Pytorch学习笔记(17)———训练一个性别2分类网络
转载自https://www.jianshu.com/p/1ec6075c0ab6
性别识别是一个2分类问题,网上应该有不少的研究。比如商汤/旷世科技 早已经将人脸属性继承到SDK中,可以供API在线调用,还有针对Android, ios的SDK, 本人测试过,速度很精度都很不错。
简单起见,直接采用预训练模型微调的方式训练一个性别分类器。
网络模型选择
torchvision.models中集成了几个常见的网络模型,ResNet, AlexNet, VGG, DenseNet, SqueezeNet。 AlexNet和VGG模型文件都很大,AlexNet大约230M, VGG更大,下载特别慢,而且这么大的模型文件对于以后往移动平台移植很不利。
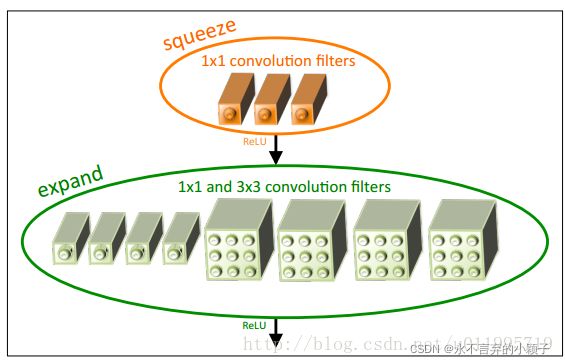
SqueezeNet有所了解,这是一个轻量化的网络,网络名称squeeze就是压缩的意思。作者文章介绍到SqueezeNet与AlexNet精度相当,模型参数大大降低。因此决定采用SqueezeNet进行实验,如果效果不错可以考虑Android端的移植。
SqueezeNet
SqueezeNet是一个轻量化的网络 ,模型文件比较小,大约4M多,相比AlexNet 230M,算是非常轻量化。

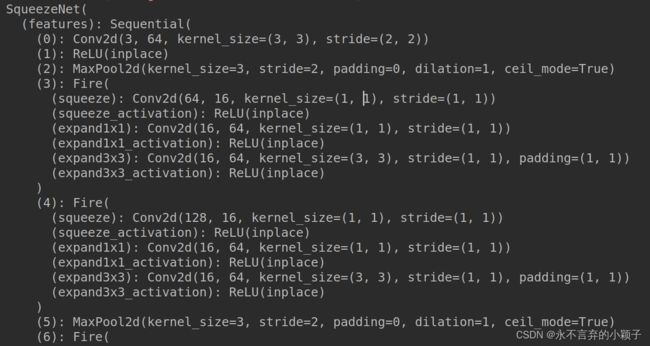
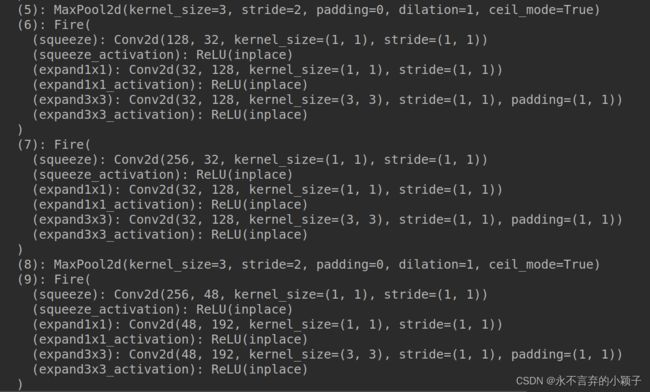
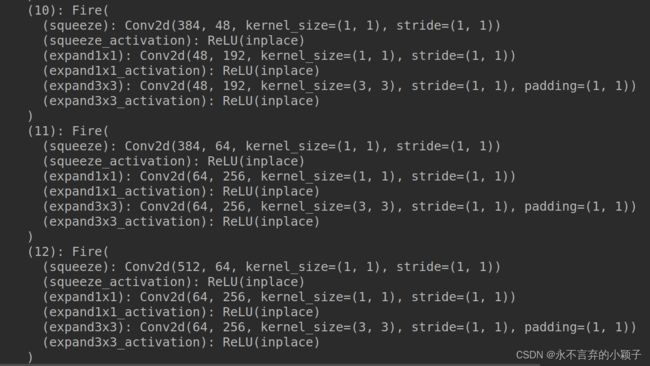
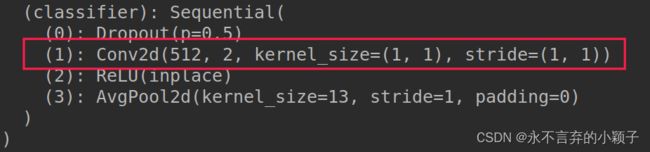
采用pytorch 打印出的SqueezeNet的网络结构。
数据集制作
UTKFace数据集进行训练
https://susanqq.github.io/UTKFace/


训练集,验证集,测试集划分
UTKFace数据需要从Google Drive下载,链接包含2个压缩包。 采用第一个压缩包crop_part1.tar.gz的数据,规模稍微小,先看看效果。训练:验证:测试 = 6:2:2
- 总共9780张图像
- 训练数据5000+
- 验证数据约2000
- 测试数据约2000
由于UTKFace数据的按照年龄排序的,因此在划分数据时候全部采用随机采样。
划分结果:

使用pytorch加载数据
- 继承
Dataset类, override__len()__,__getitem()__方法 - 采用
Dataloder包装,按照mini_batch方式读取
from torch.utils.data import Dataset
import torch
import torchvision.transforms as transforms
import PIL.Image as Image
import os
import numpy
import shutil
import random
class UTKFaceGenderDataset(Dataset):
def __init__(self, root, txt_file, transform=None, target_transform=None):
self.root = root
self.transform = transform
self.target_transform = target_transform
self.class_name = {0: 'male', 1: 'female'}
self.txt_file = txt_file
self.length = 0
self.images_name = []
f = open(txt_file, 'r')
assert f is not None
for i in f:
self.length += 1
self.images_name.append(i)
def __len__(self):
return self.length
