【强化学习-医疗】用于临床决策支持的深度强化学习:简要综述
Article
- 作者:Siqi Liu, Kee Yuan Ngiam, Mengling Feng
- 文献题目:用于临床决策支持的深度强化学习:简要综述
- 文献时间:2019
- 文献链接:https://arxiv.org/abs/1907.09475
摘要
- 由于人工智能尤其是深度学习的最新进展,许多数据驱动的决策支持系统已被实施,以促进医生提供个性化护理。我们在本文中关注深度强化学习 (DRL) 模型。 DRL 模型在计算机视觉和游戏任务(例如围棋和雅达利游戏)中展示了人类水平甚至卓越的性能。然而,在临床决策优化中采用深度强化学习技术仍然很少见。我们在此展示了第一项调查,该调查总结了使用深度神经网络 (DNN) 进行临床决策支持的强化学习算法。我们还讨论了一些案例研究,其中应用了不同的 DRL 算法来解决各种临床挑战。我们进一步比较和对比了各种 DRL 算法的优点和局限性,并就如何为特定临床应用选择合适的 DRL 算法提供了初步指南。
背景
- 在医疗保健领域,临床过程是非常动态的。 做出临床决策的“规则”通常不明确(Marik,2015)。 例如,让我们考虑以下临床决策问题:患者是否会从器官移植中受益? 在什么情况下移植会成为更好的选择; 移植后开出的最佳药物和剂量是什么? 从这些问题中做出的决定应该针对个别患者的情况。 为了找到这些问题的最佳决策,通常选择进行随机临床试验 (RCT)。 然而,在某些临床情况下,随机对照试验可能不切实际且不可行。 因此,从分析观测数据开始成为一种替代方法。 随着数据收集的改进和 DRL 技术的进步,我们看到了基于 DRL 的决策支持系统在优化治疗建议方面的巨大潜力。
- 技术意义
本调查论文总结并讨论了已应用于临床应用以提供临床决策支持的主要 DRL 算法类型。 此外,我们讨论了这些 DRL 算法的权衡和假设。 本文旨在作为指导方针,帮助我们的读者为其特定的临床应用选择合适的 DRL 模型。 据我们所知,这是第一篇关于 DRL 用于治疗推荐或临床决策支持的调查论文。 - 临床相关性
事实证明,DRL 可以达到人类水平的能力,可以在特定领域(例如视频游戏、棋盘游戏和自主控制)中学习复杂的顺序决策。 而在医疗保健方面,DRL 尚未广泛应用于临床应用。 在本文中,我们调查了在临床领域提供顺序决策支持的主要 DRL 算法。 我们相信,从收集到的大量电子健康记录 (EHR) 数据中学习,DRL 能够提取和总结优化新患者治疗所需的知识和经验。 DRL 还具有通过自动探索各种治疗方案并估计其可能结果来扩展我们对当前临床系统的理解的潜力。
强化学习MDP
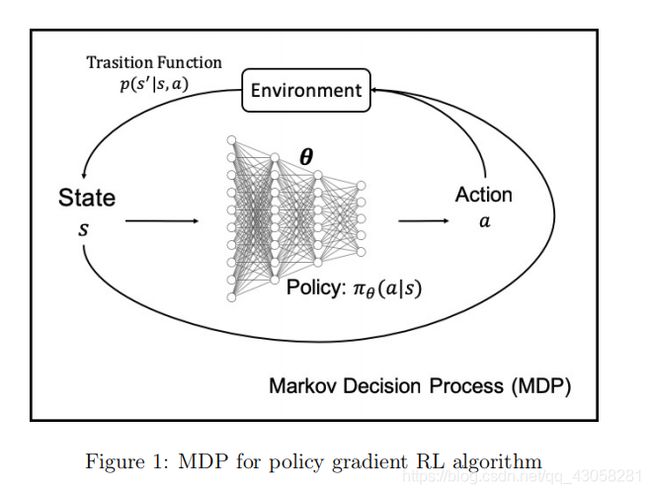
- 在临床环境中,我们将智能体视为临床医生。 我们可以将状态视为患者的福祉/状况。 患者的状态可以取决于他的人口统计学(例如,年龄、性别、种族等)、纵向和生理测量(例如,实验室测试、生命体征、医学图像报告等)和一些其他临床特征。 行动是临床医生对患者采取的治疗措施(例如,某些药物的处方、外科手术的安排等)。 转移函数 P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t,a_t) P(st+1∣st,at) 可以看作是患者自身的生物系统,给定当前的健康和干预,患者将进入下一个时间步 s t + 1 s_{t+1} st+1。 如果健康状况得到改善,我们会为智能体分配奖励,如果患者的病情在干预后恶化或停滞不前,我们就会惩罚智能体。
深度强化学习
- 在实际应用中,尤其是在临床应用中,数据生成通常是一个大问题,因为它是实时的,而且许多观察数据(来自电子健康记录)是我们不容易拥有的私有数据使用权。 我们也不希望通过反复试验来估计值,因为这通常是不道德的且成本高昂。因此,当我们选择 RL 算法时,我们需要了解这些约束。
- 在本文中,我们将首先重点讨论应用于临床决策支持的 RL 算法的主要类型,而仅简要介绍一种在临床应用中很少应用的 RL 算法。 我们还将讨论与医疗保健领域的其他算法相比,特定算法不那么“流行”的根本原因。
