LSTM源码解析
作为CV从业者,大部分时间都是在跟CNN打交道,但RNN在图像方面的应用也越来越多,比如在文本检测算法CTPN中就有用到LSTM,因为文本是有顺序和前后语义联系的,用到LSTM也合情合理。相比于卷积的过程,LSTM更加复杂,虽然看了一些博客后了解了抽象概念,但还是想通过送入实际的值,调试代码来观察整个流程中的每一步来加深对其的理解。
本文以tensorflow-1.10版本为例,在eager模式下来进行lstm源码的调试。在阅读本文前,建议先阅读Understanding LSTM Networks了解LSTM的原理,这篇文章介绍的非常详细,本文就不再介绍具体原理了,只是对照这篇文章按照tensorflow中lstm的实际调用过程进行源码解析。
首先自己造一个输入,在CTPN中,一张图片首先经过多层卷积、池化操作,在输入LSTM前的shape为(batch_size, height, width, channel),首先将其reshape成(b×h, w, c),因为任务是检测图片中的文本行,因此这里的w就是lstm中的max_time。代码如下
import tensorflow as tf
import numpy as np
tf.enable_eager_execution()
net = np.ones((2, 2, 2, 3), dtype=np.float32) # (batch_size, h, w, c)
net = tf.convert_to_tensor(net)
shape = tf.shape(net)
N, H, W, C = shape[0], shape[1], shape[2], shape[3]
net = tf.reshape(net, [N * H, W, C]) # (4,2,3) (batch_size, time_step, embedding_size)
lstm_fw_cell = tf.nn.rnn_cell.LSTMCell(num_units=2, initializer=tf.ones_initializer, state_is_tuple=True)
output, final_state = tf.nn.dynamic_rnn(lstm_fw_cell, net, dtype=tf.float32)其中num_units就是经过LSTM后的输出维度,在CNN中卷积后的输出维度(通道数)由卷积核的个数决定,具体可以查看这篇文章BasicLSTMCell中num_units参数解释。tf.ones_initializer将权重矩阵初始化为全1矩阵,方便调试计算。tf.nn.dynamic_rnn是用来封装lstm_cell的,具体步骤还是在LSTMCell中实现的。
tf.nn.dynamic_rnn的函数定义在../tensorflow/python/opts/rnn.py的455行。dynamic_rnn的入参有个time_major,默认为False。当input.shape = (batch_size, max_time, depth) 时,time_major=False。当Input.shape = (max_time, batch_size, depth) 时,time_major=True。当time_major=False时,因为我们input的shape是前者,在第583行,代码将其转成 (max_time, batch_size, depth) 格式。代码如下
if not time_major:
# (B,T,D) => (T,B,D)
flat_input = [ops.convert_to_tensor(input_) for input_ in flat_input]
flat_input = tuple(_transpose_batch_time(input_) for input_ in flat_input)
如上图所示是一个lstm cell,当time_step=0也就是在第一个时间步时,需要初始化一个 和
和 ,由dynamic_rnn的入参initial_state传入,默认值为None,当initial_state不传值时必须传入dtype这个参数,否则会报错。在第600行代码会根据dtype创建一个全0的初始state。注意shape都是(batch_size, max_time)即(4, 2)。代码如下
,由dynamic_rnn的入参initial_state传入,默认值为None,当initial_state不传值时必须传入dtype这个参数,否则会报错。在第600行代码会根据dtype创建一个全0的初始state。注意shape都是(batch_size, max_time)即(4, 2)。代码如下
if initial_state is not None:
state = initial_state
else:
if not dtype:
raise ValueError("If there is no initial_state, you must give a dtype.")
