Python基础知识笔记(文章内容持续更新)
python程序实例解析
- 2.1温度转换
- 2.2Python程序语法元素分析
-
- 2.2.3命名字与保留字
- 2.2.4字符串
- 2.2.5赋值语句
- 2.2.6 input函数 输入函数
- 2.2.7分支语句 if-elif-else
- 2.2.8 eval()函数 去掉最外层引号
- 2.2.9 print() 输出函数
- 2.2.10 循环语句 while
- 2.2.11 函数定义 def temp():
- 2.3 python蟒蛇绘制
-
- 引用函数库方式
- 2.4 turtle库语法元素分析
-
- 2.4.1 绘图坐标体系
- 2.4.2 画笔控制函数
- 2.4.3 形状绘制函数
- 2.4.4 遍历循环for-in
- 3.1数字类型
-
- 3.1.2 整数类型
- 3.1.3 浮点型类型
- 3.1.4 复数类型
- 3.2 数字类型的操作
-
- 3.2.1 内置的数值运算操作符
- 3.2.2 内置的数值运算函数
- 3.2.3 内置的数字类型转换函数
- 3.3 模块1:math库的使用(需import引用该库)
-
- 3.3.2 math库解析
- 3.4 实例天天向上
- 3.5 字符串类型及其操作
-
- 3.5.1字符串类型的表示
- 3.5.2 基本的字符串操作符
- 3.5.3 内置的字符串处理函数
-
- 内置的字符串处理函数 6个
- 恺撒密码
- 3.5.4 内置的字符串处理方法
-
- 常用的16个内置字符串处理方法(全部共43个)
- 3.6 字符串类型的格式化
-
- 3.6.1 format()方法的基本使用
- 3.6.2 format()方法的格式控制
- 3.7 实例4: 文本进度条
-
- 实例:带刷新的文本进度条
-
- 多行文本进度条
- 带时间进度条
- 普通进度条
- tpdm进度条
- 可视化进度条
- 4.1 程序的基本结构
- 4.2 分支结构
-
- 1. 单分支结构 if
- 2.二分支结构 if-else
- 3. 多分支机构 if-elif-else
- 4.4 循环结构
-
- 1.遍历循环 for
- 2.无限循环 while
- 3.循环保留字 break 和 continue
- 4. for和while的扩展模式
- 4.5 random库的使用 生成为随机数
-
- 蒙特卡罗方法求解π值
- 4.7 异常处理
- 5.1 函数的基本使用
-
- 1.函数的定义
- 2 函数的参数传递
- 3 datatime库的使用 ----标准时间库
-
- 1.datatime 的概述
- 2.datatime的解析
- 4 七段数码管绘制
- 5 代码复用和模块化设计
- 6.函数递归
- 8 python内置函数68个
-
- 1.数学运算:
- 2.类型转换:
- 3.序列操作:
- 4.对象操作:
- 5.反射操作:
- 6.变量操作:
- 7.交互操作:
- 8.文件操作:
- 9.编译执行:
- 10.装饰器:
- 常用函数解析
- 6.1 组合数据类型概述
-
- 6.1.1 序列类型
- 6.1.2 集合序列
- 6.1.3映射类型
- 6.2.1 元组概述
- 6.2.2 列表概述
- 6.2.3 字典概述
2.1温度转换
TempStr = input("请输入带有符号的温度值: ")
if TempStr[-1] in ['F','f']:
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']:
F = 1.8*eval(TempStr[0:-1]) + 32
print("转换后的温度是{:.2f}F".format(F))
else:
print("输入格式错误")
2.2Python程序语法元素分析
2.2.3命名字与保留字
Python 语言允许采用大写字母、小写字母、数字、
组合给变量命名,但名字的首字符不能是数字,中间不空格,长度无限制。
注意:标识符,保留字对大小写敏感:python3中可以采用中文等非英语语言字符对变量命名
33个保留字列表

2.2.4字符串
字符串包括:正向递增系列和反向递减系列
- 正向递增系列以最左侧字符序号为0 向右依次递增,最右侧序号为 L-1
- 反向递减系列以最右侧字符序号为 -L 向左依次递减,最左侧序号为 -L
- 字符串区间访问方式,[N:M]格式,表示字符串中从N到M (不包含M) 的子字符串
例:s[-1]表示字符串s最后一个字符串;s[0:-1]表示从0到最后一个字符串 (不包含最后一个字符)
2.2.5赋值语句
- = 表示赋值,右值赋值左变量
- 同步复制语句
<变量1>,…,<变量N> = <表达式1>,…,<表达式N>
首先运行表达式N,并赋值给变量N
好处: 互换变量 不需要中间值,如:x,y=y,x
2.2.6 input函数 输入函数
input(<提示性文字>)函数从控制台获得用户输入,并输出带提示性文字
无论用户输出字符还是数字,input()统一以字符串型输出
2.2.7分支语句 if-elif-else
类型: if-elif-else
例:
if s[-1] in ['F','f''] :
<语句块1>
elif <条件2>:
<语句块2>
else:
<语句块3>
列表: [元素1, ... ,元素n]
2.2.8 eval()函数 去掉最外层引号
例如:
>>>s="102C"
>>>eval(s[0:-1])
102
输入"‘hello’"时,eval()去掉最外层引号后.结果为字符串’hello’
输入数字运算时,可搭配input()使用
>>>s=eval(input("请输入一个数字: "))
请输入一个数字: 10024.256
>>>print(s*2)
2048.512
2.2.9 print() 输出函数
纯信息输出时 print(<带输出字符串>)
格式化输出时 print()函数用槽格式,通过format()函数将输出变量格式化输出
>>>c=10
>>>print("转换后温度为{:.2f}C".format(c))
转换后温度为10.00C
2.2.10 循环语句 while
TempStr = input("请输入带有符号的温度值: ")
while TempStr[-1] not in ['N','n']:
if TempStr[-1] in ['F','f']:
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']:
F = 1.8*eval(TempStr[0:-1]) + 32
print("转换后的温度是{:.2f}F".format(F))
else:
print("输入格式错误")
TempStr = input("请输入带有符号的温度值: ")
2.2.11 函数定义 def temp():
定义一个 temp(ch)函数
def temp(ch):
c=ch+2
retun c
主函数写法 if __name__ == '__main__':
2.3 python蟒蛇绘制
import turtle
turtle.setup(650, 350, 200, 200)
turtle.penup()
turtle.fd(-250)
turtle.pendown()
turtle.pensize(25)
