【JAVA企业级开发】还在使用Netflix已经停止运维的Zuul网关么?看完这篇文章让你掌握Spring官方推荐的Zuul的替代品,第二代分布式微服务网关组件Gateway以及服务I/O,多线程原理
这里写目录标题
- 一级目录
-
- 二级目录
-
- 三级目录
- 一API网关
- 二Zuul
-
- 1问:
- 2问:
- 3问:
- 4问:
- 5问:
- 6问:
- 三网关选择,为什么淘汰Zuul
-
- 1Spring Cloud Gateway与Zuul的区别
- 2特别提醒:Spring Cloud Finchley版本中,即使你引入了spring-cloud-starter-netflix-zuul,也不是2.0版本的zuul
- 四Spring Cloud Gateway
-
- 1.如何包括Spring Cloud Gateway
- 2创建Spring Cloud Gateway项目
-
- ①依赖
- ②配置,网上大部分采用 yml 配置,这里采用 properties配置网关
-
- 指定服务个性化配置
- 全局服务配置
- 3启动类
- 五 同步与异步,阻塞与非阻塞
-
- 1 I/O
- 2 线程
- 3 四种组合方式
- 六 IO和线程
一级目录
二级目录
三级目录
一API网关
API网关是一个服务器,是系统的唯一入口。从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部架构,为每个客户端提供一个定制的API。它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供REST/HTTP的访问API。
网关应当具备以下功能:
性能:API高可用,负载均衡,容错机制。
安全:权限身份认证、脱敏,流量清洗,后端签名(保证全链路可信调用),黑名单(非法调用的限制)。
日志:日志记录(spainid,traceid)一旦涉及分布式,全链路跟踪必不可少。
缓存:数据缓存。
监控:记录请求响应数据,api耗时分析,性能监控。
限流:流量控制,错峰流控,可以定义多种限流规则。
灰度:线上灰度部署,可以减小风险。
路由:动态路由规则。
目前,比较流行的网关有:Nginx 、 Kong 、Orange等等,还有微服务网关Zuul 、Spring Cloud Gateway等等
对于 API Gateway,常见的选型有基于 Openresty 的 Kong、基于 Go 的 Tyk 和基于 Java 的 Zuul。这三个选型本身没有什么明显的区别,主要还是看技术栈是否能满足快速应用和二次开发
二Zuul
Netflix宣布了通用API网关Zuul的架构转型。Zuul原本采用同步阻塞架构,转型后叫作Zuul2,采用异步非阻塞架构。Zuul2和Zuul1在架构方面的主要区别在于,Zuul2运行在异步非阻塞的框架上,比如Netty。Zuul1依赖多线程来支持吞吐量的增长,而Zuul 2使用的Netty框架依赖事件循环和回调函数。
这是负责这次转型的Netflix项目经理Mikey Cohen进行了采访。
1问:
你把Zuul 2的转型描述成了一个旅程,而且它看起来像是一个长途旅程,你能说一下这个旅程的动机和概况,以及为什么需要这么长时间吗?