强化学习算法
策略梯度强化学习
在策略梯度 RL 中,DNN 用于在步骤 3 中构建策略,其中 DNN 的输入是状态,输出是动作。图1是策略梯度RL的MDP图。通过采用 J(θ) 的梯度并更新 DNN 中的权重,相应地学习策略。在临床环境中,与其他 RL 算法相比,策略梯度 RL 并不“流行”。其根本原因可能在于它是一种基于策略的算法,需要基于新策略迭代收集数据。该算法是通过“反复试验”学习的。大多数临床应用无法承担收集实时临床数据的成本。例如,要了解脓毒症患者药物剂量的最佳临床决策,进行反复试验是不道德的,也将是耗时的。然而,策略梯度 RL 在其他领域仍然很流行,例如机器人控制和计算机棋盘游戏,这些领域的环境是一个可以承受试错的模拟器。
基于价值的强化学习
基于价值的强化学习在临床应用中很常见,我们将在第 3 节关于 DRL 的临床应用中看到更多例子。
Actor-Critic强化学习
Actor-critic RL 是一种 off-policy 算法,但替代版本也可以是一种 on-policy 算法。唯一的区别是在步骤 1 中,我们只收集一个轨迹并更新策略以从更新的策略生成新样本,而不是收集一批轨迹。同样,on-policy 不适合在实时临床应用中实施;因此,本文中讨论的应用之一(Wang 等人,2018 年)利用了 off-policy actor-critic RL 算法。
基于模型的强化学习
上面讨论的所有 RL 算法都是无模型 RL,在无模型 RL 中,我们假设我们不知道确切的转换函数 p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t, a_t) p(st+1∣st,at)。因此,鉴于当前状态和动作对,我们不知道真正的下一个状态是什么。无模型 RL 不会尝试明确学习转换函数,而是通过从环境中采样来绕过它。了解正确的转换功能或环境总是有帮助的。此外,在某些情况下,我们确实知道转换函数,例如我们自己设计规则的简单棋盘游戏。对于临床应用,大多数时候我们不确定确切的转换函数,但我们确实对环境的动力学有所了解。例如,临床医生一般都知道,给病人服用适当的药物剂量后,病人会逐渐从病态恢复到健康状态。即使我们不知道环境的全貌,我们仍然可以提出几个模型来估计真实的转换函数(环境)并从那里对其进行优化。它被称为基于模型的强化学习(Doya 等,2002)。我们可以使用多种模型来估计转移函数,例如高斯过程(GP)(Deisenroth 和 Rasmussen,2011;Rasmussen,2003)、DNN、高斯混合模型(GMM)(Chernova 和 Veloso,2007)等等。对于基于 DNN 模型的 RL,DNN 的输入是状态-动作对 ( s t , a t ) (s_t, a_t) (st,at),输出是 s t + 1 s_{t+1} st+1。 DNN 在第 2 步中为转移函数实现。与作为环境模型的 DNN 相比,GP 的数据效率非常高。 GP 可以使用很少的数据样本对下一个状态进行合理的预测。它在临床环境中很有用,因为大多数临床应用都存在数据不足问题。但是,GP 的局限性在于,当实际过渡函数不平滑时,它会遇到麻烦。此外,如果样本数量庞大且在高维空间中,GP 可能会很慢。它与 DNN 正好相反,其中 DNN 的样本数越大,一般预测越准确。因此,在输入状态为医学图像(非常高维)的临床上下文中,DNN 将比 GP 更适合基于模型的 RL。
强化学习的其他扩展
- 分层强化学习
当学习任务很庞大,并且我们在 RL 中看到了几个不同的状态-动作空间和几个次优策略时,对子空间进行排序并尝试获得全局空间的最优策略是很直观的。分层 RL(Kulkarni 等人,2016 年)通常包含两级结构。较低级别就像我们在一般 RL 算法中训练的策略一样,试图建议给定的动作 ( s t , a t ) (s_t, a_t) (st,at)。同时,存在一个更高级别的网络,其中“元策略”训练选择将这些较低级别策略中的哪些应用于轨迹。与随机启动的策略相比,分层 RL 具有学习更快全局最优策略的优势,并且它将从过去任务中学到的知识从较低级别的策略中转移。在临床环境中,由于人类交互的复杂行为,状态-动作空间可能很大。因此,应用分层强化学习是临床应用的一个非常自然的选择。然而,分层 RL 的架构训练起来更复杂,不恰当的迁移学习会导致“负迁移”(Pan 和 Yang,2010),其中最终策略不一定比低级别策略更好。 - 循环强化学习