state = cell.zero_state(batch_size, dtype)
print(state)
LSTMStateTuple(c=, h=) 然后第624行调用函数_dynamic_rnn_loop,主要的入参包括cell、inputs和state,cell就是最开始代码中创建的lstm_fw_cell,inputs是transpose成(T, B, D)后的,state就是上面创建的全0初始状态。
接着进入函数_dynamic_rnn_loop中,快进到823行,通过control_flow_ops.while_loop循环调用函数_time_step,每一次调用是一个时间步,一共调用max_time次。
接着进入函数_time_step,其中在786行定义call_cell,在800行调用call_cell,代码如下
call_cell = lambda: cell(input_t, state)
(output, new_state) = call_cell()这里的cell就是我们最开始创建的lstm_fw_cell,之前一开始也说过dynamic_rnn只是个封装函数,lstm的具体实现在LSTMCell里面,也就是在这里开始一个lstm cell的流程。
接着就要进入到../tensorflow/python/ops/rnn_cell_impl.py的652行的类LSTMCell中,实际调用的是807行的call函数,注释第一行就是Run one step of LSTM。
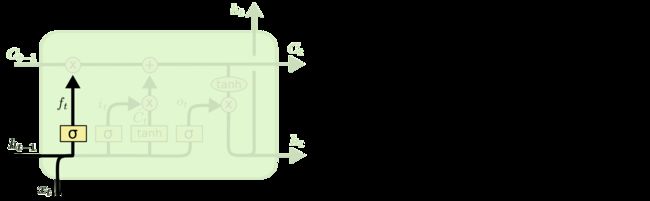
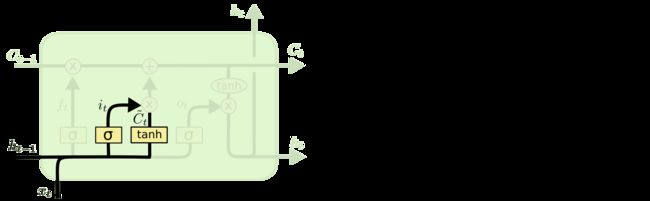
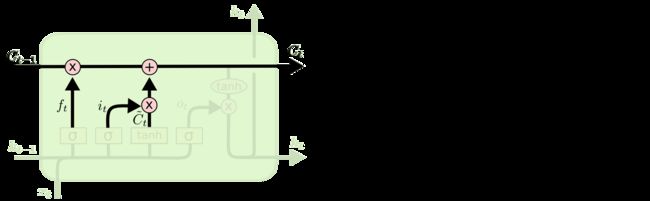
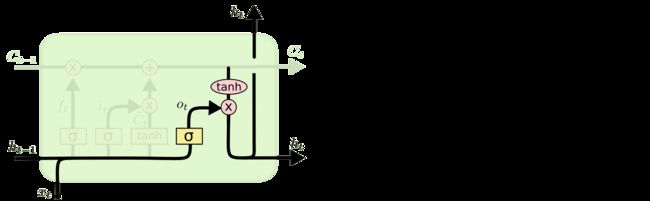
首先看到上面四个图就是LSTM一个time_step的过程,代码837行,(c_prev, m_prev) = state,state在上面的代码中已经打印出来了,是两个shape=(4, 2)的全零矩阵,这里的c_prev和m_prev就是上面代码中的c和h,对应上面图中的和。
接着第846行
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
lstm_matrix = math_ops.matmul(
array_ops.concat([inputs, m_prev], 1), self._kernel)
lstm_matrix = nn_ops.bias_add(lstm_matrix, self._bias)
i, j, f, o = array_ops.split(
value=lstm_matrix, num_or_size_splits=4, axis=1)
############
print(inputs)
tf.Tensor(
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]], shape=(4, 3), dtype=float32)
print(array_ops.concat([inputs, m_prev], 1))
tf.Tensor(
[[1. 1. 1. 0. 0.]
[1. 1. 1. 0. 0.]
[1. 1. 1. 0. 0.]
[1. 1. 1. 0. 0.]], shape=(4, 5), dtype=float32)
print(self._kernel)
print(self._bias)
print(lstm_matrix)
tf.Tensor(
[[3. 3. 3. 3. 3. 3. 3. 3.]
[3. 3. 3. 3. 3. 3. 3. 3.]
[3. 3. 3. 3. 3. 3. 3. 3.]