def __getitem__(self, index):
image_name = self.images_name[index]
# if not os.path.isfile(os.path.join(self.root, image_name)):
# return None
image = Image.open(os.path.join(self.root, image_name).rstrip())
assert image is not None
label = int(image_name.split('_')[1])
image_transformed = image
label_transformed = label
if self.transform:
image_transformed = self.transform(image)
if self.target_transform:
label_transformed = self.target_transform(label)
return {'image': image_transformed, 'label': label_transformed}
DataLoader包装
# ---------------------------数据集--------------------------------------------------
batch_size = 8
data_root = '/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor()
])
train_dataset = dataset.UTKFaceGenderDataset(root=os.path.join(data_root, 'image'),
txt_file=os.path.join(data_root, 'train.txt'),
transform=transform)
print('train_dataset: {}'.format(len(train_dataset)))
train_dataloader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True, num_workers=4)
UTKFace数据分布
train set only
-
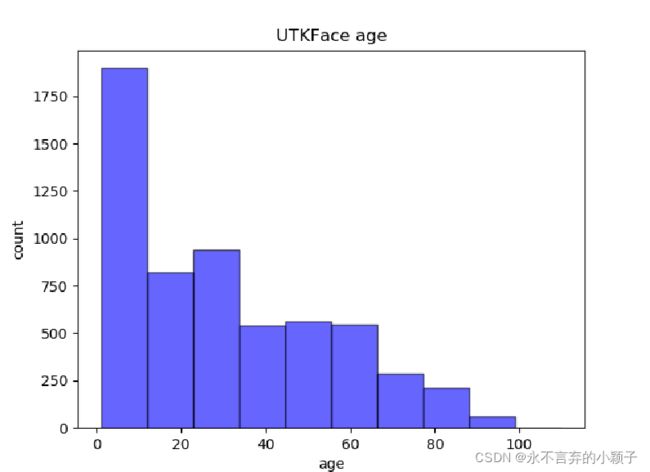
年龄分布
-
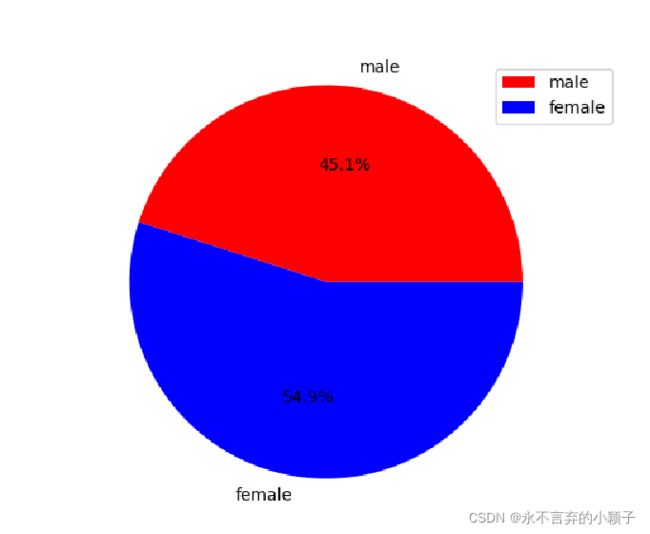
性别分布
-
人种肤色分布
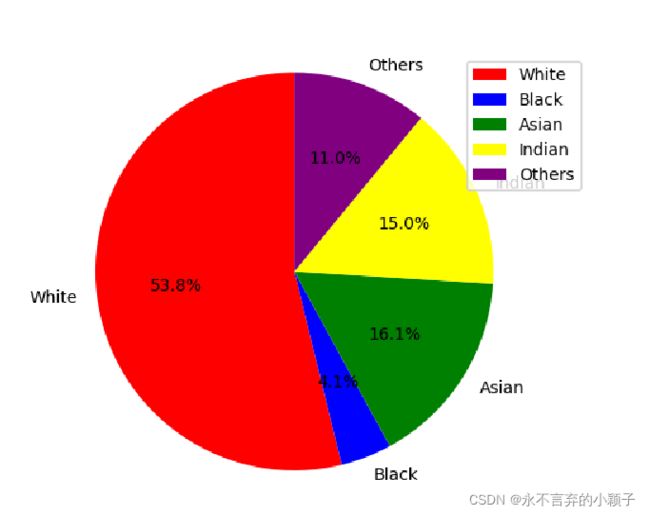
根据数据库的分布的分布情况可知,UTKFace男女性别分布基本平衡,其中欧美白种人占据的比例比较大,亚洲人占据的比例约16%,从年龄分布来看,0~10岁的比较多。因此直接用此数据库训练性别分类模型,可能对亚洲人识别不一定很好(猜测),作为实验,后续可以验证。 -
代码, 可视化数据分布:又重写写了一个UTKFaceDateset类,觉得之前的写法有不太好,容易造成BUG。
class UTKFaceDataset(Dataset):
def __init__(self, root, txt_file, transform=None, target_transform=None):
self.root = root
self.transform = transform
self.target_transform = target_transform
self.txt_file = txt_file
self.lines = []
f = open(self.txt_file, 'r')
for i in f:
self.lines.append(i)
def __len__(self):
return len(self.lines)
def __getitem__(self, index):
