pandas基础学习
1、pandas介绍
pandas是python中专门专门用于数据处理和数据分析的第三方库。
pandas常用的基本功能如下:
- 从Excel、CSV、网页、SQL、剪切板等文件或工具中读取数据
- 合并多个文件或电子表格中的数据,将数据拆分为独立的文件
- 数据清洗、如去重、处理缺失值、填充默认值、补全格式,处理极端值等
- 建立高效的索引、支持大体量数据、灵活方便的数据查询、筛选
- 按一定业务逻辑插入计算后的列、删除列
- 分组聚合数据,可独立指定分组后的各字段计算方式
- 数据的装置,如行装列,列转行变更处理
- 连接数据库,直接用SQL查询数据并进行处理
- 对时序数据进行分组采样,如按季、月、小时,也可以自定义周期,如工作日
- 窗口计算,移动窗口统计、日期移动等
- 灵活的可视化图表输出,支持所有的统计图像
- 为数据表格增加展示样式,提高数据识别效率
2、pandas的数据结构
pandas提供了Series和DataFrame作为数组数据的存储框架,数据进入这两种框架后,就可以用他们提供的强大的处理方法进行数据处理。
2.1 Series
Series(系列、数列、序列)是一个带有标签的一维数组,是由一组数据以及与这组数据有关的标签(索引)组成,Series对象可以存储整数、浮点数、字符串、Python对象等多种数据类型的数据,是pandas最基础的数据结构。各国的GDP就是一个典型的数据结构,如:中国 14.34 ,其中,国家是标签(也称索引),不是具体的数据,起到解释、定位数据的作用。
2.1.1 Series对象的创建
语法结构:pd.Series(data,index=index)
#series对象的创建
import pandas as pd
data=[13.14,21.34,5.08,10.18]
index=['中国','美国','意大利','俄罗斯']
s=pd.Series(data=data,index=index)
print(s)
中国 13.14
美国 21.34
意大利 5.08
俄罗斯 10.18
dtype: float64
2.1.2 Series的索引
位置索引,范围为[0,N-1]
#位置索引
data=[13.14,21.34,5.08,10.18]
s=pd.Series(data=data)
print(s)
print(s[2])#s[2]---获取位置索引为2的值
0 13.14
1 21.34
2 5.08
3 10.18
dtype: float64
5.08
标签索引
Series对象名[索引名称]
获取多个标签索引值,使用[[标签索引1,标签索引2,……]]
data=[13.14,21.34,5.08,10.18]
index=['中国','美国','意大利','俄罗斯']
s=pd.Series(data=data,index=index)
print(s)
print(s['中国'])#中国,为标签索引
print(s[['中国','俄罗斯']])#获取多个数据
中国 13.14
美国 21.34
意大利 5.08
俄罗斯 10.18
dtype: float64
13.14
中国 13.14
俄罗斯 10.18
dtype: float64
切片索引 :Series对象名[start : stop : step]
data=[13.14,21.34,5.08,10.18]
index=['中国','美国','意大利','俄罗斯']
s=pd.Series(data=data,index=index)
print(s[0:2:2])#位置索引切片,含投不含尾
print(s['中国':'意大利':2])#标签索引切片,含头含尾
中国 13.14
dtype: float64
中国 13.14
意大利 5.08
dtype: float64
获取Series的索引和值 :获取索引s.index,获取值s.values
data=[13.14,21.34,5.08,10.18]
index=['中国','美国','意大利','俄罗斯']
s=pd.Series(data=data,index=index)
print(s.index)
print(list(s.index))#通常将索引转换成列表输出
print(s.values)
Index([‘中国’, ‘美国’, ‘意大利’, ‘俄罗斯’], dtype=‘object’)
[‘中国’, ‘美国’, ‘意大利’, ‘俄罗斯’]
[13.14 21.34 5.08 10.18]
2.2 DataFrame
DataFrame意为数据框架,是Pandas库中的一种数据结构,类似于二维表,由行和列组成,与Series一样支持多种数据类型
2.2.1 DataFrame对象的创建
语法结构:pd.DataFrame(data,index,columns,dtype)
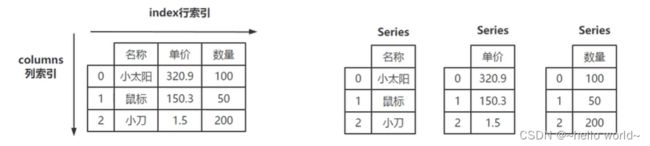
#创建方式一:列表方式创建DataFrame对象
data=[['小太阳',320.9,100],['鼠标',150.3,50],['小刀',1.5,200]]
column=['名称','单价','数量']
df=pd.DataFrame(data=data,columns=column)
print(df)
print(type(df))
名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200
#创建方式二:字典方式创建DataFrame对象
ata={'名称':['小太阳','鼠标','小刀'],
'单价':[320.9,150.3,1.5],
'数量':[100,50,200]}
f=pd.DataFrame(data=data)
print(df)
print(type(df))
名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200
注意事项:使用字典创建DataFrame对象时,列表长度必须保持一致;当值为单个时,其他行自动填充
2.2.2 DataFrame的属性
| 属性 | 描述 |
|---|---|
| values | 查看所有元素的值 |
| dtypes | 查看所有元素的类型 |
| index | 查看所有行名、重命名行名 |
| columns | 查看所有列名、重命名列名 |
| T | 行列数据转换 |
| head | 查看前N条数据,默认5条 |
| tail | 查看后N条数据,默认5条 |
| shape | 查看行数和列数shape[0]表示行,shape[1]表示列 |
| info | 查看索引、数据类型和内存信息 |
#values——查看所有元素的值
data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('查看所有值\n',df.values)

