5 分钟教你搭建「视频动作分类」系统
写在前面
在之前的文章中,我们已经搭建过「以文搜图」、「以图搜图」等搜索服务,而今天这篇文章,将要教会你如何搭建一个「视频动作分类」的 AI 系统!
例如,我们只需放上一张“婴儿吃胡萝卜”的视频,这个系统就能分析和判断出这个视频最有可能的动作类别是 “eating carrots”。

「视频动作分类」系统展示图
怎么样,是不是很神奇呢?快跟着我们往下看吧!
准备工作
安装依赖包
在搭建「视频动作分类」系统之前,我们需要创建系统依赖的环境。我们用到了以下工具:
-
Towhee:用于构建模型推理流水线的框架,对于新手非常友好。
-
Milvus:用于存储向量并创建索引的数据库,简单好上手。
-
Gradio:轻量级的机器学习 Demo 构建工具。
-
Pillow:图像处理常用的 Python 库。
python -m pip install -q pymilvus towhee towhee.models pillow ipython gradio
数据准备
我们从 Kinetics400 的验证集中选取了 200 个视频,作为本次示例所用的数据。
首先,下载数据集并解压:
curl -L https://github.com/towhee-io/examples/releases/download/data/reverse_video_search.zip -O
unzip -q -o reverse_video_search.zip
这个数据集的包含了两个主文件:
-
train:视频所在文件夹,包含 20 个类别(每个类别为一个子文件夹),每个类别包含了 10 个视频,总计有 200 个视频。
-
reverse_video_search.csv:一个 csv 文件,其中包含视频文件夹中每个视频的 id、path 和 label。 接着,我们输入以下代码便可查看数据集内的详细信息:
import pandas as pd
df = pd.read_csv('./reverse_video_search.csv')print(df.head(3))print(df.label.value_counts())
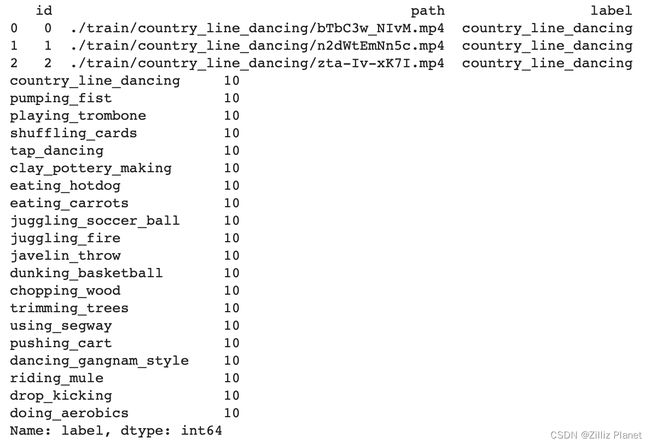
同时,我们在这里定义一个ground_truth函数,这个函数可以通过视频文件路径就能找到它真实的分类标签。
def ground_truth(path):
label = df.set_index('path').at[path, 'label']
return [label.replace('_', ' ')]
到这里,我们就完成了所有的准备工作啦!
系统搭建
首先,我们使用 X3D_M 视频分类模型来预测视频所属的类别,利用 Towhee 提供的一系列简单又好用的 API 就可以对输入的视频进行批处理。
预测类别
舞蹈视频是最适合进行动作分类的例子了!我们在这里以目标类别为“tap_dancing”的视频为例,观察 X3D_M 模型预测的结果。在默认情况下,模型将会返回得分(可能性)最高的前 5 个分类,我们可以通过自行更改topk来控制返回的类别数量。
import towhee
(
towhee.glob['path']('./train/tap_dancing/*.mp4')
.video_decode.ffmpeg['path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 16})
.action_classification['frames', ('predicts', 'scores', 'features')]
.pytorchvideo(model_name='x3d_m', skip_preprocess=True, topk=5).select['path', 'predicts', 'scores']()
.show()
)
这里对用到的 Towhee API 做一些说明:
-
towhee.read_csv():从 CSV 文件中读取数据。 -
.video_decode.ffmpeg():一个 Towhee 的算子,能通过文件路径读取视频,并通过指定的采样方法得到一定数量的视频帧。了解更多 -
.action_classification.pytorchvideo():一个 Towhee 的算子,可以提取视频特征并预测视频所属的动作分类。了解更多
输入以上代码后,模型返回的结果示例如下:

可以看到,path 一栏是预测对象(视频)的文件路径,predicts(topk=5)一栏是预测的前五个结果,scores 一栏则是五个类别对应的得分。上图展示了5个视频的预测结果,top1 (第一个预测类别)的预测结果有 4/5 判断正确,而 top2 (前两个预测类别)则全部准确预测。
评估和优化
我们刚刚展示了如何识别一个动作视频的类别,但这套系统的整体性能表现如何呢?接下来,我们借助 Towhee 批量处理和评估接口,使用 mHR(recall@K)来衡量预测结果。
import time
start = time.time()
dc = (
towhee.read_csv('reverse_video_search.csv').unstream()
.video_decode.ffmpeg['path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 16})
.action_classification['frames', ('predicts', 'scores', 'features')].pytorchvideo(
model_name='x3d_m', skip_preprocess=True, topk=5)
)
end = time.time()
print(f'Total time: {end-start}')
benchmark = (
dc.runas_op['path', 'ground_truth'](func=ground_truth)
.runas_op['predicts', 'top1'](func=lambda x: x[:1])
.runas_op['predicts', 'top3'](func=lambda x: x[:3])
.with_metrics(['mean_hit_ratio'])
.evaluate['ground_truth', 'top1'](name='top1')
.evaluate['ground_truth', 'top3'](name='top3')
.evaluate['ground_truth', 'predicts'](name='top5')
.report()
)
运行以上代码后,会返回处理和预测所有样本数据的时间和不同 topk 对应的命中率。
Total time: 39.41930913925171

