基于Titanic数据集的数据分析处理及乘客生还率预测全流程教程
基于Titanic数据集的数据分析处理及乘客生还率预测全流程教程
-
- 0.项目介绍
- 1.使用数据集
- 2.数据的基本统计分析
- 3.数据的属性探查
- 4.数据预处理
- 5.数据的相关性分析
- 6.特征工程
- 7.数据模型构建
- 8.交叉检验
- 9.特征选择
- 10.模型过拟合分析
- 11.项目总结
- 12.参考文献
0.项目介绍
kaggle比赛中有一经典Titanic泰坦尼克号数据集,本数据集非常适合新手作为数据分析入门研究例程,本项目主要对Titanic数据集整个分析建模过程进行详细描述,帮助数据分析入门的同学快速了解整个数据分析建模的全流程解决方案和思考的过程。数据集要使用我提供的,网上很多的数据集经过了一些处理,可能无法复现整个流程。
1.使用数据集
数据集下载地址:
我用夸克网盘分享了「Kaggle_Titanic」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/ab45007990ba
提取码:14Kn
2.数据的基本统计分析
数据分析的第一步便是了解数据集属性,查看数据的基本情况(数据量、缺失值、异常值等)。
import pandas as pd
import numpy as np
# 训练数据
data_train=pd.read_csv("datasets/Kaggle_Titanic/train.csv")
# 测试数据
data_test = pd.read_csv("datasets/Kaggle_Titanic/test.csv")
# 查看各列属性的数据量和缺失情况
print(data_train.info())
print(data_test.info())
# 查看各列属性的基本统计信息,
print(data_train.describe())
print(data_test.describe())
训练数据集的基本情况:有11列属性,分别是乘客的ID、获救情况,乘客等级、姓名、性别、年龄、堂兄弟妹个数、父母与小孩的个数、船票信息、票价、船舱、登船的港口;从其中我们获取到几点认知:
PassengerId(乘客ID),Name(姓名),Ticket(船票信息)存在唯一性,三类意义不大,可以考虑不加入后续的分析;
Survived(获救情况)变量为因变量,其值只有两类1或0,代表着获救或未获救;
Pclass(乘客等级),Sex(性别),Embarked(登船港口)是明显的类别型数据,而Age(年龄),SibSp(堂兄弟妹个数),Parch(父母与小孩的个数)则是隐性的类别型数据;Fare(票价)是数值型数据;Cabin(船舱)则为文本型数据;
Age(年龄),Cabin(船舱)和Embarked(登船港口)信息存在缺失数据。
而在测试数据集中,年龄、票价和船舱三类属性存在缺失值。
在对训练数据集和测试数据集进行基本统计分析时,我们重点关注标准差,最小值和最大值三个指标,标准差反映了数据的离散程度,最大和最小值一般可以看出数据是否有异常值。在这两组数据上,其它数据均无异常,而两组数据均存在票价为0的船票,考虑该类船票可能是优惠船票,且该属性上标准差也较大,数据属性探测时,需要通过箱线图查看一下异常值情况。
3.数据的属性探查
数据的属性探测是针对单个的属性探测其分布情况,一般可以通过绘制单个属性的分布图进行探查。
查看获救情况的分布:
#%%
import matplotlib.pyplot as plt
import seaborn
# 显示中文标题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 查看有多少人丧生,多少人获救
print(data_train['Survived'].value_counts())
输出:
0 549
1 342
Name: Survived, dtype: int64
分别看一下各属性的基本分布情况,首先我们对适合利用图形展示的属性,通过绘图的方式探查属性的分布,分类型和数值型数据非常适合绘图,所以这部分我们选择乘客等级、性别、年龄、票价和登船港口五类属性。
# 绘图
fig = plt.figure()
# 乘客等级分布
plt.subplot2grid((2, 3), (0, 0))
data_train['Pclass'].value_counts().plot(kind='bar')
plt.ylabel(u"人数")
plt.xlabel(u'乘客等级')
plt.title(u'乘客等级分布')
# 乘客性别分布
plt.subplot2grid((2, 3), (0, 1))