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看所有元素的类型\n', df.dtypes)

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看所有行名称\n',list(df. index))
print('------------')
df.index=[1,2,3]#修改行名称
print ('修改行名称后的df\n',df)

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看列索引\n', df.columns)
print('------------')
df.columns=['国家','商品数量','GDP']
print('查看列名称该后的df\n',df)

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=df.T
print('转置后的df\n',df)

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看前2条数据\n',df.head(2))
print('------------')
print('查看后1条数据\n',df.tail(2))
print('------------')
print('查看行数和列数\n','行',df.shape[0],' 列',df.shape[1])

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看索引,数据类型,内存信息\n',df.info)

2.2.3 DataFrame的函数
| 属性 | 描述 |
|---|---|
| describe() | 查看每列的统计汇总信息,DataFrame类型 |
| count() | 返回每一列的非空值的个数 |
| sum() | 返回每一列的和,无法计算返回空值 |
| max() | 返回每一列的最大值 |
| min() | 返回每一列的最小值 |
data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看每列的统计汇总信息\n', df.describe())

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('查看每列的统计汇总信息\n', df.describe())
print('------------')
print('返回每一列的非空值的个数\n',df.count())

data=[['中国',1400,21],['美国',7000,25],['俄罗斯',1000,18]]
column=['国家','数量','GDP']
df=pd.DataFrame(data=data,columns=column)
print(df)
print('------------')
print('返回每一列的和,无法计算返回空值\n',df.sum())
print('------------')
print('返回每一列的最大值\n',df.max())
print('------------')
print('返回每一列的最小值\n',df.min())

3、数据基础操作
3.1 导入数据
3.1.1 导入Excel数据
Excel数据常常导入的是.xls或.xlsx文件
语法结构:pd.read_excel(io,sheet_name,header)
io:表示.xls或.xlsx文件路径或类文件对象.
sheet_name:表示工作表,取值如下表所示
header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None
| 值 | 说明 |
|---|---|
| sheet_name=0 | 第一个Sheet页中的数据作为DataFrame对象 |
| sheet_name=1 | 第二个Sheet页中的数据作为DataFrame对象 |
| sheet_name=‘Sheet1’ | 名称为’Sheet1’的Sheet页中的数据作为DataFrame对象 |
| sheet_name=[0,1,‘Sheet3’] | 第一个、第二个和名称为Sheet3的Sheet页中的数据作为DataFrame对象 |
| sheet_name=None | 读取所有工作表 |
#导入Excel数据
data=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(data)
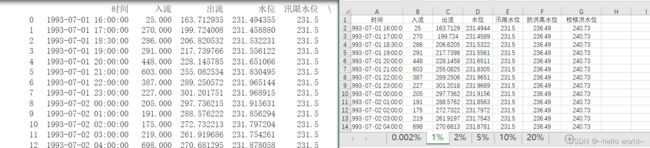
#导入指定列的数据
import pandas as pd
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%' , usecols=['入流','出流','水位'])
print (df)