马尔可夫决策过程的一个基本限制假设是马尔可夫性质(对 MDP 的完全观察),这在现实世界问题中很少得到满足。在医疗应用中,不太可能测量患者的完整临床状态。它被称为部分可观察马尔可夫决策过程 (POMDP) 问题 (Kaelbling et al., 1998)。 POMDP 有一个 4 元组 ( S , A , R , O ) (S, A, R, O) (S,A,R,O),其中 O O O 是观测值。经典 DQN 仅在观察反映潜在状态时才有用。(Hausknecht 和 Stone,2015)。 Hausknecht 和 Stone (2015) 提出了对 DQN 网络的扩展来处理 POMDP 问题,其中 DQN 的第一个完全连接层被替换为长短期记忆 (LSTM) (Hochreiter 和 Schmidhuber,1997)。这种新的 RL 算法称为深度循环 Q 网络 (DRQN)(Hausknecht 和 Stone,2015 年)。他们的算法表明,它可以通过时间成功地整合信息,并且可以在标准 Atari 游戏上复制 DQNâĂŹs 的性能,并为游戏屏幕设置 POMDP。 - 逆强化学习
为了学习临床应用中的大部分标准 RL 算法,我们会手工设计奖励函数,但我们不知道真正的奖励是什么。如果错误指定,这种奖励设计非常容易受到影响。逆 RL 是一种算法,我们可以从专家演示中推断出正确的奖励函数,而无需手动对奖励进行编程。(Ghavamzadeh 等人,2015 年;Abbeel 和 Ng,2004 年;Ng 等人,2000 年)逆向 RL 的替代方案是直接从专家的行为中学习它们,这通常是指模仿学习(Schaal,1999)。然而,模仿学习的一个限制是专家可能具有不同的能力并且容易不完美(Wang et al., 2018);向专家学习可能只会导致次优政策。因此,通常在逆 RL 中,我们会在动态模型中获得状态-动作空间和次优策略。逆 RL 的目标是恢复正确的奖励函数。然后我们可以使用学习到的奖励函数来获得比次优策略更好的新策略。奖励可以通过 DNN 学习,其中输入是由次优策略 π # {\pi}^{\#} π# 产生的状态-动作对 ( s , a ) (s, a) (s,a),然后 DNN 的输出是奖励 r ϕ ( s , a ) r_{\phi}(s, a) rϕ(s,a),其中 ϕ \phi ϕ 是我们将通过反向传播学习的 DNN 参数。稍后在我们获得 r ϕ ( s , a ) r_{\phi}(s, a) rϕ(s,a) 后,我们可以使用新的奖励函数来规划更好的策略,并希望是最优策略 π ∗ {\pi}^∗ π∗。在临床背景下,重要的是要推理临床医生正在努力实现的目标以及他们认为必不可少的内容。
临床应用的深度强化学习
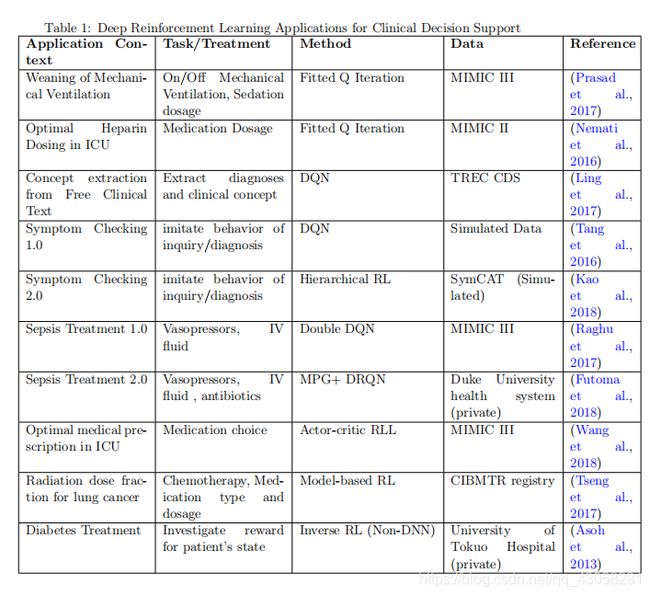
- 最近的研究(Prasad 等人,2017;Nemati 等人,2016 年;Tseng 等人,2017 年)表明,DRL 可用于为具有不同类型数据源的各种应用提供治疗建议和临床决策支持 ,包括电子病历、在线疾病数据库和遗传数据等。 应用包括药物/液体选择、急性或慢性疾病患者的剂量、机械通气的设置和持续时间,以及根据临床记录构建临床主题。 表 1 总结了本次调查中讨论的所有临床应用论文,特别强调了 DRL 方法的不同子类型和不同的临床问题。 正如前面部分所讨论的,策略梯度 RL 是一种不适合大多数临床应用的在线算法。 因此,基于价值的强化学习算法在临床应用中很受欢迎。
- 对于本节中的每个应用程序,我们将研究作者使用的 RL 算法、基于上下文的 MDP ( S , A , R ) (S,A,R) (S,A,R)的公式,最后是 RL 的性能。 我们首先讨论使用基于价值的 RL 的应用,然后是演员-评论家 RL、基于模型的 RL、分层 RL、循环 RL,最后是逆 RL。 对于基于值的强化学习,我们根据基于值的强化学习算法的子类型进一步划分应用,包括拟合 Q 迭代、DQN 和双 DQN。
