朴素贝叶斯分类器
基本知识
1、假设各个特征之间强(朴素)独立,即样本每个特征与其他特征都不相关(独立推不相关)
2、思想基础:对于待分类项,该项在哪个条件下出现的概率最大,则认为此待分类项属于该类别(如y1 = 0.2 y2 = 0.11 y3=0.5,咱们认为该项属于y3)
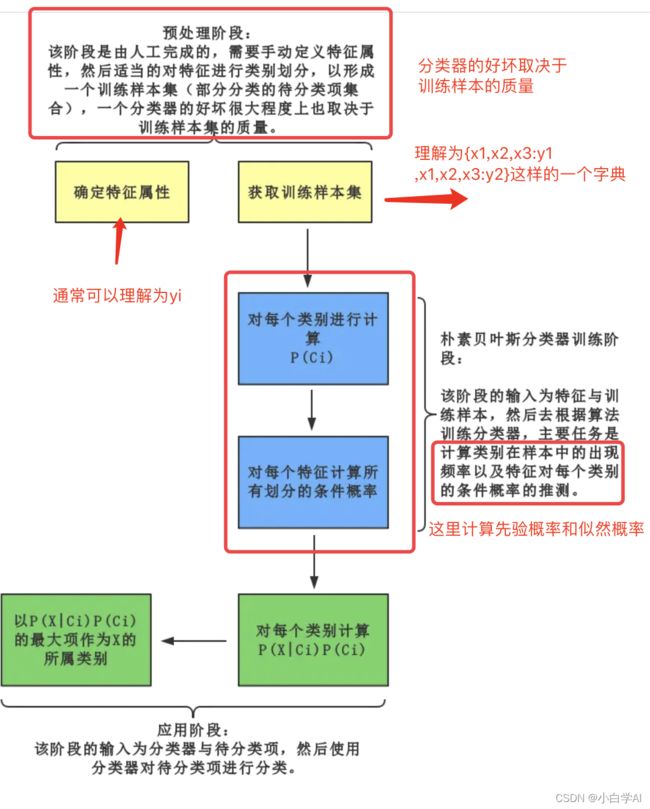
3、算法流程图

4、具体概率计算(需要用到算法流程图的信息)
- 找到已知分类的集合,即训练样本集
- 计算各个类别下各个特征属性的条件概率(如下图所示,有所省略)

![]()
- 若各个特征属性是条件独立,则有以下公式(应该可以懂吧!很简单!)