attrs = self.lines[index].split('_')
assert len(attrs) == 4
age = int(attrs[0])
gender = int(attrs[1])
race = int(attrs[2])
date_time = attrs[3].split('.')[0]
# [age] is an integer from 0 to 116, indicating the age
# gender] is either 0 (male) or 1 (female)
# [race] is an integer from 0 to 4, denoting White, Black,
# Asian, Indian, and Others (like Hispanic, Latino, Middle Eastern)
# [date&time] is in the format of yyyymmddHHMMSSFFF,
# showing the date and time an image was collected to UTKFace
assert age in range(0, 117)
assert gender in [0, 1]
assert race in [0, 1, 2, 3, 4]
label = {'age': age, 'gender': gender, 'race': race, 'data_time': date_time}
image_path = os.path.join(self.root, self.lines[index]).rstrip()
assert os.path.isfile(image_path)
image = Image.open(image_path).convert('RGB')
image_transformed = image
label_transformed = label
if self.transform:
image_transformed = self.transform(image)
if self.target_transform:
label_transformed['age'] = self.target_transform(label['age'])
label_transformed['gender'] = self.target_transform(label['gender'])
label_transformed['race'] = self.target_transform(label['race'])
return {'image': image_transformed, 'label': label_transformed}
import torch
import dataset
import matplotlib.pyplot as plt
import numpy as np
def main():
train_dataset = dataset.UTKFaceDataset(root='/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/image',
txt_file='/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/train.txt')
# 性别
gender_nums = {'male': 0, 'female': 0}
# 年龄段
age_nums = {'age0_10': 0, 'age10_20': 0, 'age20_30': 0, 'age30_40': 0,
'age40_50': 0, 'age50_60': 0, 'age60_70': 0, 'age70_80': 0,
'age80_90': 0, 'age90_100': 0, 'age100_120': 0}
age_hist = []
# 人种
race_nums = {'White': 0, 'Black': 0, 'Asian': 0, 'Indian': 0, 'Others': 0}