turtle.pencolor("purple")
turtle.seth(-40)
for i in range(4):
turtle.circle(40, 80)
turtle.circle(-40, 80)
turtle.circle(40, 80/2)
turtle.fd(40)
turtle.circle(16, 180)
turtle.fd(40 * 2/3)
引用函数库方式
- import <库名>
- form <库名> import <函数名>
form <库名> import * (其中* 是通配符,表示所有函数) - import <库名> as <自定义名>
例如:
import turtle as t
使用函数式则可以 t.fd()格式引用
2.4 turtle库语法元素分析
2.4.1 绘图坐标体系
- 初始时,小海龟位于 画布正中央,此处坐标(0,0),行进方向为 水平右方
- turtle绘图体系 绝对方位的0度为 画布正右方
- turtle坐标系的 原点默认在屏幕左上角
- 画布设置
turtle.setup(width,height,startx,starty)
作用:设置主窗体的大小位置
参数:
width:窗口宽度 ,若值是整数,表示像素值;若值是小数,表示窗口宽度与屏幕的比例。
height:窗口高度,若值是整数,表示像素值;若值是小数,表示窗口高度与屏幕的比例。
startx:窗口左侧与屏幕左侧的像素距离,如果值是None,窗口位于屏幕水平中央。
starty:窗口顶部与屏幕顶部的像素距离,如果值是None,窗口位于屏幕垂直中央。
2.4.2 画笔控制函数
-
turtle.penup()
别名: turtle.pu() , turtle up()
作用:抬起画笔,之后移动不绘制形状 -
turtle.pendown()
别名:turtle.pd() ,turtle.down()
作用:落下画笔,运动会绘制形状(与turtle.penup()一组) -
turtle.pensize(width)
别名: turtle.width()
作用:设置画笔尺寸
参数:width画笔的宽度,如果为None或空,则返回当前画笔宽度 -
turtle.pencoclor(colorstring)或turtle.pencolor((r,g,b))
作用:设置画笔颜色,无参数时返回当前画笔颜色
参数:colorstring 表示颜色字符串,如"purple",“red”,“blue”
(r,g,b)颜色对应的RGB数值,如(51,204,140)


2.4.3 形状绘制函数
-
turtle.forward(d)
别名:turtle.fd(d)
作用:向当前行进方向前进 d距离
参数:d行进距离的像素值,当值为负数时,向相反方向前进 -
turtle.bk(d)
作用:向海龟 负方向移动 d距离 (海龟方向不改变) -
turtle.setheading(angle)
别名:turtle.seth(angle)
作用:设置海龟当前前进方向angle,该角度为绝对方向角度
参数:angle行进方向的绝对角度的整数值 -
turtle.left(angle)
作用:海龟向左转
参数:angle在海龟当前行进方向上旋转的角度 -
. turtle.right(angle)
作用:海龟向右转
参数:angle在海龟当前行进方向上旋转的角度 -
turtle.circle(r,extent=None)
作用:根据半径r绘制extent角度的弧形
参数:r半径,当值为正数时,半径在海龟左侧:但值为负数时,半径在海龟右侧.
extent,绘制弧形的角度,但不设参数或设置为None时,绘制整个圆 -
turtle.done()
作用:绘图完后手动退出,若不加,则程序完成就自动退出(一般都在绘图程序后加此函数) -
turtle.speed()
设置画笔速度(0-10),速度越大越快,大于10小于0.5时默认为0,0是最快的速度 -
turtle.undo()
撤销上一次命令 -
.hideturtle()
隐藏海龟 -
turtle.showturtle()
显示海龟
2.4.4 遍历循环for-in
格式:
for i in range(<循环次数>):
<语句块>
range(n) 产生0至n-1的整数系列,共循环n次
range(n,m)产生n至m-1的整数系列,共循环m-n次
3.1数字类型
3.1.2 整数类型
整数类型包括:十进制、二进制、八进制、十六进制
- 十进制:默认采用
- 二进制:以 0b或0B 引导,由0和1组成,例如0b101
- 八进制:以 0o或0O 引导,由0到7组成例如0o711
- 十六进制:以 0x或0X 引导,由0到9,a到f,A到F组成.例如0xABC
pow(x,y),计算x^y (x的y次方)
3.1.3 浮点型类型
表示方法:十进制和科学计数法
科学计数法:以字母e或E 作为幂的符号,以10为基数,e=a*10^b
例如:4.3e-3=0.0043
3.1.4 复数类型
复数的虚部以后缀 “j"或"J” 表示
其实部与虚部的数值都是浮点数
z.real 获取z的实部
z.imag或缺z的虚部
3.2 数字类型的操作
3.2.1 内置的数值运算操作符

3种数字类型的扩展关系: 整数->浮点数->复数
不同数字类型间运算所生成结果是"更宽"的类型
例如:整数浮点数与分数运算,结果为分数
3.2.2 内置的数值运算函数
| 函数 | 描述 |
|---|---|
| abs(x) | x的绝对值,例如`>>>abs(-3+4j) 结果为5.0 |
| divmod(x,y) | (x//y,x%y) ,输出为二元组形式(元组类型) |
| pow(x,y[z]) | (xy)%z,[…]表示该参数可以省略,即pow(x,y),等价于xy |
| round(x[,d]) | 对x四舍五入,保留d位小数,round(x)返回四舍五入的整数 |
| max(x1,x2,…,xn) | x1,x2,…xn的最大值,n无限定 |
| min(x1,x2,…,xn) | x1,x2,…xn的最小值,n无限定 |
3.2.3 内置的数字类型转换函数
| 函数 | 描述 |
|---|---|
| int(x) | 将x转换为整数,x可以为浮点数(直接舍弃小数部分,不四舍五入)或字符串 |
| float(x) | 返回浮点数x或字符串x对应的整数类型 |
| complex(re[,im] | 生成一个复数,re为实部,可以是整数.浮点数或字符串:im为虚部,可以是整数浮点数不能为字符串 |
复数不能直接转换为其他数字类型,可以通过.real和.imag提取实部和虚部,然后分别转换
例如:
>>>float((10+99j).imag)
99.0
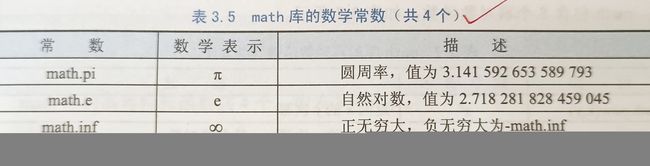
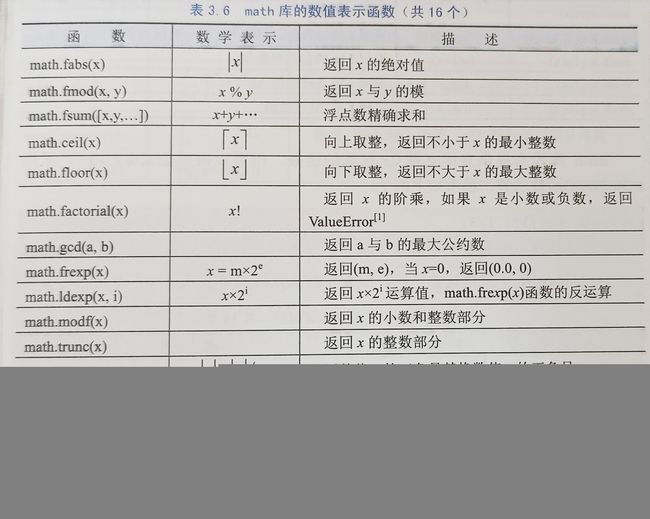
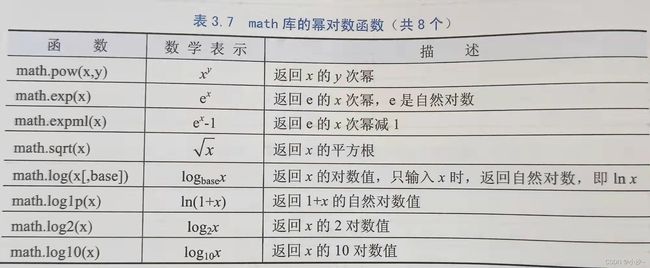
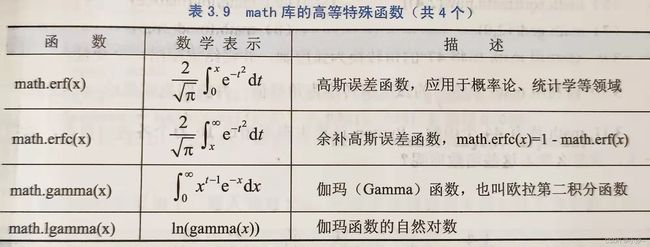
3.3 模块1:math库的使用(需import引用该库)
3.3.2 math库解析

3.4 实例天天向上
【实例代码3.3】天天向上。
一年365天,如果好好学习时能力值相比前一天提高1%,当放任时相比前一中国人 天下降1%。效果相差多少呢?