data_train['Sex'].value_counts().plot(kind='bar')
plt.ylabel(u"人数")
plt.xlabel(u'性别')
plt.title(u'乘客性别分布')
# 乘客的年龄分布
plt.subplot2grid((2, 3), (0, 2))
data_train['Age'].hist()
plt.xlabel(u'年龄')
plt.title(u'乘客年龄分布')
# 票价的分布
plt.subplot2grid((2, 3), (1, 0))
data_train['Fare'].hist()
plt.xlabel(u'票价')
plt.title(u'船票票价分布')
# 箱线图:票价的异常情况探查
plt.subplot2grid((2, 3), (1, 1))
data_train['Fare'].plot(kind='box')
plt.title(u'票价箱线图')
# 登船港口的分布情况
plt.subplot2grid((2, 3), (1, 2))
data_train['Embarked'].value_counts().plot(kind='bar')
plt.xlabel(u'登船口')
plt.title(u'登船口乘客量分布')
plt.show()
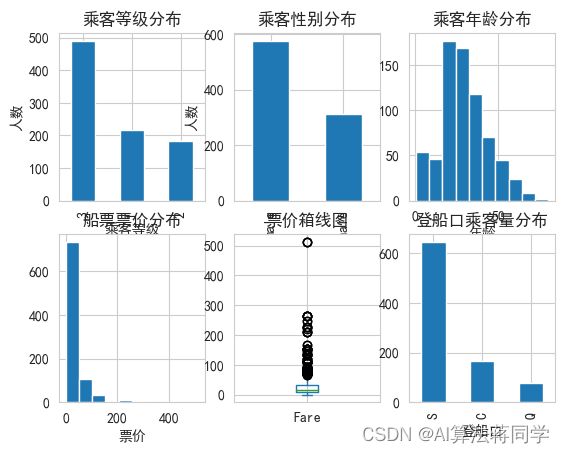
对于乘客等级、性别、登船口这类类别型的属性,从柱状图上探查各类的分布情况,而对于年龄和票价这类连续型的属性,我们可以选择利用直方图查看属性的分布。从乘客等级分布的柱状图上,我们得到三等乘客人数最多,1等和2等的乘客相对较少(等级顺序:1>2>3);在性别上,男性多于女性;在登船港口上,发现人数从高到低的港口分别是S>C>Q;看一下年龄的分布情况,我们发现20~30岁区间的乘客人数最多。
print(data_train[data_train['Fare'] == min(data_train['Fare'])]['Fare'].value_counts())
print(data_train[data_train['Fare'] == max(data_train['Fare'])]['Fare'].value_counts())
输出:
0.0 15
Name: Fare, dtype: int64
512.3292 3
Name: Fare, dtype: int64
在第一部分,我们怀疑票价属性存在异常值,并且从该属性的直方图和箱线图分布上,我们也发现数据存在极大和极小值,最小值为0的有15个记录,而最大值为512.3292的有3条记录。从绘制箱线图的结果发现,确实是很多数据存在异常,但是考虑到该数据反映的是票价,极端值确实存在可理解的情况,0可能是员工票或优惠票,极大值可能是VIP船舱的票价,所以数理层面上的异常并不能代表错误。
探查剩余属性的分布 首先是SibSp(堂兄弟妹个数)和Parch(父母与小孩的个数)两个属性,这两类属性也是类别型属性,只是类别较多,我们统计各类的乘客数量。
print(data_train['SibSp'].value_counts())
print(data_train['Parch'].value_counts())
0 608
1 209
2 28
4 18
3 16
8 7
5 5
Name: SibSp, dtype: int64
0 678
1 118
2 80
5 5
3 5
4 4
6 1
Name: Parch, dtype: int64
我们发现这两类属性在值为0和1时,乘客量较多。
其次是缺失值最严重的Cabin(船舱)属性,在上面的分析中我们已经发现这列属性仅有两百多条记录,只占总数据的1/4,而且这类属性为文本型数据,很难进行缺失值填充,在后续的建模分析中,我们暂时不考虑这列属性,但是我们依然可以探查这仅有的数据呈现怎样的分布。观察数据发现这些文本类似于我们的高铁票座位号信息,是有字母+数字构成,而字母代表了作为的位置,所以我们可以将字母取出,然后统计这些字母的分布。
data_train['level'] = data_train['Cabin'].str.extract(r'([A-Za-z])')
print(data_train['level'].value_counts())
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
Name: level, dtype: int64
从结果上,我们发现B/C/D/E区的乘客量较多,这必须结合泰坦尼克号船舱座位分布去查看,此处我们不做深究。
4.数据预处理