基于价值的强化学习
拟合 Q 迭代
- 机械通气的撤机
- 重症监护室的患者从机械通气 (MV) 中撤机通常是随意且低效的。在这方面,Prasad 等人。 (2017) 使用离策略拟合 Q 迭代 (FQI) 算法来确定 MV 管理的 ICU 策略,他们旨在开发一种决策支持工具,该工具可以利用数据丰富的 ICU 设置中的可用患者信息来提醒临床医生患者已准备好开始撤机,并推荐个性化治疗方案。他们使用 MIMIC-III 数据库从 8182 名接受有创通气超过 24 小时的独特成年患者中提取了 8860 例入院病例。
- 它们包括患者的人口统计学特征、既往状况、合并症和随时间变化的生命体征等特征。他们使用高斯过程 (GP) 对实验室测量值和生命体征进行预处理,以估算缺失值;这可以确保更精确的政策估计。状态 s t s_t st 是一个 32 维的特征向量。动作被设计为二维向量,第一维是开/关 MV,第二维是四种不同水平的镇静剂量。每种状态下的奖励 r t r_t rt 包括进入通气时间和生理稳定性,而奖励会随着生命体征稳定和成功拔管而增加,但会惩罚不良事件(重新插管)和额外的呼吸机小时。与宾夕法尼亚大学医院 HUP 实施的实际政策相比,他们学到的政策与实际政策的 85% 相匹配。
- ICU 中的最佳肝素剂量
- 某些药物管理不善会不必要地延长住院时间,从而推高成本,并使患者处于危险之中。普通肝素 (UH) 是此类药物的一个例子,过量服用会导致出血风险增加,而服用不足会导致血栓形成风险增加。鉴于临床治疗的顺序性,RL 特别适用于药物剂量问题。Nemati等人。 (2016) 训练了一个 RL 药物给药代理,以学习一种给药策略,该策略使患者在其治疗性活化部分凝血活酶时间 (aPTT) 内停留的总时间比例最大化。他们使用 MIMIC-II 数据库提取了 4470 名在 ICU 住院期间接受静脉注射肝素的患者,时间窗口为 48 小时。变量包括人口统计、实验室测量和严重程度评分(格拉斯哥昏迷评分(GCS)、每日顺序器官衰竭评估(SOFA)评分)。使用特征构建状态并通过判别隐马尔可夫模型(DHMM)(Kapadia,1998)估计。而离散动作是使用来自六个分位数间隔的离散肝素值,而奖励是根据 aPPT 反馈设计的。根据反馈,决定增加、减少或维持肝素剂量,直到下一次 aPTT 测量。 r t = 2 1 + e − ( a P T T t − 60 ) − 2 1 + e − ( a P T T t − 100 ) − 1 r_t = \frac{2}{1+e^{-(aPTT_t-60)}} - \frac{2}{1+e^{-(aPTT_t-100)}} -1 rt=1+e−(aPTTt−60)2−1+e−(aPTTt−100)2−1.。当患者的 aPTT 值在治疗窗内时,该函数分配的最大奖励为 1,随着与治疗窗的距离增加,该值迅速减少至最小奖励 -1。
- 通过比较临床医生和训练有素的 RL 代理的累积奖励来测试最佳策略的性能。平均而言,随着时间的推移,RL 算法通过遵循代理的建议,产生了最佳的长期性能。
Deep Q Network
- 从免费临床文本中提取临床概念
- 从免费的临床文本中提取相关的临床概念是诊断推理的关键第一步。Ling et all. (2017) 提出使用 DQN 从外部证据中学习临床概念(维基百科:体征和症状部分和 MayoClinic:症状部分)。他们使用 TREC CDS 数据集(Simpson et al., 2014)进行实验。该数据集包含 30 个主题,其中每个主题都是描述患者诊断情况的医学自由文本。 MetaMap(Aronson,2006)从 TREC CD5 和外部文章中提取了临床概念。状态包含两个向量:当前的临床概念,以及来自外部文章的候选概念:两个向量之间越相似,状态值就越高。动作空间是离散的,包括接受或拒绝候选概念的动作。奖励的设计方式是,当候选概念比患者诊断的当前概念更相关时,奖励会很高。训练 DQN 以优化衡量候选临床概念准确性的奖励函数。他们在 TREC CDS 数据集上的初步实验证明了 DQN 在各种基于非强化学习的基线上的有效性。