此时,天天向上的力量是(1+0.01)365,相反的力量是(1-0.01)365。从0.001、0.005到0.01,这个每天努力的因素根据需求的不同而不断变化,因此,新代码中采用dayfactor变量表示这个值。这种改变的好处是每次只需要修改这个变量值即可,而不需要修改后续与该变量相关位置的代码。代码如下:
import math
dayfactor = 0.01
dayup = math.pow((1.0 + dayfactor), 365) # 提高dayfactor
daydown = math.pow((1.0 - dayfactor), 365) # 放任dayfactor
print("向上: {:.2f}, 向下: {:.2f}.".format(dayup, daydown))
【实例代码3.5】天天向上。
每周工作5天,休息2天,休息日水平下降0.01,工作日要努力到什么程度,一年后的水平才与每天努力1%取得的效果一样呢?
代码如下:
#e3.5DayDayUp365.py
def dayUP(df):
dayup = 1.0
for i in range(365):
if i % 7 in [6, 0]:
dayup = dayup * (1 - 0.01)
else:
dayup = dayup * (1 + df)
return dayup
dayfactor = 0.01
while (dayUP(dayfactor)<37.78):
dayfactor += 0.001
print("每天的努力参数是: %.3f."%dayfactor)
3.5 字符串类型及其操作
3.5.1字符串类型的表示
- 单引号字符串:'单引号表示,可以使用双引号"作为字符串一部分
- 双引号字符串:"双引号表示,可以使用单引号’作为字符串一部分
- 三引号字符串:‘’‘三引号表示,可以使用’单引号’
“双引号”
也可以换行
‘’’
3.5.2 基本的字符串操作符
- 5个字符串的基本操作符
| 操作符 | 描述 |
|---|---|
| x+y | 连接两个字符串x和y |
| x*n或n*x | 复制n次字符串x |
| x in s | 如果x是s的子串,返回True,否则返回False |
| str[i[ | 索引,返回第i个字符串 |
| str[N:M] | 切片,返回索引第N到第M-1的子串 |
- 格式化控制字符 (\ 转义符)
| 字符 | 含义 |
|---|---|
| \n | 换行 |
| \\ | 表示反斜杠\ |
| \’ | 表示单引号’ |
| \" | 表示双引号" |
| \t | 水平制表(Tab) |
| \a | 蜂鸣,响铃 |
| \b | 回退,向后退一格 (py文件下) |
| \f | 换页 |
| \n | 换行,光标移动到下行首行 |
| \r | 回车,光标移动到本行首行(py文件下) |
| \v | 垂直制表 |
| \0 | NULL,什么都不做 |
3.5.3 内置的字符串处理函数
python3以Unicode字符为计数基础,字符串中英文字符和中文字符都是一个长度单位
内置的字符串处理函数 6个
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串x的长度,也可以返回其他组合数据类型元素个数 |
| str(x) | 返回任意类型x对应的字符串形式 |
| chr(x) | 返回Unicode编码x对应的单字符 |
| ord(x) | 返回单字符对应的Unicode编码 |
| hex(x) | 返回整数x对应十六进制数的小写形式字符串 |
| oct(x) | 返回整数x对应八进制数的小写形式字符串 |
恺撒密码
信息中每一个英文字符循环替换为字母表顺序中该字符后面第三个字符
plaincode = input("请输入明文: ")
for p in plaincode:
if ord("a") <= ord(p) <= ord("z"):
print(chr(ord("a") + (ord(p) - ord("a") + 3)%26),end='')
else:
print(p, end='')
3.5.4 内置的字符串处理方法
常用的16个内置字符串处理方法(全部共43个)
str为字符串或变量
| 方法 | 描述 |
|---|---|
| str.lower() | 返回字符串str的副本,全部字符小写 |
| str.upperr() | 返回字符串str的副本,全部字符大写 |
| str.islower() | 当str所有字符都是小写时,返回True,否则返回False |
| str.isprintable() | 当str所有字符都是可打印的,返回True,否则返回False |
| str.isnumeric() | 当str所有字符都是数字时,返回True,否则返回False |
| str.isspace() | 当str所有字符为空格时,返回True,否则返回False |
| str.endswith(suffix[,start[,end]]) | str[start:end]以suffix结尾返回True,否则返回False |
| str.srartswith(prefix[,start[,end]]) | str[start:end]以prefix开始返回True,否则返回False |
| str.split(sep=None,maxsplit=-1) | 返回一个列表,由str根据sep被分隔的部分构成,默认分隔符为空格,maxsplit为最大分隔次数,默认maxsplit参数可以不给出 |
| str.count(sub[,start[,end]]) | 返回str[start:end]中sub子串出现的次数 |
| str.replace(old,new[,count]) | 返回字符串str的副本,所有old子串被替换为new,如果count给出,则前count次old出现被替换 |
| str.center(width[,fillchar]) | 字符串居中函数,返回长度为width的字符串,其中str处于新字符串中心位置,两侧增加字符采用fillchar填充,当witdh小于字符串长度时,返回str |
| str.strip([chars) | 返回字符串str的副本,在其左右侧去掉chars中列出的字符 |
| str.zfill(width) | 返回长度为width的字符串,如果字符串长度不足width,在左侧添加字符“0”,但如果str最左侧是字符”+”或者”-”,则从第二个字符左侧添加”0”,当width小于字符串长度时,返回str。该方法主要用于格式化数字形字符串中 |
| str.format() | 返回字符串str的一种排版格式 |
| str.join(x) | 返回一个新字符串,由组合数据类型x变量的每一个元素组成,元素间用str分隔 |
3.6 字符串类型的格式化
3.6.1 format()方法的基本使用
格式:<模板字符串>.format(<逗号分隔的参数>)
format()中逗号分隔的参数按照 序号关系替换到模板字符串的槽中,槽用{}表示,如果槽中没有序号,则按照顺序替换
如果`需要输出大括号,采用{{{表示,}}表示}
>>>"圆周率{{{1}{2}}}是{0}",format("无理数",3.14,"...")