3.1.2 导入CSV文件
除了Excel文件,CSV文件是pandas另一种重要文件形式,CSV可用记事本打开
语法结构:pd.read_csv(filepath_or_buffer,sep=,header,encoding=None)
filepath_or_buffer:字符串、文件路径,也可以是URL链接
sep:每行数据内容的分割符号字符串、分隔符,CSV常用’,’
header:指定作为列名的行,默认值为0,即取第一行的值为列名。数据为除列名以外的数据,若数据不包含列表,则设置header=None
names:用来指定列的名称,类似于列表的序列,不允许有重复值
usecols:用来获取指定列名的的数据
skip_blank_lines:跳过指定行数
nrows:用于指定需要读取的行数,常用于较大的数据
encoding:字符串,默认值为None,文件的编码格式
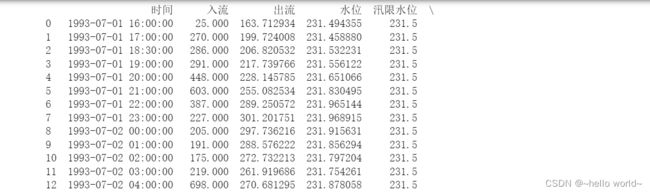
df=pd.read_csv(r'C:\Users\Desktop\data.CSV',sep=',',encoding='gbk')#ANSI默认为gbk
pd.set_option('display.unicode.east_asian_width',True)#规则格式
print(df)
3.1.3 导入MTHL网页
语法结构:pd.read_html(io,match='.+ ',flavor,header,encoding)
io:字符串、文件路径,也可以是URL链接,网址不接受https
match:正则表达式
flavor:解释器,默认为’lxml’.
header:指定列标题所在的行
encoding:文件的编码格式
注:导入MTHL网页数据时只能导入table标签的数据
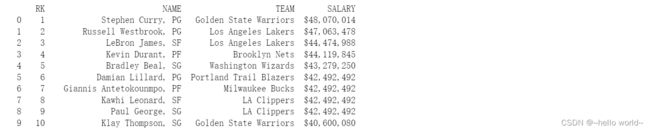
#导入HTML
url='http://www.espn.com/nba/salaries'
df=pd.DataFrame()#创建一个空的DataFrame对象
#DataFrame添加数据
df=df.append(pd.read_html(url,header=0))
print (df)
#将数据保存
df.to_csv('nba球员薪水',index=False)#index=False表示保存时不要索引,保存位置与该编码文件在同一个目录
3.2 数据提取
3.2.1 按行提取
数据提取常用到DataFrame对象的loc属性与iloc属性
loc属性,以列名(columns)和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整行数据,包括所有列。
iloc属性,以行和列位置索引(即:0,1,2…)作为参数,0表示第一行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。
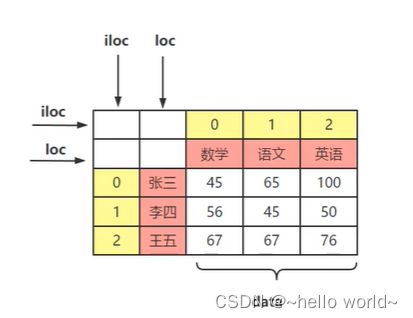
data=[[45,65,200],[56,45,50],[67,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print (df)
print('----------')
#提取单行数据
print('loc提取行数据\n',df.loc['李四'])
print('----------')
print('loc提取行数据\n',df.iloc[1])

data=[[45,65,200],[56,45,50],[67,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print (df)
print('----------')
#提取多行数据
print('loc提取多行数据\n',df.loc[['张三','王五']])
print('----------')
print('loc提取多行数据\n',df.iloc[[0,2]])

data=[[45,65,200],[56,45,50],[67,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print (df)
print('----------')
#提取多行数据
print('loc提取连续多行数据\n',df.loc['张三':'王五'])#含头含尾
print('----------')
print('loc提取连续多行数据\n',df.iloc[0:2])#含头不含尾

3.2.2 按列提取
data=[[45,65,200],[56,45,50],[67,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print (df)
print('----------')
print('直接提取\n',df[['数学','英语']])#直接提取
print('----------')
#提取多行数据
print('loc提取列数据\n',df.loc[:,['数学','英语']])#含头含尾
print('----------')
print('iloc提取连续多列数据\n',df.iloc[:,1:])#含头不含尾

3.2.3 提取区域数据
data=[[45,65,200],[56,45,50],[67,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('----------')
print('李四的数学与英语成绩\n',df.loc['李四',['数学','英语']])
print('----------')
print('张三与王五的语文成绩\n',df.iloc[[0,2],[1]])

3.2.4 提取指定条件数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('----------')
print('提取数学成绩及格的数据\n',df.loc[df['数学']>=60])
print('----------')
print('提取数学和语文成绩都及格的数据\n',df.loc[(df['数学']>=60)&(df['语文']>=60)])

3.3 数据操作
3.3.1 数据的增加
按列增加数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('----------')
df['物理']=[67,89,94]
print('直接采用赋值的方式在最后增加一列\n',df)
print('----------')
df.loc[:,'化学']=[76,83,95]
print('用col属性在最后增加一列\n',df)

#在指定索引处插入列数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('----------')
lst=[67,89,94]
df.insert(2,'物理',lst)
print('在索引为2处增加一列\n',df)

按行增加数据
#按行增加数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('----------')
df.loc['陈六']=[56,64,71]
print('在最后增加一行数据\n',df)

#合并两个DataFrame对象
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张时','李阿','王明']
columns=['数学','语文','英语']
df1=pd.DataFrame(data=data,index=index,columns=columns)
df=df.append(df1)#需要赋值,赋值看不到拼接效果
print(df)