可以看到,X3D_M 模型预测 200 个示例视频所需要花费的时间约为 39 s(平均每个视频消耗约0.2s),预测结果 top1 的准确率为 70%,而 top5 的准确率高达 90%!
虽然 90% 的命中率是一个不错的结果,但我们使用的 X3D_M 轻量模型其实已经牺牲了部分精度。如果换成更复杂的深度学习模型,比如 MViT,理论上能够使准确率更上一层楼。
我们只需将上面代码中的 model_name 指定为 'mvit_base_32x3' 即可:
import time
start = time.time()
dc = (
towhee.read_csv('reverse_video_search.csv').unstream()
.video_decode.ffmpeg['path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 32})
.action_classification['frames', ('predicts', 'scores', 'features')].pytorchvideo(
model_name='mvit_base_32x3', skip_preprocess=True, topk=5)
)
end = time.time()
print(f'Total time: {end-start}')
benchmark = (
dc.runas_op['path', 'ground_truth'](func=ground_truth)
.runas_op['predicts', 'top1'](func=lambda x: x[:1])
.runas_op['predicts', 'top3'](func=lambda x: x[:3])
.with_metrics(['mean_hit_ratio'])
.evaluate['ground_truth', 'top1'](name='top1')
.evaluate['ground_truth', 'top3'](name='top3')
.evaluate['ground_truth', 'predicts'](name='top5')
.report()
)
Total time: 79.16032028198242
不难发现,我们使用了同样的样本数据,然而将模型替换成 MViT 后,所需时间大约是之前的 2 倍,而准确率的确有所提升:
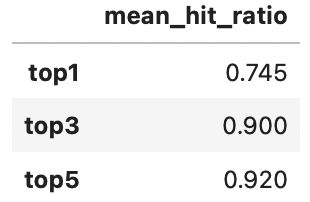
那有什么办法可以既高效快速地运行模型,又能保持较高的准确率呢? 有!Towhee 允许并行执行,能够减少处理批量数据的时间。我们只需在代码中加入 set_parallel():
start = time.time()
dc =(
towhee.read_csv('reverse_video_search.csv').unstream()
.set_parallel(5)
.video_decode.ffmpeg['path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 16})
.action_classification.pytorchvideo['frames', ('predicts', 'scores', 'features')](
model_name='x3d_m', skip_preprocess=True, topk=5)
)
end = time.time()
print(f'Total time: {end-start}')
这一次花费的时间几乎是之前的一半:Total time: 22.97886061668396,明显比之前更快了!
异常处理
如果我们一次处理多条数据,其中一个数据异常就会使整个程序报错并中断,这对于大规模测试或者生产环境无疑是致命的。而这些异常数据并不会影响整个「视频动作分类」系统,所以,我们需要让系统在遇到异常值时生成报告,然后继续处理其余的视频。
Towhee 支持异常处理的执行模式,允许流水线继续处理并用 Empty 值表示异常。 用户可以选择如何处理流水线末端的空值。
(
towhee.glob['path']('./exception/*')
.exception_safe()
.video_decode.ffmpeg['path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 16})
.action_classification['frames', ('labels', 'scores', 'vec')].pytorchvideo(
model_name='x3d_m', skip_preprocess=True)
.drop_empty()
.select['path', 'labels']()
.show()
)
在上面的查询过程中,exception文件夹下共有 4 个文件,其中 1 个文件损坏。 使用exception_safe()后,我们最终成功获得了 3 个视频文件的预测结果。从结果中可以看出,drop_empty()删除了失败的预测结果(空数据)。

Gradio 部署 demo
Towhee 提供的 towhee.api()可以将流水线包装成一个函数,以便使用。 我们可以在 Gradio 中使用这个 action_classification_function 轻而易举地构建一个简单可交互的在线演示 demo。
import gradio
topk = 3
with towhee.api() as api:
action_classification_function = (
api.video_decode.ffmpeg(
sample_type='uniform_temporal_subsample', args={'num_samples': 32})
.action_classification.pytorchvideo(model_name='mvit_base_32x3', skip_preprocess=True, topk=topk)
.runas_op(func=lambda res: {res[0][i]: res[1][i] for i in range(len(res[0]))})
.as_function()
)
interface = gradio.Interface(action_classification_function,
inputs=gradio.Video(source='upload'),
outputs=[gradio.Label(num_top_classes=topk)]
)
interface.launch(inline=True, share=True)
Gradio 为我们提供了一个 Web UI,点击 URL 进行访问(或直接与 notebook 下方出现的界面进行交互):

点击这个 URL 链接,就会跳转到我们「视频分类」的交互界面,输入你想要分类的视频,即可呈现出视频所对应的分类标签。例如,我们上传一个“婴儿吃胡萝卜” 的视频即可得到系统识别的动作标签:
可以看到,我们的「视频分类」系统是十分精确的,能准确地识别并给出视频所属的分类标签。
总结
在今天的文章中,我们通过 Towhee 利用 X3D 以及 MViT 两种不同量级的视频动作分类模型搭建了一个简单的「视频分类」系统,并使用 Gradio 创建了一个可交互的程序界面。
在之前的文章中,我们在 Towhee 的帮助下搭建了「以文搜图」、「以图搜图」等搜索服务,参考本文的实现,我们也可以利用 Towhee (以及 Milvus)实现更多种更通用的视频分类和识别业务,大家可以动起手来搭建一套属于自己的 AI 业务系统!