在第二部分的属性探查阶段,我们并未对数据做任何处理,而是从原始数据中探查数据本来的样子和问题,接下来,我们需要对数据中存在问题(缺失值,异常值)的数据做预处理。
因为我们在前面的分析中认为票价存在的异常值还是符合常规认知的,所以此处我们并不对票价异常值进行处理,而船舱数据缺失严重,不作为我们后续建模的考虑因素。所以我们将会对年龄和登录港口两属性的缺失值进行填充。
年龄缺失值填充 一般对缺失数据的填充有删除、固定值填充、均值/众数/中位数填充等方法,本项目数据集数据量较小,直接利用固定值填充的方式不合适,也无法反映这部分缺失数据的特性,所以我们也参考博客中的方法,利用随机森林算法,借助其他属性值,来预测缺失数据值。
from sklearn.ensemble import RandomForestRegressor
def set_missing_age(df):
# 把数值类型特征取出来,放入随机森林中进行训练
age_df = df[['Age','Fare','Parch','SibSp','Pclass']]
# 乘客分成已知年龄和未知年龄两个部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# 目标数据y
y = known_age[:,0]
# 特征属性数据x
x = known_age[:,1:]
# 利用随机森林进行拟合
rfr = RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(x,y)
# 利用训练的模型进行预测
predictedAges = rfr.predict(unknown_age[:,1::])
# 填补缺失的原始数据
df.loc[(df.Age.isnull()),'Age'] = predictedAges
return df
# 年龄缺失值填充
data_train = set_missing_age(data_train)
print(data_train)
SibSp Parch Ticket Fare Cabin Embarked level
0 1 0 A/5 21171 7.2500 NaN S NaN
1 1 0 PC 17599 71.2833 C85 C C
2 0 0 STON/O2. 3101282 7.9250 NaN S NaN
3 1 0 113803 53.1000 C123 S C
4 0 0 373450 8.0500 NaN S NaN
… … … … … … … …
886 0 0 211536 13.0000 NaN S NaN
887 0 0 112053 30.0000 B42 S B
888 1 2 W./C. 6607 23.4500 NaN S NaN
889 0 0 111369 30.0000 C148 C C
890 0 0 370376 7.7500 NaN Q NaN
[891 rows x 13 columns]
登陆港口缺失值填充
登陆港口属性缺失值仅有两条记录,数据量小,我们直接删除这两条记录。
data = data_train.drop(data_train[data_train.Embarked.isnull()].index)
print(data)
5.数据的相关性分析
数据的相关性分析可以探查属性间的相关性,查看属性是否存在冗余;另外通过探寻各属性和结果属性的关系,进而选择和结果相关性较大的属性,作为建模的重要特征,所以这一部分我们首先探测各属性间关系,然后再探测单个属性和结果之间的关系。
属性间相关性探测:
import seaborn
df = data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Survived']]
# 属性间相关系数
cor = df.corr()
print(cor)
# 属性间相关系数热力图
seaborn.heatmap(cor)
plt.show()
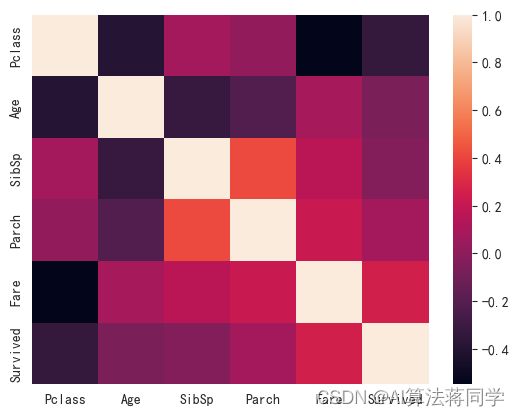
从相关系数方面,我们发现各属性和结果相关性都不大,而属性间也只有SibSp和Parch属性的相关性较高,其它属性间的相关性较低。我们认为相关性系数更适合分析数值型数据,而针对分类型数据,则不适合。所以,我们单独分析每一个属性和结果质检的关系。
单个属性和结果之间的相关性 首先,我们先对类别型属性进行分析(这里的类别型数据有等级、性别、登陆港口,还包括了年龄,SibSp和Parch这些隐型的数据
# 绘图
plt.figure(figsize=(10, 8), dpi=100)
# 乘客的等级和获救情况的关系, 从结果上发现,1和2等级的乘客获救率明显高于3等级的乘客
p1 = plt.subplot(221)