3.3.2 数据的修改
修改列标题,使用DataFrame对象的columns属性直接赋值,或者使用DataFrame对象的rename方法修改列标题
#修改行标题
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('------------')
df.columns=['数学(上)','语文(上)','英语(上)']
print('直接修改:\n',df)
print('------------')
df.rename(columns={'数学(上)':'math','语文(上)':'chinese','英语(上)':'english'},inplace=True)
print('用rename方法:\n',df)

修改行标题,使用DataFrame对象的index属性直接赋值,,或者使用DataFrame对象的rename方法修改行标题
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('------------')
df.index=['张时','李阿','王明']
print('直接修改:\n',df)
print('------------')
df.rename({'张时':'zhangshi','李阿':'lia','王明':'wangming'},inplace=True,axis=0)
print('用rename方法:\n',df)

修改数据,使用DataFrame对象的loc属性和iloc属性
#修改数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('--------------')
df.loc['张三']=[100,100,90]#修改一整行
print ('修改一整行数据\n',df)
print('--------------')
df.iloc[0,:]=[90,90,90]#修改第0行的所有列
print('修改一整行数据\n',df)
print('--------------')
df.iloc[1,1]=78#修改第0行的所有列
print('修改单个数据\n',df)

3.3.3 数据的删除
使用DataFrame对象中的drop方法()
语法结构:df.drop(labels=None,axis=0,index=None,columns=None,inplace=False)
labels:表示行标签或列标签
axis:axis=0表示按行删除,axis=1表示按列删除
index :删除行,默认值为None
columns:删除列,默认值为None
inplace:对原数组作出修改并返回一个新数组。默认值为False,如果值为True,那么原数组直接就将被替换
删除列数据
#删除列数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('--------------')
df1=df.drop(['数学'],axis=1,inplace=False)
print(df1)
print('--------------')
df2=df.drop(columns='数学', inplace=False)
print(df2)
print('--------------')
df.drop(labels='数学', axis=1,inplace=True)
print(df)

删除行数据
#删除行数据
data=[[75,56,80],[56,45,50],[60,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('--------------')
df1=df.drop(['张三'],axis=0,inplace=False)
print(df1)
print('--------------')
df2=df.drop(index='张三', inplace=False)
print(df2)
print('--------------')
df.drop(labels='张三', axis=0,inplace=True)
print(df)

删除指定条件的数据
#删除指定条件的数据
data=[[75,56,80],[56,45,50],[50,67,67]]
index=['张三','李四','王五']
columns=['数学','语文','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print('--------------')
df.drop(df[df['数学']<60].index[:], inplace=True)
print('删除数学成绩小于60的数据\n',df)

3.4 数据清洗
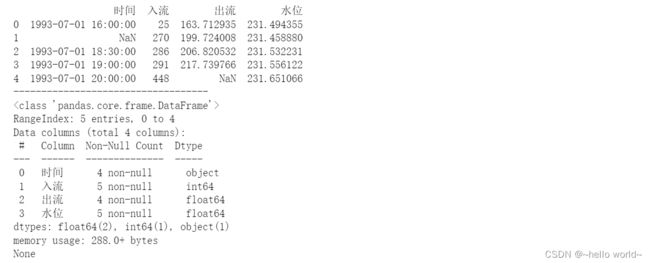
3.4.1 查看缺失值
·使用DataFrame对象的info()方法
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
print(df.info())
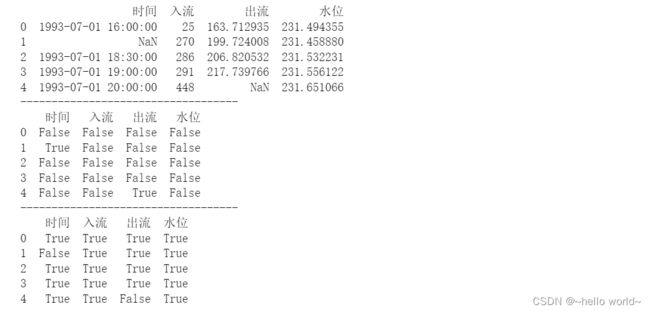
3.4.2 判断数据是否存在缺失值
使用DataFrame的isnull()方法和notnull()方法
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
print(df.isnull())
print('-----------------------------------')
print(df.notnull())
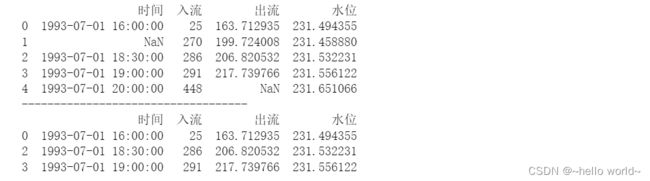
3.4.3缺失值的处理
缺失值的处理方式有不处理、删除、填充或替换、插值(均值、中位数、众数等填补)
#删除缺失值
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
df=df.dropna()
print(df)
#提取指定不为null的数据
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
print('提取出流不为null的数据\n',df[df['出流'].notnull()])