'圆周率{3.14...}是无理数'
3.6.2 format()方法的格式控制
格式如下表:

- format()参数长度比<宽度>设定值大,则使用参数时间长度:如小于设定值,则默认以空格字符补充
- <填充>指宽度内除参数外用什么表示,默认空格
- <类型> 对于整数,输出格式包括一下6种
(1) b: 输出整数的二进制形式
(2) c: 输出整数对应的Unicode字符
(3) d: 输出整数的十进制形式
(4) o: 输出整数的八进制形式
(5) x: 输出整数的小写十六进制方式
(6) X: 输出整数的大写十六进制方式
对于浮点数类型:
(1) e: 输出浮点数对应的小写字母e的指数形式
(2) E: 输出浮点数对应的大写字母E的指数形式
(3) f: 输出浮点数的标准浮点形式
(4) %: 输出浮点数的百分形式
注:输出浮点数尽量 <.精度> 表示小数部分的宽度,更好控制输出格式
3.7 实例4: 文本进度条
- import调用python标准时间库time,使用 time.sleep(t)将当前程序暂时挂起ts t可以是小数
- 注意 默认情况下print()输出结尾自动产生一个’\n’ 换行符
在print()中更换参数end的默认值为’’ ,即每次输出完不换行 - 采用 time.clock()函数 增加运行时间的监控,该函数一般多次出现,第一次调用时计时开始,第二次及后续调用时 返回与第一次的时间差,单位为秒
实例:带刷新的文本进度条
多行文本进度条
import time
scale = 20
print()
print("------执行开始------")
for i in range(scale+1):
a, b = '**' * i,'..' * (scale - i)
c = (i/scale)*100
print("%{:^3.0f}[{}->{}]" .format (c, a, b))
time.sleep(0.1)
print("------执行结束------")
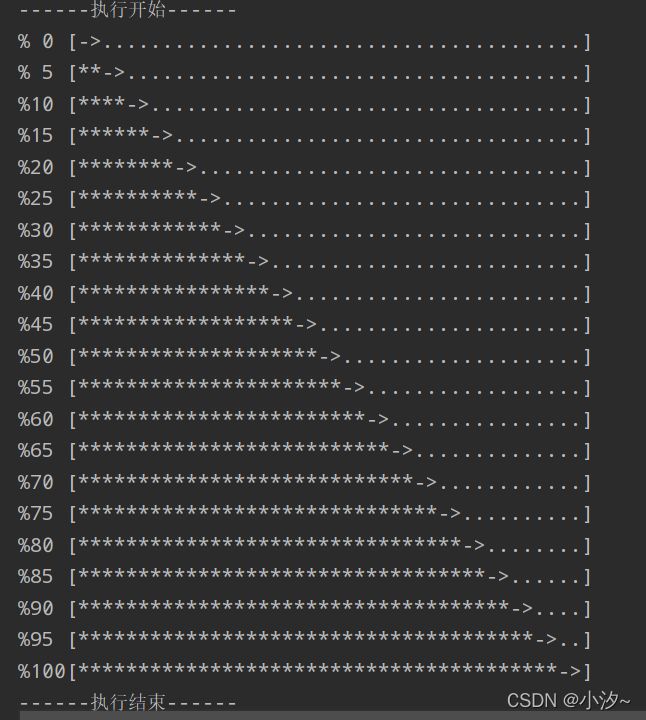
带时间进度条
import time
scale = 50
print("执行开始".center(scale // 2,"-"))
start = time.perf_counter()
for i in range(scale + 1):
a = "*" * i
b = "." * (scale - i)
c = (i / scale) * 100
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end = "")
time.sleep(0.1)
print("\n"+"执行结束".center(scale // 2,"-"))

普通进度条
import time
def pace():
for i in range(1, 101):
print("\r", end="")
print("下载进度: {}%: ".format(i), "▋" * (i // 2), end="")
time.sleep(0.1)
pace()

tpdm进度条
from time import sleep
from tqdm import tqdm
# tqdm 进度条库
for i in tqdm(range(1,1001)):
# 模拟你的任务
sleep(0.01)

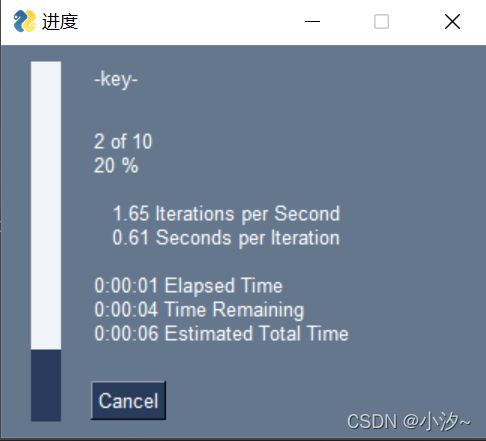
可视化进度条
import PySimpleGUI as sg
import time
mylist = [1,2,3,4,5,6,7,8,9,10]
for i, item in enumerate(mylist):
sg.one_line_progress_meter('进度', i+1, len(mylist), '-key-')
time.sleep(1)
4.1 程序的基本结构
程序基本结构组成: 顺序结构,分支结构和循环结构
4.2 分支结构
python的关系操作符
| 操作符 | 含义 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| >= | 大于或等于 |
| > | 大于 |
| == | 等于 |
| != | 不等于 |
注意:
1.使用’=‘表示赋值语句,使用’==’ 表示等于
2. 字符串比较依次按照字典顺序进行,英文大写字符对于unicode编码比小写字符小
>>>"Python" > "python"
False
1. 单分支结构 if
格式:
if <条件>:
<语句>
2.二分支结构 if-else
格式1:
if <条件>:
<语句1>
else:
<语句2>
格式2:紧凑结构
<表达式1> if <条件> else <表达式2>
#表达式1,2 一般是数字类型或字符串类型中的一个值
3. 多分支机构 if-elif-else
if <条件1>:
<语句1>
elif <条件2>:
<语句2>
else:
<语句3>
#elif 可以多个
4.4 循环结构
1.遍历循环 for
格式:
for <循环变量> in <遍历结构>:
<语句>
遍历结构可以是 字符串,文件,组合数字类型或range()函数 等
# 循环n次
for i in range(n):
# 遍历文件fi的每一行
for line in fi :
# 遍历字符串s
for c in s:
# 遍历列表ls
for ltem inls:
2.无限循环 while
while <条件>:
<语句>
#其中 条件与if 中判断条件一样,结果为 True或False
3.循环保留字 break 和 continue
break : 跳出最内层for或while循环
continue : 结束当前当次循环,继续循环条件中的未执行语句
4. for和while的扩展模式
for <循环变量> in <遍历结构>:
<语句>
else:
<语句2>
while <条件>:
<语句>
else :
<语句2>
for循环和while循环中都存在一个else扩展用法。else中的语句块只在一种条
件下执行,即循环正常遍历了所有内容或由于条件不成立而结束循环,没有因为
break 或returm(函数返回中使用的保留字)而退出。
continue保留字对else 没有影响
4.5 random库的使用 生成为随机数
| 函数 | 描述 |