Mikey Cohen答:
我们希望构建一个可以为持久连接设备横向扩展的系统,这就是转向Zuul 2的主要动机。8300多万用户,每个用户持有多个设备,在系统横向扩展方面,我们面临着一个巨大挑战。基于持久连接,我们可以实现推送,还可以支持从用户设备到云控制系统之间的双向通信。我们还可以使用推送通知取代从用户设备发出的轮询请求。轮询请求在用户设备访问微服务方面扮演了重要角色。使用推送可以降低通信成本,还能提升用户体验。除此之外,基于持久连接和推送机制可以开发出很多用户体验更好、更易于调试的功能特性。最后,我们会支持更多协议,比如websocket和HTTP/2。
实际上,这确实是一个旅程。如果我们在构建Zuul 2时脱离实际,那么它就不会是一个值得纪念的旅程。这次转型的复杂性是巨大的。运行在Zuul上的云网关是Netflix云服务的主要入口。我们支持超过1000种设备,这些设备在功能配置、使用限制方面也是千差万别。Zuul需要支持这些设备的各种古怪行为,并把它们规范化。例如,有些设备关心消息头的顺序,有些对消息头有大小限制,有些不支持块编码,而且它们的一些特性在Tomcat和Netty里的处理方式不一样。这个项目的一个巨大挑战是找出这些差异,并做到让它们兼容。大部分这类问题只有在真实环境里才会暴露出来。要想在不影响生产环境用户的情况下检测出这类问题,需要承担巨大的风险,同时对减小风险影响范围的工程技术来说也是一个巨大考验。一个失效就会让我们8300多万用户中的一部分人或所有人无法消费Netflix的内容。
更深入一点看我们的架构,网关的所有特性和平台基础架构需要运行在异步环境里。Netflix的所有平台基础架构,包括Zuul过滤器,都是基于同一个假设而构建的,那就是它们会被运行在阻塞式的环境里。跟请求相关的线程变量在我们的支持包和平台代码里无处不在。使用阻塞式I/O是这个平台的第二大特点。这些设计概念在异步非阻塞的架构里无法正常工作。识别出这些陷阱,并构建出基于异步非阻塞架构的可行方案是很耗费时间的,有时候会变得很困难。
作为Netflix网关的构成角色之一,尝试理解我们所看到的一切也是这个旅程的一部分。简单地说,这个角色主要负责路由、观察和规范化那些进入Netflix的请求。我们使用迂回的方式构建Zuul 2,我们先移除Zuul 1的大部分业务逻辑,再把新的逻辑填充进原先的系统。除了让Zuul 2在网关里的角色更加明确之外,也简化了阻塞式代码的迁移工作,因为我们移除了大量代码。
创建Zuul过滤器和过滤解析异步化也一直是这次转型的另一个重大挑战。正如博文里所讲的那样,在Zuul 2之前我们就做了这方面的工作,所以我们可以在Zuul 1和Zuul 2上运行之前创建的Zuul过滤器(异步代码可以在同步环境里运行,反之则不行)。这样我们就可以基于这些过滤器继续开发网关的其它功能特性。不过在迭代过程中还是会对Zuul过滤器接口进行修改,并把这些过滤器串联起来。我们使用RxJava来串联Zuul过滤器。通过对100多个Zuul过滤器进行串联,我们发现这真是一个重注细节、耗费时间的任务。
最后,我们使用几个迭代来构建可以让Zuul 2运行起来的框架。我们从使用早期版本的Netty转到使用RxNetty项目。在构建Zuul 2的过程中,我们发现有些地方仍需要Netty的核心功能,而RxNetty却把它们移除了,所以在这些地方我们仍然使用Netty。一路走来,伴随着学习和纠错,我们构建了一个越来越健壮的产品。
2问:
你在博客里提到,除了后端延迟、错误重试,多线程系统能够应对大部分场景。是否还有其它原因促使你转向新的架构?
Mikey Cohen答:
我们一度相信在CPU使用效率和弹性方面会得到大幅改进。在部分集群(不是全部)里,我们确实看到了效率方面的改进(10-25%),不过这似乎不值一提。未能准确估算网关CPU工作量,也未能准确判断那些CPU比异步NIO密集的场景,这些大概就是造成我们错误预期的原因。我相信,使用Zuul 2开源版本(在它发布之后)的人将要看到的性能方面的大幅度提升,这在很大程度上是因为我们在Netflix Zuul 2网关上所做的大部分工作都是跟Netflix整体架构相关的。很多人认为10-25%这样的性能提升已经是一个很大的收获。不过如果把所耗费的时间、资源,还有运营方面面临的挑战以及异步NIO系统引入的调式复杂性都考虑在内,那么在性能方面获得的提升跟所付出的工作量无法划上等号。这么说来,其它方面的成效,比如连接管理和推送通知,以及弹性的提升,对我们来说就更重要了。
我们期待在弹性方面有更大的提升。就像我在博客里提到的那样,我坚信它会变成现实,但天下没有免费的午餐。我们积极地采取各种措施来获得更多的弹性提升,比如减少实例化对象,记录异常信息,改变节流机制,重用连接,改进负载均衡算法等。
3问:
Zuul过滤器是Zuul的关键组成部分。这次转型的切入点就是这些过滤器,对吗?你能否描述一下过滤器的重构过程,同时为那些使用类似方式重构大型系统的开发者们提供一些建议吗?