- 症状检查 1.0
- 为了便于自我诊断,Tang 等人 (2016) 提出了症状检查系统。症状检查员首先询问有关患者状况的一系列问题。然后,患者将根据问题提供一系列答案。然后症状检查员试图根据问答进行诊断。Tang等人,提出了一个基于 RL 的集成模型来训练这个症状检查器。他们实现了 11 个 DQN 模型,而每个模型代表人体的一个解剖部位,如头部、颈部、手臂等。这些模型相互独立训练。对于每个解剖模型,状态 s 是基于症状的单热编码。 (即,如果症状是头痛,那么只有代表头部的解剖模型会有 s = 1,而其他模型会有 s = 0)。动作是离散的,有两种类型:询问和诊断。如果最大 Q 值对应于查询操作,则症状检查器将继续询问下一个问题。如果最大 Q 值对应于诊断动作。症状检查器将给出诊断并终止。奖励被设计为标量。当代理可以通过有限数量的查询正确预测疾病时,它就会获得奖励。他们将 DQN 算法应用于模拟的疾病数据集,结果表明症状检查器可以模仿医生的询问和诊断行为。
Double DQN
- 脓毒症治疗 1.0
- Raghu等人(2017)。 是最早直接讨论将 DRL 应用于医疗保健问题的人之一。 他们使用 MIMIC-III 数据集的 Sepsis 子集,并选择将动作空间定义为由血管加压药和静脉输液组成。 他们将药物剂量分为四个箱,由不同数量的每种药物组成。 Q 值在实践中经常被高估,导致错误的预测和糟糕的政策。 因此,作者用双 DQN 解决了这个问题(Wang 等,2015)。 他们还采用了对决深度 Q 网络来分离价值流和优势流,其中价值代表当前状态的质量,优势代表所选行动的质量。 奖赏功能是基于测量器官衰竭的 SOFA 评分的临床动机。 他们证明,使用连续状态空间建模,发现的策略可以将医院的患者死亡率降低 1.8% 到 3.6%。
Actor-critic强化学习
- ICU最佳医疗处方
- Wang等人 (2018) 采用 Actor-critic RL 算法来为各种疾病的患者寻找最佳的医疗处方。他们对 MIMIC-III 数据库进行了实验,并提取了 22,865 名录取。用于状态构建的功能包括演示图形、生命体征、实验室结果等。动作空间是 180 个不同的 ATC 代码。Wang等人,不仅仅是实现了经典的演员评论强化学习。相反,他们将强化学习与演员网络中的监督学习 (SL) 结合起来。目标函数 J ( θ ) J(\theta) J(θ) 被评估为方程中 RL 和 SL 目标函数的线性组合: J ( θ ) = ( 1 − ϵ ) J R L ( θ ) + ϵ ( − J S L ( θ ) ) J(θ) = (1-\epsilon)J_{RL}(\theta) + \epsilon(-J_{SL}(\theta)) J(θ)=(1−ϵ)JRL(θ)+ϵ(−JSL(θ)) , 其中 ϵ \epsilon ϵ是一个范围从 0 到 1 的超参数,它用于平衡 RL 和 SL。 J R L ( ϵ ) J_{RL}(\epsilon) JRL(ϵ) 在 actor-network 中是客观的,而 J S L ( ϵ ) J_{SL}(\epsilon) JSL(ϵ) 被评估为预测治疗和医生给的处方之间的交叉熵损失。
- 他们将梯度上升应用于目标函数 w.r.t. ϵ \epsilon ϵ 在 actor-network 中,并尝试了不同的 RL-SL 平衡值。此外,他们还结合了一个 LSTM 网络来提高部分观察到的 MDP (POMDP) 的性能,状态 s s s 被用 c t = f ( o 1 , o 2 , . . . , o t ) c_t = f(o_1, o_2, ...,o_t) ct=f(o1,o2,...,ot)总结整个历史观察所取代, c t c_t ct 被用作演员和评论网络的状态。 他们的实验表明,所提出的网络可以自动检测良好的药物治疗。
基于模型的强化学习
- 肺癌的辐射剂量分数