|---|---|
| seed(a=None | 初始化随机数种子,默认值为当前系统数据 |
| random() | 生成一个[0.0,1.0]之间的随机小数 |
| randint(a,b) | 生成[a,b]之间的整数 |
| getrandbits(k) | 生成一个k比特长度的随机整数 |
| randdrange(start,stop[,step] | 生成一个[start,stop]之间以step为步数的随机整数 |
| uniform(a,b) | 生成[a,b]之间的随机小数 |
| choice(seq) | 以序列类型,例如列表中随机返回一个元素 |
| shuffle(seq) | 将序列列表中的元素随机排列,返回打乱后的序列 |
| sample(pop,k) | 从pop类型中随机选取k个元素,以列表类型返回 |
蒙特卡罗方法求解π值
from random import random
from math import sqrt
from time import clock
DARTS = 1000
hits = 0.0
clock()
for i in range(1, DARTS+1):
x, y = random(), random()
dist = sqrt(x ** 2 + y ** 2)
if dist <= 1.0:
hits = hits + 1
pi = 4 * (hits/DARTS)
print("Pi值是{}.".format(pi))
print("运行时间是: {:5.5}s".format(clock()))
4.7 异常处理
- 异常处理 try-except语句
格式1:
try :
<语句1>
except:
<语句2>
语句1的正常执行的程序内容,当发生异常时执行except后面的语句
格式2: 异常高级用法 支持多个except
try :
<语句1>
except <异常类型1>:
<语句2>
except <异常类型N>:
<语句N+1>
except :
<语句N+2>
异常语句还能与else和 finally 保留字 配合使用
try :
<语句1>
except:
<语句2>
else :
<语句3>
finally :
<语句4>
else: 当try的语句1正常执行结束且没有发生异常时,else中语句3运行
finally: 无论try语句1是否异常,语句4都执行
5.1 函数的基本使用
1.函数的定义
- 创建函数
在 Python 中,使用 def 关键字定义函数:
def happy():
print("happy")
- 调用函数
如需调用函数,请使用函数名称后跟括号:
def happy():
print("happy")
happy()
- lambda函数 -匿名函数
函数可接受任意数量的参数,但只能有一个表达式。
格式: <函数名> = lambda <参数列表 > : <表达式>
x = lambda a, b : a * b
print(x(5, 6))
>30
type(x)
>
2 函数的参数传递
- 可选参数必须定义在非可选参数的后面,可选参数带有默认值
- 可以设计可变数量的参数,通过在参数前加 ==*==实现,带星的可变参数只能放在参数列表最好,调用时这些参数被当成 元组 类型传递
- 传参 :
位置传参:调用时按照位置输入参数
名称传参:按照形参名称输入实参,顺序可以任意调整
>>> func(x1,x2,x3,x4)
#位置传参
>>>result = func(1,2,3,4)
#名称传参:
>>> result = func( x1=1,x3=3,x2=2,x4=4)
- 函数返回值 return
可返回0个,1个或者多个结果
返回多个结果时,以 元组类型 保存
函数可以没有return,此时不返回值 - pass 语句
函数定义不能为空,但是如果您出于某种原因写了无内容的函数定义,请使用 pass 语句来避免错误。 - == 变量的作用域==
全局变量: 定义在函数外,不缩进
局部变量: 函数内部定义使用, 只在函数内部有效,函数结束后,局部变量被释放
1.局部变量可以与全局变量重名,但函数内局部变量不改变全局变量的值
total = 0 # 这是一个全局变量
def sum( arg1, arg2 ):
total = arg1 + arg2 # total在这里是局部变量.
print ("函数内是局部变量 : ", total)
# 这里输出的是30
return total
sum( 10, 20 )
print ("函数外是全局变量 : ", total)
# 输出全局变量 0
- 简单数据类型变量用 global 声明后,作为全局变量使用,函数退出后 变量保留且值被函数改变
def myfunc():
global x
x = 100
myfunc()
print(x)
>100
3.组合数据类型的全局变量 (列表字典),如果在函数内部没有被真实创建的同名变量,则函数内部可以中间使用并修改全局变量的值, 如果函数内部存在同名真实创建的列表,则函数使用该列表不会改变全局变量
ls = []
def f( a ,b ):
li.append(b) #将局部变量b增加到全局变量ls中
return a*b
s = f ( "kno~",2)
print( s ,ls)
#输出 kno~kno~ [2]
ls = [ ]#全局变量ls
def f( a ,b ):
ls = [] #同名的局部变量 ls
li.append(b) #将局部变量b增加到局部变量ls中
return a*b
s = f ( "kno~",2)
print( s ,ls)
# 输出 kno~kno~ []
3 datatime库的使用 ----标准时间库
1.datatime 的概述
| 类 | 表示含义 |
|---|---|
| datatime.date | 表示日期的类,可以表示 年 月 日 |
| datatime.time | 表示时间的类,可以表示 小时 分钟 秒 毫秒 |
| datatime.datetime | 表示时间日期的类,覆盖上面两种 |
| datatime.timedelta | 表示两个datetime对象的差值; |
| datatime.tzinfo | 表示时区的相关信息 |
2.datatime的解析
创建datatime对象的三种方法datetime.now(),datetime.utcnow(),datetime.datetime().