[3. 3. 3. 3. 3. 3. 3. 3.]], shape=(4, 8), dtype=float32) 首先看inputs,原始输入shape=(4,2,3),是(B,T,D)格式,之前有讲过dynamic_rnn一开始就将输入transpose成了(T,B,D)也就是(2,4,3)的格式,然后这里是一个time_step,故这里的inputs.shape=(4,3)。然后将其与m_prev拼接,shape变成(4,5),结果如代码中打印的所示。
接着773行可以看到self._kernel.shape=[input_depth + h_depth, 4 * self._num_units]=[3+2, 4*2],input_depth=3就是输入shape中的D,h_depth=self._num_units=2,这是我们一开始传入LSTMCell的参数num_units,之前我们提过num_units就是lstm_cell的输出维度,这里需要注意第二个维度之所以要乘以4,是因为如上面四张图中,有四个权重矩阵与输入相乘的式子![]() ,区别在于W和b的下标不同,代码中将这四个不同的W拼接了起来一起计算,然后再split成了4个输出。
,区别在于W和b的下标不同,代码中将这四个不同的W拼接了起来一起计算,然后再split成了4个输出。
然后到859行
c = (sigmoid(f + self._forget_bias) * c_prev + sigmoid(i) * self._activation(j))
print(c)
tf.Tensor(
[[0.9478634 0.9478634]
[0.9478634 0.9478634]
[0.9478634 0.9478634]
[0.9478634 0.9478634]], shape=(4, 2), dtype=float32)其中self._forget_bias取默认值1.0,self._activation是tanh函数,其它值上面都已经print出来了,大家可以自己手动算一下最终结果是不是和上面打印的一样。这里的c就是上面第三张图中的 。
。
最后869行
m = sigmoid(o) * self._activation(c)
print(m)
tf.Tensor(
[[0.7037754 0.7037754]
[0.7037754 0.7037754]
[0.7037754 0.7037754]
[0.7037754 0.7037754]], shape=(4, 2), dtype=float32)这里的m就是上面第四张图中计算的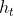 ,至此LSTM的一个time_step计算完毕,源码中的c和m对应图中的和。
,至此LSTM的一个time_step计算完毕,源码中的c和m对应图中的和。
接着c和m组合成state传入下一个time_step中,重复同样的计算步骤,大家可以自己手动计算一下,第二个时间步的c和m结果如下
tf.Tensor(
[[1.9313017 1.9313017]
[1.9313017 1.9313017]
[1.9313017 1.9313017]
[1.9313017 1.9313017]], shape=(4, 2), dtype=float32)
tf.Tensor(
[[0.9472957 0.9472957]
[0.9472957 0.9472957]
[0.9472957 0.9472957]
[0.9472957 0.9472957]], shape=(4, 2), dtype=float32)因为我们的输入max_time=2,所以第二个时间步整个流程就结束了。接着我们打印dynamic_rnn的返回output和final_state,结果如下
print(output)
tf.Tensor(
[[[0.7037754 0.7037754]
[0.9472957 0.9472957]]
[[0.7037754 0.7037754]
[0.9472957 0.9472957]]
[[0.7037754 0.7037754]
[0.9472957 0.9472957]]
[[0.7037754 0.7037754]
[0.9472957 0.9472957]]], shape=(4, 2, 2), dtype=float32)
print(final_state)
LSTMStateTuple(c=, h=) 在实际应用中,我们只需要output,final_state用不到。注意output是两个time_step的m值,即图中的向上的箭头,且因为一开始将输入由(B,T,D)转成了(T,B,D),最后要再转回(B,T,D)再返回。最终output.shape=(4,2,2),分别对应batch_size,max_time,num_units。
双向LSTM
在CTPN中实际用的是双向LSTM,代码中LSTMCell不变,封装函数由tf.nn.dynamic_rnn改为tf.nn.bidirectional_dynamic_rnn,其内部实现也很简单,就是正向和反向调用两次dynamic_rnn。但是在反向dynamic_rnn前需要将inputs先reverse一下,为了方便观察,将原始input由全1矩阵改为随机矩阵,然后inputs和inputs_reverse如下所示
print(inputs)
tf.Tensor(
[[[0.84839684 0.21003267 0.49825752]
[0.17281447 0.92418146 0.70772856]]
[[0.7951453 0.31010404 0.15164271]
[0.03229304 0.3272632 0.12064549]]
[[0.02255895 0.512737 0.10098135]
[0.0386815 0.1329508 0.68645036]]
[[0.55390334 0.5705598 0.38108754]
[0.82101023 0.92697096 0.77738845]]], shape=(4, 2, 3), dtype=float32)
print(inputs_reverse)
tf.Tensor(
[[[0.17281447 0.92418146 0.70772856]
[0.84839684 0.21003267 0.49825752]]
[[0.03229304 0.3272632 0.12064549]
[0.7951453 0.31010404 0.15164271]]
[[0.0386815 0.1329508 0.68645036]
[0.02255895 0.512737 0.10098135]]
[[0.82101023 0.92697096 0.77738845]
[0.55390334 0.5705598 0.38108754]]], shape=(4, 2, 3), dtype=float32)其实很好理解,就是将inputs在max_time维度进行反转,所谓的反向就是时间序列这个维度的反向。
然后反向dynamic_rnn的输出再沿max_time维度反转回去,和正向的输出保持一致。将输入再改回全1矩阵,打印出最终输出如下
(, ) 从上面可以看出,因为输入是全1矩阵,且初始state都是全0初始化,因此前向和反向lstm的输出是一样的,为了将两个输出按照时间序列对应起来,将反向输出按max_time维度进行反转就得到了最终的结果。
参考
http://colah.github.io/posts/2015-08-Understanding-LSTMs/#fn1
BasicLSTMCell中num_units参数解释_notHeadache的博客-CSDN博客_lstm中的units