for i, sample in enumerate(train_dataset):
print(i, sample['label'])
age = sample['label']['age']
gender = sample['label']['gender']
race = sample['label']['race']
if gender == 0:
gender_nums['male'] += 1
else:
gender_nums['female'] += 1
if race == 0:
race_nums['White'] += 1
elif race == 1:
race_nums['Black'] += 1
elif race == 2:
race_nums['Asian'] += 1
elif race == 3:
race_nums['Indian'] += 1
else:
race_nums['Others'] += 1
age_hist.append(age)
if 0 <= age < 10:
age_nums['age0_10'] += 1
elif 10 <= age < 20:
age_nums['age10_20'] += 1
elif 20 <= age < 30:
age_nums['age20_30'] += 1
elif 30 <= age < 40:
age_nums['age30_40'] += 1
elif 40 <= age < 50:
age_nums['age40_50'] += 1
elif 50 <= age < 60:
age_nums['age50_60'] += 1
elif 60 <= age < 70:
age_nums['age60_70'] += 1
elif 70 <= age < 80:
age_nums['age70_80'] += 1
elif 80 <= age < 90:
age_nums['age80_90'] += 1
elif 90 <= age < 100:
age_nums['age90_100'] += 1
else:
age_nums['age100_120'] += 1
print(age_nums, gender_nums, race_nums)
# 画图
plt.figure('age')
plt.hist(age_hist, bins=10, facecolor='blue', edgecolor='black', alpha=0.6)
plt.title('UTKFace age')
plt.xlabel('age')
plt.ylabel('count')
plt.figure('gender')
plt.pie(x=[gender_nums['male'], gender_nums['female']], colors=['red', 'blue'], labels=['male', 'female'],
autopct='%1.1f%%', pctdistance=0.6)
plt.axis('equal')
plt.legend()
plt.figure('race')
plt.pie(x=[race_nums['White'], race_nums['Black'], race_nums['Asian'], race_nums['Indian'], race_nums['Others']],
colors=['red', 'blue', 'green', 'yellow', 'purple'],
labels=['White', 'Black', 'Asian', 'Indian', 'Others'],
labeldistance=1.1,
shadow=False,
startangle=90,
autopct='%1.1f%%', pctdistance=0.6)
plt.axis('equal')
plt.legend()
plt.show()
