mse均方误差计算公式_【从零开始学机器学习12】MSE、RMSE、R2_score
摘要:【机器学习12】线性回归算法评价指标:MSE、RMSE、R2_score。
上一篇文章我们介绍了简单的一元线性回归算法,今天介绍评价线性回归效果好坏的几个重要指标。
Python 手写线性回归算法竟如此简单(可点击)
在介绍这几个指标前,先来回顾下上节是如何建立线性回归模型的。
对一个有 m 个样本和 1 个特征的数据集,拆成训练集和测试集后。在训练集上让预测值 y 和真实值 y 之间的差值平方和尽可能地小: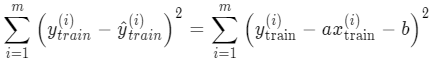
然后求解出 a 和 b 得到回归模型,应用到测试集上计算出预测值 y:![]()
最后计算出预测值和真实值的差值平方和,作为衡量线性回归模型好坏的评价指标: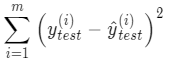
不过上式有个问题:值的大小和样本数量 m 有密切关系,这样的结果是无法衡量模型好坏的。
MSE
举个例子,假设建立了两个模型,一个模型使用了 10 个样本,计算出的上式值是 100;另一个模型使用了 50 个样本,计算出的值是 200,很难判断两个模型哪个更好。
那怎么办呢,其实很好解决,将上式除以 m 就可以去除样本数量的影响:
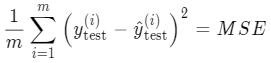
这个式子的结果就是第一个模型评价指标:均方误差 MSE(Mean Squared Error)。
针对上面举例的两个模型,他们的 MSE 分别是 10(100/10)和 4 (200/50),所以后者模型效果更好。
RMSE
但是,MSE 公式有一个问题是会改变量纲。因为公式平方了,比如说 y 值的单位是万元,MSE 计算出来的是万元的平方,对于这个值难以解释它的含义。所以为了消除量纲的影响,我们可以对这个MSE 开方,得到的结果就第二个评价指标:均方根误差 RMSE(Root Mean Squared Error):
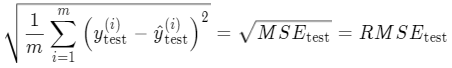
可以看到 MSE 和 RMSE 二者是呈正相关的,MSE 值大,RMSE 值也大,所以在评价线性回归模型效果的时候,使用 RMSE 就可以了。
MAE
上面公式为了避免误差出现正负抵消的情况,采用计算差值的平方。还有一种公式也可以起到同样效果,就是计算差值的绝对值: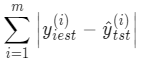
因此,将上式也除以样本数 m 得到的结果就是第三个评价指标:平均绝对误差 MAE(Mean Absolute Error):

上面三个模型解决了样本数量 m 和 量纲的影响。但是它们都存在一个相同的问题:当量纲不同时,难以衡量模型效果好坏。
举个例子,模型在一份房价数据集上预测得到的误差 RMSE 是 5 万元, 在另一份学生成绩数据集上得到误差是 10 分。凭这两个值,很难知道模型到底在哪个数据集上效果好。
R2_score
那如何比较不同量纲下模型的效果好坏呢?这就需要用到回归模型的第四个评价指标:R方值(R2_score)。
它的含义就是,既然不同数据集的量纲不同,很难通过上面的三种方式去比较,那么不妨找一个第三者作为参照,根据参照计算 R方值,就可以比较模型的好坏了。
这个参照是什么呢,就是均值模型。我们知道一份数据集是有均值的,房价数据集有房价均值,学生成绩有成绩均值。现在我们把这个均值当成一个基准参照模型,也叫 baseline model。这个均值模型对任何数据的预测值都是一样的,可以想象该模型效果自然很差。基于此我们才会想从数据集中寻找规律,建立更好的模型。