- Tseng等人 (2017) 实施了基于模型的 RL,为接受放疗的肺癌患者训练剂量递增策略。他们在 RL 设计中包括了 114 名患者,并首先训练了一个 DNN 来估计转换函数 p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t , a_t) p(st+1∣st,at)。 DNN 模型的损失函数旨在最小化估计轨迹的 Q 值期望值与观察值之间的差异。在构建过渡函数之后,Tseng 等人。应用 DQN 来学习胸部照射剂量的最佳策略,在局部控制 (LC) 和辐射诱发的肺炎 (RP) 风险之间进行权衡。对网络的奖励被设计为鼓励改进 LC 和试图抑制 RP 之间的权衡。 DQN 状态定义为 9 个特征的组合,包括细胞因子、PET 放射组学和剂量特征。该作用被设计为每分数的剂量。
- 由于构建转移函数需要大量数据。作者在转换函数中的 DNN 中实现了 drop-off 以避免过度拟合。另一方面,作者实施了生成对抗网络 (GAN)(Goodfellow 等人,2014 年)来模拟更多数据以缓解数据不足问题。来自 GAN 的模拟数据也被馈送到转换函数 DNN 进行训练。所提出的(基于模型的 RL)网络显示出一个有希望的结果,与临床医生相比,它可以建议类似的治疗剂量。
分层强化学习
- 症状检查 2.0
- Kao 等人(2018)的主要思想是模仿一组具有不同专业知识的医生共同诊断患者。由于患者一次只能接受一位医生的询问,因此需要一个元策略来指定医生依次向患者询问。元策略来自更高级别的网络。在每一步,元策略负责指定一个解剖部分模型来执行疾病预测的症状查询。
- 在 Kao 等人的论文中,第一层级是主代理 M M M。主 M M M 拥有其动作空间 A M A_M AM 和策略 π M {\pi}_M πM。在这个级别中,动作空间 A M A_M AM 等于 P P P,即解剖部位的集合。在步骤 t t t,主代理进入状态 s t s_t st,并根据其策略 π M {\pi}_M πM 从 A M A_M AM 中选择一个动作 a M t a_{M_t} aMt。层次结构的第二层由解剖模型 m p m_p mp 组成。如果主人执行 a M a^M aM,则任务将委托给解剖模型 m p = m a M m_p = m_{a^M} mp=maM 。一旦选择了模型 m p m_p mp,则根据 m p m_p mp 的策略在 a t ∈ A a_t \in A at∈A 处执行实际动作,表示为 π m p {\pi}_{m_p} πmp。
- 基于这种结构,Kao 等人,使用来自 SymCAT 症状疾病数据库的模拟数据训练在线症状检查器,用于健康相关疾病的自我诊断。 它是 Symptom Checking 1.0 的改进版本,Kao 等人,在 Symptom Checking 1.0 的解剖模型之上添加了另一层 DQN 作为主代理。 解剖模型和主模型都应用 DQN 来选择最大化 Q 值的动作。 他们的结果表明,与传统系统相比,所提出的分层强化学习算法显着提高了症状检查的准确性。
循环强化学习
- 脓毒症治疗 2.0
- Futoma 等人 (2018)提出了对 DRQN 架构的新扩展,使用多输出高斯过程来训练代理以学习脓毒症患者的最佳治疗方法。他们从杜克大学健康系统的私人数据库中收集了 9,255 名败血症患者及其 165 项特征(包括人口统计学、纵向生理变量、药物治疗等)的数据,并在 30 天内进行了随访。操作是离散值,由 3 种常见的脓毒症患者治疗组成:抗生素、血管加压药和静脉输液。奖励是稀疏编码的。每个非终止时间点的奖励为 0。如果患者存活,则在轨迹结束时奖励为 +10; 如果病人死亡奖励为-10 。他们研究了在 DQN 架构中用 LSTM 层替换全连接神经网络层的效果。脓毒症治疗的优化政策可以将患者死亡率从 13.3% 的总体基线死亡率降低 8.2%。
逆强化学习
- 糖尿病治疗