1.datatime.now() 获取当前的日期和时间对象,返回datatime.datatime类型,
2.datatime.utchow ()获取当前日期和时间对应的UTC时间,返回datatime类型
3.datatime()构造一个日期时间对象
方法 datatime(year,moth,day,hour=0,minute=0,second=0,microsecond=0)
>>> from datetime import datetime
>>> today= datetime.now() #返回一个datetime类型,表示当前日期和时间,精确到微秒。
>>> today
datetime.datetime(2020, 9, 19, 9, 46, 35, 391262)
>>> today= datetime.utcnow() #返回一个datetime类型,表示当前日期和时间的UTC(世界标准时间)表示,精确到微秒。
>>> today
datetime.datetime(2020, 9, 19, 1, 48, 53, 506101)
>>> today = datatime(2020, 9, 19, 1, 48, 53, 506101)
datetime.datetime(2020, 9, 19, 1, 48, 53, 506101)
datatime类常用的属性,创建today为datetime对象:
| 属性 | 描述 |
|---|---|
| today.min | 固定返回datetime的最小时间对象,datetime(1,1,1,0,0) |
| today.max | 固定返回datetime的最大时间对象,datetime(9999.12,31,23l,59,59,999999) |
| today.year | 返回today包含的年份 |
| today.month | 返回today包含的月份 |
| today.day | 返回today包含的日期 |
| today.hour | 返回today包含的小时 |
| today.minute | 返回today包含的分钟 |
| today.second | 返回today包含的分秒 |
| today.microsecond | 返回today包含的微秒值 |
datatime 对象常用的时间格式化方法:
| 属性 | 描述 |
|---|---|
| today.isoformat() | 采用ISO标准显示时间。 |
| today.isoweekday() | 根据日期计算星期后返回1—-7对应星期一到星期日。 |
| today.strtime(format) | 根据格式化字符串format进行格式显示的方法 |
| 使用方法如下 |
today= datetime(2020,9,19,10,0,35,397865)
today.isoformat() #运行结果:'2020-09-19T10:00:35.397865'
today.isoweekday() #运行结果:6
today.strftime("%Y-%m-%d %H:%M:%S")#运行结果'2020-09-19 10:00:35'
strtime()格式化字符串的数字左侧会自动补零
strftime()方法的格式化控制符表:
| 格式化字符串 | 日期/时间 |
|---|---|
| %Y | 年份 (0001-9999 ) |
| %m | 月份( 01-12) |
| %B | 月名 (January-December) |
| %b | 月名缩写 (Jan-Dec) |
| %d | 日期 (01-31) |
| %A | 星期(Monday-Sunday) |
| %a | 星期缩写(Mon-Sun) |
| %H | 小时(24小时制)(00-23) |
| %M | 分钟(00-59) |
| %S | 秒(00-59) |
| %x | 日期(年/月/日) |
| %X | 时间(时: 分 :秒) |
4 七段数码管绘制
import turtle, datetime
def drawGap(): #绘制数码管间隔
turtle.penup()
turtle.fd(5)
def drawLine(draw): #绘制单段数码管
drawGap()
turtle.pendown() if draw else turtle.penup()
turtle.fd(40)
drawGap()
turtle.right(90)
def drawDigit(d): #根据数字绘制七段数码管
drawLine(True) if d in [2,3,4,5,6,8,9] else drawLine(False)
drawLine(True) if d in [0,1,3,4,5,6,7,8,9] else drawLine(False)
drawLine(True) if d in [0,2,3,5,6,8,9] else drawLine(False)
drawLine(True) if d in [0,2,6,8] else drawLine(False)
turtle.left(90)
drawLine(True) if d in [0,4,5,6,8,9] else drawLine(False)
drawLine(True) if d in [0,2,3,5,6,7,8,9] else drawLine(False)
drawLine(True) if d in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180)
turtle.penup()
turtle.fd(20)
def drawDate(date):
turtle.pencolor("red")
for i in date:
if i == '-':
turtle.write('年',font=("Arial", 18, "normal"))
turtle.pencolor("green")
turtle.fd(40)
elif i == '=':
turtle.write('月',font=("Arial", 18, "normal"))
turtle.pencolor("blue")
turtle.fd(40)
elif i == '+':
turtle.write('日',font=("Arial", 18, "normal"))
else:
drawDigit(eval(i))
def main():
turtle.setup(800, 350, 200, 200)
turtle.penup()
turtle.fd(-350)
turtle.pensize(5)
drawDate(datetime.datetime.now().strftime('%Y-%m=%d+'))
turtle.hideturtle()
main()
5 代码复用和模块化设计
基本要求:
1.紧耦合: 功能块内部耦合紧密
2.松耦合: 功能块之间耦合度底
6.函数递归
使用递归一定要有基例的构建,可以多个基例,基例决定递归的深度
默认情况调用1000层,python解释器终止程序,
若需要超过1000层,可用下面代码设定
import sys
sys.setrecursionlimit(2000) #2000是新的递归层数
- 字符串反转
def reverse(s):
if s == "":
return s
else:
return reverse(s[1:]) + s[0]
str = input("请输入一个字符串: ")
print(reverse(str))
- 阶乘
def factorial(num):
if num == 0:
return 1
else:
return num * factorial(num-1)
n = eval(input("请输入一个整数: "))
print(factorial(abs(int(n))))
- 科赫雪花
import turtle
def koch(size, n):
if n == 0:
turtle.fd(size)
else:
for angle in [0, 60, -120, 60]:
turtle.left(angle)
koch(size/3, n-1)
def main():
turtle.setup(600,600)
turtle.speed(0)
turtle.penup()
turtle.goto(-200, 100)
turtle.pendown()
turtle.pensize(2)
level = 5
koch(400,level)
turtle.right(120)
koch(400,level)
turtle.right(120)
koch(400,level)
turtle.hideturtle()
main()
8 python内置函数68个
1.数学运算:
| 函数 | 描述 |
|---|---|
| abs() | 求数值的绝对值 |
| divmod() | 返回两个数值的商和余数 |
| max() | 返回可迭代对象哄的元素中的最大值或者所有参数的最大值 |
| min() | 返回可迭代对象哄的元素中的最大值或者所有参数的最小值 |
| pow() | 返回两个数值的幂运算或者其与指定整数的模值 |
| round() | 对浮点数进行四舍五入值 |
| sum() | 对元素类型是数值的可迭代对象中的每个元素求和 |
2.类型转换:
| 函数 | 描述 |
|---|---|
| bool() | 根据传入的参数的逻辑值创建一个新的布尔值 |