Pclass_0 = data.loc[data['Survived'] == 0, 'Pclass'].value_counts()
Pclass_1 = data.loc[data['Survived'] == 1, 'Pclass'].value_counts()
df_pclass = pd.DataFrame({u'获救':Pclass_1,u'未获救':Pclass_0})
df_pclass.plot(kind='bar', ax=p1)
plt.title(u'不同等级乘客的获救情况')
# 同样的方法,我们看一下性别和获救情况的关系,结果非常明显,女性比男性的获救率高
p2 = plt.subplot(222)
Survived_m = data.loc[data['Sex'] == 'male', 'Survived'].value_counts()
Survived_f = data.loc[data['Sex'] == 'female', 'Survived'].value_counts()
df_sex = pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df_sex.plot(kind='bar', stacked=True, ax=p2)
plt.title(u'不同性别乘客的获救情况')
# 年龄划分,划分的标准:0~10为儿童;10~60为成年人;60及以上为老年人
p3 = plt.subplot(223)
bins = [min(data['Age']), 10, 60, max(data['Age'])]
bins_label = ['10岁及以下', '10-60岁', '60岁以上']
data['Age_cut'] = pd.cut(data['Age'], bins=bins, labels=bins_label)
print(data['Age_cut'].value_counts())
# 再对数据进行统计,结果发现儿童的获救率明显高于成年人和老年人
Age_0 = data.loc[data['Survived'] == 0, 'Age_cut'].value_counts()
Age_1 = data.loc[data['Survived'] == 1, 'Age_cut'].value_counts()
df_age = pd.DataFrame({u'获救':Age_1, u'未获救':Age_0})
df_age.plot(kind='bar', ax=p3)
plt.title(u'不同年龄阶段乘客的获救情况')
# 登录港口和获救情况的关系
p4 = plt.subplot(224)
Embarked_0 = data.Embarked[data.Survived == 0].value_counts()
Embarked_1 = data.Embarked[data.Survived == 1].value_counts()
df_Embarked = pd.DataFrame({u'获救': Embarked_1, u'未获救': Embarked_0})
df_Embarked.plot(kind='bar', stacked=True, ax=p4)
plt.title(u'不同登陆港口乘客的获救情况')
plt.show()
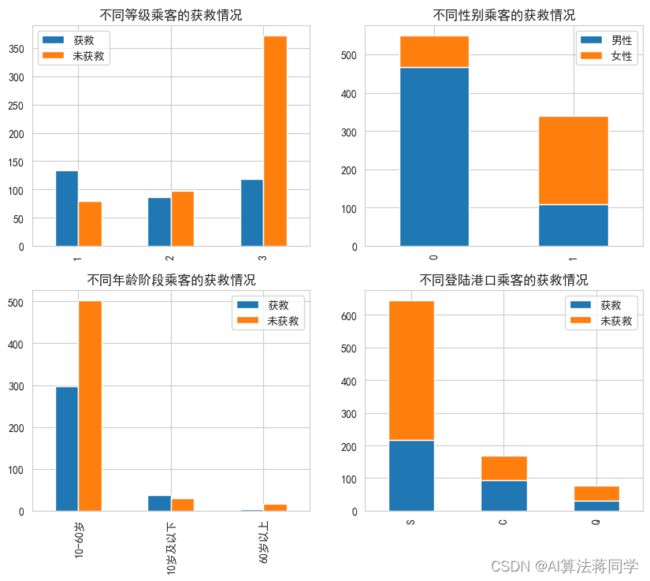
因为年龄是一个隐型的类别型属性,属性类别多,我们需要对其进行等级划分,这里划分了三个阶段,10岁以下代表儿童,10~60岁代表成年人,60岁以上代表老年人,进而转换成类别型数据。统计这四类类别型数据是否获救的数量,并绘制柱状图,从图中得的以下结论:等级高的乘客获救率高(1>2>3);女性获救率远大于男性;儿童的获救率高于成年人和老年人;C港的获救率大一些,而S港登船人数最多,这说明了这些属性对是否获救存在影响,是后续建模需要考虑的属性。
其次,针对类别较多的SibSp和Parch属性,我们直接统计各类的是否获救情况。
# 堂兄弟妹个数以及父母子女个数的获救情况统计
g1 = data.groupby(['SibSp', 'Survived'])
df_SibSp = pd.DataFrame(g1.count()['PassengerId'])
df_SibSp.rename(columns={'PassengerId':'count'}, inplace=True)
print(df_SibSp)
g2 = data.groupby(['Parch', 'Survived'])