- 在之前的论文中,奖励函数是通过启发式来近似的。但是,无法验证奖励函数的适当性。在最近关于 RL 的研究中,有人提出逆 RL 来从专家的行为数据中估计他们的奖励函数。已经有一些论文关注逆 RL(Ng 等人,2000 年;Abbeel 和 Ng,2004 年)。然而,据我们所知,还没有任何论文实现了基于 DNN 的逆 RL 算法用于临床决策支持。对于基于非 DNN 的逆 RL,Asoh(2013) 在贝叶斯框架中实现了逆 RL,并使用马尔可夫链蒙特卡罗采样(Ghavamzadeh 等,2015)在临床环境中学习奖励函数。他们应用逆 RL 来学习具有统一先验的糖尿病治疗的奖励函数。药物处方数据是东京大学医院的私有数据。状态是离散的,定义为糖尿病的严重程度(“正常”、“中”、“重度”)。他们使用 MCMC 采样并将 3 个状态的奖励推导出为 r = ( 0.01 , 0.98 , 0.01 ) r = (0.01, 0.98, 0.01) r=(0.01,0.98,0.01)。奖励显示“中度”糖尿病患者的价值最高。这似乎与目前的临床理解相矛盾,即奖励应该对“正常”水平的糖尿病患者具有最高价值。Asoh等人,解释说,他们数据库中 65% 的糖尿病患者已经处于“中等”状态。因此,让患者处于“中等”状态可能是临床医生的最大努力。
- 尽管很少有临床应用实现逆 RL,但我们相信逆 RL 是一个有价值的话题,它将有利于临床环境中的应用。我们不仅通过模仿专家的行为来优化策略,而且我们还非常热衷于训练策略,使其能够自动找出临床医生认为重要的治疗方法。
如何选择强化学习算法
- 这个问题没有唯一的答案。 RL 算法的选择将取决于实际应用。 以下是要考虑的权衡和假设列表:
- 样本效率:样本效率是指需要多少样本才能使算法收敛。 如果算法是on-policy,比如policy gradient RL,那么它需要更多的样本。 相比之下,基于值的 RL 和基于模型的 RL 是 off-policy 算法,因此训练所需的样本更少。 Actor-critic RL 算法介于基于值的 RL 和策略梯度 RL 之间。 鉴于不同的样本效率,这并不意味着我们应该总是选择需要较少样本的那个。 对于容易生成样本的特定应用程序(即症状检查器 1.0 使用模拟器生成数据),模型训练的挂钟时间可能比所需的样本数量更重要。 在这种情况下,on-policy RL 算法可能是首选,因为它们通常比 off-policy RL 算法收敛速度更快。
- 收敛:策略梯度对目标函数进行梯度上升,保证收敛。 基于值的 RL 最小化了拟合的“贝尔曼误差”,但在最坏的情况下,不能保证在非线性情况下收敛到任何东西。 而对于基于模型的强化学习算法,模型最小化拟合误差,保证模型收敛。 然而,更好的模型并不等同于更好的策略。
- Episodic/无限视界:Episodic意味着状态-动作轨迹有一个终点。 例如,在疾病症状检查器应用程序中,代理不断搜索症状,当代理发现疾病时,事件就结束了。 情节通常由策略梯度方法假设,也由一些基于模型的 RL 方法假设。 无限视界意味着轨迹没有明确的终点。 轨迹的时间步长可以达到无穷大,但总会有一些点,状态动作对的分布保持稳定,不再变化。 我们将其称为平稳分布。 我们在本文中讨论的大多数应用都是情节性(Episodic)的,并且有明确的终点(即死亡率、疾病诊断)。 Episodic假设通常由纯策略梯度 RL 和一些基于模型的 RL 算法假设。 而我们观察到基于值的 RL 算法也适用于本文中的许多临床应用。
- 完全观察/部分观察 MDP: 当完全观察 MDP 时,可以应用所有主要的 RL 算法。而对于部分观察到的 MDP,一种可能的解决方案是使用循环 RL,例如基于 LSTM 的 DRQN 算法,将所有历史观察聚合为置信状态。实时的,临床上大部分应用都是POMDP;我们只能通过患者的生理特征来表示他们的状态。对于在 POMDP 中工作的方法,除了 RNN 之外,还广泛使用了保持置信状态的方法。信念状态是基于历史不完整和嘈杂观察的潜在状态的后验分布。 McAllister 和 Rasmussen (2017) 说明了一种特殊情况,其中部分可观察性是由于未观察状态上的加性高斯白噪声造成的。然后可以使用信念来过滤嘈杂的观察结果。Igl等人 (2018) 提出了一种深度变分强化学习 (DVRL) 算法,该算法使用 DNN 从嘈杂的观察中直接输出置信状态。他们展示了他们的算法在推断实际信念状态方面优于循环强化学习。
挑战和补救措施