Mikey Cohen答:
把网关的业务逻辑部分异步化是有远见的想法,从长远来看,它会为我们节省很多时间。我们没必要为了保持一致性而维护两套过滤器(Zuul 1一套,Zuul 2一套)。在构建Zuul 2之前,我们准备了超过6个月的时间,这着实是一个巨大的前期投入。我想很多团队会认为这是本末倒置,但我们有理由相信这样做对我们有很大好处。首先,过滤器的开发可以在同一个代码库上进行,这样可以保证业务逻辑的一致性。既然我们知道业务逻辑要保持一致,那么就可以把不一致的部分移除掉。最后,我们可以借助这样的一个非常有用的工具,从系统和运营的角度来比较Zuul 1和Zuul 2。
4问:
你有没有一些实战经验可以分享给开发者和架构师们,帮助他们完成从同步阻塞到异步非阻塞的架构转型?另外,RxNetty是一个什么样的框架,它在这次转型过程中起到多大的作用?
Mikey Cohen答:
在转向异步系统的过程中,我们打了很多场仗。它们相互交织在一起,有着相同的主题和模式。在一开始,我们发现了资源泄露的问题:ByteBuf、信号量、文件描述符等。这类罕见的极端情况在我们的系统里却大量出现。通常需要几天时间的调试才能找到问题的根源。产生问题的根源多种多样,不过大部分都跟错误事件丢失有关。在打仗过程中,我们构建了一些工具,并尝试把它们贡献出来。我们向Netty贡献了一个可插拔的资源泄露探测器,有了这个插件,就可以使用监控工具检测资源泄露。我们还总结了一些模式,并把它们分享出来,遵循这些模式可以帮助我们更快地解决问题。
我们打的这些仗不是相互孤立的。我们构建的测试框架止步于此,因为很多问题只有在生产环境里才会出现。生产环境有大规模的用户和真实的系统,会暴露出大量问题。变更会带来巨大风险,一旦网关崩溃,用户就无法使用系统。转型越快意味着经历得越多,不过对用户的影响也越大。相反,以保守的速度转型意味着经历是循序渐进的,对用户的影响也较小。所以,对Zuul 2来说,在高风险的快速转型和保守的转型之间,有着微妙的平衡关系。
5问:
你说自己有意避开测试基准。既然异步和非阻塞都跟性能相关,那么你能告诉我们一些整体性能改进的细节吗?
Mikey Cohen答:
关于Zuul 1和Zuul 2(阻塞和非阻塞)之间的性能比较问题,我想我们在连接扩展性能上取得了大幅度的改进,不过吞吐量的提升受到CPU密集型任务的限制。这些任务主要包括收集度量指标、记录日志、分析数据、加密和压缩。不过在把Zuul 2开源以后,我相信在移除了这些任务的实现版本上可以看到吞吐量的重大提升。
6问:
你能具体说一下Zuul 2的开源计划以及Zuul的路线图吗?
Mikey Cohen答:
我们一直在致力于Zuul 2的开源工作,并计划在今年年底发布。我们还计划增加一些新的功能,比如对websocket和HTTP/2的支持。从路线图来看,我们即将对外开放部分过滤器、路由工具和设计理念。把Netflix特定的逻辑梳理出去是这个工作的主要内容。既然我们开发了websocket和推送功能,我们也想把相关的经验和基础架构也开源出来。
Zuul 2文档还在准备当中。Zuul wiki上有Zuul的相关信息,它还告诉我们如何开始使用Zuul。
三网关选择,为什么淘汰Zuul
一方面因为Zuul1.0已经进入了维护阶段,而且是采用的是同步阻塞架构,而且Gateway是SpringCloud团队研发的, 是亲儿子产品,值得信赖。而且很多功能Zuul都没有用起来也非常的简单便捷。
Gateway是基于异步非阻塞模型上进行开发的,性能方面不需要担心。虽然Netflix早就发布 了最新的Zuul 2.x,但Spring Cloud貌似没有整合计划。而且Netflix相关组件都宣布进入维护期;不知前景如何?