#填充数据
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
df['出流']=df['出流'].fillna(0)
print('用0填充后的数据\n',df)

3.4.4 重复值处理
#删除全部重复的数据
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
print('判断是否存在重复值\n',df.duplicated())
print('-----------------------------------')
df=df.drop_duplicates()
print('删除全部重复的数据\n',df)

#删除指定列重复的数据
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%',header=0)
print(df)
print('-----------------------------------')
print('判断是否存在重复值\n',df.duplicated('水位'))
print('-----------------------------------')
df=df.drop_duplicates(['水位'],keep='last')
print('删除指定列重复的数据,保留重复行的最后一行\n',df)

3.5 异常值的检测与处理
异常值是指超出或低于正常范围的值
异常值的检测方式,根据给定的数据范围进行判断,不在范围内的数据视为异常值,常用检测方式有均方差、箱形图
异常值的处理方式有删除、当成缺失值处理、当成特殊情况进行分析

箱型图各参数数学含义(转自:箱形图(python画箱线图))
4、基于索引的相关操作
Pandas索引的作用有更方便地查询数据、提升查询性能。其中,如果索引是唯一的,Pandas会使用哈希表优化;如果索引不是唯一,但是有序,Pandas会使用二分查找算法;如果索引是完全随机的,那么每次查询都要扫描数据表。
4.1 重新设置索引
语法结构:**df.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)**
labels:新标签/索引,使“ axis”指定的轴与之一致。
index, columns:符合的新标签/索引。最好是一个Index对象,以避免重复数据
axis:轴到目标。可以是轴名称(“索引”,“列”)或数字(0、1)
method:NaN填充方法,{None,“ backfill” /“ bfill”,“ pad” /“ ffill”,“ nearest”},pad/ffill:用前一个非缺失值去填充该缺失值,backfill/bfill:用下一个非缺失值填充该缺失值,None:指定一个值去替换缺失值(缺省默认这种方式)
copy:即使传递的索引相同,也返回一个新对象
level:在一个级别上广播,在传递的MultiIndex级别上匹配索引值
fill_value:在计算之前,使用此值填充现有的缺失(NaN)值以及成功完DataFrame对齐所需的任何新元素。如果两个对应的DataFrame位置中的数据均丢失,则结果将丢失。
limit:向前或向后填充的最大连续元素数
tolerance:不完全匹配的原始标签和新标签之间的最大距离。匹配位置处的索引值最满足方程abs(index [indexer]-target)
#重新设置索引
import pandas as pd
df=pd.Series([55,15,32],index=[1,2,3])
print(df)
#重设置设置索引
print ('重设置设置索引后的数据\n',df.reindex(range(1,6)))
print('NaN值使用33进行填充后的数据\n',df.reindex (range(1,6),fill_value=33))

4.2 设置某列为行索引
指定某列为行索引与重新设置索引区别在于,重新设置索引前提是存在一个索引,只是不满意而已,而指定某列为行索引是没有用默认的索引。
语法结构:df.set_index()
#设置指定列为行索引
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df=df.set_index(['时间'])
print ('设置时间一列为索引\n',df)

4.3 数据清洗后重新设置连续索引
语法结构:df.reset_index()
#数据清洗后重新设置连续索引
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df=df.dropna().reset_index()
print('数据清洗后重新设置连续索引的数据\n',df)

4.4 数据的排序
DataFrame数据排序排序时主要使用sort_values()方法
语法语法:df.sort_values(by,axis=0,ascending=True,inplace=False,kind='quicksort ,na_position='last ,ignore_index=False)
by:要排序的名称列表
axis:轴,0表示行,1表示列,默认行排序
ascending:升序或降序排序,布尔值,指定多个排序可以使用布尔值列表,降序
inplace:布尔值,默认值为False,如果值为True,则就地排序
kind:指定排序算法,值为’quicksort(快速排序)、'mergesort(混合排序)或’heapsort(堆排),默认值为quicksort
na_position:空值(NaN)的位置,值为first空值在数据开头,last空值在最后,默认值为last
ignore_index:布尔值,是否忽略索引,值为True标记索引(从0开始按顺序的整数值),值为False则忽略索引
#排序后的数据
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df=df.sort_values(by='出流')
print('排序后的数据\n',df)

df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df=df.sort_values(by=['入流','出流'])#靠后的优先
print('根据多列排序后的数据\n',df)