df_Parch = pd.DataFrame(g2.count()['PassengerId'])
df_Parch.rename(columns={'PassengerId': 'count'}, inplace=True)
print(df_Parch)
count
SibSp Survived
0 0 398
1 208
1 0 97
1 112
2 0 15
1 13
3 0 12
1 4
4 0 15
1 3
5 0 5
8 0 7
count
Parch Survived
0 0 445
1 231
1 0 53
1 65
2 0 40
1 40
3 0 2
1 3
4 0 4
5 0 4
1 1
6 0 1
从结果中,我们发现,SibSp<3和Parch<3的情况下,获救率更高。
最后,我们再对数值型属性Fare的获救情况进行分析,因为是连续性数值,我们采用密度分布图的方式(因票价不能确定如何分段,我们不采用年龄属性的处理方法)。
从结果中,我们发现获救的绿色曲线比未获救的红色曲线在票价轴方向更靠近右侧,这说明票价高的获救情况要好于票价低的。
在单个属性探测时,我们分析票价属性时,发现其存在在数值层面异常的极大和极小值,现在我们单独查看这些极端值的获救情况。
print(data.loc[data['Fare'] == 0, 'Survived'].value_counts())
print(data.loc[data['Fare'] == max(data['Fare']), 'Survived'].value_counts())
0 14
1 1
Name: Survived, dtype: int64
1 3
Name: Survived, dtype: int64
结果发现,票价为0的15名乘客,仅有1人获救,而票价最高的三名乘客,全部获救,这说明了票价的高低对是否获救存在影响,同时也说明了这些数值层面的异常值并不是真实的异常值(当然,也可以探索一下票价极端值和其它属性的关系,比如等级)。
6.特征工程
特征工程是数据建模非常重要的一个环节,在这一环节中,一方面,我们需要基于前面的分析对数据做处理(归一化、降维等);另一方面,我们需要根据我们选择的模型要求,将数据处理成模型需要的样子(因子化、数据变换等)。特征选择是特征工程中又一步关键处理,这步处理贯穿于模型的构建-预测-分析全过程,是模型优化的重要步骤,需要不断迭代和测试。
在本项目中,因为最终的预测是二分类问题,所以我们初步选择逻辑回归模型进行预测,我们需要对属性中类别型的数据做因子化处理,而票价属性则相应的需要做归一化处理。
import sklearn.preprocessing as preprocessing
# 特征因子化
def set_numeralization(data):
# 针对定类性属性进行因子化,分别有Embarked,Sex,Pclass
dummies_Embarked = pd.get_dummies(data['Embarked'], prefix='Embarked')
dummies_Sex = pd.get_dummies(data['Sex'], prefix='Sex')
dummies_Pclass = pd.get_dummies(data['Pclass'], prefix='Pclass')
# 将新的属性拼合
df = pd.concat([data, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
# 将旧的属性剔除
df.drop(['Pclass', 'Sex', 'Embarked'], axis=1, inplace=True)
return df
# 特征归一化
def set_normalization(df):
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age'].values.reshape(-1,1))
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1,1),age_scale_param)
fare_scale_param = scaler.fit(df['Fare'].values.reshape(-1,1))
df['Fare_scaled'] = scaler.fit_transform(df['Fare'].values.reshape(-1,1),fare_scale_param)
return df
# 特征工程
data = set_numeralization(data)
data = set_normalization(data)