多方面综合考虑Gateway是很理想的网关选择。
1Spring Cloud Gateway与Zuul的区别
在SpringCloud Finchley 正式版之前,Spring Cloud推荐的网关是Netflix提供的Zuul
1、Zuul1.x,是一个基于同步阻塞I/O的API, Gateway是基于异步非阻塞模型上进行开发的
2、Zuul 1.x基于Servlet 2. 5使用阻塞架构它不支持任何长连接(如WebSocket) Zuul的设计模式和Nginx较像,每次I/O操作都是从工作线程中选择一个执行, 请求线程被阻塞到工作线程完成,但是差别是Nginx用C++实现,Zuul 用Java实现,而JVM本身会有第一次加载较慢的情况,使得Zuul的性能相对较差。
3、Zuul 2.x理念更先进,想基于Netty非阻塞和支持长连接,但SpringCloud目前还没有整合。Zuul 2.x的性能较Zuul 1.x有较大提升在性能方面,根据官方提供的基准测试,Spring Cloud Gateway的RPS (每秒请求数)是Zuul的1. 6倍。
4、Spring Cloud Gateway建立在Spring Framework 5、Project Reactor和Spring Boot2之上,使用非阻塞API。
5、Spring Cloud Gateway 还支持WebSocket, 并且与Spring紧密集成拥有更好的开发体验
2特别提醒:Spring Cloud Finchley版本中,即使你引入了spring-cloud-starter-netflix-zuul,也不是2.0版本的zuul
org.springframework.cloud
spring-cloud-starter-netflix-zuul
四Spring Cloud Gateway
官网技术文档:
https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.3.RELEASE/reference/html/#glossary
该项目提供了一个在Spring生态系统之上构建的API网关,包括:Spring 5,Spring Boot 2和Project Reactor。Spring Cloud Gateway旨在提供一种简单而有效的方法来路由到API,并为它们提供跨领域的关注,例如:安全性,监视/指标和弹性。
pringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。在于高并发 非阻塞式通信的话就非常有优势了。
需要注意的事:
使用SpringCloud Gateway的时候必须开启 服务消费者的自注册!
因为 使用 gateway之后微服务的调用流程就变成
Gateway》》》》》》Eureka/nacos consumer》》》》》》Eureka/nacos Server》》》》Eureka/nacos Provider
如果消费者不开启自注册的话,gateway就调用不了消费者。
eureka.client.register-with-eureka=true

1.如何包括Spring Cloud Gateway
要将Spring Cloud Gateway包含在您的项目中,请使用启动器,其组ID为org.springframework.cloud,工件ID为spring-cloud-starter-gateway。有关使用当前Spring Cloud Release Train设置构建系统的详细信息,请参见Spring Cloud Project页面。
网关服务中,不能有 spring-boot-starter-web的依赖
如果包括启动器,但不希望启用网关,请设置spring.cloud.gateway.enabled=false。
Spring Cloud Gateway是基于Spring Boot 2.x,Spring WebFlux和Project Reactor 构建的。结果,当您使用Spring Cloud Gateway时,许多您熟悉的同步库(例如,Spring Data和Spring Security)和模式可能不适用。如果您不熟悉这些项目,建议您在使用Spring Cloud Gateway之前先阅读它们的文档以熟悉一些新概念。
Spring Cloud Gateway需要Spring Boot和Spring Webflux提供的Netty运行时。它不能在传统的Servlet容器中或作为WAR构建时使用。
2创建Spring Cloud Gateway项目
由于 Gateway也是作为独立微服务注册进 微服务集群的,所以我们在创建Spring Cloud Gateway项目,需要单独再创建一个moudle,作为微服务集群的一个独立的客户端。
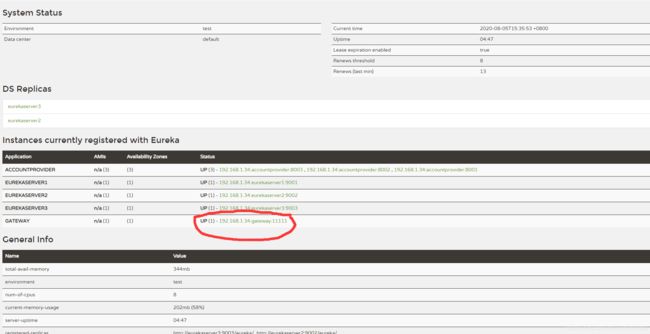