4.5 数据的排名
数据的排名是根据Series或DataFrame对象的某几列的值进行排名,主要使用rank方法
语法结构:df.rank(axis=0,method=‘average"’,ascending=True,na_option=‘keep’)
axis:轴,0表示行,1表示列,默认按行排序
method:表示在具有相同值的情况下所使用的排序方法,有average:默认值,平均排序、min:最小值排名、max:最大值排名、first:按值在原始数据中的出现的顺序分配排名、dense:密集排名,类似最小值排名,排名相同的数据只占一个名次
na_option:空值的排序方式,有keep:保留、top:如果升序,将最小排名赋给NaN、bottom:最大升序,将最大排名赋给NaN
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df=df.sort_values(by='出流')
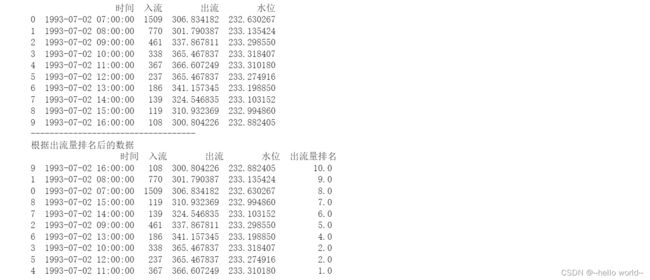
df['出流量排名']=df['出流'].rank(method='min',ascending=False)
print('根据出流量排名后的数据\n',df)
5、数据计算
| 函数 | 说明 |
|---|---|
| 求和:sum([axis,skipna]) | axis=1表示按行加,axis=0表示按列加,默认列加skipna=1表示将NaN转0, skipna=0表示不转 |
| 求均值:mean([axis,skipna]) | |
| 最大值:max([axis,skipna]) | |
| 最小值:min([axis,skipna]) | |
| 中位数:media(axis=None,skipna=None) | axis=1表示行, axis=0表示列,默认为None;skipna布尔值,表示计算结果是否排除了NaN/Null,默认为True |
| 求众数:mode(axis=0,dropna=True) | axis=1表示行, axis=0表示列,默认值为0,dropna是否删除缺失值,布尔型,默认为True |
| 求方差:var(axis=None,skipna=None) | |
| 标准差:std(axis=None,skipna=None) | |
| 分位数:quantile(q=0.5,axis=0, numeric_only=True) | numeric_only的值为False,将计算日期、时间和时增量数据的分位数 |
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df.loc['平均数']=df.loc[1:].mean()
print('平均数\n',df)

6、数据格式化
对数据进行格式化,以增加数据的可读性,常用的方式是设置小数位数用df.round(decimals=0)函数、设置百分比用apply()函数与format()函数、设置千位分隔符用apply()函数与format()函数。
6.1 小数位数设置
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
print('保留三位小数\n',df.round(3))#对所有数据都有作用

#指定列保留小数——用字典
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
print('指定列保留小数\n',df.round({'入流':0,'出流':3,'水位':3}))

#指定列保留小数——用Series
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
S=pd.Series([0,3,3],index=['入流','出流','水位'])
print('指定列保留小数\n',df.round(S))
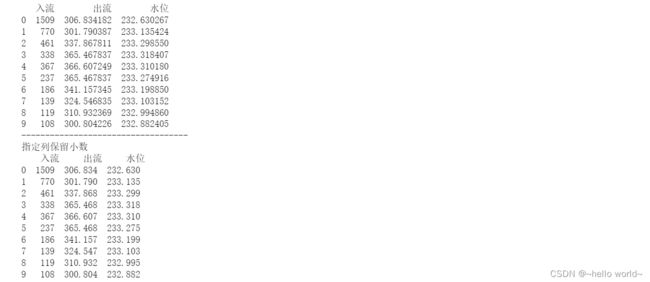
#指定列保留小数——用自定义函数
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df=df.applymap(lambda x:'{:.3f}'.format (x))
print('指定列保留小数\n',df)

6.2 设置百分比
#设置百分比——对列起作用,apply函数
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df['百分比']=df['出流'].apply(lambda x:format(x,'.0%'))
print (df)

#设置百分比——对列起作用,map函数
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df['百分比']=df['出流'].map(lambda x:format(x,'.0%'))
print(df)

6.3 千位分隔符
千位分隔符只是为了方面读数,不能参与运算
df=pd.read_excel(r'C:\Users\Desktop\data.xlsx',sheet_name='1%')
print(df)
print('-----------------------------------')
df['入流']=df['入流'].apply(lambda x:format(int(x),','))
print (df)