注:测试数据集经过数据探测也存在数据的缺失情况,其中年龄属性采用和训练数据集一样的处理进行填充,票价信息仅缺失一条,测试数据集不建议删除缺失数据,我们用常数0来代替;同样的,测试数据也要和训练数据一样做特征工程部分的处理。
7.数据模型构建
逻辑回归模型是一种基于线性回归的二分类算法,我们选择该模型进行建模。关于该模型的数学原理请参考如下链接。
from sklearn import linear_model
# 利用正则表达式取出需要的属性
train_df = data_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.values
test_df = data_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Embarked_.*|Sex_.*|Pclass_.*')
# 获取y
y = train_np[:,0]
# 获取自变量x
x = train_np[:,1:]
# 利用逻辑回归进行拟合,得到训练的模型
clf = linear_model.LogisticRegression(solver='liblinear',C=1.0,penalty='l2',tol=1e-6)
clf.fit(x,y)
# 对测试数据进行预测
predictions = clf.predict(test_df)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].values,'Survived':predictions.astype(np.int32)})
print(result.head())
# 模型中各属性的系数(用于分析各特征的贡献度)
feature_corr = pd.DataFrame({'columns':list(train_df.columns)[1:],'coef':list(clf.coef_.T)})
print(feature_corr)
PassengerId Survived
0 892 0
1 893 0
2 894 0
3 895 0
4 896 0
columns coef
0 SibSp [-0.1594196079516946]
1 Parch [0.28911975046852934]
利用逻辑回归模型,我们对数据做了初步的建模,因为没有真值,所以无法比较预测的精度。我们再来看一下各属性贡献度:
SibSp和Parch属性和结果呈负相关,且影响较小,我认为可能是这列数据类型太分散,应该做数据的分段; 登船港口属性中,Q和C与结果呈正相关,而S港口呈负相关,这和我们前面分析这列属性和获救结果得到的结论一致; 性别属性,女性和结果呈正相关,且相关性较高,男性则和结果呈很大的负相关,符合我们前面的分析; 乘客等级属性,1等和结果呈很高的正相关,3等呈很高的负相关,符合前面的分析; 年龄属性和结果呈现出负相关,说明年龄越大获救的可能性越低(这一点值得说明,中国的观念是尊老爱幼,而国外的观念则看重声明的价值,认为儿童和青壮年相对于老人对社会的贡献度越高),初次分析时这对我造成了误解,所以任何的分析项目得看实际的项目背景。但是在前面的分析中,我们发现儿童更容易获救,这说明该属性需要做分段处理; 票价属性呈现较小的正相关。 通过我们简单的逻辑回归模型的预测结果,我们发现现在无法评价模型的好坏,用来训练模型的部分属性和我们前期分析的结果不一致,这就引出构建一个优秀模型重要的两个环节:交叉验证和特征选择。
8.交叉检验
交叉验证是为了检验我们模型的好坏,我们利用sklearn中的模型交叉验证对训练数据进行检测,这里我们对模型分割5次,每次20%拿去检测,80%用于训练,输出每次的精度,和五次精度平均值。
from sklearn.model_selection import cross_val_score
train_df = data_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.values
# 获取y
y = train_np[:, 0]
# 获取自变量x
x = train_np[:, 1:]
# 利用逻辑回归进行拟合,得到训练的模型
clf = linear_model.LogisticRegression(solver='liblinear', C=1.0, penalty='l2', tol=1e-6)
clf.fit(x, y)
# 交叉检验
score = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print(score)