| int() | 根据传入的参数创建一个新的整数 |
| float() | 根据传入的参数创建一个新的浮点数 |
| complex() | 根据传入的参数创建一个新的复数 |
| str() | 返回一个对象的字符串表现形式 |
| bytearray() | 根据传入的参数创建一个新的字节数组 |
| bytes() | 根据传入的参数创建一个新的不可变字节数组 |
| memoryview() | 根据传入的参数创建一个新的内存查看对象 |
| ord() | 返回Unicode字符对应的整数 |
| chr() | 返回整数所对应的Unicode字符 |
| bin() | 将整数转化为2进制字符串 |
| oct() | 将整数转化为8进制字符串 |
| hex() | 将整数转化为16进制字符串 |
| tuple() | 根据传入的参数创建一个新的元组 |
| list() | 根据传入的参数创建一个新的列表 |
| dictionary() | 根据传入的参数创建一个新的字典 |
| set() | 根据传入的参数创建一个新的集合 |
| frozenset() | 根据传入的参数创建一个不可变集合 |
| enumerate() | 根据可迭代对象创建枚举对象 |
| range() | 根据传入的参数创建一个新的range对象 |
| iter() | 根据传入的参数创建一个新的可迭代对象 |
| slice() | 根据传入的参数创建一个新的切片对象 |
| super() | 根据传入的参数创建一个新的子类和父类关系的代理对象 |
| object() | 创建一个新的object对象 |
3.序列操作:
| 函数 | 描述 |
|---|---|
| all() | 判断可迭代对象的每个元素是否都为True值 |
| any() | 判断可迭代对象的元素是否为True值的元素 |
| filter() | 使用指定方法过滤可迭代对象的元素 |
| map() | 使用指定方法取作用传入的每个迭代对象的元素,生成新的可迭代对象 |
| next() | 返回可迭代对象的下一个元素值 |
| reversed() | 反转序列生成新的可迭代对象 |
| sorted() | 对可迭代对象进行排序,返回一个新的列表 |
| zip() | 聚合传入的每隔迭代器中的相同位置的元素,返回一个新的元祖类型迭代器 |
4.对象操作:
| 函数 | 描述 |
|---|---|
| help() | 返回对象的帮助信息 |
| dir() | 返回对象或者当前作用域内的属性列表 |
| id() | 返回对象的唯一标识符 |
| hash() | 获取对象的哈希值 |
| type() | 返回对象的类型,或者根据传入的参数创建一个新的类型 |
| len() | 返回对象的长度 |
| ascii() | 返回对象的可打印表字符串表现方式 |
5.反射操作:
| 函数 | 描述 |
|---|---|
| import() | 动态导入模块 |
| isinstance() | 判断对象是否是类或者元祖中任意类元素的实例 |
| issubclass() | 判断类是否是另一个类或者类型元组中任意类元素的子类 |
| hasattr() | 检查对象是否含有属性 |
| getsttr() | 获取对象的属性值 |
| setattr() | 设置对象的属性值 |
| delattr() | 删除对象的属性 |
| callable() | 检查对象是否可被调用 |
| format() | 格式化显示值 |
| var() | 返回当前作用域内的局部变量和其值组成的字典,或者返回对象的属性列表 |
6.变量操作:
| 函数 | 描述 |
|---|---|
| globals() | 返回当前作用域内的全局变量和其值组成的字典 |
| locals() | 返回当前作用域内的局部变量和其值组成的字典 |
7.交互操作:
| 函数 | 描述 |
|---|---|
| print() | 向标准输出对象打印输出 |
| input() | 读取用户输入值 |
8.文件操作:
| open() | 使用指定的模式和编码打开文件,返回文件读取对象 |
9.编译执行:
| compile() | 将字符串编译为代码或者AST对象,使之能够通过exec语句来执行或者eval进行求值 |
| eval() | 执行动态表达式求值 |
| exec() | 执行动态语句块 |
| repr() | 返回一个对象的支付穿表现形式 |
10.装饰器:
| property() | 标示属性的装饰器 |
| classmethod() | 标示方法为类方法的装饰器 |
| staticmethod() | 标示方法为静态方法的装饰器 |
常用函数解析
- hasattr(object,name))
判断对象object是否包含名为name的特性(hasattr是通过调用getattr(object,name)是否抛出异常来实现的)
hasattr(list,'add')
Out[4]: False
hasattr(list,"append")
Out[5]: True
- all(x)
x为组合类型数据,可迭代对象(列表、元组、字典)
如果其中全部元素为True,则都返回True,否则False
注意: ==整数0,空字符串"",空列表[]等都当初False
检查列表中的所有项目是否为 True:
mylist = [0, 1, 1]
x = all(mylist)
- any()
与all()相反,只要组合数据类型有一个是True,则返回True,全部元素为False,则返回False
4.id()
返回元组对象的唯一 id,可以通过比较两个变量编号是否相同判断数据是否一致
- reversed()返回组合数据类型的逆序形式
反转列表的顺序,并打印每个项目:
alph = ["a", "b", "c", "d"]
ralph = reversed(alph)
for x in ralph:
print(x)
- sorted(iterable, key=key, reverse=reverse)
对一个系列进行排序,默认从小到大
参数 描述
iterable 必需。要排序的序列,列表、字典、元组等等。
key可选。执行以确定顺序的函数。默认为 None。
reverse可选。布尔值。False 将按升序排序,True 将按降序排序。默认为 False。
7.type() 返回数据对应类型
6.1 组合数据类型概述
组合数据类型: 序列类型,集合类型,映射类型
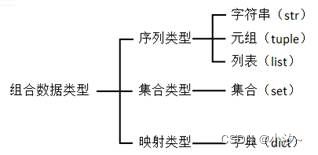
序列类型:是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他。
集合类型:是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
映射类型:是键—值数据项的组合,每个元素是一个键值对,表示为(key,value)
6.1.1 序列类型
- 序列类型是一维元素向量,元素之间存在先后关系,通过序号访问
- 序列中可以存在数值相同但位置不同的元素
- 序列类型支持成员关系操作符in、长度计算函数len()、分片[]以及元素本身也可以是序列类型
- 序列类型有str(字符串)、tuple(元组)、list(列表)等。
- 只要是序列类型,都可以使用相同的索引体系,即正向递增序号和反向递减序号
序列类型通用操作符和函数
| 操作符/函数 | 描述 |
|---|---|
| x in s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
| s+t | 连接s和t |
| sn或ns | 将序列s复制n次 |
| s[i] | 索引,返回序列的第i个元素 |
| s[i:j] | 分片,返回包含序列s的第i到j个元素的子序列(不包含j,左闭右开) |
| s[i:j:k] | 步骤分片,返回包含序列s的第i到第j个元素以k为步数的子序列 |
| len(s) | 序列s的元素个数(长度) |
| min(s) | 序列s中的最小元素 |
| max(s) | 序列s中的最大元素 |
| s.index(x[,i[,j]]) | 序列s中从i开始到j位置中第一次出现元素x的位置 |
| s.count(x) | 序列s中出现x的总次数 |
6.1.2 集合序列
- 包含0个或多个数据项的无序组合,不可索引,无位置概念,分片,元素不可重复,元素类型只能是固定数据类型,例如整数、浮点数、字符串以及元组等。列表、字典以及集合类型本身都是可变数据类型,不能作为集合元素出现,能够进行哈希运算的类型都可以作为集合的元素
- hash() 哈希运算函数,对数据类型生成一个哈希值
- 可以动态增加或删除
- 打印效果与定义顺序不一定一致,其元素唯一性,可用于 过滤重复元素
- 集合用大括号{}表示, set(x)可用于生成集合
- 直接使用{}无法生成集合,生成的是空字典
- 集合四种基本操作 交集(&),并集(|),差集(-),补集(^)
- 集合主要用于 成员关系测试,元素去重,删除数据项
>>> A = {"python", 123, ("python", 123)}
>>> print(A);
{123, 'python', ('python', 123)}
>>> B = set("pypy123"); #使用set建立集合
>>> print(B);
{'y', '3', 'p', '2', '1'}
>>> C = {"python", 123, "python", 123};
>>> print(C);
