大数据之 Hadoop 教程
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop 由三个关键部分组成:
HDFS:Hadoop 分布式文件系统,它是 Hadoop 数据存储层。
MapReduce:数据计算框架
YARN:负责资源管理和任务调度。
一、什么是HDFS
HDFS并非是数据库,官方定义叫做分布式文件系统。它的主要目的是支持以流的形式访问写入的大型文件。
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
HDFS对需要存储的数据,进行写入和读出,通过统一的命名空间——“目录树”来定位文件。当收到数据存储请求时,HDFS将文件进行分块(Block),一批数据会被分成若干个Block,然后分配到集群当中的计算机进行存储;当需要提取这些数据时,再通过定位文件所在位置,找到需要的数据。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。
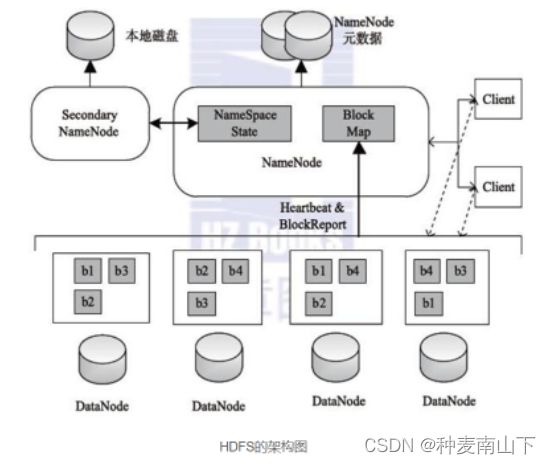
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分
1、Client:就是客户端。
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- Client 可以通过一些命令来访问 HDFS。
2、NameNode:就是 master,它是一个主管、管理者。
- 管理 HDFS 的名称空间
- 管理数据块(Block)映射信息
- 配置副本策略
- 处理客户端读写请求。
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
二、HDFS shell操作
HDFS以文件和目录的形式组织用户数据。它提供了一个命令行的接口(DFSShell)让用户与HDFS中的数据进行交互。命令的语法和用户熟悉的其他shell(例如 bash, csh)工具类似。
cp
使用方法:hadoop fs -cp URI [URI …]
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。
mkdir
使用方法:hadoop fs -mkdir
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
put
使用方法:hadoop fs -put
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
- hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:
- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
三、Map/Reduce概述
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。
键是输入值的引用,而值就是要操作的数据集。
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
Map/Reduce框架运转在
这里提供一个示例,帮助您理解它。假设输入域是 one small step for man,one giant leap for mankind。在这个域上运行 Map 函数将得出以下的键/值对列表 :
(one,1)(small,1) (step,1) (for,1) (man,1)(one,1) (giant,1) (leap,1) (for,1) (mankind,1)
如果对这个键/值对列表应用 Reduce 函数,将得到以下一组键/值对:
(one,2) (small,1) (step,1) (for,2) (man,1)(giant,1) (leap,1) (mankind,1)
结果是对输入域中的单词进行计数。
一个Map/Reduce 作业的输入和输出类型如下所示:
(input)
四、Yarn是什么
Yarn 是一种资源管理系统,在集群模式下,管理、分配和释放资源(CPU,内存,磁盘)变得非常复杂。而 Yarn 可以非常高效的管理这些资源。它根据来自任何应用程序的请求分配相同的值。
在 Master 节点会运行一个叫ResourceManager 守护进程,且每个slave 节点都会有一个叫 NodeManager 的守护进程。