print(score.mean())
[0.61452514 0.61797753 0.62921348 0.62359551 0.61235955]
0.619534241416107
最终五次检测的平均精度约为0.7885,这是我们对我们的baseline模型的验证,作为我们后续模型优化的对比标准,接下来,我们根据6中属性的分析,再进一步对属性进行处理,并构建模型和验证。
9.特征选择
特征选择是特征工程和模型优化的重要部分,选择的过程贯穿于数据的整个分析和建模的过程,是一个不断迭代的过程。在此项目中,我们基于baseline模型分析出的问题,先对SibSp和Parch属性做进一步的分段处理,而在前面的分析中我们在数据归一化处理过程中,将年龄和票价数据缩放到(-1,1)的区间,我认为选择最大和最小值归一化更合理,所以对这两个属性重新处理,最后再验证模型。
# 对于SibSp属性,我们划分成0,1~2,3~8三个等级
data['SibSp_cut'] = 1
data.loc[data['SibSp'] == 0, 'SibSp_cut'] = 0
data.loc[data['SibSp'] >= 3, 'SibSp_cut'] = 2
# 对于Parch属性,我们划分成0,1~3,4~6三个等级
data['Parch_cut'] = 1
data.loc[data['Parch'] == 0, 'Parch_cut'] = 0
data.loc[data['Parch'] > 3, 'Parch_cut'] = 2
# 因子化处理
dummies_SibSp = pd.get_dummies(data['SibSp_cut'], prefix='SibSp')
dummies_Parch = pd.get_dummies(data['Parch_cut'], prefix='Parch')
data.drop(['SibSp_cut', 'Parch_cut'], axis=1, inplace=True)
# 数据归一化
transfer = preprocessing.MinMaxScaler(feature_range=[0, 1])
data['Age_scaled'] = transfer.fit_transform(data['Age'].values.reshape(-1, 1))
data['Fare_scaled'] = transfer.fit_transform(data['Fare'].values.reshape(-1, 1))
# 数据合并
df = pd.concat([data, dummies_SibSp, dummies_Parch], axis=1)
# 特征筛选
data_train = df.filter(regex='Survived|Age_.*|SibSp_.*|Parch_.*|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
# 模型的交叉检验
train_np = data_train.values
# 获取y
y = train_np[:, 0]
# 获取自变量x
x = train_np[:, 1:]
# 利用逻辑回归进行拟合,得到训练的模型
clf = linear_model.LogisticRegression(solver='liblinear', C=1.0, penalty='l2', tol=1e-6)
clf.fit(x, y)
feature_corr = pd.DataFrame({'columns': list(data_train.columns)[1:], 'coef': list(clf.coef_.T)})
print(feature_corr)
# 交叉检验
score = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print(score)
print(score.mean())
columns coef
0 Embarked_C [0.10629099416336898]
1 Embarked_Q [0.17907683683824227]
2 Embarked_S [-0.2558142800445464]
3 Sex_female [1.287669638317124]
4 Sex_male [-1.258116087360005]
5 Pclass_1 [1.0061926511143342]
6 Pclass_2 [0.04484426461693781]
7 Pclass_3 [-1.021483364774083]
8 Age_scaled [-2.1007144328346015]