if __name__ == '__main__':
main()
训练
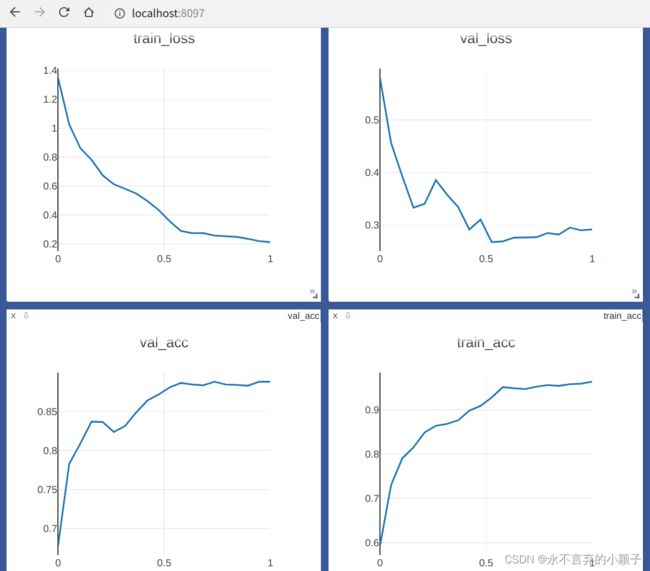
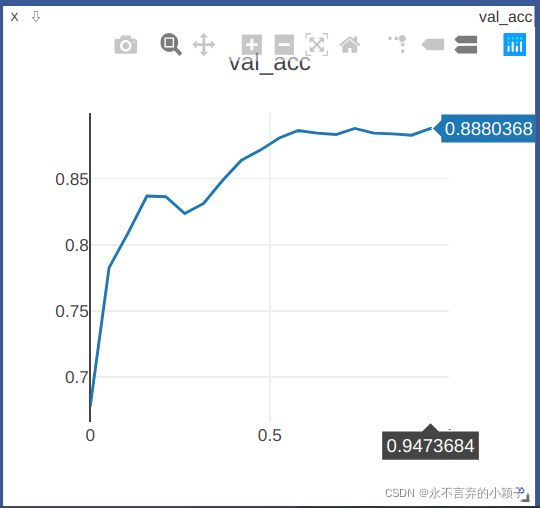
训练采用GPU,下面有部分的loss, Acc曲线。
测试
viz = visdom.Visdom(env='test')
GENDER = ['male', 'female']
for i, sample in enumerate(test_dataloader):
inputs, labels = sample['image'], sample['label']
outputs = model(inputs)
_, prediction = torch.max(outputs, 1)
correct += (labels == prediction).sum().item()
total += labels.size(0)
inputs = make_grid(inputs)
viz.image(inputs, opts=dict(title='{},{},{},{}'.format(GENDER[labels[0].item()],GENDER[labels[1].item()],GENDER[labels[2].item()],GENDER[labels[3].item()])))
![]()
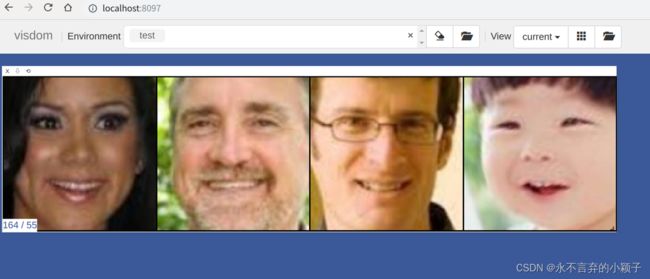



输出
完整工程
- 数据集
from torch.utils.data import Dataset
import torch
import torchvision.transforms as transforms
import PIL.Image as Image
import os
import numpy
import shutil
import random
class UTKFaceGenderDataset(Dataset):
def __init__(self, root, txt_file, transform=None, target_transform=None):
self.root = root
self.transform = transform
self.target_transform = target_transform
self.class_name = {0: 'male', 1: 'female'}
self.txt_file = txt_file
self.length = 0
self.images_name = []
f = open(txt_file, 'r')
assert f is not None
for i in f:
self.length += 1
self.images_name.append(i)
def __len__(self):
return self.length
def __getitem__(self, index):
image_name = self.images_name[index]
# if not os.path.isfile(os.path.join(self.root, image_name)):
# return None
image = Image.open(os.path.join(self.root, image_name).rstrip())
assert image is not None
label = int(image_name.split('_')[1])
image_transformed = image
label_transformed = label
if self.transform:
image_transformed = self.transform(image)
if self.target_transform:
label_transformed = self.target_transform(label)