R2_score 的计算公式是这样的: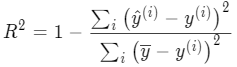
通过它的取值可以更好理解它是如何评价模型好坏的,有这几种取值情况:
R2_score = 1,达到最大值。即分子为 0 ,意味着样本中预测值和真实值完全相等,没有任何误差。也就是说我们建立的模型完美拟合了所有真实数据,是效果最好的模型,R2_score 值也达到了最大。但通常模型不会这么完美,总会有误差存在,当误差很小的时候,分子小于分母,模型会趋近 1,仍然是好的模型,随着误差越来越大,R2_score 也会离最大值 1 越来越远,直到出现第 2 中情况。
R2_score = 0。此时分子等于分母,样本的每项预测值都等于均值。也就是说我们辛苦训练出来的模型和前面说的均值模型完全一样,还不如不训练,直接让模型的预测值全去均值。当误差越来越大的时候就出现了第三种情况。
R2_score < 0 :分子大于分母,训练模型产生的误差比使用均值产生的还要大,也就是训练模型反而不如直接去均值效果好。出现这种情况,通常是模型本身不是线性关系的,而我们误使用了线性模型,导致误差很大。
理解了 R2_score 后,我们可以对它的计算公式作进一步改进,以便后面编程实现。将分子和分母同除以一个 m,就能得到下式: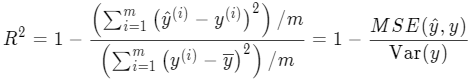
分子是均方误差,分母是方差,都能直接计算得到,从而能快速计算出 R2 值。
以上我们就介绍了评价线性回归模型的四个指标,下面通过波士顿房价数据集来实际计算一下。
实际案例计算
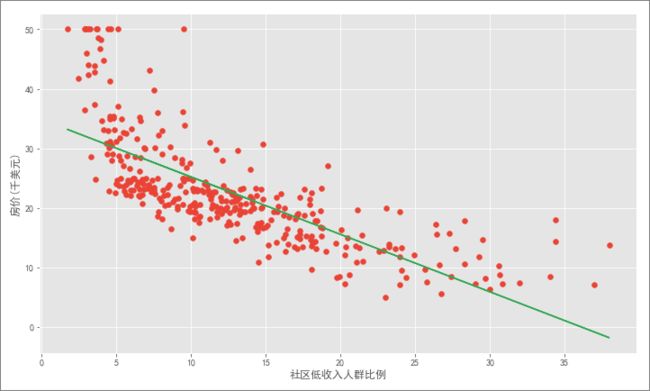
之前在运用 kNN 算法解决回归问题时就已经介绍过波士顿房价数据集,这里不再赘述。由于现在是介绍简单一元线性回归,所以只使用其中一个跟房价相关度最高的特征:LSTAT(社区低收入人群比例),建立线性回归模型后,便可计算模型的几个评价值。
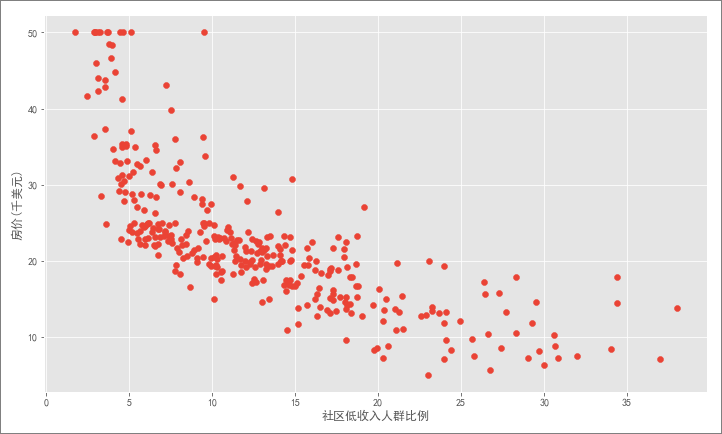
可以看到该特征和房价呈负相关关系,很容易理解:低收入人群越多的社区,该比例越高,房价自然也就越低。
将数据划分为训练集和测试集后,使用上一篇教程中手写的线性回归算法建立回归模型,得到最佳拟合直线:
解析来就可以计算各项值了。
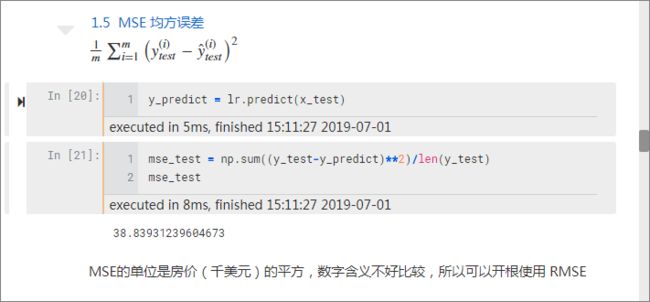
均方误差值 MSE:
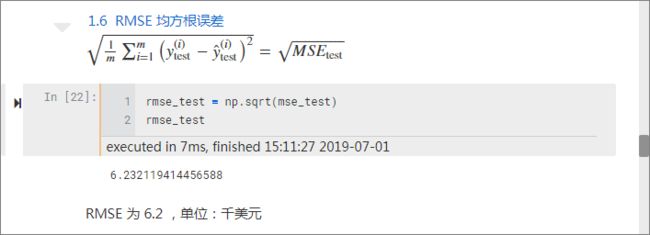
均方根误差值 RMSE:
平均绝对误差 MAE:
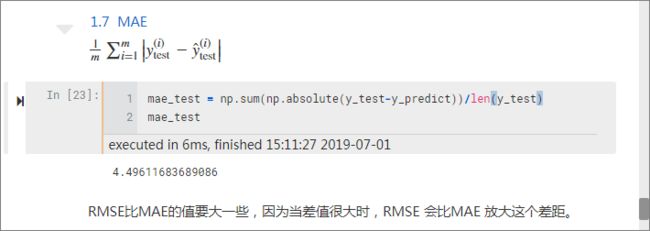
可以看到,RMSE 比 MAE 的值要大一些,因为当差值很大时,RMSE 会比MAE 放大这个差距。举个例子,一个数据集有两个样本,样本差分别是 2 和 100,
则 MAE =(2+100)/2=51,而 RMSE 增大到了 70。
最后计算一下 R2_score 值:

R2_score 只有 0.51 分,模型并不理想,主要是因为我们的线性回归模型只使用了一个特征,如果使用多个特征的话效果可能会更好,下一节我们介绍多元线性回归会再计算该值。
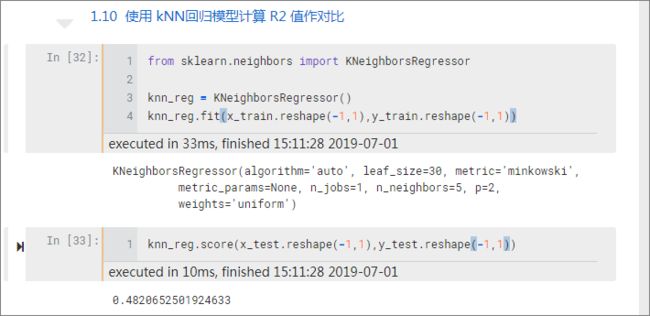
为了作为对比,还可以计算 kNN 模型下的 R2_score 值,可以看到只有 0.48 分,还不如线性回归。
本文的 jupyter notebook 代码,可以扫码回复「LR2」得到,加油!