9 Fare_scaled [0.3827749158987113]
10 SibSp_0 [0.6126674653149456]
11 SibSp_1 [0.6846228137253144]
12 SibSp_2 [-1.2677367280831495]
13 Parch_0 [0.314541262228494]
14 Parch_1 [0.595259392162106]
15 Parch_2 [-0.8802471034334667]
[0.79775281 0.81460674 0.79213483 0.80898876 0.8079096 ]
0.8042785501174381
经过我们的特征选择处理之后,首先,模型的验证精度相对于baseline有了明显的提升,其次是我们处理后的属性贡献度:
年龄属性经过极大极小值归一化处理之后,和获救结果呈负相关,且非常显著,这也和我们前面分析认知一致,即获救结果和生命值呈正相关;
同年龄属性,票价属性在新的归一化处理之后,相关性有所提高;
SibSp属性经过分段处理后,可以发现贡献度有了显著的变化,0和1等级(SibSp<3)和结果呈正相关,2等级(SibSp>2)和结果呈负相关,和我们前期分析结果一致;
Parch属性同SibSp属性,在经过新的归一化处理之后,贡献度变化显著,尤其是等级1(Parch在1~3之间),和结果有显著的正相关关系,2等级则呈显著的负相关关系。
这再次说明了特征选择对模型优化的重要性,但是为了得到优秀的训练模型,往往要经过多次选择和验证,同时也要结合我们前期的分析结果以及对项目背景的理解。
10.模型过拟合分析
通过特征选择,我们优化了模型,将模型的检验精度提高了一些,但是衡量一个模型的好坏不至是看模型的精度高低,因为检验数据和训练数据出自一份数据集,在检验数据上取得了好的精度,不代表在测试数据集上依然可以得到好的预测结果,这种情况我们称之为过拟合,所以针对得到的模型,我们还要检测其是否存在过拟合情况。而如何评断过拟合,则用到了learning curve,关于学习曲线的介绍和使用见如下链接。
from sklearn.model_selection import learning_curve
# 绘制学习曲线
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1.0, 20), verbose=0, plot=True):
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.gca().invert_yaxis()
plt.show()
# train_np = data_train.values
# 获取y
y = train_np[:, 0]
# 获取自变量x
X = train_np[:, 1:]
clf = linear_model.LogisticRegression(solver='liblinear', C=1.0, penalty='l2', tol=1e-6)
clf.fit(X, y)
plot_learning_curve(clf, u"学习曲线", X, y)

从模型的学习曲线上,训练数据集和交叉验证数据集的整体走势比较平滑,模型最终的精度稳定在0.8左右,说明我们的模型未出现过拟合和欠拟合的情况,模型合理。
11.项目总结
我们利用Titanic数据集做了一次完整的数据分析->数据建模全流程的处理,为大家提供了一套比较完整的分析建模思路。本次的分享重点在于介绍清楚每个环节,而实际应用中每个环节还有许多可以继续挖掘的点,这些内容就不在本次内容阐述了,后续我会专项系统讲解各环节的知识点。最后,我们再着重强调一下,在做数据分析和建模的过程中需要关注以下几点:
- 项目背景和数据属性理解非常重要,因为每个项目都有自己的背景,和需要关注的问题,且不同的认知和生活习惯往往会造成数据呈现不一样的结论,所以我们不能以自己主观理解去给数据下结论,而是要----从数据本身发现规律,因为数据是事实最有利的证据;
- 特征工程非常重要,模型的优越程度和特征的挖掘与处理程度有很大的关系,可以说,做好了特征工程,你的模型就完成了一大半。
后续。。。。我们还没有尝试使用其它模型来检测分类精度,下面的文章,我将会挑选其它分类模型来进行验证,比较不同模型之间的差异。
12.参考文献
1.https://zhuanlan.zhihu.com/p/342552186
2.https://link.zhihu.com/?target=https%3A//blog.csdn.net/han_xiaoyang/article/details/49797143