①依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>FengboSoft</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>eureka-gateway-global</artifactId>
<dependencies>
<!--gateway依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--springcloud的Finchley.SR2版本新的eureka客户端依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--eureka服务客户端启动配置依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<!--eureka的自我检查机制的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- <!–web组件–>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>-->
</dependencies>
</project>
请注意!网关服务中,因为是基于netty做服务通信的,依赖的是spring5.0的WebFlux,而不是不能存在spring-boot-starter-web的依赖,否则会报异常。
如果在Gateway的谓语中实现 Filter过滤器功能,那还还要单独依赖于 servlet依赖
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.0</version>
</dependency>
②配置,网上大部分采用 yml 配置,这里采用 properties配置网关
Route(路由):路由是构建网关的基本模块,它由ID, 目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
Predicate(断言):参考的是Java8的java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由
Filter(过滤) :指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
指定服务个性化配置
#应用名称
spring.application.name=gateway
#端口号
server.port=11111
#注意不要忘了/eureka/后缀,设置与eureka-server的交互地址
eureka.client.service-url.defaultZone= http://eurekaserver1:9001/eureka/,http://eurekaserver2:9002/eureka/,http://eurekaserver3:9003/eureka/
#eureka的健康检查机制开关
eureka.client.healthcheck.enabled=true
#默认为false,如果设置为True,则对全部服务起作用,就不用对单独服务配置,如果需要对单独服务进行配置,则需配置成默认值
#设置服务与发现结合,这样可以采用服务名的路由策略
spring.cloud.gateway.discovery.locator.enabled=true
#服务路由名小写开启小写验证,默认feign根据服务名查找都是用的全大写
spring.cloud.gateway.discovery.locator.lower-case-service-id=true
#设置路由id,个性话配置服务调用网关
#spring.cloud.gateway.routes[0].id=zero
#设置路由的uri,uri以lb://开头(lb代表从注册中心获取服务)
#spring.cloud.gateway.routes[0].uri=http://lb:accountprivader
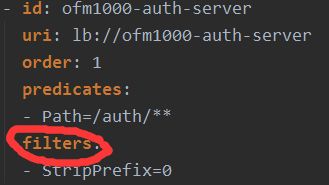
#设置路由断言(必须配置),代理servicerId为auth-service的/auth/路径
#spring.cloud.gateway.routes[0].predicates[0]=Path=/gateway/**
#springcloud的配置中心开关,SpringCloud默认启动的时候是会先加载bootstrap.properties或bootstrap.yml配置文件,如果没有的话,则会远程从http://localhost:8888获取配置,然后才会加载到application.yml,properties文件。
spring.cloud.config.enabled=false
或者以配置类的形式也可以
package fengbo.config;
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Created by @author LiuChunhang on 2020/8/5.