6.4 apply()、map()、applymap()的区别
apply()可以在series,对Series的每一个元素都执行一次函数,也可以在DataFrame中起作用,对DataFrame中的某一行或某一列的每个元素执行一次函数
s=pd.Series (data=[ 1,2,3,4],index=['a','b', 'c','d'])
print (s)
print (' --------------------------')
s=s.apply(lambda x:x*10)
print('apply()可以在series,对Series的每一个元素都执行一次函数\n',s)
df=pd.DataFrame(data=[[10,20,30,40],[11, 22,33,44]],index=['a','b'], columns=['A','B','C','D'])
print (' --------------------------')
print(df)
df=df.apply(lambda x:x.sum(),axis=0)
print (' --------------------------')
print('apply对DataFrame中的某一行或某一列的每个元素执行一次函数\n',df)

map只能应用在Series的每个元素上,map的参数是一个函数,还可以是字典
df=pd.DataFrame(data=[['男'],['女'],['男'],['女']], index=['张三','李姐','王五','陈妹'],columns=['性别'])
print(df)
def gender(g) :
if g=='男':
return 0
else:
return 1
df2=df['性别'].map(gender)
print('-----------------')
print('map的参数是一个函数\n',df2)
print('-----------------')
df3=df['性别'].map({'男':0,'女':1})
print('map的参数是字典\n',df3)

applymap()将函数应用到DataFrame中的每一个元素中,与apply()的区别,apply()只能应用到某列或某行
df=pd.DataFrame(data=[[10,20,30,40],[11, 22,33,44]],index=['a','b'], columns=['A','B','C','D'])
print (' --------------------------')
print(df)
df=df.applymap(lambda x:x*10)
print (' --------------------------')
print('applymap()将函数应用到DataFrame中的每一个元素中\n',df)

7、数据统计分组分析
7.1 分组统计groupby函数
分组统计函数groupby的功能是根据给定的条件将数据拆分成组,每个组可以独立应用函数(如sum()),并将结果合并到一个数据结构中。
语法结构:df.groupby(by=None,axis=0,as_index=True,sort=True)
按照单列分组计算
#按照一列分组统计
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
df1=df[['产品名称','数量','标准单价']]
print('对数量,标准单价都进行求和统计\n',df1.groupby('产品名称').sum())

按照多列分组计算
#按照多列分组统计
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
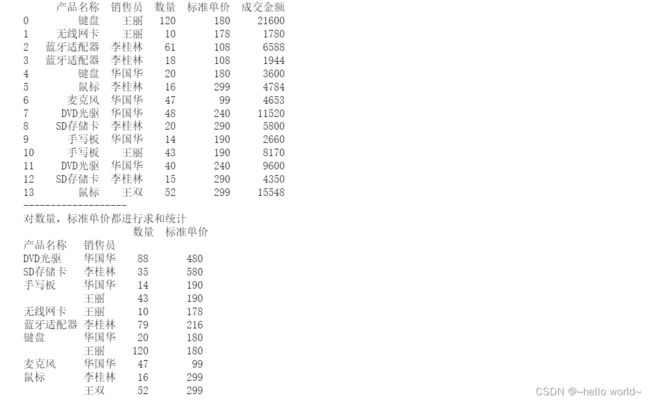
df1=df[['产品名称','销售员','数量','标准单价']]
df1=df1.groupby(['产品名称','销售员']).sum()
print('对数量,标准单价都进行求和统计\n',df1)
按照指定列分组计算
#按照指定列分组计算
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
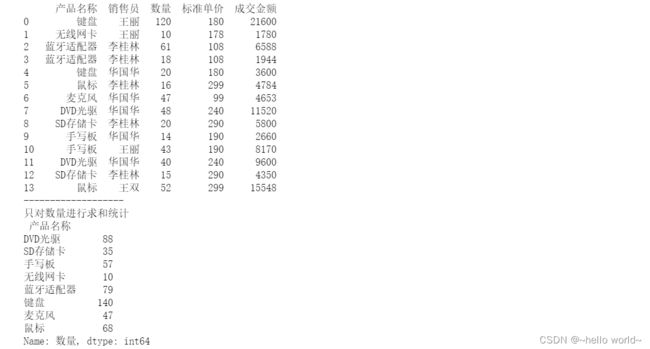
df1=df[['产品名称','数量','标准单价']]
print('只对数量进行求和统计\n',df1.groupby('产品名称')['数量'].sum())
7.2 分组数据的迭代
分组数据的迭代是通过for循环对分组统计数据进行迭代(遍历分组数据)
#分组数据的迭代
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
df1=df[['产品名称','数量','标准单价']]
print('分组之后的数据类型为DataFrameGroupBy\n',df1.groupby('产品名称'))
print('-------------------')
for name,group in df1.groupby('产品名称'):
print(name,group)

#按照多列分组,数据迭代
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
df1=df[['产品名称','销售员','数量']]
print('分组之后的数据类型为DataFrameGroupBy\n',df1)
print('--------------------')
for (name1,name2),group in df1.groupby(['产品名称','销售员']):
print(name1,name2)
print(group)
print('-----------------------')