- 从有限的观察数据中学习
- Deep RL 在临床环境中的应用与 Atari 游戏的情况大不相同,在 Atari 游戏中,可以多次重复游戏并播放所有可能的场景,以允许 Deep RL 代理学习最佳策略。 在临床环境中,Deep RL 代理需要从收集的一组有限数据和干预变化中学习。 它被称为 POMDP 问题。 因此,对于临床应用,RL 代理学习到的改进策略往往不是最优策略。 如上一节所述,这个问题可以通过使用诸如 LSTM(Futoma 等人,2018 年)之类的循环结构或通过使用 DNN(Igl 等人,2018 年)推断和维护置信状态来解决。
- 状态动作的定义,临床应用的奖励空间
- 在临床环境中找到状态、动作和奖励功能的适当表示具有挑战性(Futoma 等,2018)。 需要定义奖励函数以平衡短期改进和长期成功之间的权衡。 以ICU脓毒症患者为例。 血压的周期性改善可能不会导致患者预后的改善。 然而,如果我们只关注患者的结果(存活或死亡)作为奖励,这将导致很长的学习序列,而没有任何对智能体的反馈。 虽然好消息是一些 RL 算法,例如逆 RL,我们不需要手动设计奖励。 可以使用 DNN 对其进行近似,我们甚至可以训练比手工制作的奖励更接近实际奖励的奖励。
- 性能基准测试
- 在其他领域,例如视频游戏,DQN 在 Atari 游戏上的成功实现引起了该领域研究的极大兴趣 Mnih 等人。 (2013)。 例如,DeepMind 将演员-评论家 RL 应用于他们的视频游戏“星际争霸 II”(Alghanem 等人,2018 年)。 微软为研究人员开发了一个开源环境,用于测试他们的视频游戏“马尔默”(Johnson 等人,2016)。 现在,所有这些成功的实现都成为 RL 在视频游戏中的任何新应用的基准。 但是,在医疗保健领域,由于缺乏许多成功的应用程序,因此没有基准测试。 我们观察到大多数现有的 RL 医疗保健应用程序使用了 MIMIC EHR 数据库 Johnson 等人(2016a)。 因此,我们计划使用 MIMIC 数据建立一套基准,以将深度强化学习应用于 ICU 的临床决策支持。
- 探索/开发
- RL 的基本困境是探索与开发。如果智能体知道采取某些行动会带来良好的回报,那么智能体如何决定是尝试尝试新行为来发现具有更高回报的行为(探索)还是继续做目前已知的最好的事情(开发)。探索意味着做我们知道会产生最高回报的事情,而探索意味着做我们以前没有做过的事情,但希望得到更高的回报。由于伦理和治疗安全方面的考虑,探索在临床环境中可能具有挑战性。探索开发平衡的一种范例是使用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 搜索来探索概率为 ϵ ∈ [ 0 , 1 ] \epsilon \in [0, 1] ϵ∈[0,1] 的随机动作。 ϵ \epsilon ϵ的值越高,智能体在探索任意动作时就越“开放”。选择探索或开发的替代方法包括乐观探索(Auer 等人,2002 年)、汤普森抽样(Chapelle 和 Li,2011 年)和信息增益(Mohamed 和 Rezende,2015 年;Houthooft 等人,2016 年)。
- 数据缺陷和数据质量
- 几乎所有的深度学习模型在医疗保健应用中都存在数据不足的问题。 尽管存在可用的公共数据库,但较小的医疗机构通常缺乏足够的数据来依靠其本地数据库来拟合良好的深度学习模型。 可能的解决方案包括使用基于 GAN 的模型从相似分布中生成数据(Tseng 等人,2017 年),或使用迁移学习(Haarnoja 等人,2017 年)从更大的数据集预训练 DNN 模型,然后将其应用于较小的医院/机构临床数据。
- 几乎所有的深度学习模型在医疗保健应用中都存在数据不足的问题。 尽管存在可用的公共数据库,但较小的医疗机构通常缺乏足够的数据来依靠其本地数据库来拟合良好的深度学习模型。 可能的解决方案包括使用基于 GAN 的模型从相似分布中生成数据(Tseng 等人,2017 年),或使用迁移学习(Haarnoja 等人,2017 年)从更大的数据集预训练 DNN 模型,然后将其应用于较小的医院/机构临床数据。