return {'image': image_transformed, 'label': label_transformed}
# train_file = open('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/train.txt', 'w')
# val_file = open('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/val.txt', 'w')
# test_file = open('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/test.txt', 'w')
#
# image_idx = list(range(len(os.listdir('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/image'))))
# images_name = os.listdir('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/image')
#
# for i in range(1956):
# num = 0
# while True:
# num = random.randint(a=image_idx[0], b=image_idx[len(image_idx)-1]-1)
# if num in image_idx:
# break
# image_name = images_name[num]
# test_file.write(image_name + '\n')
# image_idx.remove(num)
# print(i)
#
# test_file.close()
# print('test.txt create finish!')
#
# for i in range(1956):
# num = 0
# while True:
# num = random.randint(a=image_idx[0], b=image_idx[len(image_idx)-1]-1)
# if num in image_idx:
# break
# image_name = images_name[num]
# val_file.write(image_name + '\n')
# image_idx.remove(num)
# print(i)
#
# test_file.close()
# print('val.txt create finish!')
#
# for i in image_idx:
# train_file.write(images_name[i] + '\n')
# print('train.txt create finish!')
# ---------------------------测试--------------------------------------------------
# length = len(os.listdir('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/image'))
#
#
#
# batch_size = 8
# data_root = '/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/'
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#
# transform = transforms.Compose(
# [transforms.Resize((224, 224)),
# transforms.ToTensor()
# ])
#
# train_dataset = UTKFaceGenderDataset(root=os.path.join(data_root, 'image'),
# txt_file=os.path.join(data_root, 'train.txt'),
# transform=transform,
# target_transform=ToTensor())
#
# print('train_dataset: {}'.format(len(train_dataset)))
#
#
# val_dataset = UTKFaceGenderDataset(root=os.path.join(data_root, 'image'),
# txt_file=os.path.join(data_root, 'val.txt'),
# transform=transform,
# target_transform=ToTensor()
# )
# print('val dataset: {}'.format(len(val_dataset)))
#
# datasets = [train_dataset, val_dataset]
# for dataset in datasets:
# print('-'*20)
# for i, sample in enumerate(dataset):
# print('{}, {}, label={}'.format(dataset.images_name[i].rstrip(), i, sample['label'].item()))
# # if (sample['label'].item() == 0) or (sample['label'].item() == 1):
# # continue
# # else:
# # os.remove(os.path.join('/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/image',dataset.images_name[i].rstrip()))
# # continue
# assert sample['label'].item() == 0 or sample['label'].item() == 1
- 训练+验证
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
import copy
import matplotlib.pyplot as plt
import dataset
import os
import torchnet
# ---------------------------数据集--------------------------------------------------
batch_size = 8
data_root = '/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor()
])
train_dataset = dataset.UTKFaceGenderDataset(root=os.path.join(data_root, 'image'),
txt_file=os.path.join(data_root, 'train.txt'),
transform=transform)
print('train_dataset: {}'.format(len(train_dataset)))
train_dataloader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True, num_workers=4)
# plt.figure()
# for i in train_dataset:
# plt.imshow(np.transpose(i['image'].numpy(), (1, 2, 0)))
# plt.title(train_dataset.class_name[i['label']])
# plt.show()
val_dataset = dataset.UTKFaceGenderDataset(root=os.path.join(data_root, 'image'),
txt_file=os.path.join(data_root, 'val.txt'),
transform=transform)
print('val dataset: {}'.format(len(val_dataset)))
val_dataloader = DataLoader(dataset=val_dataset,batch_size=batch_size, shuffle=False, num_workers=4)
# ------------------定义网络---------------------------------
# 载入预训练的型
model = models.squeezenet1_1(pretrained=True)
model.classifier[1] = nn.Conv2d(in_channels=512, out_channels=2, kernel_size=(1, 1), stride=(1, 1))
model.num_classes = 2
print(model)
# print('Down finish')
# model = models.alexnet(pretrained=True)
# # 修改输出层,2分类
# model.classifier[6] = nn.Linear(in_features=4096, out_features=2)
model.to(device)
# ------------------优化方法,损失函数--------------------------------------------------
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
loss_fc = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.StepLR(optimizer, 10, 0.1)