7.3 聚合函数的使用
通过groupby()与agg()函数联合使用,常用的函数函数, sum(),mean(),max(),min()等
#单列聚合函数
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
df1=df[['产品名称','数量']]
print('使用聚合函数后的数据\n',df1.groupby('产品名称').agg(['sum','mean']))

不同列用不同聚合函数
#不同列使用不同聚合函数
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
df1=df[['产品名称','数量','成交金额']]
print('使用聚合函数后的数据\n',df1.groupby('产品名称').agg({'数量':['sum','mean'],'成交金额':['max','min']}))

7.4 通过自定义函数对数据进行分组统计
#通过自定义函数对数据进行分组统计
pd.set_option('display.unicode.east_asian_width',True)#规则格式
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
print('-------------------')
print (df['产品名称'].value_counts()) #df['产品名称']为Series
maxcount=lambda x:x.value_counts().index[0] #行索引为0,即为最大的数,value_counts()为降序排序
maxcount.__name__='销量最多的产品'
df1=df.agg({'产品名称':[maxcount],'数量':['max']})
print('-------------------')
print(df1)

7.5 通过字典和Series对象进行分组统计
通过字典进行分组统计
#通过字典进行分组统计
pd.set_option('display.unicode.east_asian_width',True) #规则格式
pd.set_option ('display.max_columns',500)
pd.set_option('display.width',1000)
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
df=df.set_index('产品名称')
dic={'南岸':'重庆','江津':'重庆','成都':'四川','泸州':'四川'}
df=df.groupby(dic,axis=1).sum()
print('------------------')
print(df)

通过Series进行分组统计
#通过Series进行分组统计
pd.set_option('display.unicode.east_asian_width',True) #规则格式
pd.set_option ('display.max_columns',500)
pd.set_option('display.width',1000)
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx')
print(df)
df=df.set_index('产品名称')
dic={'南岸':'重庆','江津':'重庆','成都':'四川','泸州':'四川'}
S=pd.Series(dic)
df=df.groupby(S,axis=1).sum()
print('------------------')
print(df)

7.6 数据移位
数据移位,是指数据上移或者下移
语法结构:df.shift(periods=1,freq=None,axis=0)
periods:表示移动的幅度,可以是正数,也可以是负数,默认值是1, 1表示移动一次。
freq:可选参数,默认值为None,只适用于时间序列,如果这个值存在,那么会按照参数值来移动时间索引,而数据值不会发生变化
axis:axis=1表示列,axis=0表示行,默认值为0
data=[532,937,447,765,564]
index=['一月','二月','三月','四月','五月']
df=pd.DataFrame(data=data,index=index, columns=['手机销量'])
print(df)
print('------------------')
df['销量差']=df['手机销量']-df['手机销量'].shift()
print(df)

8.数据的转换
·数据转换的分类
·—列数据转换为多列数据
行列转换
DataFrame转换为字典、列表和元组等等
语法结构:Series.str.split(pat=None,n=-1,expand=False)
pat:字符串、符号或正则表达式,表示字符串分割的数据,默认以空格分割字
n:整型、分割次数,默认值是-1。0或-1都将返回所有拆分的字符串
expand:布尔型,分割后的结果是否转换为DataFrame,默认值是False
pd.set_option('display.unicode.east_asian_width',True) #规则格式
pd.set_option ('display.max_columns',500)
pd.set_option('display.width',1000)
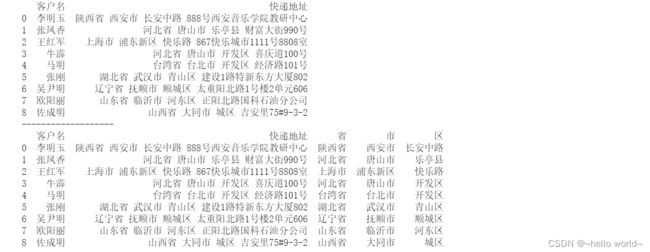
df=pd.read_excel(r'C:\Users\Desktop\数据统计.xlsx',usecols=['客户名','快递地址'])
print(df)
print('-------------------')
df1=df['快递地址'].str.split(' ',expand=True)
df['省']=df1[0]
df['市']=df1[1]
df['区']=df1[2]
print(df)
将元组数据进行分割
data={'a':[1,2,3,4,5],
'b':[(1,2),(2,3),(3,4),(4,5),(5,6)]}
df=pd.DataFrame (data=data)
print(df)
print('----------------')
df[['b1','b2']]=df['b'].apply(pd.Series)
print (df)

data={'a':[1,2,3,4,5],
'b':[(1,2),(2,3),(3,4),(4,5),(5,6)]}
df=pd.DataFrame (data=data)
print(df)
print('----------------')
#join()与apply()
df=df.join(df['b'].apply (pd.Series))
print (df)

本文仅用于学习交流