{123, 'python'}
集合类型的操作符
| 操作符 | 描述 |
|---|---|
| S - T 或s.difference(T) | 差,返回一个新集合,包括在集合S但不在T中的元素 |
| S -= T 或s.difference_updata(T) | 差,更新集合S,包括在集合S但不在T中的元素 |
| S & T 或 s.instersection(T) | 交,返回一个新集合,包括同时在集合S和T中的元素 |
| S &= T 或s.instersection_updata(T) | 交,更新集合S,包括同时在集合S和T中的元素 |
| S ^ T 或symmetric_difference(T) | 补,返回一个新集合,包括集合S和T中的非相同元素 |
| S ^= T 或symmetric_difference(T) | 补,更新集合S,包括集合S和T中非相同的元素 |
| S | T或s.union(T) | 并,返回一个新集合,包括在集合S和T中所有的元素 |
| S |= T 或s.upadate(T) | 并,更新集合S,包括在集合S和T中所有的元素 |
| S <= T 或 S < T或s…issubset(T) | 返回True或False,判断S和T的子集关系,前者s与T相同或是T的子集,返回True,后者可用于判断s是否为T的真子集 |
| S >= T 或 S > T 或s.issuperset(T) | 返回True或False,判断S和T的包含关系,前者s与T相同或是T的超集,返回True,后者可用于判断s是否为T的真超集 |
集合类型的操作函数或方法
| 操作函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果x不在集合S中,将x增加到S |
| S.discard(x) | 移除S中元素x,如果x不在集合S中,不报错 |
| S.remove(x) | 移除S中元素x,如果x不在集合S中,产生KeyError异常 |
| S.clear() | 移除S中所有元素 |
| S.pop() | 随机返回S的一个元素,更新S,若S为空产生KeyError异常 |
| S.copy() | 返回集合S的一个副本 |
| len(S) | 返回集合S的元素个数 |
| x in S | 判断S中元素x,x在集合S中,返回True,否则返回False |
| x not in S | 判断S中元素x,x不在集合S中,返回True,否则返回False |
| set(x) | 将其他类型变量x转变为集合类型 |
6.1.3映射类型
映射类型是“键—值”的数据项的组合,每个元素是一个键值对,即元素是(key,value),元素之间是无序的,键值对(key,value)是一种二元关系。
键和值通过冒号连接,不同键值对通过逗号隔开。主要是以字典(dist)体现,字典是集合类型的延续,所以各个元素并没有顺序之分。键和值可以是任意数据类型,包括程序自定义的类型。
6.2.1 元组概述
- 元组tuple是包含0个或多个数据项的不可变序列类型,因为它一旦创建就不能被修改,并且元组生成后固定的,其中的任何数据项不可替换或者删除
- 元组类型在表达固定数据项、函数多返回值、多变量同步赋值、循环遍历等情况下十便利。
- Python中元组采用逗号和圆括号来表示。
- 生成元组只需要使用逗号将元素隔离开即可。也可以增加圆括号,但圆括号在不混淆语义的情况下不是必须的。
- 一个元组可以作为另一个元组的元素,并且可以采用多级索引来获取信息。
- 也可以使用 tuple() 构造函数来创建元组
| 函数 | 描述 |
|---|---|
| cmp(tuple1, tuple2) | 比较两个元组元素。 |
| tuple(seq) | 将列表转换为元组。 |
元组tuple是包含0个或多个数据项的不可变序列类型,并且元组生成后
固定的,其中的任何数据项不可替换或者删除
>>>print( 'abc', -4.24e93, 18+6.6j, 'xyz')
>>>x, y = 1, 2
>>>print( "Value of x , y : ", x,y)
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2
6.2.2 列表概述
- 是一种有序和长度内容可更改。允许重复的成员。没有长度限制
- 列表也支持成员关系操作符in、长度len()以及分片[]等操作。
- 列表可以同时使用正向递增序号何反向递减序号,也可以采用标准的比较操作符(<=/==/!=/>=/>)进行比较,列表比较其实是单个数据项的逐个比较。
- 列表用中括号[]表示,也可以通过list()函数将元组或字符串转化成列表。直接使用list()函会返回一个空列表。
- 简单将一个列表赋值给另一个列表不会生成新列表对象
因为:list2 将只是对 list1 的引用,list1 中所做的更改也将自动在 list2 中进行。
>>>is=[1,"b",1]
>>>it=is #it只是对is的引用,it不包括真实数据,修改is同时也会修改it
>>>is[0]=0
>>>print(it)
[0,"b",1]
列表类型特有的函数和方法
| 函数/方法 | 描绘 |
|---|---|
| list(seq) | 将元组转换为列表 |
| ls[i]=x | 替换列表ls第i项数据为x |
| ls[i:j]=lt | 列表lt替换列表ls中第i到第j项数据(不包含第j项,下同) |
| ls[i:j:k]=lt | 用列表lt替换列表ls中第i到第j项以k为步长的数据 |
| del ls[i:j] | 删除列表ls第i到第j项数据。等价于ls[i:j]=[] |
| del ls[i:j:k] | 删除列表ls第i到第j项以k为步长的数据 |
| ls+=lt或ls.extend(lt) | 将列表lt元素增加到列表ls中 |
| ls*=n | 更新列表ls,其元素重复n次 |
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.clear() | 删除ls中所有的元素 |
| ls.copy() | 生成一个新列表,复制ls中的所有元素 |
| ls.insert(i,x) | 在列表第i的位置新增插入元素x |
| ls.pop(i) | 将列表ls中第i项元素取出并删除该元素 |
| ls.remove(x) | 将列表ls中出现的第一个元素x删除 |
| ls.reserve() | 列表ls中的元素反转 |
当使用一个列表改变另一个列表时,Python不要求两个列表长度一样,但遵循“多增少减”的原则
如下:
>>>vlist=list[range(5)]
>>>vlist[1:3] = ["new","bit",1]
>>>vlist
[0,"new","bit",1,3,4]
>>>vlist[1:3]=["fewer"]
>>>vilst
[0,"fewer",1,3,4]
#检查列表中是否存在 “apple”:
thislist = ["apple", "banana", "cherry"]
if "apple" in thislist:
print("Yes, 'apple' is in the fruits list")
6.2.3 字典概述
- Python 最强大的数据类型之一,通过键-值对的方式建立数据对象之间的映射关系。字典的每个键-值对用冒号:分割,每个键-值对间用逗号,分隔开,字典则包含在{}中。每个键都与一个值相关联,我们可以使用键来访问与之相关联的值。与键相关联的值可以是数字、字符串、列表乃至字典。事实上,可将任何 Python 对象用作字典中的值。
格式如下:
d = { key1 : value1, key2 : value2 }
- 键值对之间没有顺序且不能重复,打印效果可能跟定义顺序不一致
- 键值对的访问模式
<值> =<字典变量>[<键>]
- 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
- 直接使用大括号{}可以创建一个空字典,并通过中括号[]向其增加元素
注意: 直接使用大括号不能生成空集合,需要使用set()
>>> d={}
>>>d['2^10']=1024
>>>print(d)
{'2^10:1024}
字典类型的函数和方法
| 函数和方法 | 描述 |
|---|---|
| 返回所有键信息 | |
| 返回所有值信息 | |
| 返回所有的键值对 | |
| 键存在则返回相应值,否则返回默认值 | |
| 键存在则返回相应值,同时删除键值对,否则返回默认值 | |
| 随机从字典中取出一个键值对,以元组(key,value)形式返回 | |
| 删除所有键值对 | |
| del |
删除字典中某一个键值对 |
| 如果键在字典中则返回Trule,否则False | |
| < d>.fromkeys(list) | 定的多个键创建一个新字典,值默认都是 None,也可以传入一个参数作为默认的值。 |
list1 = ['Author', 'age', 'sex']
dic1 = dict.fromkeys(list1)
dic2 = dict.fromkeys(list1, 'Python')
# dic1 = {'Author': None, 'age': None, 'sex': None}
# dic2 = {'Author': 'Python', 'age': 'Python', 'sex': 'Python'}
如果希望方法返回的是列表类型,可以使用list()