAAM方法在基础算法和全局度量上带来一致的、重要的改进。从提高基线精度的能力方面证明了我们的全方法的有效性和泛化能力,从而在一定程度上验证了所提出的度量。
**不同reID特征的影响:**基于不同reID特征的跟踪精度总结如表3所示,因为追踪过程中外观变化比重识别过程中要小得多,在MCT中临时滑动窗口可能只有几十个图像,而reID中则有超过10000个图像。在更小的图库中,对特征识别能力的要求更低,PCB与IDE具有类似的匹配精度。此外,MTMCT除了基于特征的匹配外,还有其他几个组成部分。这些组件的不完善降低了re-ID特性带来的改进。
**Comparison with variants and ablation study:**使用相机内度量替代相机间度量或者反过来,结果都有所不同程度的下降,当使用不同的re-ID功能时,下降是一致的。这些结果表明,摄像机内和摄像机间指标都是我们系统的必要组成部分。
从ablation study来看,去除相机内度量会导致更大的下降。可能的原因是,re-ID跟踪中局部数据关联与全局匹配的方差差距在SCT中较大,而在MCT中较小。在单台摄像机中,目标的外观变化非常小。在相邻摄像机对之间,外观有较大的变异(仍然小于全局)。从全局意义上说,外观变化是最大的。由于SCT(局部)和re-ID(全局)匹配之间存在最大的差距,摄像机内度量有较大的改进。
这两个指标是不可互换的,表三也证明了此点,同时证明相机内度量在SCT上最有效以及相机间度量在MCT上最有效。
**与目前的方法进行比较:**表5显示了本文所使用的IDE方法与最先进的方法进行比较。首先基础所使用的跟踪器都非常有竞争力,这证明本文所改进的跟踪器和重识别特征的有效性。其次,LAAM进一步改进了具有竞争力的基线跟踪器,并在简单和困难测试集上都实现了新的最先进的精度。
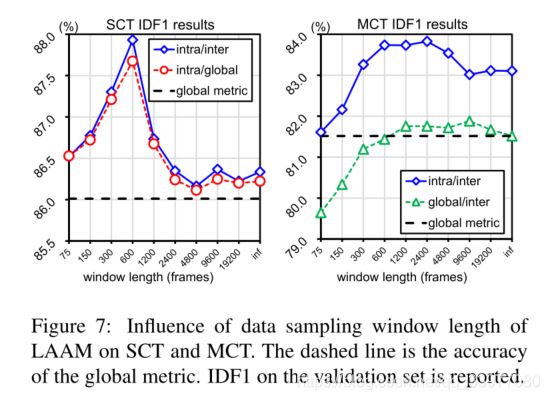
**参数设置:**采样窗口的长度也直接影响模型的性能,短的采样窗口可能会显著减少训练对的选择,使度量更容易过拟合。另一方面,较长的采样窗口不再支持局地性。
A short sampling window may significantly reduce the choices of training pairs, leaving the metric more prone to overfitting. On the other hand, a long sampling window no longer underpins locality.
还有两个值得注意的现象:首先,从图7可以看出,为MCT设计的摄像机间度量也改进了SCT。事实上,我们的跟踪器允许返回目标,所以正确地标记这些返回目标可以提高SCT的准确性。第二,从图7中可以看出,短窗口下摄像机间的度量低于全局度量。这是因为当跨摄像机采样窗口小于摄像机过渡时间时,将不会有足够的跨摄像机训练样本。
**计算性能:**在GTX 1080ti GPU的服务器上,度量网络需要20分钟的训练时间。测试过程中,使用GPU提取CNN特征,计算包括度量相似度评分在内的跟踪器。测试过程,还有创建小轨迹,计算单相机的轨迹等操作。在算法过程中还需要计算跨摄像机轨迹。
在MTMCT中,更好的相似度估计通常使数据关联更容易。虽然LAAM在相似度估计上花费了更多的时间,但它通过提供更准确的相似度评分节省了数据关联的时间。在SCT中,数据关联相对简单,大部分时间花在相似性计算上。在MCT中,数据关联比较困难,并且控制着计算时间。结果,与基础算法相比,我们的方法在SCT上更慢,在MCT上花费的时间也差不多。
6. 总结
re-ID是一个全局匹配问题,而MTMCT是基于局部匹配的。这种差异影响了直接应用全局re-ID外观特征进行MTMCT局部匹配的有效性。
本文提出了局域感知外观度量(LAAM),它使用了一种新的训练数据采样策略。给定全局学习的再识别特征,训练数据对从其局部邻域采样。对于单摄像机跟踪(SCT),局部邻域是指单摄像机内连续帧;对于多摄像机跟踪(MCT),指目标可以连续出现的相邻摄像机。在两个MTMCT数据集上,我们表明LAAM导致了基线的显著改进,并报告了DukeMTMC的最新跟踪精度。