- 又因为计算后验概率时,所有分母(下面的数字)都是常数,所以都不考虑,因此得到以下公式 (利用了独立的性质)
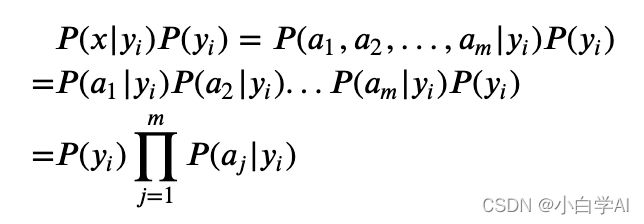
5、算法流程图
朴素贝叶斯手写数字识别
背景介绍:MNIST是手写体数据集,包含各种0-9的图像,每幅手写体图像的大小为 28×28 ,共有 784 个像素点,可记为一个 784 维的向量,每个 784 维向量对应着一个标签
预备知识:MNIST 训练集和测试集、BernoulliNB().fit(images,labels)函数来训练、predict来预测、score来计算正确率
代码部分:
1、导入相关的库和MNIST数据集
#忽略出现的warning
import warnings
warnings.filterwarnings("ignore")
#导入numpy库
import numpy as np
# tensorflow库中的mnist数据集
import tensorflow as tf
# mnist在tf.keras.datasets里面
mnist = tf.keras.datasets.mnist
# sklearn 库中的BernoulliNB
# 这里的BernoulliNB已经在sklearn当中分装好了
from sklearn.naive_bayes import BernoulliNB
# 绘图工具库plt
import matplotlib.pyplot as plt2、读取MNIST训练集和测试集
print("读取数据中 ...")
# 利用mnist中的load_data()方法载入数据
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 将28✖️28图像数据变形为一维的784位的向量
# len(train_images)表示行的长度
train_images = train_images.reshape(len(train_images),784)
test_images = test_images.reshape(len(test_images),784)
print('读取完毕!')3、自定义plot_images方法,将图片可视化
def plot_images(imgs):
# 选择可视化样本的数量
sample_num = min(9, len(imgs))
# 绘制区域
img_figure = plt.figure(1)
# 设置图片的长和宽
img_figure.set_figwidth(5)
img_figure.set_figheight(5)
# 利用for循环,在画布中添加9个小画布
# 可视化前九张图片
for index in range(0, sample_num):
ax = plt.subplot(3, 3, index + 1)
# 利用ax.imshow方法可视化
ax.imshow(imgs[index].reshape(28, 28), cmap='gray')
# 不显示网格
ax.grid(False)
plt.margins(0, 0)
plt.show()
plot_images(train_images) 
4、训练朴素贝叶斯分类器
print("初始化并训练贝叶斯模型...")
# 定义 朴素贝叶斯模型
classifier_BNB = BernoulliNB()
# 训练模型
classifier_BNB.fit(train_images,train_labels)
print('训练完成!')5、利用训练好的分类器来识别测试集的图片
print("测试训练好的贝叶斯模型...")
# 分类器在测试集上的预测值
test_predict_BNB = classifier_BNB.predict(test_images)
print("测试完成!")6、利用score函数,评价预测测试集的正确率
# 计算准确率
accuracy = classifier_BNB.score(test_images, test_labels)
print('贝叶斯分类模型在测试集上的准确率为 :',accuracy)
7、比较0-9不同数字识别的准确率!!!!!!!最重要的部分
# 记录每个类别的样本的个数,例如 {0:100} 即 数字为 0 的图片有 100 张
class_num = {}
# 每个类别预测为 0-9 类别的个数,
predict_num = []
# 每个类别预测的准确率
class_accuracy = {}
for i in range(10):
# 找到测试集类别是 i 的下标
class_is_i_index = np.where(test_labels == i)[0]
# 统计类别是 i 的个数,利用len函数统计class_is_i_index的总长度
class_num[i] = len(class_is_i_index)
# 统计类别 i 预测为 0-9 各个类别的个数
# sum(test_predict_BNB[class_is_i_index] == e) for e in range(10)])
# 通过已知的类别是 i 的下标,判断类别是 i 的下标是否对应类别为i,利用==判断是否预测正确
# 判断类别是 i 的下标是否对应类别为i,则对应输出True,将预测错误的类别也做统计
# 利用sum计算出预测正确的数量
# 这里的输出是一个矩阵
predict_num.append(
[sum(test_predict_BNB[class_is_i_index] == e) for e in range(10)])
# 统计类别 i 预测的准确率
# round函数表示保留3位
class_accuracy[i] = round(predict_num[i][i] / class_num[i], 3) * 100
print("数字 %s 的样本个数:%4s,预测正确的个数:%4s,准确率:%.4s%%" % (
i, class_num[i], predict_num[i][i] , class_accuracy[i]))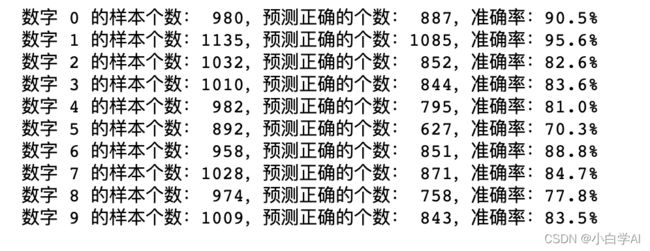
8、绘制热力图(这里随便看看)
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(rc={'figure.figsize': (12, 8)}, font_scale=1.5)
sns.set_style('whitegrid',{'font.sans-serif':['simhei','sans-serif']})
np.random.seed(0)
uniform_data = predict_num
ax = sns.heatmap(uniform_data, cmap='YlGnBu', vmin=0, vmax=150)
ax.set_xlabel('真实值')
ax.set_ylabel('预测值')
plt.show()
通过热力图,我们看到 3 经常被错认为 5 和 8, 4 和 9 经常互相错认。
9、查看真实标签为9,但是预测为4的错认的照片
def get_imgs(images, true_labels, predict_labels, true_label,
predict_label):
#一些传入参数的含义
"""
从全部图片中按真实标签和预测标签筛选出图片
:param images: 一组图片
:param true_labels: 每张图片的标签
:param predict_labels: 模型预测的每张图片的标签
:param true_label: 希望取得的图片的真实标签
:param predict_label: 希望取得的图片的预测标签
:return:
"""
# 所有类别为 true_label 的样本的 index 值
# 获得真实标签的索引
true_label_index = set(np.where(true_labels == true_label)[0])
# 所有预测类别为 predict_label 的样本的 index 值
# 获得预测标签的索引
predict_label_index = set(np.where(predict_labels == predict_label)[0])
# 取交集,即为真实类别为 true_label, 预测结果为 predict_label 的样本的 index 值
res = list(true_label_index & predict_label_index)
return images[res]
#获得真实为9 预测为4的图像
imgs = get_imgs(test_images, test_labels, test_predict_BNB, 9, 4)
plot_images(imgs)