*//*
@Configuration
public class RoutesConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes().route(predicateSpec ->
predicateSpec.path("/gateway/**").uri("lb://accountprovider").id("zero")
).build();
}
}
全局服务配置
说完了直接配置路由的方式,我们来说说不配置的方式也能转发,有用过Zuul的同学肯定都知道,Zuul默认会为所有服务都进行转发操作,只需要在访问路径上指定要访问的服务即可,通过这种方式就不用为每个服务都去配置转发规则,当新加了服务的时候,不用去配置路由规则和重启网关。
在Spring Cloud Gateway中当然也有这样的功能,只需要通过配置即可开启,配置如下:
spring.cloud.gateway.discovery.locator.enabled=true
开启之后我们就可以通过地址去访问服务了,格式如下:
http://网关地址/服务名称(大写)/**
http://gateway:11111/ACCOUNTPROVIDER/account/login
这个大写的名称还是有很大的影响,如果我们从Zull升级到Spring Cloud Gateway的话意味着请求地址有改变,或者重新配置每个服务的路由地址,通过源码我发现可以做到兼容处理,再增加一个配置即可:
spring.cloud.gateway.discovery.locator.lowerCaseServiceId=true
配置完成之后我们就可以通过小写的服务名称进行访问了,如下:
http://网关地址/消费者服务名称(小写)/**
http://gateway:11111/accountconsumer/account/login

3启动类
网关模块的启动类的消费者模块的启动类基本上是一样的,还是使用三个最基本且必不可少的注解。
@SpringBootApplication
@EnableEurekaClient/@EnableDiscoveryClient
package fengbo;
import org.springframework.boot.Banner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
/**
* Created by @author LiuChunhang on 2020/8/4.
*/
@SpringBootApplication
@EnableEurekaClient
public class Gateway {
public static void main(String[] args) {
SpringApplication springApplication = new SpringApplication(Gateway.class);
springApplication.setBannerMode(Banner.Mode.OFF);
springApplication.run(args);
}
}
五 同步与异步,阻塞与非阻塞
我们知道 Zuul是基于同步阻塞 通信的,Gateway是基于 异步非阻塞的,那什么是 同步与异步,阻塞与非阻塞呢?
1 I/O
同步和异步IO的概念:
同步是用户线程发起I/O请求后需要等待或者轮询内核I/O操作完成后才能继续执行
异步是用户线程发起I/O请求后仍需要继续执行,当内核I/O操作完成后会通知用户线程,或者调用用户线程注册的回调函数
阻塞和非阻塞IO的概念:
阻塞是指I/O操作需要彻底完成后才能返回用户空间
非阻塞是指I/O操作被调用后立即返回一个状态值,无需等I/O操作彻底完成
2 线程
1同步与异步(线程间调用)#
同步与异步是对应于调用者与被调用者,它们是线程之间的关系,两个线程之间要么是同步的,要么是异步的
同步操作时,调用者需要等待被调用者返回结果,才会进行下一步操作
而异步则相反,调用者不需要等待被调用者返回调用,即可进行下一步操作,被调用者通常依靠事件、
回调等机制来通知调用者结果
2阻塞与非阻塞(线程内调用)#
阻塞与非阻塞是对同一个线程来说的,在某个时刻,线程要么处于阻塞,要么处于非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态:
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
3 四种组合方式
同步阻塞方式:
发送方发送请求之后一直等待响应。
接收方处理请求时进行的IO操作如果不能马上等到返回结果,就一直等到返回结果后,才响应发送方,期间不能进行其他工作。
同步非阻塞方式:
发送方发送请求之后,一直等待响应。
接受方处理请求时进行的IO操作如果不能马上的得到结果,就立即返回,取做其他事情。
但是由于没有得到请求处理结果,不响应发送方,发送方一直等待。
当IO操作完成以后,将完成状态和结果通知接收方,接收方再响应发送方,发送方才进入下一次请求过程。(实际不应用)
异步阻塞方式:
发送方向接收方请求后,不等待响应,可以继续其他工作。
接收方处理请求时进行IO操作如果不能马上得到结果,就一直等到返回结果后,才响应发送方,期间不能进行其他操作。 (实际不应用)
异步非阻塞方式:
发送方向接收方请求后,不等待响应,可以继续其他工作。
接收方处理请求时进行IO操作如果不能马上得到结果,也不等待,而是马上返回去做其他事情。
当IO操作完成以后,将完成状态和结果通知接收方,接收方再响应发送方。(效率最高)
六 IO和线程
计算密集型 vs. IO密集型
是否采用多任务(也就是多进程/线程)的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(按照这个我理解的IO就是指把内容从硬盘上读到内存的过程,或者是从网络上接收信息到本机内存的过程的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。