# ------------------训练--------------------------------------------------------------
num_epoch = 10
# 训练日志保存
file_train_loss = open('./log/train_loss.txt', 'w')
file_train_acc = open('./log/train_acc.txt', 'w')
file_val_loss = open('./log/val_loss.txt', 'w')
file_val_acc = open('./log/val_acc.txt', 'w')
# loss可视化
# win_loss = torchnet.logger.VisdomPlotLogger(plot_type='line',
# env='gender_classfiy',
# opts=dict(title='Train loss'),
# win='Train loss')
#
# # Accuracy可视化
# win_acc = torchnet.logger.VisdomPlotLogger(plot_type='line',
# env='gender_classify',
# opts=dict(title='Val acc'),
# win='Val acc')
acc_best_wts = model.state_dict()
best_acc = 0
iter_count = 0
for epoch in range(num_epoch):
train_loss = 0.0
train_acc = 0.0
train_correct = 0
train_total = 0
val_loss = 0.0
val_acc = 0.0
val_correct = 0
val_total = 0
scheduler.step()
for i, sample_batch in enumerate(train_dataloader):
inputs = sample_batch['image'].to(device)
labels = sample_batch['label'].to(device)
# 模型设置为train
model.train()
# forward
outputs = model(inputs)
# print(labels)
# loss
loss = loss_fc(outputs, labels)
# forward update
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计
train_loss += loss.item()
train_correct += (torch.max(outputs, 1)[1] == labels).sum().item()
train_total += labels.size(0)
print('iter:{}'.format(i))
if i % 200 == 199:
for sample_batch in val_dataloader:
inputs = sample_batch['image'].to(device)
labels = sample_batch['label'].to(device)
model.eval()
outputs = model(inputs)
loss = loss_fc(outputs, labels)
_, prediction = torch.max(outputs, 1)
val_correct += ((labels == prediction).sum()).item()
val_total += inputs.size(0)
val_loss += loss.item()
val_acc = val_correct / val_total
print('[{},{}] train_loss = {:.5f} train_acc = {:.5f} val_loss = {:.5f} val_acc = {:.5f}'.format(
epoch + 1, i + 1, train_loss / 100,train_correct / train_total, val_loss/len(val_dataloader),
val_correct / val_total))
if val_acc > best_acc:
best_acc = val_acc
acc_best_wts = copy.deepcopy(model.state_dict())
file_train_loss.write(str(train_loss / 100) + '\n')
file_train_acc.write(str(train_correct / train_total) + '\n')
file_val_loss.write(str(val_loss/len(val_dataloader)) + '\n')
file_val_acc.write(str(val_correct / val_total) + '\n')
iter_count += 200
# 可视化
# win_loss.log(iter_count, train_loss)
# win_acc.log(iter_count, val_acc)
train_loss = 0.0
train_total = 0
train_correct = 0
val_correct = 0
val_total = 0
val_loss = 0
print('Train finish!')
# 保存模型
torch.save(acc_best_wts, './models/model_squeezenet_utk_face_1.pth')
print('Model save ok!')
- 测试
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
import copy
import matplotlib.pyplot as plt
import dataset
import os
data_root = '/media/weipenghui/Extra/人脸属性识别/UTKFace/crop_part1/'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor()
])
test_dataset = dataset.UTKFaceGenderDataset(root=os.path.join(data_root, 'image'),
txt_file=os.path.join(data_root, 'test.txt'),
transform=transform)
print('test_dataset: {}'.format(len(test_dataset)))
model = models.squeezenet1_1(pretrained=True)
model.classifier[1] = nn.Conv2d(in_channels=512, out_channels=2, kernel_size=(1, 1), stride=(1, 1))
model.num_classes = 2
model.load_state_dict(torch.load('./models/model_squeezenet_utk_face_20.pth', map_location='cpu'))
print(model)
model.eval()
test_dataloader = DataLoader(dataset=test_dataset, batch_size=4, shuffle=False, num_workers=4)
correct = 0
total = 0
acc = 0.0
for i, sample in enumerate(test_dataloader):
inputs, labels = sample['image'], sample['label']
outputs = model(inputs)
_, prediction = torch.max(outputs, 1)
correct += (labels == prediction).sum().item()
total += labels.size(0)
acc = correct / total
print('test finish, total:{}, correct:{}, acc:{:.3f}'.format(total, correct, acc))
- 解析log, 可视化Loss, Accuracy
import numpy as np
import visdom
train_loss = np.loadtxt('./log/train_loss2.txt', dtype=float)
train_acc = np.loadtxt('./log/train_acc2.txt', dtype=float)
val_loss = np.loadtxt('./log/val_loss2.txt', dtype=float)
val_acc = np.loadtxt('./log/val_acc2.txt', dtype=float)
viz = visdom.Visdom(env='gender_classifier')
viz.line(Y=train_loss, win='train_loss', opts=dict(title='train_loss'))
viz.line(Y=val_loss, win='val_loss', opts=dict(title='val_loss'))
viz.line(Y=train_acc, win='train_acc', opts=dict(title='train_acc'))
viz.line(Y=val_acc, win='val_acc', opts=dict(title='val_acc'))
全部来自https://www.jianshu.com/p/1ec6075c0ab6